

点平検索関連技術の探求と実践

著者: Xiaoya Shen Yuan Zhudi 他
1. 背景
コメント検索は Dianping App One の中核ですエントランスの充実により、さまざまなシーンでの店舗探しニーズに合わせたライフスタイルサービス加盟店を検索できます。検索の長期的な目標は、検索エクスペリエンスを継続的に最適化し、ユーザーの検索満足度を向上させることです。そのためには、ユーザーの検索意図を理解し、検索語と販売者の相関関係を正確に測定し、関連する販売者を可能な限り表示し、より多くのランク付けを行う必要があります。フォワードに基づいて関連する加盟店。したがって、検索用語と販売者との相関関係の計算はレビュー検索の重要な部分です。
点平の検索シナリオが直面する関連性の問題は複雑かつ多様です。ユーザーの検索用語は、企業名、料理、住所、カテゴリ、およびそれらの間のさまざまな複雑さの検索など、非常に多様です。同時に、加盟店は加盟店名、住所情報、グループ注文情報、料理情報、その他各種施設やラベル情報など複数の情報を保有しているため、Queryと加盟店とのマッチング形態は非常に高くなる。複雑であり、そのようなさまざまな相関関係の問題が発生しやすいです。具体的には、次のタイプに分類できます。
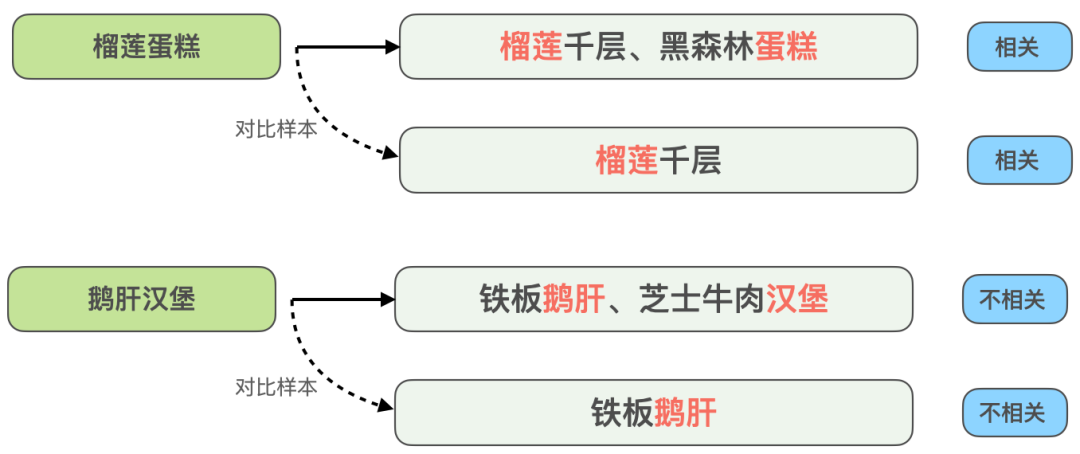
- テキストの不一致: 検索時、より多くの販売者を確実に検索して露出させるため, 図 1(a) に示すように、「牡蠣鍋」を検索するユーザーは、クエリをより細かい単語に分割して取得する可能性があり、販売者のさまざまなフィールドにクエリが一致しないという問題が発生します。鍋には牡蠣が入っており、「牡蠣」と「鍋」はそれぞれ店主の2つの料理に合わせられています。
- セマンティック オフセット: クエリは文字通り販売者と一致しますが、販売者はクエリの主な目的 (「ミルク ティー」 - 「ブラウン」など) と意味的に関連していません。シュガーパールミルクティーの「パッケージ」(図1(b)に示す)。
- カテゴリ オフセット: クエリは文字通り販売者と一致し、意味的に関連していますが、メイン カテゴリはユーザーのニーズと一致しません。たとえば、ユーザーが次のように検索した場合です。 「フルーツプレート」を提供する「フルーツ」KTV 販売業者は、明らかにユーザーのニーズと無関係です。
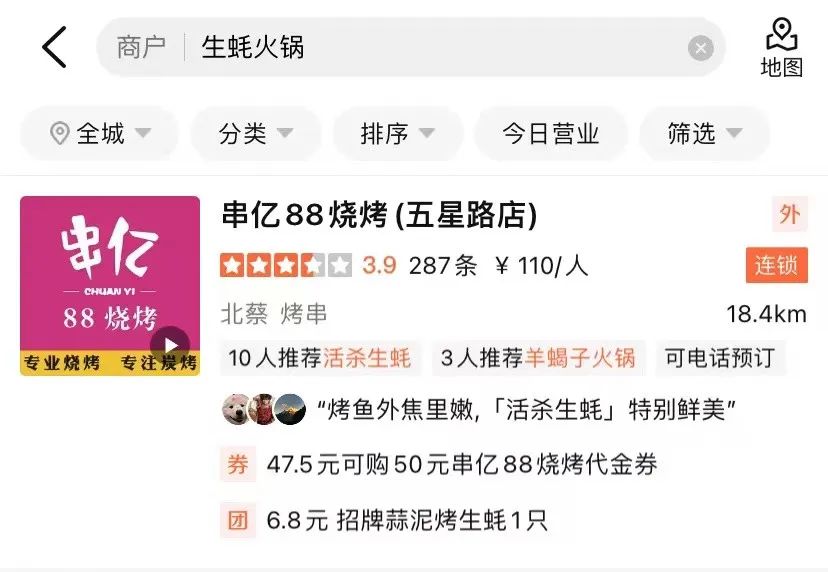
##(a) テキストの不一致の例
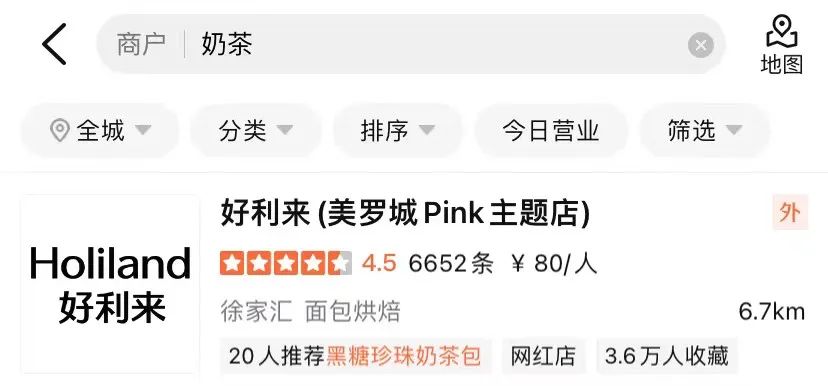
(b) セマンティック オフセットの例
図 1 レビュー検索関連性問題の例
