

知識強化と事前トレーニングされた大規模モデルに基づくクエリ意図認識


#1. 背景の紹介

##エンタープライズ デジタル化近年注目を集めている人工知能、ビッグデータ、クラウドコンピューティングなどの新世代デジタル技術を活用して企業のビジネスモデルを変革し、企業ビジネスの新たな成長を促進することを指します。企業のデジタル化には、通常、業務運営のデジタル化と企業管理のデジタル化が含まれます。この共有化では主に企業管理レベルのデジタル化を導入します。
#情報のデジタル化とは、簡単に言うと、デジタル的な方法で情報を読み取り、書き込み、保存し、送信することを意味します。以前の紙の文書から現在の電子文書やオンラインで共同作業を行う文書に至るまで、情報のデジタル化は今日のオフィスの新たな常態となっています。現在、アリババはビジネス コラボレーションに DingTalk ドキュメントと Yuque ドキュメントを使用しており、オンライン ドキュメントの数は 2,000 万件以上に達しています。さらに、多くの企業は、アリババのイントラネットである Alibaba Internal and Outside Networks や技術コミュニティ ATA など、独自の社内コンテンツ コミュニティを持っており、現在、ATA コミュニティには 300,000 件近くの技術記事があり、それらはすべて非常に貴重なコンテンツ資産です。
#プロセスのデジタル化とは、デジタル テクノロジーを使用してサービス プロセスを変革し、サービスの効率を向上させることを指します。社内管理、IT、人事などのトランザクション業務が多く発生します。 BPMSプロセス管理システムは、業務プロセスを標準化し、ビジネスルールに基づいてワークフローを策定し、ワークフローに従って自動的に実行することで、人件費を大幅に削減できます。 RPA は主にプロセスにおける複数システムの切り替えの問題を解決するために使用され、システム インターフェイス上で手動のクリック入力操作をシミュレートできるため、さまざまなシステム プラットフォームに接続できます。プロセスデジタル化の次の発展方向は、対話型ロボットと RPA によって実現されるプロセスのインテリジェンスです。現在、タスクベースの会話ロボットは、休暇の申請やチケットの予約など、ユーザーが数ラウンドの対話内でいくつかの単純なタスクを完了できるように支援します。
#ビジネスデジタル化の目標は、デジタルテクノロジーによって新たなビジネスモデルを確立することです。実際に企業内には、購買部門の業務デジタル化などのビジネスミドルオフィスがいくつかあります。これは、商品の検索から購入申し込みの開始、購入契約の作成、支払い、注文の実行などの一連のプロセスをデジタル化することを指します。 。また、法務ミドルオフィスの業務デジタル化では、契約センターを例に挙げると、契約書作成から契約レビュー、契約締結、契約履行に至る契約ライフサイクル全体のデジタル化を実現します。
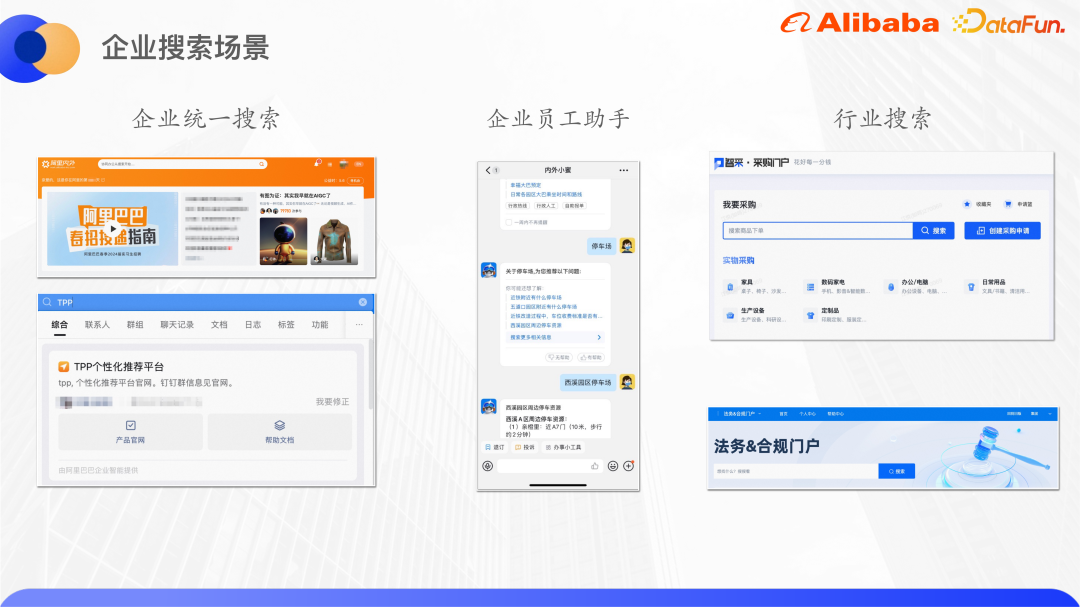
(1) 複数の情報を集約する統合検索 (包括的検索とも呼ばれます)コンテンツ サイトに関する情報には、DingTalk ドキュメント、Yuque ドキュメント、ATA などが含まれます。統合検索への入り口は現在、アリババの内部ネットワークである Alibaba Internal および Outside と従業員専用バージョンの DingTalk に配置されており、これら 2 つの入り口を合わせたトラフィックは約 140 QPS に達し、これは ToB シナリオでは非常に高いトラフィックとなります。
