

OpenAI が新しいオープンソースの大規模モデルをリリースすることが明らかになりました。

OpenAIがついに「オープン」になりました!
最新のニュースは、彼らが新しいオープンソース言語モデルのリリースを準備しているということです。
GPT-2以来、4年ぶりです。
多くのネチズンが手を突っ込んで期待を表明しました。「彼らは独自のオープンソース代替品をリリースするつもりですか?」
結局のところ、現時点で最良のオープンソース モデルは依然として GPT-4 には程遠いのです。パラメーターだけで言えば、両者の差は 3 桁あり、一方は 200 億、もう一方は 1 兆 3000 億です。

OpenAI は Open になる予定です
この場合、OpenAI の動きは「大規模モデル全体の競争環境を変える」ことになるのでしょうか?
多くのネチズンは、最初に矢面に立たされるのはLLaMAの大型モデルであるアルパカ族ではないかと述べています。
結局のところ、ChatGPT の誕生以来、さまざまなオープンソース ソリューションが際限なく登場してきましたが、そのほとんどは Meta の大規模モデルからインスピレーションを得たものです。
たとえば、スタンフォードの Alpaca、バークレーの Vicuna、Kaola、ColossalChat、さらには国内のハルビン工業大学の LLaMA 微調整モデル Huatuo など、中国の医学的知識に基づいています...これらのオープンソース モデルの一部には、携帯電話での使用にも最適化されています。
カリフォルニア大学バークレー校が作成した大規模モデル Chatbot Arena の最新ランキングは、多くのオープンソース モデルが GPT-4 と Claude のすぐ後に続いていることを示しています。
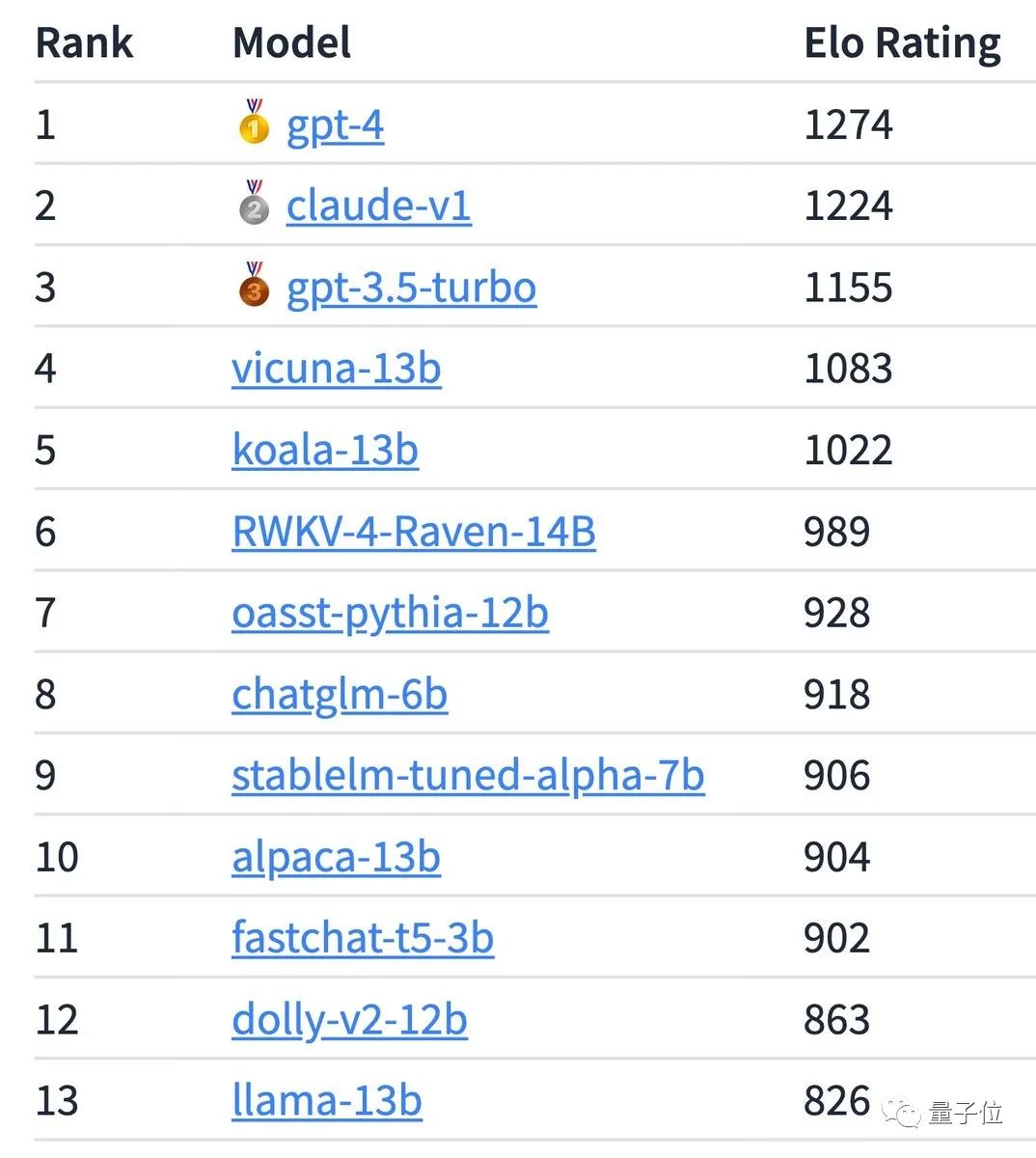
しかし、それが「代替」となるかどうかは、最終リリースまでわかりません。
OpenAI が他の同様のオープンソース モデルと競合するためにこのモデルを使用するかどうかも不明です。
The Information によると、この件に詳しい関係者の話として、この新しいオープンソース モデルが GPT と競合する可能性は低いことは確かです。
同時に、誰かが Google の名前を挙げています。現在、Google はますますプレッシャーにさらされています。