リテラルに基づくマッチング相関法では上記の問題に効果的に対処することができず、ユーザーの意図に沿わない検索リスト内のさまざまな無関係な問題を解決するには、検索語と販売者との間の深い意味的相関関係をより正確に特徴付ける必要があります。この記事は、Meituan の大規模なビジネス コーパスでトレーニングされた MT-BERT 事前トレーニング モデルに基づいて、Dianping 検索シナリオにおけるクエリと販売者 (POI、一般的な検索エンジンの Doc に相当) の深いセマンティクスを最適化します。モデルを作成し、クエリと POI 間の相関情報を検索リンクの各リンクに適用します。
本稿では、既存の検索関連性技術のレビュー、レビュー検索関連性の計算スキーム、実用化、概要と展望の4つの側面からレビュー検索関連性技術を紹介します。点平検索関連性計算の章では、加盟店入力情報の構築、点平検索関連性計算へのモデルの適応、オンラインでのモデルのパフォーマンスの最適化という 3 つの主要な課題をどのように解決するかを紹介し、実用化の章では、オフラインでの開発を紹介します。点評検索関連性モデルとオンライン効果。
2. 検索相関の既存のテクノロジー検索相関の目的は、クエリと返されたドキュメントの間の相関の度合いを計算すること、つまり、クエリ内のコンテンツがドキュメント内のコンテンツであるかどうかを判断することです。 Doc ユーザーのクエリのニーズを満たし、NLP のセマンティック マッチング タスク (Semantic Matching) に対応します。 Dianping の検索シナリオでは、検索の関連性は、ユーザーのクエリと販売者の POI の間の相関関係を計算することです。
テキスト マッチング方法: 初期のテキスト マッチング タスクでは、TF-IDF や BM25 などの用語ベースのマッチング機能を介して、Query と Doc の間のリテラル一致度のみが考慮されていました。 . 相関関係を計算します。リテラル一致相関のオンライン計算効率は高いですが、用語ベースのキーワード一致の一般化パフォーマンスは低く、意味情報と語順情報が欠如しており、単語の複数の意味または 1 つの意味を持つ複数の単語の問題を処理できないため、一致の欠落と誤解 一致現象は深刻です。
従来のセマンティック マッチング モデル: リテラル マッチングの欠点を補うために、Query と Doc の間のセマンティックな相関関係をよりよく理解するために、セマンティック マッチング モデルが提案されています。従来のセマンティック マッチング モデルには、主に暗黙的空間に基づくマッチングが含まれます。つまり、Query と Doc の両方を同じ空間内のベクトルにマッピングし、部分最小二乗 (PLS )# などのベクトルの距離または類似性をマッチング スコアとして使用します。 ##[1]; および翻訳モデルに基づくマッチング: Doc をクエリ空間にマッピングした後にマッチングするか、Doc が Query[2] に翻訳される確率を計算します。