(2) エンタープライズ従業員アシスタントとは、Xiaomi の内外を指します。これは、アリババの社内従業員向けのインテリジェントなサービス ロボットであり、人事、管理、IT を統合します。は、多くの分野で企業知識の質問と回答サービス、および迅速なサービス チャネルを提供しており、DingTalk の入り口と一部のプラグインの入り口を含めると、合計約 25 万人が利用でき、グループの 1 つでもあります。交通位置。
(3) 業界検索は前章で述べたビジネスのデジタル化に相当し、例えば調達には調達モールというポータルがあり、バイヤーは調達モール内で検索し、商品を選択し、アプリケーションは、ユーザーが企業の購入者であることを除いて、電子商取引の検索 Web サイトに似ています。法令順守ビジネスにも対応するポータルがあり、法学部の学生はそこで契約書を検索し、次のような一連のタスクを実行できます。契約書の作成、承認、署名。 
一般的に、企業内の各ビジネス システムまたはコンテンツ サイトには独自の検索ビジネスがあります。システムは相互に分離する必要がありますが、コンテンツ サイトを分離すると情報の島という現象が形成されます。たとえば、技術的なクラスメートが技術的な問題に遭遇した場合、まず ATA にアクセスして問題に関連する技術記事を検索します。見つからない場合は、Zhibo、DingTalk ドキュメント、および Yuque ドキュメントで同様のコンテンツを検索します。 、合計 4 ~ 5 回の検索が必要になりますが、この検索動作は間違いなく非常に非効率的です。したがって、これらのコンテンツを統合エンタープライズ検索に収集し、一度の検索ですべての関連情報を取得できるようにしたいと考えています。
さらに、ビジネス属性を含む業界検索は通常、相互に分離する必要があります。たとえば、調達モールのユーザーはグループのバイヤーであり、契約センターのユーザーはグループの法務担当者です。この 2 つの検索シナリオではユーザー数が非常に少ないため、ユーザーの行動は次のようになります。比較的疎であり、ユーザーの行動データに依存する推奨アルゴリズムの場合、効果は大幅に減少します。また、調達や法務の分野では、専門家によるアノテーションが必要でコストが高いため、アノテーション付きデータがほとんどなく、高品質なデータセットを収集することが困難です。最後はクエリとドキュメントのマッチングの問題です。検索されるクエリの長さは基本的に 12 単語以内です。短いテキストです。文脈が理解できず、意味情報が十分に豊富ではないため、学術コミュニティでは、短いテキストの理解に関する関連研究が数多く行われています。検索対象となるのは基本的に文字数が数百から数千に及ぶ長い文書であり、長い文書の内容を理解して表現することも非常に困難な作業です。
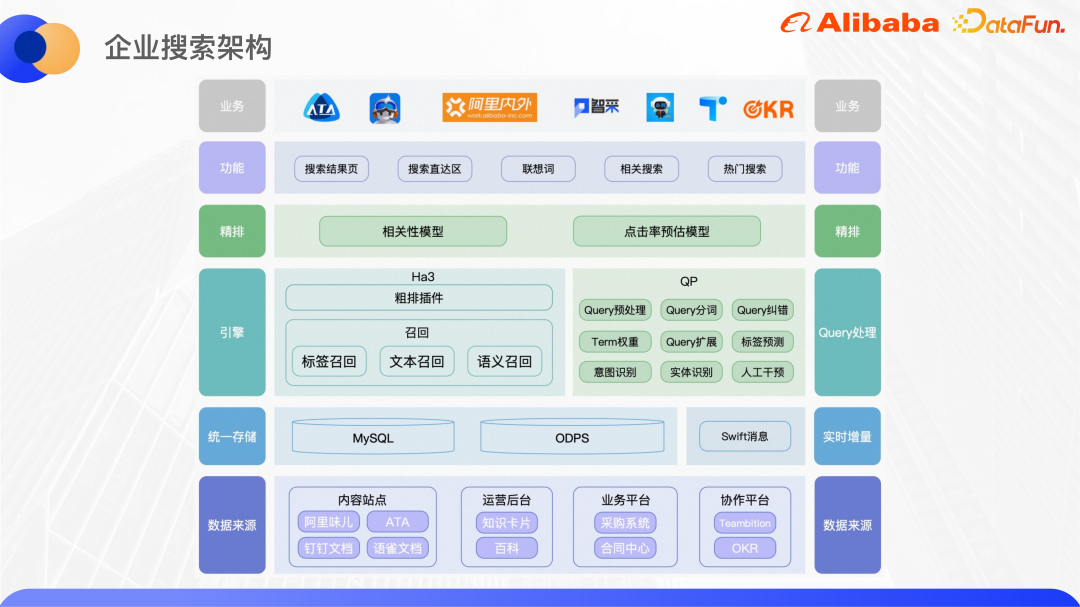 #上の図は、現在のエンタープライズ サーチの基本アーキテクチャを示しています。ここでは主に統合検索部分を紹介します。
#上の図は、現在のエンタープライズ サーチの基本アーキテクチャを示しています。ここでは主に統合検索部分を紹介します。
現在、統合検索は、ATA、DingTalk ドキュメント、Yuque ドキュメントなど、大小を問わず 40 以上のコンテンツ サイトに接続されています。アリババが自社開発した Ha3 エンジンはリコールと大まかな並べ替えに使用されており、リコールの前にアルゴリズムの QP サービスが呼び出され、ユーザーのクエリを分析し、クエリの分割、エラー修正、用語の重み付け、クエリの拡張、NER の意図認識などを提供します。 QP の結果とビジネス ロジックに従って、クエリ文字列がエンジン側で再呼び出しのために組み立てられます。 Ha3 ベースの大まかなソート プラグインは、GBDT などのいくつかの軽量ソート モデルをサポートできます。詳細なランキング段階では、より複雑なモデルを並べ替えに使用できます。相関モデルは主に検索の精度を確保するために使用され、クリックスルー率推定モデルはクリックスルー率を直接最適化します。
