

GPT-4 の 32k 入力ボックスではまだ不十分ですか? Unlimiformer はコンテキストの長さを無限の長さに引き伸ばします

Transformer は、現在最も強力な seq2seq アーキテクチャです。事前トレーニングされたトランスフォーマーには通常、512 (例: BERT) または 1024 (例: BART) トークンのコンテキスト ウィンドウがあり、これは現在の多くのテキスト要約データセット (XSum、CNN/DM) にとって十分な長さです。
ただし、16384 は、本の要約 (Krys-´cinski et al., 2021) や物語などの長い物語を含むタスクの生成に必要なコンテキストの長さの上限ではありません。質疑応答 (Kociskýet al., 2018)、通常は 100,000 を超えるトークンを入力します。 Wikipedia の記事から生成されたチャレンジ セット (Liu* et al.、2018) には、500,000 を超えるトークンの入力が含まれています。生成的質問応答のオープンドメイン タスクでは、Wikipedia 上の存命の著者全員による記事の集合的なプロパティに関する質問に答えるなど、より大きな入力から情報を合成できます。図 1 は、いくつかの一般的な要約データセットと Q&A データセットのサイズを一般的なコンテキスト ウィンドウの長さに対してプロットしたもので、最も長い入力は Longformer のコンテキスト ウィンドウの 34 倍以上の長さです。
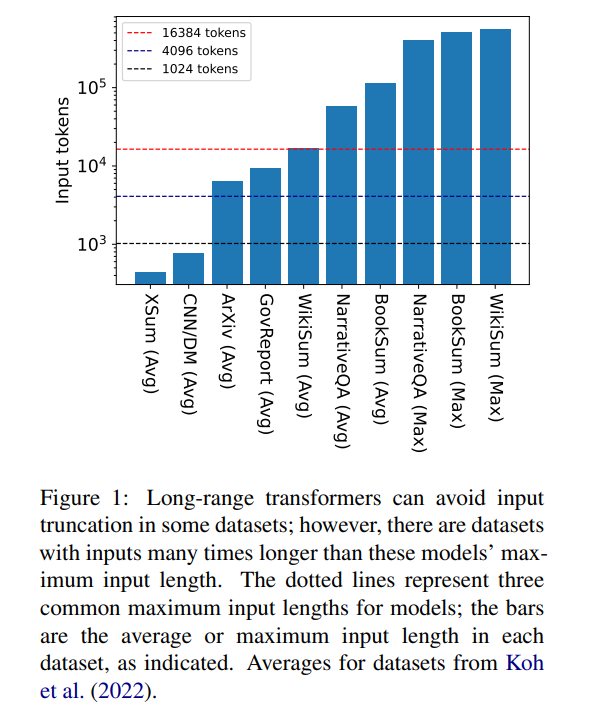
これらの非常に長い入力の場合、ネイティブのアテンション メカニズムは 2 次の複雑さがあるため、バニラ トランスフォーマーはスケーリングできません。長い入力トランスフォーマーは、標準トランスフォーマーよりも効率的ではありますが、依然として大量の計算リソースを必要とし、コンテキスト ウィンドウのサイズが大きくなるにつれて増加します。さらに、コンテキスト ウィンドウを増やすには、新しいコンテキスト ウィンドウ サイズでモデルを最初から再トレーニングする必要があり、計算コストと環境コストがかかります。
記事「Unlimiformer: 無制限の長さの入力を備えた長距離変圧器」で、カーネギー メロン大学の研究者が Unlimiformer を紹介しました。これは、テスト時に無限長の入力を受け入れるために事前トレーニングされた言語モデルを拡張する検索ベースのアプローチです。

論文リンク: https://arxiv.org/pdf/2305.01625v1.pdf
Unlimiformer は既存のエンコーダー/デコーダー トランスフォーマーに挿入でき、無制限の長さの入力を処理できます。長い入力シーケンスを指定すると、Unlimiformer はすべての入力トークンの非表示状態に基づいてデータ ストアを構築できます。デコーダの標準クロスアテンション メカニズムは、データ ストアにクエリを実行し、上位 k 個の入力トークンに焦点を当てることができます。データ ストアは GPU または CPU メモリに保存でき、サブリニアにクエリを実行できます。