ディープ ラーニング モデルと事前トレーニング モデルの開発に伴い、ディープ セマンティック マッチング モデルも業界で広く使用されています。実装方法に関して、ディープ セマンティック マッチング モデルは、表現ベース (Representation-based) メソッドとインタラクション ベース (Interaction-based) メソッドに分けられます。自然言語処理の分野における効果的な方法として、事前トレーニングされたモデルは意味一致タスクでも広く使用されています。
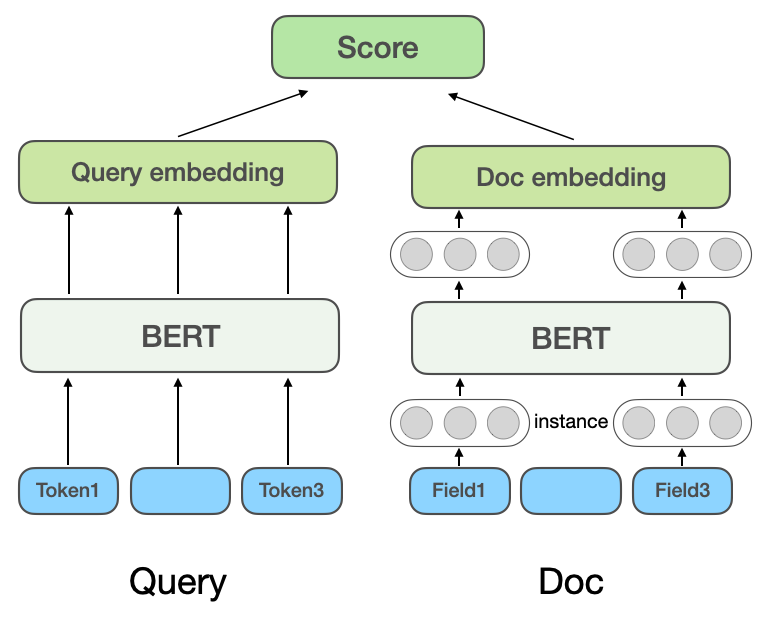
(a) 表現ベースのマルチドメイン相関モデル
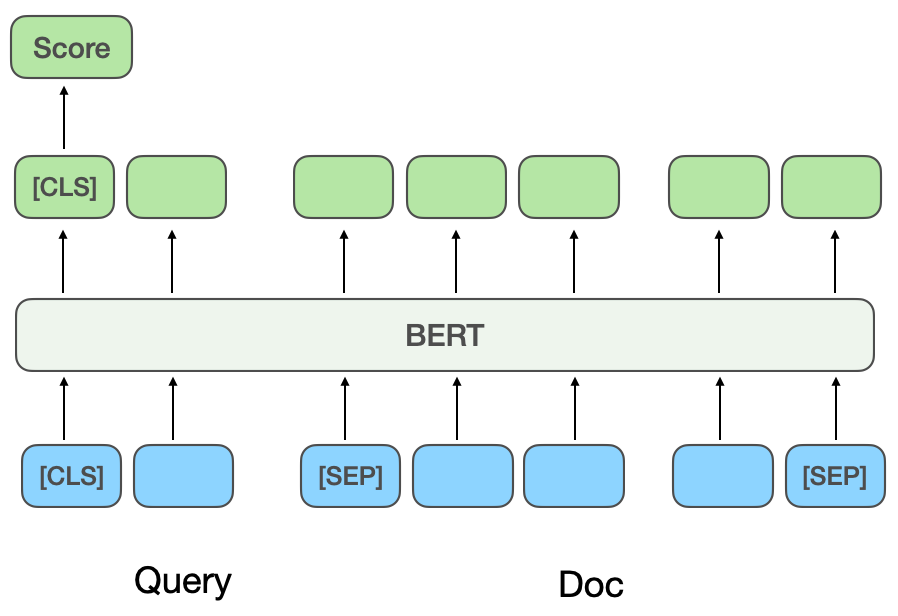
(b) インタラクションベースの相関モデル
図 2 深いセマンティックマッチング相関モデル
表現ベースの深い意味的マッチング モデル: 表現ベースの方法では、Query と Doc の意味ベクトル表現をそれぞれ学習し、2 つのベクトルに基づいて類似性を計算します。 Microsoft の DSSM モデル #[3] は、古典的なツインタワー構造のテキスト マッチング モデルを提案しており、2 つの独立したネットワークを使用して Query と Doc のベクトル表現を構築し、コサイン類似度を使用して 2 つのベクトルを測定します。 。 Microsoft Bing Search の NRM[4] は、ドキュメント表現の問題を対象としています。基本的なドキュメントのタイトルとコンテンツに加えて、他のマルチソース情報も考慮されます (各種類の情報は、フィールド Field ) (外部リンク、ユーザーがクリックしたクエリなど)。ドキュメント内に複数のフィールドがあり、各フィールドに複数のインスタンス (Instance) があると考えてください。各インスタンスは対応します。クエリワードなどのテキストに。モデルは最初にインスタンス ベクトルを学習し、すべてのインスタンス表現ベクトルを集計してフィールド表現ベクトルを取得し、複数のフィールド表現ベクトルを集計して最終的なドキュメント ベクトルを取得します。 SentenceBERT[5]事前トレーニング済みモデル BERT をツイン タワーのクエリとドキュメントのコーディング層に導入し、さまざまなプーリング メソッドを使用してツイン タワーの文ベクトルを取得し、ドット乗算、スプライシングなどを使用します。 . はクエリを実行し、Doc は対話を行います。
Dianping の初期の検索関連性モデルは、NRM と SentenceBERT のアイデアを参考にして、図 2(a) に示す表現ベースのマルチドメイン関連性モデル構造を採用しました。 POI ベクトルを事前に計算してキャッシュに保存することができ、Query ベクトルと POI ベクトルの間の対話部分のみがオンラインで計算されるため、オンラインで使用すると計算速度が速くなります。