検索の並べ替えに加えて、検索ドロップダウン ボックスの直接検索領域、関連ワードなど、他の検索周辺機能も統合します。 、関連検索、人気検索など。現在、上位層でサポートされているサービスは、主にアリババ内外とアリババDingTalkの統合検索、調達や法務の垂直検索、ATA Teambition OKRシステムのクエリ理解などである。
#
上の図は、エンタープライズ サーチ QP の一般的なアーキテクチャです。QP サービスは、DII と呼ばれるアルゴリズム オンライン サービス プラットフォーム上に展開されます。 DII プラットフォームは、KV テーブルとインデックス テーブル インデックスの構築とクエリをサポートできます。これは全体としてチェーン サービス フレームワークであり、複雑なビジネス ロジックは比較的独立した結合したビジネス モジュールに分割する必要があります。たとえば、アリババ内外の検索 QP サービスは、単語分割、エラー修正、クエリ拡張、用語重み付け、意図認識などの複数の機能モジュールに分割されています。チェーン フレームワークの利点は、複数人による共同開発が容易になることです。各人が独自のモジュールの開発に責任を負います。上流と下流のインターフェイスが合意されている限り、異なる QP サービスが同じモジュールを再利用できるため、重複したコード。さらに、基盤となるアルゴリズム サービス上に層がラップされ、外部への TPP インターフェイスが提供されます。 TPP はアリババ内の成熟したアルゴリズム推奨プラットフォームであり、AB 実験や柔軟な拡張を容易に行うことができ、ログ管理、監視および警報のメカニズムも非常に成熟しています。
TPP 側でクエリの前処理を実行し、次に DII リクエストを組み立て、DII アルゴリズム サービスを呼び出し、結果を取得した後に解析し、最後に結果を返します。呼び出し側。
2. 作業共有
次に、2 つのエンタープライズ シナリオにおけるクエリ意図の識別作業を紹介します。
1. 内部および外部 Xiaomi
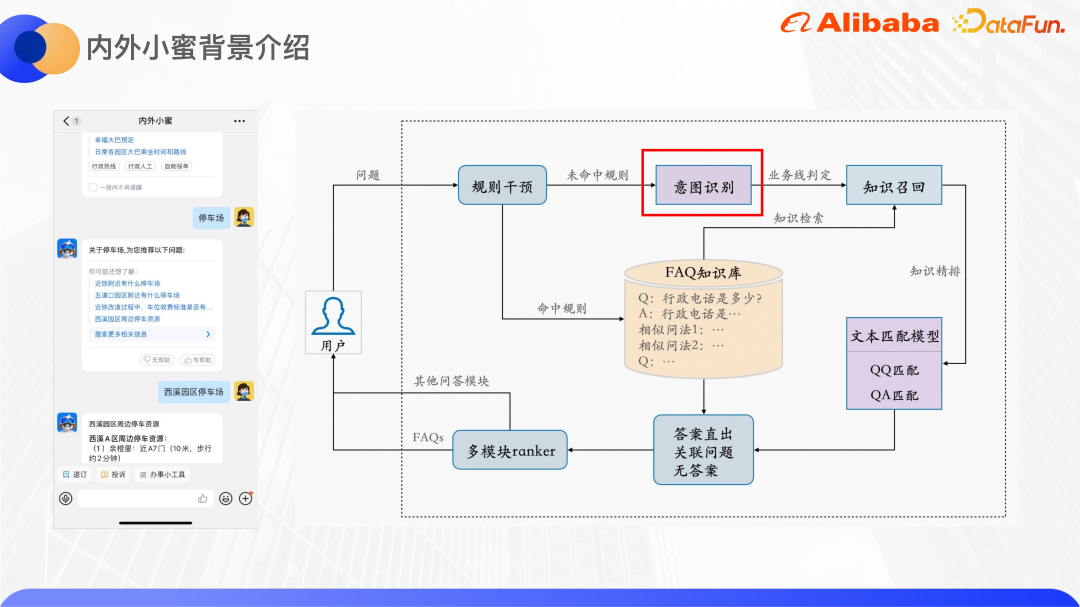
内部の最下層外部の Xiaomi は Yunxiaomi に基づいています DAMO アカデミーによって開始された Q&A エンジンは、FAQ Q&A、マルチラウンド タスク Q&A、ナレッジ グラフ Q&A をサポートできます。上の図の右側は、FAQ の質問と回答エンジンの一般的なフレームワークを示しています。
ユーザーがクエリを入力すると、主にビジネスと運用がいくつかのルールを設定できるようにするルール介入モジュールが表示されます。ルールがヒットすると、設定された答えを直接返します。ルールがヒットしない場合は、アルゴリズムが使用されます。意図認識モジュールは、対応するビジネスラインへのユーザーのクエリを予測します。各ビジネスラインの FAQ ナレッジベースには多数の QA ペアがあり、各質問はいくつかの類似した質問で構成されます。クエリを使用してナレッジベース内の QA ペアの候補セットを取得し、テキスト マッチング モジュールを使用して QA ペアを絞り込みます。モデル スコアに基づいて、回答がストレートであるか、関連する質問が推奨されているか、または適切であるかが判断されます。は答えではありません。 FAQ の質問と回答エンジンに加えて、タスクベースの質問と回答、ナレッジ グラフの質問と回答などの他の質問と回答エンジンも存在するため、マルチモジュール ランカーは最終的にどのエンジンの回答を選択するかを選択するように設計されています。ユーザーに明らかにします。