Unlimiformer はトレーニングされたモデルに直接適用でき、追加のトレーニングなしで既存のチェックポイントを改善できます。微調整を行うと、Unlimiformer のパフォーマンスがさらに向上します。この論文では、Unlimiformer が重みの追加や再トレーニングを行わずに、BART (Lewis et al., 2020a) や PRIMERA (Xiao et al., 2022) などの複数の基本モデルに適用できることを実証します。さまざまな長距離 seq2seq データセットにおいて、Unlimiformer は、Longformer (Beltagy et al., 2020b)、SLED (Ivgi et al., 2022)、および Memorizing Transformers (Wu et al., 2021) などの長距離 Transformer よりも強力であるだけではありません。 ) これらのデータ セットではパフォーマンスが向上しており、この記事では、Unlimiform を Longformer エンコーダー モデルの上に適用してさらに改善できることもわかりました。
これまでにない技術原理
エンコーダ コンテキスト ウィンドウのサイズが固定されているため、Transformer の最大入力長は制限されています。ただし、デコード中に、異なる情報が関連する可能性があり、さらに、異なる注意が異なる種類の情報に焦点を当てる可能性があります (Clark et al.、2019)。したがって、固定されたコンテキスト ウィンドウでは、あまり注目されていないトークンに労力が無駄になる可能性があります。
各デコード ステップで、Unlimiformer の各アテンション ヘッドはすべての入力から個別のコンテキスト ウィンドウを選択します。これは、デコーダに Unlimiformer ルックアップを挿入することで実現されます。クロスアテンション モジュールに入る前に、モデルは外部データ ストアで k 最近傍 (kNN) 検索を実行し、各デコーダ層で各アテンション ヘッドのセットを選択します。参加するためのトークン。 ###############コーディング######### モデルのコンテキスト ウィンドウの長さよりも長い入力シーケンスをエンコードするために、この記事では、Ivgi et al. (2022) (Ivgi et al., 2022) の方法に従って入力の重複ブロックをエンコードします。エンコード プロセスの前後に十分なコンテキストを確保するために、各チャンクの出力の中央部分のみが保持されます。最後に、この記事では Faiss (Johnson et al., 2019) などのライブラリを使用して、データ ストア内のエンコードされた入力のインデックスを作成します (Johnson et al., 2019)。 