#オープンソースと堀も激しい議論を引き起こしました。
オープンソースと堀
オープンソースかクローズドソースか?これは質問です。#
##少し前に、Google の内部文書がインターネット上で騒動を巻き起こしました。その核心は非常に明確でした:オープンソースの大規模モデルが開発されています急速に、OpenAI と Google の地位を侵食しつつあります。そして、「クローズドソースに対するスタンスが変わらない限り、最終的にはオープンソースの代替手段が(ChatGPTを含む)それらを覆い隠すことになるでしょう。」と述べました。 現時点では、Google も OpenAI も、この大規模なモデル軍拡競争に壕を持っていません。 低電力デバイスでの実行、スケーラブルなパーソナル AI、マルチモダリティなど、多くのオープンソースの問題が解決されています。 現在、OpenAI と Google はモデルの品質において一定の優位性を持っていますが、この差は急速に縮まりつつあります。 過去数週間、オープンソース AI 分野のすべてのチームは、モデルの点でもアプリケーションの点でも継続的に進歩してきました。 たとえば、AI スタートアップの Together は先月、LLaMA に基づいたオープンソースの大規模モデルとクラウド プラットフォームを構築し、現在 2,000 万米ドルのシード資金を調達しています。 この傾向はオフラインでも続いており、多くの人々がオープンソース運動を楽しみ、祝っています。 「オープンソース センター」HuggingFace は、一連の大規模モデル ツールを立ち上げたほか、オフラインでの「Woodstock of AI」集会も開催し、5,000 人以上が集まりました。 Stable Diffusion を開発した Stability AI と、PyTorch Lightning を開発した Lightning AI もオープンソース交流会を開催する予定です。 多くの人の目から見て、OpenAI と Google は悪い前例を作っています。つまり、監視されていないモデルの危険性は現実です。 これらの大手テクノロジー企業のモデルは完全には再現できないかもしれませんが、オープンソース コミュニティはこれらの「秘密のレシピ」の基本的な材料を理解しています。しかし今ではその成分を知る人は誰もいません。 この件についてどう思いますか? 参考リンク:
[1]https://www.reuters.com/technology/openai-readies-new-open-source-ai-model-information-2023-05-15/
[2]https://www.theinformation.com/articles/open-source-ai-is-gaining-on-google-and-chatgpt
[3]https://venturebeat.com/ai/オープンソース AI はビッグテクノロジーとしての祝賀を継続する/堀を巡る検討/
以上がOpenAI が新しいオープンソースの大規模モデルをリリースすることが明らかになりました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7489
7489
 15
1377
52
77
11
19
41
15
1377
52
77
11
19
41

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
AIモデルによって与えられた答えがまったく理解できない場合、あなたはそれをあえて使用しますか?機械学習システムがより重要な分野で使用されるにつれて、なぜその出力を信頼できるのか、またどのような場合に信頼してはいけないのかを実証することがますます重要になっています。複雑なシステムの出力に対する信頼を得る方法の 1 つは、人間または他の信頼できるシステムが読み取れる、つまり、考えられるエラーが発生する可能性がある点まで完全に理解できる、その出力の解釈を生成することをシステムに要求することです。見つかった。たとえば、司法制度に対する信頼を築くために、裁判所に対し、決定を説明し裏付ける明確で読みやすい書面による意見を提供することを求めています。大規模な言語モデルの場合も、同様のアプローチを採用できます。ただし、このアプローチを採用する場合は、言語モデルが
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
FP8 以下の浮動小数点数値化精度は、もはや H100 の「特許」ではありません。 Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考え、Microsoft DeepSpeed チームは NVIDIA からの公式サポートなしで A100 上で FP6 の実行を開始しました。テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化が INT4 に近いか、場合によってはそれよりも高速であり、後者よりも精度が高いことを示しています。これに加えて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeed などの深層学習推論フレームワークに統合されています。この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットの 2.65 倍になります。 1つ
 オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
前に書かれたプロジェクトのリンク: https://nianticlabs.github.io/mickey/ 2 枚の写真が与えられた場合、それらの写真間の対応関係を確立することで、それらの間のカメラのポーズを推定できます。通常、これらの対応は 2D 対 2D であり、推定されたポーズはスケール不定です。いつでもどこでもインスタント拡張現実などの一部のアプリケーションでは、スケール メトリクスの姿勢推定が必要なため、スケールを回復するために外部深度推定器に依存します。この論文では、3D カメラ空間でのメトリックの対応を予測できるキーポイント マッチング プロセスである MicKey を提案します。画像全体の 3D 座標マッチングを学習することで、相対的なメトリックを推測できるようになります。
 OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
ソフトウェア テクノロジの最前線に立つ UIUC Zhang Lingming のグループは、BigCode 組織の研究者とともに、最近 StarCoder2-15B-Instruct 大規模コード モデルを発表しました。この革新的な成果により、コード生成タスクにおいて大きな進歩が達成され、CodeLlama-70B-Instruct を上回り、コード生成パフォーマンス リストのトップに到達しました。 StarCoder2-15B-Instruct のユニークな特徴は、その純粋な自己調整戦略であり、トレーニング プロセス全体がオープンで透過的で、完全に自律的で制御可能です。このモデルは、高価な手動アノテーションに頼ることなく、StarCoder-15B 基本モデルの微調整に応じて、StarCoder2-15B を介して数千の命令を生成します。