#以下では、意図認識モジュールに焦点を当てます。
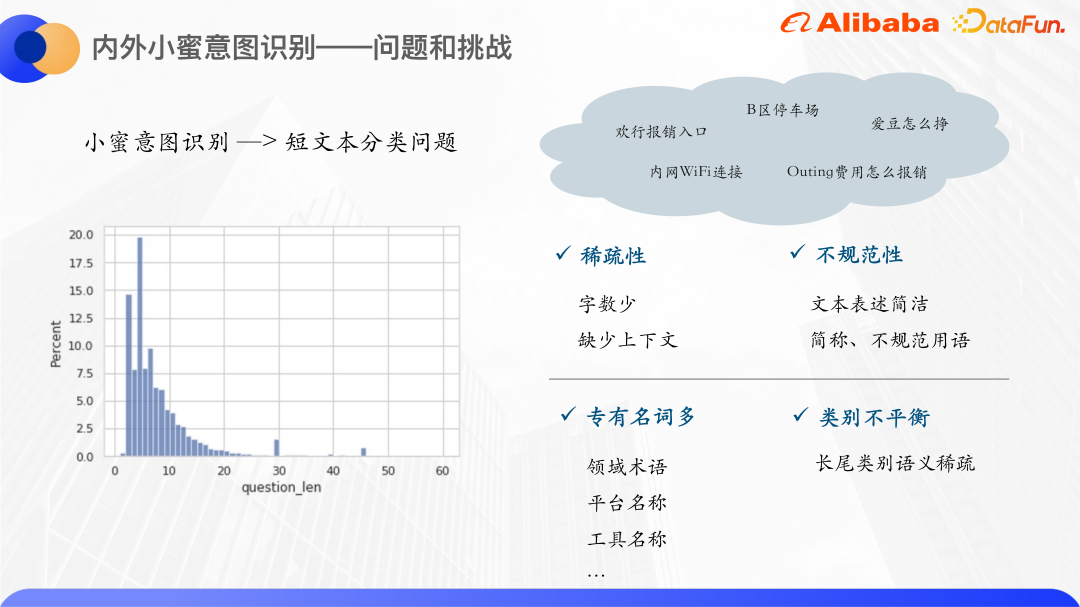
過去 1 年間の内外における Xiaomi のユーザー クエリを数えたところ、ほとんどのユーザーのクエリの単語数は 0 ~ 20 の間に集中しており、クエリの単語数の 80% 以上が 10 単語以内であるため、Xiaomi の意図認識は短文分類の問題であり、短文の数は非常に少なく、したがって、従来のベクトル空間モデルが使用される場合、表現によりベクトル空間が疎になります。そして一般的に言って、短いテキスト表現はあまり標準化されておらず、略語や不規則な用語が多いため、OOV 現象がより多く発生します。
Xiaomi の短いテキスト クエリのもう 1 つの特徴は、多くの固有名詞 (通常は Huanxing、Idou などの内部プラットフォーム名やツール名) が含まれていることです。これらの固有名詞のテキスト自体はカテゴリに関連した意味情報を持たないため、効果的な意味表現を学習することが困難であるため、知識強化を利用してこの問題を解決することを考えました。
一般的な知識の強化にはオープンソースのナレッジ グラフが使用されますが、企業内の固有名詞はオープンソースのナレッジ グラフで対応するエンティティを見つけることができないため、内側から知識を探します。アリババにはナレッジ カードの検索機能があります。各ナレッジ カードはイントラネット製品に対応しています。Xiaomi の内外の分野と非常に関連しています。たとえば、Huanxing と Idol はここで関連情報を見つけることができます。ナレッジ カードは企業向けです。ナレッジカードは知識源として使用されます。
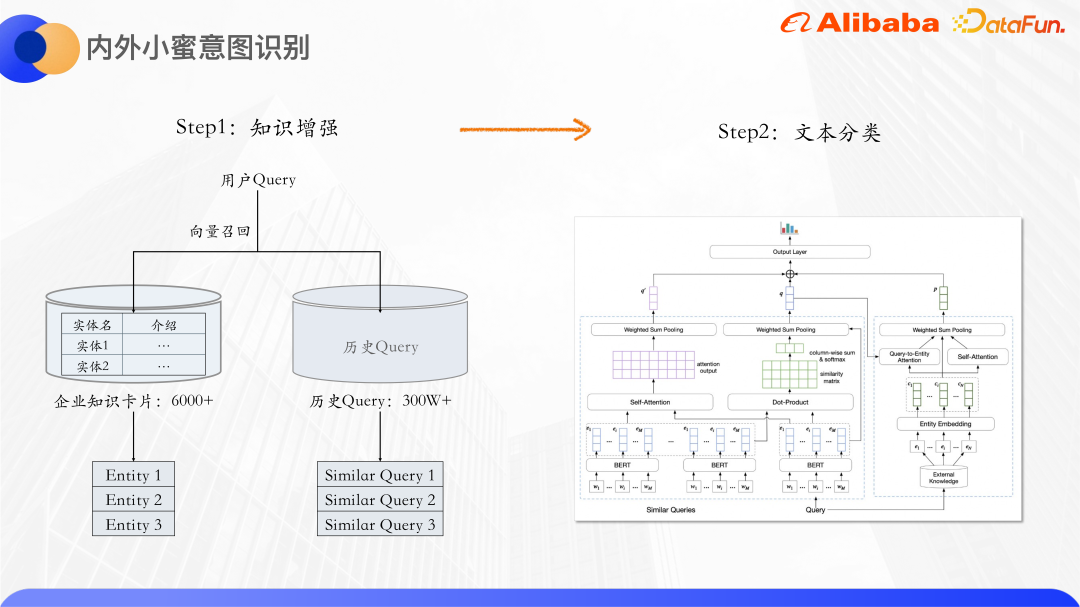
この方法は 2 つのステップに分かれています:
最初のステップは知識の強化です。合計 6,000 を超えるエンタープライズ ナレッジ カードがあります。各ナレッジ カードにはエンティティ名とテキストの紹介があります。ユーザーのクエリに従って、それに関連するナレッジ カードが呼び出され、履歴クエリも使用されます。イントラネット Wifi 接続、Wifi イントラネット接続など、類似したクエリが多数あります。同様のクエリは、互いの意味情報を補完し、短いテキストのまばらさをさらに軽減できます。ナレッジ カード エンティティに加えて、同様のクエリが呼び出され、元のクエリが分類のためにテキスト分類モデルに送信されます。
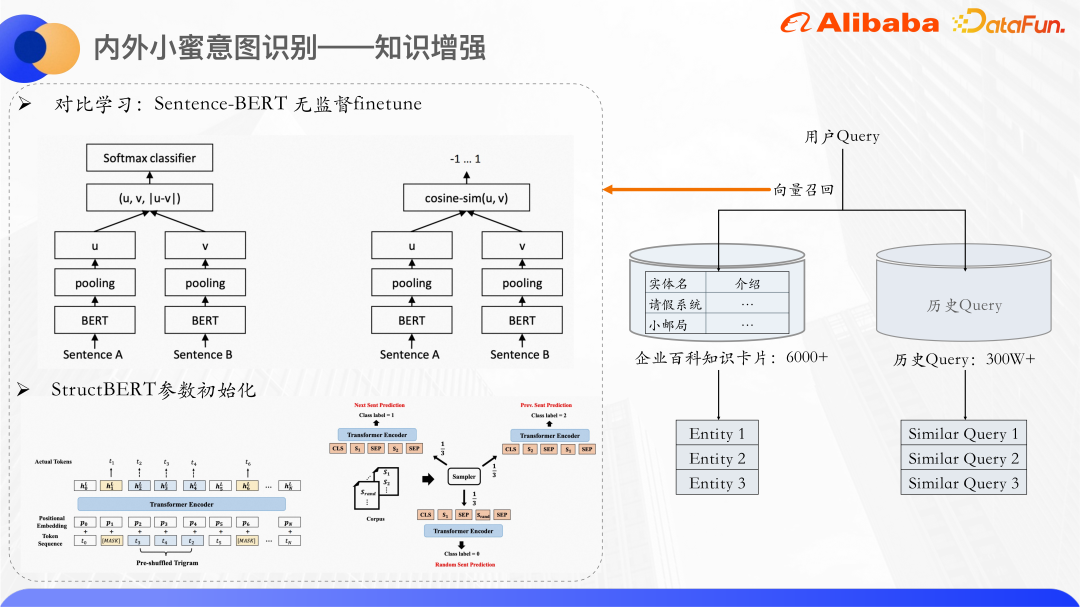
ベクトル呼び出しを使用して、ナレッジ カードのエンティティや同様のクエリを呼び出します。 Bert を使用して、クエリとナレッジ カードのテキスト説明の具体的な量をそれぞれ計算します。一般に、Bert の CLS ベクトルは文表現として直接使用されません。多くの論文でも、Bert が出力するベクトルには表現劣化の問題があり、直接表現に適していないため、CLS ベクトルを文表現として直接使用すると効果が低いと述べられています。教師なしの類似度計算を行うため、対照学習のアイデアを使用して、類似したサンプルを近づけ、異なるサンプルを可能な限り均等に分散します。
具体的には、Sentence-Bert はデータセットを微調整し、そのモデル構造とトレーニング方法により、より優れた文ベクトル表現を生成できます。 2塔構造になっており、両側のBertモデルはモデルパラメータを共有し、2つの文をそれぞれBertに入力し、Bertが出力する隠れ状態をプールした後、2つの文の文ベクトルを取得します。ここでの最適化の目標は、比較学習、infoNCE の損失です。