強化されたクロスアテンション メカニズムの取得 標準のクロスアテンション メカニズムでは、トランスフォーマーのデコーダがエンコーダーの最終的な隠し状態では、エンコーダーは通常、入力を切り捨て、入力シーケンスの最初の k 個のトークンのみをエンコードします。 この記事では、入力の最初の k 個のトークンだけに焦点を当てているのではなく、クロス アテンション ヘッドごとに、長い入力系列の最初の k 個の隠れ状態を取得し、そのトークンのみに焦点を当てています。最初の k トークン。これにより、キーワードを切り詰めるのではなく、入力シーケンス全体からキーワードを取得できるようになります。また、私たちのアプローチは、すべての入力トークンを処理するよりも計算と GPU メモリの点で安価であり、通常は 99% 以上の注意パフォーマンスを維持します。 図 2 は、この記事による seq2seq トランスフォーマー アーキテクチャへの変更を示しています。完全な入力は、エンコーダーを使用してブロック エンコードされ、データ ストアに保存されます。その後、デコード時に、エンコードされた潜在状態データ ストアがクエリされます。 kNN 検索はノンパラメトリックであり、以下で詳しく説明するように、事前トレーニングされた任意の seq2seq トランスフォーマーに注入できます。 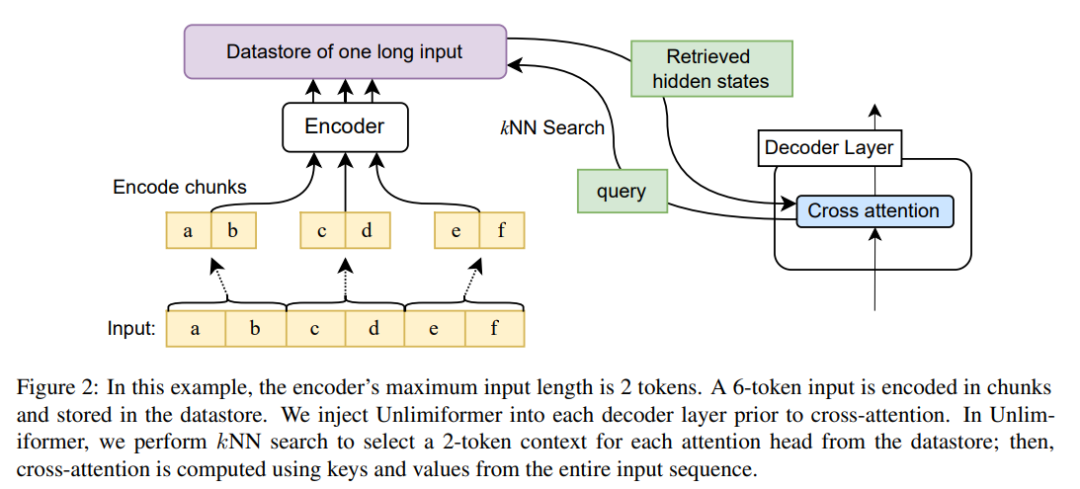
長い文書の概要
表 3 は、長いテキスト (4k および 16k トークン入力) の概要データセットの結果を示しています。
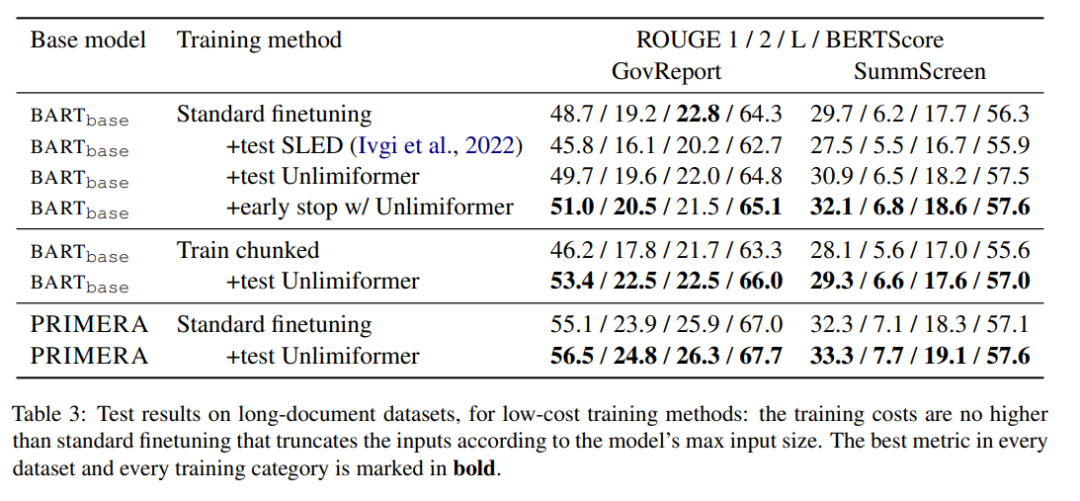
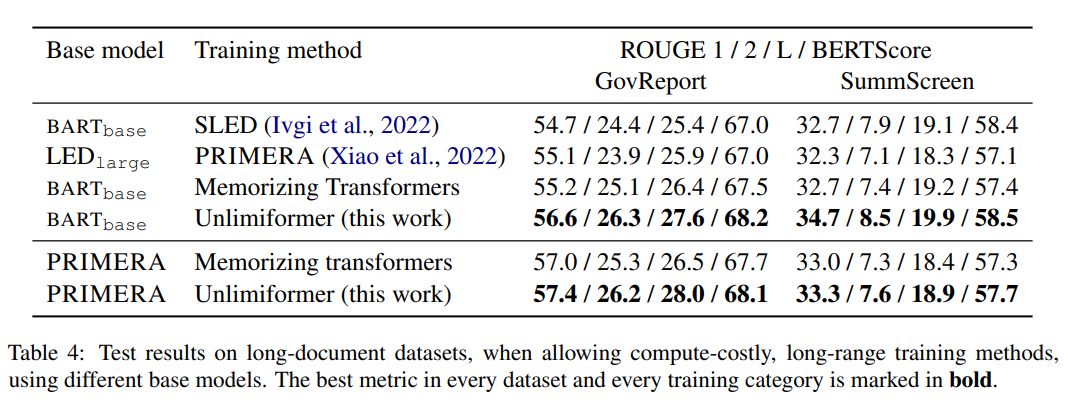
表 4 のトレーニング方法の中で、Unlimiformer はさまざまな指標で最高の結果を達成できます。
#書籍の概要
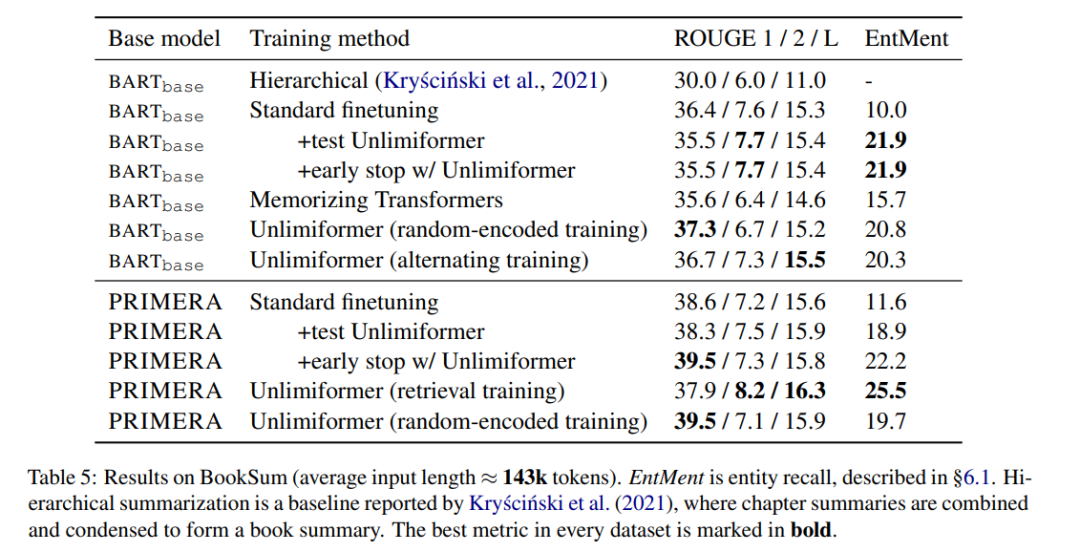
表 5 の表示書籍の要約に関する結果。 BARTbase と PRIMERA に基づいて、Unlimiformer を適用すると一定の改善結果が得られることがわかります。
 #
#
以上がGPT-4 の 32k 入力ボックスではまだ不十分ですか? Unlimiformer はコンテキストの長さを無限の長さに引き伸ばしますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7478
7478
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
MySQLはJSONデータを返すことができます。 json_extract関数はフィールド値を抽出します。複雑なクエリについては、Where句を使用してJSONデータをフィルタリングすることを検討できますが、そのパフォーマンスへの影響に注意してください。 JSONに対するMySQLのサポートは絶えず増加しており、最新バージョンと機能に注意を払うことをお勧めします。
 マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
sqllimit句:クエリ結果の行数を制御します。 SQLの制限条項は、クエリによって返される行数を制限するために使用されます。これは、大規模なデータセット、パジネートされたディスプレイ、テストデータを処理する場合に非常に便利であり、クエリ効率を効果的に改善することができます。構文の基本的な構文:SelectColumn1、column2、... FromTable_nameLimitnumber_of_rows; number_of_rows:返された行の数を指定します。オフセットの構文:SelectColumn1、column2、... FromTable_nameLimitoffset、number_of_rows; offset:skip
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 Prometheus MySQL ExporterでMySQLおよびMariadb液滴を監視します
Apr 08, 2025 pm 02:42 PM
Prometheus MySQL ExporterでMySQLおよびMariadb液滴を監視します
Apr 08, 2025 pm 02:42 PM
MySQLおよびMariaDBデータベースの効果的な監視は、最適なパフォーマンスを維持し、潜在的なボトルネックを特定し、システム全体の信頼性を確保するために重要です。 Prometheus MySQL Exporterは、プロアクティブな管理とトラブルシューティングに重要なデータベースメトリックに関する詳細な洞察を提供する強力なツールです。
 MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLプライマリキーは、データベース内の各行を一意に識別するキー属性であるため、空にすることはできません。主キーが空になる可能性がある場合、レコードを一意に識別することはできません。これにより、データの混乱が発生します。一次キーとして自己挿入整数列またはUUIDを使用する場合、効率やスペース占有などの要因を考慮し、適切なソリューションを選択する必要があります。
 MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
Hash値として保存されているため、Navicatを介してMongoDBパスワードを直接表示することは不可能です。紛失したパスワードを取得する方法:1。パスワードのリセット。 2。構成ファイルを確認します(ハッシュ値が含まれる場合があります)。 3.コードを確認します(パスワードをハードコードできます)。