良い例: サンプルをモデルに 2 回直接入力しますが、この 2 回のドロップアウトは次のとおりです。が異なるため、表現されるベクトルもわずかに異なります。
否定的な例: 同じバッチ内の他のすべての文。
この損失を最適化することで、文ベクトルを予測するための Sentence-Bert モデルが得られます。
StructBERT モデル パラメーター を使用して、ここで Bert 部分を初期化します。 StructBERT は DAMO アカデミーによって提案された事前学習モデルです。そのモデル構造はネイティブ BERT と同じです。その中心的なアイデアは、言語構造情報を事前学習タスクに組み込んで、クエリの文ベクトルと知識カードを取得することです。ベクトルのコサイン類似度の計算を通じて、最も類似した上位 k 個のナレッジ カードと類似のクエリを思い出します。
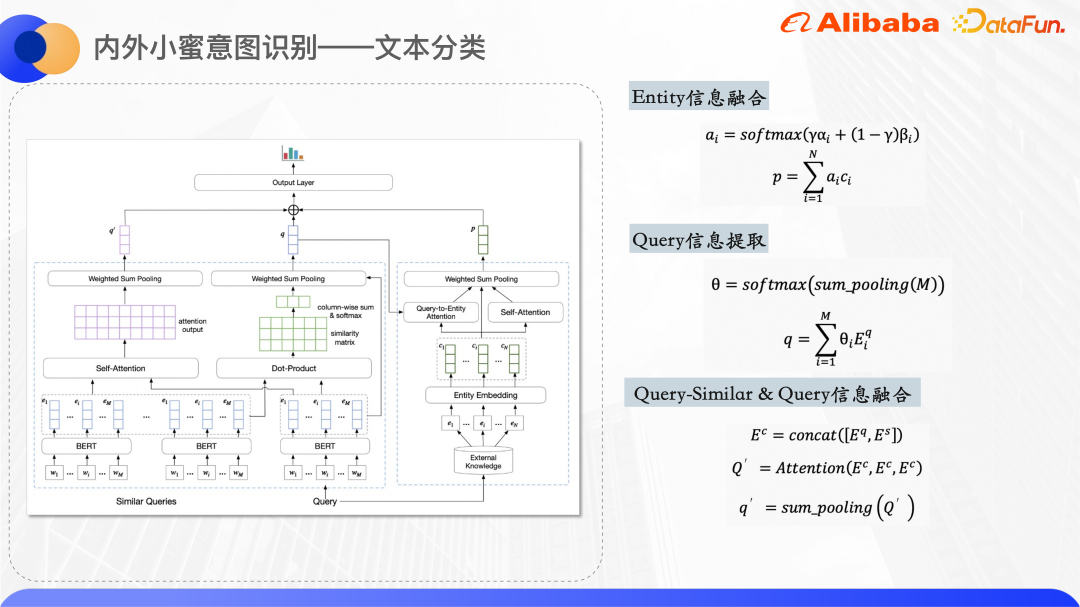
#上の図は、Bert を使用したテキスト分類のモデル構造です。エンコーディング層 元のクエリの表現と類似のクエリのワード ベクトルを抽出する ナレッジ カードの各エンティティはエンティティ ID 埋め込みを維持し、ID 埋め込みはランダムに初期化されます。
#モデル構造図の右側は、クエリによって呼び出されたエンティティを処理し、エンティティの統一されたベクトル表現を取得するために使用されます。短いテキスト自体は比較的曖昧であるため、呼び出されたナレッジ カード エンティティにもある程度のノイズが含まれますが、2 つの注意メカニズムを使用することで、モデルは正しいエンティティにより多くの注意を払うことができます。 1 つはクエリ対エンティティの注意です。これは、モデルがクエリに関連するエンティティにさらに注意を払うようにすることを目的としています。もう 1 つは、エンティティ自体の自己注意です。これにより、互いに類似したエンティティの重みが増加し、ノイズの多いエンティティの重みが減少します。 2 セットのアテンション ウェイトを結合すると、最終的なエンティティのベクトル表現が得られます。
モデル構造図の左側は元のクエリと類似のクエリを処理するもので、類似のクエリと元のクエリの重複する単語によってクエリの中心となる単語が特徴付けられることが観察されるためです。ある程度の効果があるため、ここでは 2 つの単語間のクリックを計算して類似度行列を取得し、合計プーリングを実行して、クエリに比較的類似した元のクエリ内の各単語の重みを取得します。目的は、モデルにより多くの支払いをさせることです。中心となる単語に注目し、類似クエリと元のクエリの単語ベクトルを結合し、結合して融合された意味情報を計算します。
最後に、上記の 3 つのベクトルが連結され、密層予測を通じて各カテゴリの確率が取得されます。
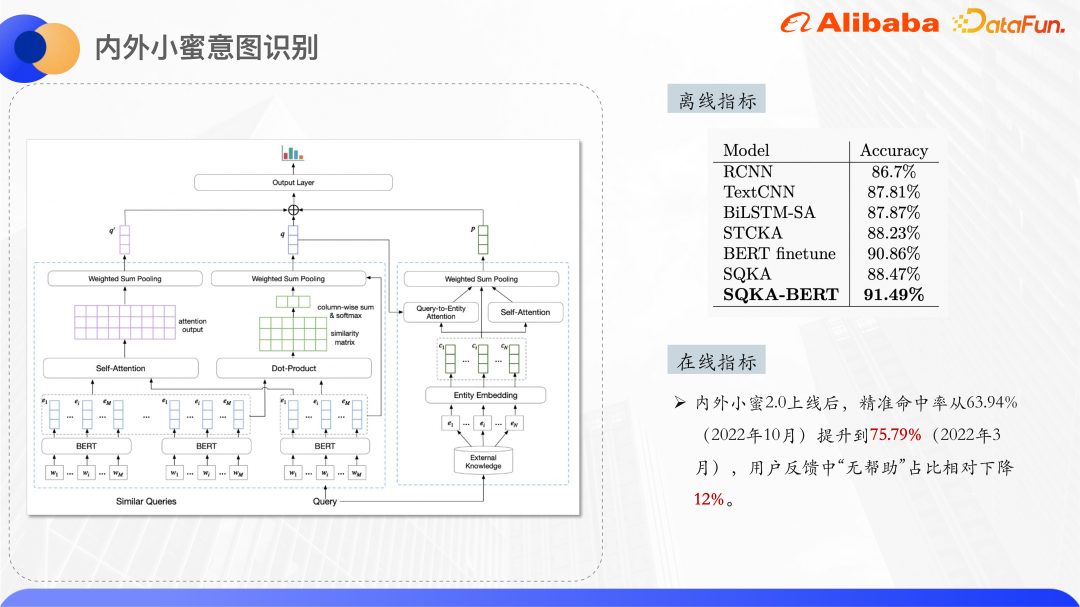
上記は BERT 微調整の結果を超える実験結果です。エンコード層では使用されず、すべての非 Bert モデルも超えます。
#2. 業界検索
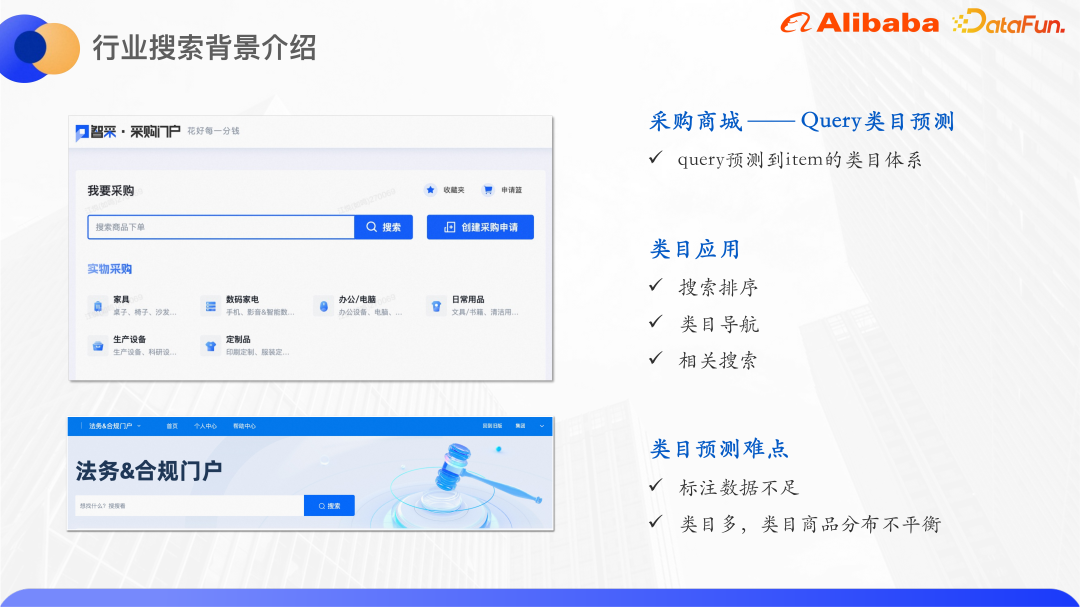
購買モールを例に挙げます。 . モールでは独自の商品カテゴリシステムがあり、各商品は商品カテゴリに分類されてから店頭に並べられます。モール検索の精度を向上させるためには、特定のカテゴリへのクエリを予測し、そのカテゴリに応じて検索ランキング結果を調整する必要があります。また、サブカテゴリのナビゲーションや関連検索をインターフェイスに表示することもできます。カテゴリの結果。
カテゴリ予測には手動でラベル付けされたデータセットが必要ですが、調達分野ではラベル付けのコストが比較的高いため、この問題は小規模の観点から解決されます。サンプルの分類。
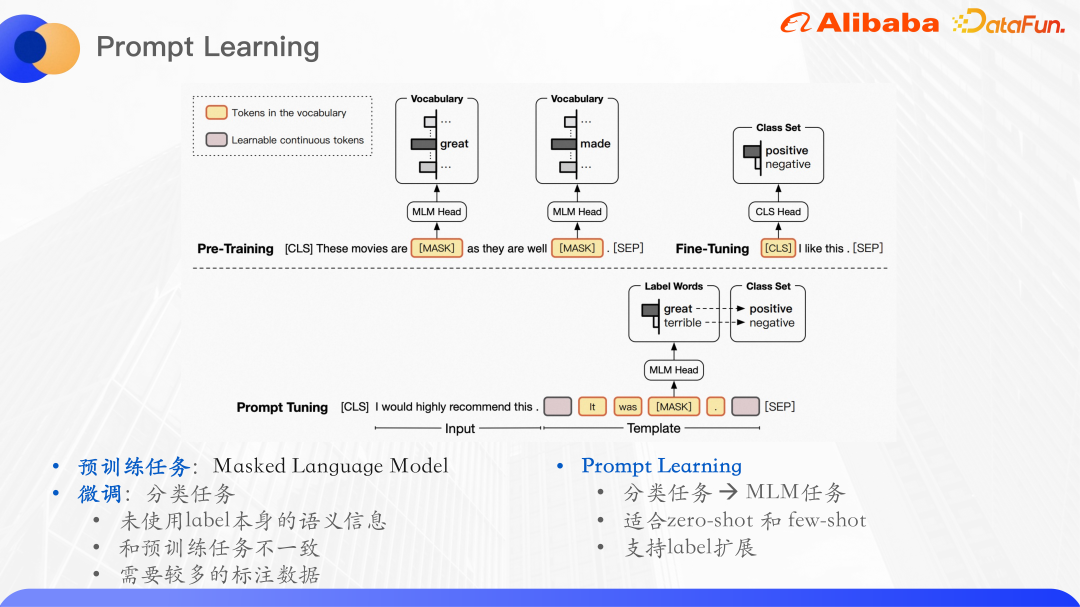
事前トレーニングされたモデルは、NLP タスクにおける強力な言語理解機能を実証しました。使用されるパラダイムは、大規模なラベルなしデータセットで事前トレーニングし、その後、監視された下流タスクで微調整することです。たとえば、Bert の事前トレーニング タスクは主にマスク言語モデルです。これは、文内の単語の一部をランダムにマスクして元のモデルに入力し、マスク部分の単語を予測して確率を最大化することを意味します。言葉。
クエリ カテゴリ予測の実行は、本質的にはテキスト分類タスクです。テキスト分類タスクは、特定のラベル ID への入力を予測することであり、これには意味情報、微調整された分類タスク、および事前トレーニング タスクが矛盾しており、事前トレーニング タスクから学習された言語モデルを最大限に活用できないため、新しい事前トレーニング済み言語モデルが登場しました。
事前トレーニングされた言語モデルのパラダイムはプロンプト学習と呼ばれます。プロンプトは、事前トレーニングされた言語モデルが人間の問題をよりよく理解するのに役立つ手がかりとして理解できます。具体的には、入力テキストに追加の段落を追加し、この段落でラベルに関連する単語をマスクし、モデルを使用してマスクの位置にある単語を予測し、分類タスクをマスクに変換します。言語モデル.タスクでは、マスク位置で単語を予測した後、多くの場合、その単語をラベル セットにマッピングする必要があります.調達のためのカテゴリ予測は、典型的な小規模サンプル分類問題です.カテゴリ予測タスク用にいくつかのテンプレートが構築されており、マスクは削除され、その部分が予測する必要がある単語になります。
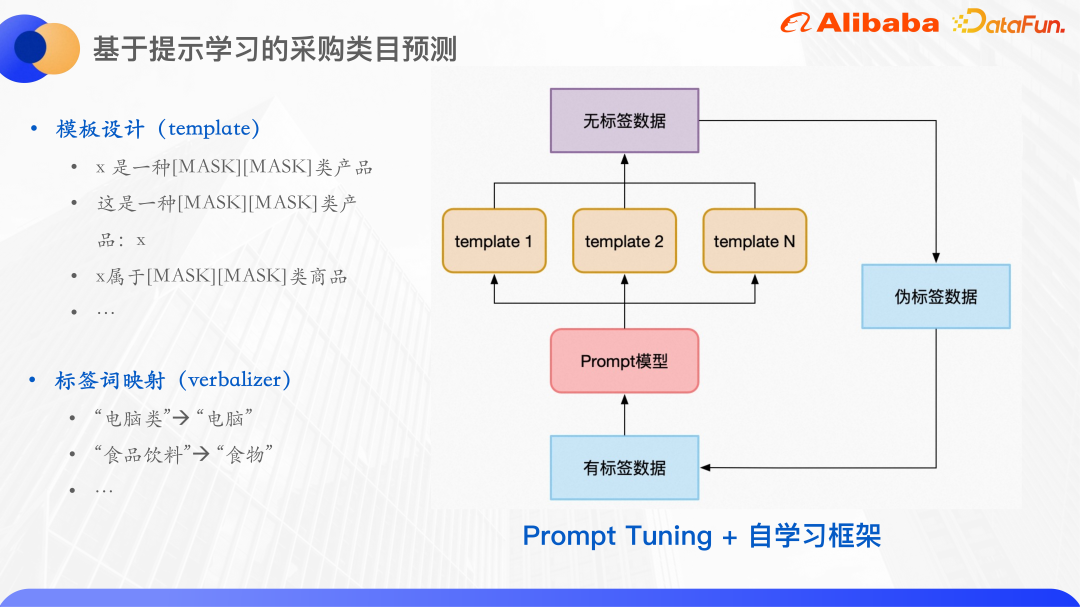
#テンプレートでは、予測単語からラベル単語へのマッピングが確立されます。
#第一に、予測された単語は必ずしもラベルではありません。学習を容易にするため、各サンプルのマスク文字数は同じにしており、元のラベル単語は 3 文字、4 文字などで構成されていますが、ここでは予測単語とラベル単語がマッピングされて 2 文字に統合されています。
さらに、即時学習に基づいて、自己学習フレームワークを使用して、最初にラベル付きデータを使用して各テンプレートのモデルをトレーニングし、次に複数のモデルを統合してラベルなしデータを予測し、1 ラウンドでトレーニングします。 、信頼性の高いサンプルが擬似ラベル データとして選択され、トレーニング セットに追加されることで、より多くのラベル付きデータが取得され、一連のモデルがトレーニングされます。
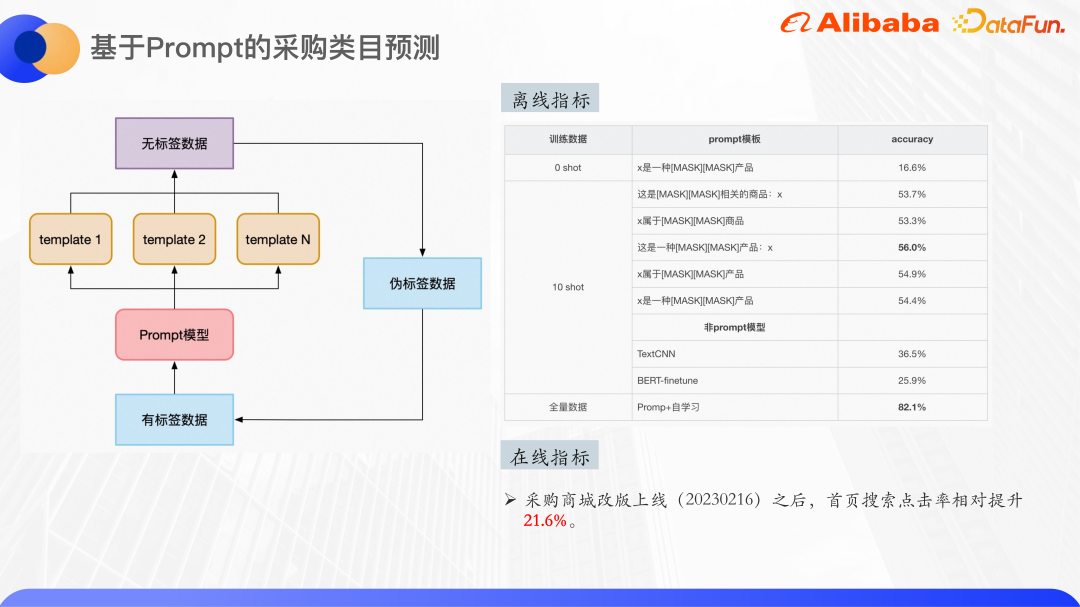
#上の写真は実験結果です。ゼロショットでの分類がわかります。シナリオ 結果として、事前トレーニング済みモデルは Bert ベースを使用し、合計 30 クラスがあり、ゼロショットはすでに 16% の精度を達成できます。 10 ショットのデータセットでトレーニングすると、いくつかのテンプレートで最大精度 56% に達することができ、その改善は明らかであり、テンプレートの選択も結果に一定の影響を与えることがわかります。
同じ 10 ショット データセットを TextCNN と BERT-finetune を使用してテストしました。その効果は、プロンプト学習の微調整の効果よりもはるかに低かったため、プロンプト学習は、小規模なサンプル シナリオで非常に効果的です。
最終的に、全量のデータ、約 4,000 のトレーニング サンプル、および自己学習を使用して、効果は約 82% に達しました。カードしきい値などの後処理をオンラインで追加すると、分類精度が 90% 以上であることを保証できます。
#3. 感想のまとめ

##Enterprise Thereシーンクエリを理解する上での 2 つの大きな問題:
# (1) 不十分なドメイン知識、一般的な短いテキスト理解 ナレッジ グラフは知識の強化に使用されますが、企業シナリオの特殊性により、オープンソースのナレッジ グラフではニーズを満たすことが難しいため、企業内の半構造化データが知識の強化に使用されます。
(2) 企業内の一部の専門分野ではラベル付きデータが非常に少なく、サンプル数は 0 です。サンプル数が少ない シナリオはたくさんある この場合、事前学習モデルにヒント学習を加えたものを考えるのが自然ですが、既存の事前学習で使用したコーパスがそのまま使用されているため、サンプル数が0の場合の実験結果はあまり良くありませんエンタープライズ シナリオのドメイン知識。
# それでは、共通コーパスに基づいた企業内部の垂直分野からのデータを使用して、企業レベルの事前トレーニング済みの大規模モデルをトレーニングすることは可能でしょうか。アリババのATAとして?記事データ、契約データ、コードデータなどを訓練して大規模な事前訓練済みモデルを取得し、プロンプト学習またはコンテキスト学習を使用してテキスト分類、NER、テキストマッチングなどのさまざまなタスクを統合します1 つの言語モデル タスクにまとめます。
さらに、質疑応答 QA や検索などの事実に基づくタスクの場合、生成言語モデルの結果に基づいて回答の正しさをどのように保証するかということも考えなければなりません。
4. Q&A セッション
Q1: アリババが提供する意図認識モデル全体に関連する論文やコードはありますか?
#A1: モデルは自己開発されており、論文やコードはまだありません。
Q2: 現在、クエリおよび同様のクエリではトークン レベルの入力が使用されていますが、取得されたナレッジ カード情報が分類モデルで具体的な数量を使用せず、ID の埋め込みだけが考慮されるのはなぜですか?
A2: クエリおよび同様のクエリはトークン ディメンション レベルの入力を使用し、ナレッジ カードは ID 埋め込みのみを使用します。これは、ナレッジ カード自体の名前を考慮すると、内部的な製品名は、テキストの意味論の観点からは特に意味がありません。これらのナレッジ カードがテキストで記述されている場合、比較的長いテキストにすぎず、ノイズが多すぎる可能性があるため、テキストによる説明は使用されず、このナレッジ カードの ID 埋め込みのみが使用されます。
Q3: プロモートに関する問題については、サンプル数が少ない場合、現在の精度はわずか 16%、10 ショートはわずか 50 です。この場合、エンタープライズアプリケーションにも応用できますが、どのように検討すればよいでしょうか?それともこれに関して何かアイデアはありますか?
A3: 10 ショートは確かに約 50% にすぎません。これは、事前トレーニング済みモデルが調達分野のまれなコーパスをカバーしておらず、パラメーターを使用しているためです。モデル BERT-ベースのデータ量が比較的少ないため、10 ショットの効果はあまり良くありませんが、データ量をすべて使用すると、80% 以上の精度が達成されます。
#Q4: 最後に記載されている企業の事前トレーニングされた大規模モデルに対する回答の正確性についてさらに詳しく教えていただけますか? 関連する内容について詳しく教えていただけますか?
#A4: この領域は現在調査中です。主なアイデアは、強化学習に似たいくつかのアイデアを使用し、言語モデルが生成される前に出力を調整するために人工的なフィードバックを追加することです。
入力後、大規模モデルの出力の背後に前処理を追加します。前処理中に、ナレッジ グラフやその他の知識を追加して、モデルの精度を確保できます。と答える。
以上が知識強化と事前トレーニングされた大規模モデルに基づくクエリ意図認識の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7658
7658
 15
1393
52
91
11
39
156
15
1393
52
91
11
39
156

 画像内の物体検出のために ML データを探索および視覚化する方法
Feb 16, 2024 am 11:33 AM
画像内の物体検出のために ML データを探索および視覚化する方法
Feb 16, 2024 am 11:33 AM
近年、機械学習データ(ML-data)を深く理解することの重要性に対する理解が深まってきています。ただし、大規模なデータ セットの検出には通常、多大な人的および物的投資が必要なため、コンピュータ ビジョンの分野で広く応用するにはさらに開発が必要です。通常、オブジェクト検出 (コンピューター ビジョンのサブセット) では、画像内のオブジェクトは境界ボックスを定義することによって配置されます。オブジェクトを識別できるだけでなく、コンテキスト、サイズ、オブジェクトとシーン内の他の要素との関係も把握できます。関係性も理解できます。同時に、クラスの分布、オブジェクト サイズの多様性、クラスが出現する一般的な環境を包括的に理解することは、評価とデバッグ中にトレーニング モデル内のエラー パターンを発見するのにも役立ちます。
 Power Query で複数の列をドラッグ アンド ドロップで並べ替える方法
Mar 14, 2024 am 10:55 AM
Power Query で複数の列をドラッグ アンド ドロップで並べ替える方法
Mar 14, 2024 am 10:55 AM
この記事では、PowerQuery で複数の列をドラッグ アンド ドロップで並べ替える方法を説明します。さまざまなソースからデータをインポートする場合、列が希望の順序にならないことがよくあります。列の順序を変更すると、分析やレポートのニーズに合った論理的な順序で列を配置できるだけでなく、データの読みやすさが向上し、フィルタリング、並べ替え、計算の実行などのタスクが高速化されます。 Excelで複数の列を並べ替えるにはどうすればよいですか? Excel で列を再配置する方法はたくさんあります。列ヘッダーを選択し、目的の場所にドラッグするだけです。ただし、多くの列を含む大きなテーブルを扱う場合、このアプローチは面倒になる可能性があります。列をより効率的に再配置するには、拡張されたクエリ エディターを使用できます。クエリの強化
 React Query データベース プラグイン: データをインポートおよびエクスポートする方法
Sep 26, 2023 pm 05:37 PM
React Query データベース プラグイン: データをインポートおよびエクスポートする方法
Sep 26, 2023 pm 05:37 PM
ReactQuery データベース プラグイン: データのインポートとエクスポートを実装するためのメソッド、特定のコード サンプルが必要 フロントエンド開発で ReactQuery が広く適用されるようになり、ますます多くの開発者がデータ管理に ReactQuery を使用し始めています。実際の開発では、多くの場合、データをローカル ファイルにエクスポートしたり、ローカル ファイルからデータベースにデータをインポートしたりする必要があります。これらの機能をより便利に実装するには、ReactQuery データベース プラグインを使用できます。 ReactQuery データベース プラグインは一連のメソッドを提供します
 Pythonによるディープラーニング事前学習モデルの詳細説明
Jun 11, 2023 am 08:12 AM
Pythonによるディープラーニング事前学習モデルの詳細説明
Jun 11, 2023 am 08:12 AM
人工知能と深層学習の発展に伴い、事前トレーニング モデルは、自然言語処理 (NLP)、コンピューター ビジョン (CV)、音声認識などの分野で一般的なテクノロジーになりました。現在最も人気のあるプログラミング言語の 1 つである Python は、当然のことながら、事前トレーニングされたモデルの適用において重要な役割を果たします。この記事では、Python のディープラーニング事前トレーニング モデルに焦点を当て、その定義、種類、アプリケーション、事前トレーニング モデルの使用方法について説明します。事前トレーニング済みモデルとは何ですか?深層学習モデルの主な困難は、高品質のデータを大量に分析することです。
 Power Query を使用してデータを NTFS に分割する方法
Mar 15, 2024 am 11:00 AM
Power Query を使用してデータを NTFS に分割する方法
Mar 15, 2024 am 11:00 AM
この記事では、PowerQuery を使用してデータを行に分割する方法を紹介します。他のシステムまたはソースからデータをエクスポートする場合、複数の値を組み合わせたセルにデータが格納される状況がよく発生します。 PowerQuery を使用すると、そのようなデータを行に簡単に分割できるため、データの処理と分析が容易になります。これは、ユーザーが Excel のルールを理解しておらず、誤って複数のデータをセルに入力した場合、または他のソースからデータをコピー/ペーストするときにデータの書式が正しく設定されていない場合に発生する可能性があります。このデータを処理するには、分析またはレポート用の情報を抽出して整理するための追加の手順が必要です。 PowerQuery でデータを分割するにはどうすればよいですか? PowerQuery 変換は、単語などのさまざまな要素に基づいて行うことができます。
 知識強化と事前トレーニングされた大規模モデルに基づくクエリ意図認識
May 19, 2023 pm 02:01 PM
知識強化と事前トレーニングされた大規模モデルに基づくクエリ意図認識
May 19, 2023 pm 02:01 PM
1. 背景 はじめに 近年、エンタープライズデジタル化が注目されており、人工知能、ビッグデータ、クラウドコンピューティングなどの新世代デジタル技術を活用して企業のビジネスモデルを変革し、企業ビジネスの新たな成長を促進することを指します。 。企業のデジタル化には、通常、業務運営のデジタル化と企業管理のデジタル化が含まれます。この共有化では主に企業管理レベルのデジタル化を導入します。情報のデジタル化とは、簡単に言えば、デジタル的な方法で情報を読み取り、書き込み、保存し、送信することを意味します。以前の紙の文書から現在の電子文書やオンラインで共同作業を行う文書に至るまで、情報のデジタル化は今日のオフィスの新たな常態となっています。現在、アリババはビジネス コラボレーションに DingTalk ドキュメントと Yuque ドキュメントを使用しており、オンライン ドキュメントの数は 2,000 万件以上に達しています。さらに、多くの企業は社内で
 React Query データベース プラグイン: データのバックアップと復元の戦略
Sep 28, 2023 pm 11:22 PM
React Query データベース プラグイン: データのバックアップと復元の戦略
Sep 28, 2023 pm 11:22 PM
ReactQuery データベース プラグイン: データのバックアップと復元を実装するための戦略、特定のコード サンプルが必要です はじめに: 最新の Web 開発において、データのバックアップと復元は非常に重要なタスクです。特に ReactQuery のような状態管理ツールを使用する場合は、データのセキュリティと信頼性を確保する必要があります。この記事では、データのバックアップと復元戦略を実装するための ReactQuery に基づくデータベース プラグインを紹介し、具体的なコード例を示します。 ReactQu
 React Query データベース プラグイン: データの圧縮と解凍に関するヒント
Sep 26, 2023 pm 08:03 PM
React Query データベース プラグイン: データの圧縮と解凍に関するヒント
Sep 26, 2023 pm 08:03 PM
ReactQuery データベース プラグイン: データの圧縮と解凍を実装するためのヒント、必要な特定のコード サンプル はじめに: 最新の Web アプリケーション開発では、大量のデータ クエリを処理するのが一般的なタスクです。 ReactQuery は、データのクエリと状態を管理するためのシンプルかつ直感的な方法を提供する強力なライブラリです。 ReactQuery 自体はすでに非常に優れていますが、大量のデータを扱う場合は、パフォーマンスを向上させ、ストレージ領域を最適化するために、いくつかの追加のトリックを考慮する必要がある場合があります。この記事で紹介するのは