インタラクションベースの深いセマンティックマッチングモデル: インタラクションベースの方法は、Query と Doc のセマンティック表現ベクトルを直接学習しませんが、Query が Doc と対話できるようにします。いくつかの基本的な一致信号を確立し、その後、基本的な一致信号を一致スコアにマージします。 ESIM[6] は、事前トレーニング モデルが導入される前に業界で広く使用されていた古典的なモデルです。最初に、Query と Doc がエンコードされて初期ベクトルが取得され、その後、Attention メカニズムが対話型のモデルに使用されます。重み付けを行った後、初期ベクトルと結合し、最後に分類により関連性スコアが得られます。
事前トレーニング済みモデル BERT が対話型計算に導入される場合、通常、Query と Doc は BERT 文間関係タスクの入力として結合され、最終的な相関スコアが計算されます。図 2(b) に示すように、MLP ネットワーク [ 7] を通じて取得されます。 CEDR[8]BERT 文間関係タスクが Query ベクトルと Doc ベクトルを取得した後、Query ベクトルと Doc ベクトルが分割され、Query と Doc のコサイン類似度行列がさらに計算されます。 Meituan 検索チーム [9] は、Meituan 検索相関モデルにインタラクション ベースの手法を導入し、事前トレーニング用に販売者カテゴリ情報を導入し、マルチタスク学習用にエンティティ認識タスクを導入しました。 Meituan 店内検索広告チーム [10] は、クエリを追加しながらパフォーマンスを確保しながら、ツインタワー モデルの仮想インタラクションを実現するために、インタラクション ベースのモデルを表現ベースのモデルに蒸留する方法を提案しました。そしてPOIインタラクション。
3. 検索相関計算の確認
表現ベースのモデルは、POI のグローバルな特性を表現することに焦点を当てており、オンライン クエリと POI の間の一致情報が不足しています。この方法は、表現ベースの方法の欠点を補い、クエリと POI の間の相互作用を強化し、モデルの表現能力を向上させることができます。 -テキスト意味一致タスクのトレーニング済みモデル、レビュー検索相関計算により、Meituan MT-BERT[11] の対話型ソリューションに基づいて事前トレーニング済みモデルが決定されました。事前トレーニングされたモデルに基づくインタラクティブ BERT をレビュー検索シナリオの関連性タスクに適用する場合、まだ多くの課題があります:
- POI サイド モデルをより適切に構築する方法入力情報: ドキュメント側モデルの入力情報の構築は、相関モデルにおける重要なリンクです。一般的な Web 検索エンジンでは、Doc という Web ページのタイトルは関連性を判断する上で非常に重要です。しかし、レビュー検索シナリオでは、POI 情報は多くの分野の特性を持ち、複雑な情報を持っています。「」と同様の情報を提供できるフィールドはありません。ウェブページのタイトル」。各販売者は、販売者名、カテゴリ、住所、グループ順序、販売者タグなどのさまざまな構造化情報を通じて表現されます。関連性スコアを計算する場合、マルチソースの販売者情報を大量にモデルに入力することはできず、販売者名やカテゴリなどの基本情報のみを使用した場合、情報不足により満足のいく結果を得ることができません。豊富な情報を含む構造? POI 側のモデル入力が、私たちが解決したい主な問題です。
- 点平検索関連性の計算に適切に適応するためにモデルを最適化する方法: 点平検索シナリオのテキスト情報と一般的な点にはいくつかの違いがあります。たとえば、一般的な意味シナリオでは「ハッピー」と「ハッピー」は同義語ですが、レビュー検索シナリオでは、「ハッピー バーベキュー」と「ハッピー バーベキュー」はまったく異なるブランドになります。 。同時に、クエリと POI の相関判定ロジックは、一般的な NLP シナリオのセマンティック マッチング タスクとまったく同じではありません。クエリと POI のマッチング モードは非常に複雑です。クエリが POI の異なるフィールドに一致する場合、相関判定はたとえば、クエリ「フルーツ」が販売者カテゴリ「果物屋」に一致する場合は相関が高くなりますが、KTV の「フルーツ盛り合わせ」タグに一致する場合は相関が低くなります。したがって、一般的な対話ベースの BERT 文間関係意味論的一致タスクと比較して、相関計算では、クエリ部分と POI 部分の間の特定の一致にも注意を払う必要があります。レビュー検索シナリオに適応するようにモデルを最適化し、複雑で多様な関連性判断ロジックを処理し、無関係なさまざまな問題を可能な限り解決する方法が、私たちが直面する主な課題です。
- 事前トレーニング済み相関モデルのオンライン パフォーマンスのボトルネックを解決する方法: 表現ベースのモデルは計算速度が速いものの、表現力に限界があります。 -ベースのモデルは強化可能 クエリと POI の間の相互作用によりモデルの効果が向上しますが、オンラインで使用すると大きなパフォーマンスのボトルネックが発生します。したがって、12層BERTインタラクションベースのモデルをオンラインで使用する場合、コンピューティングリンク全体のパフォーマンスを確保しながら、モデルの計算効果をいかに確保し、オンラインで安定かつ効率的に実行できるかが、オンラインアプリケーションの最後のハードルとなります。相関計算の。
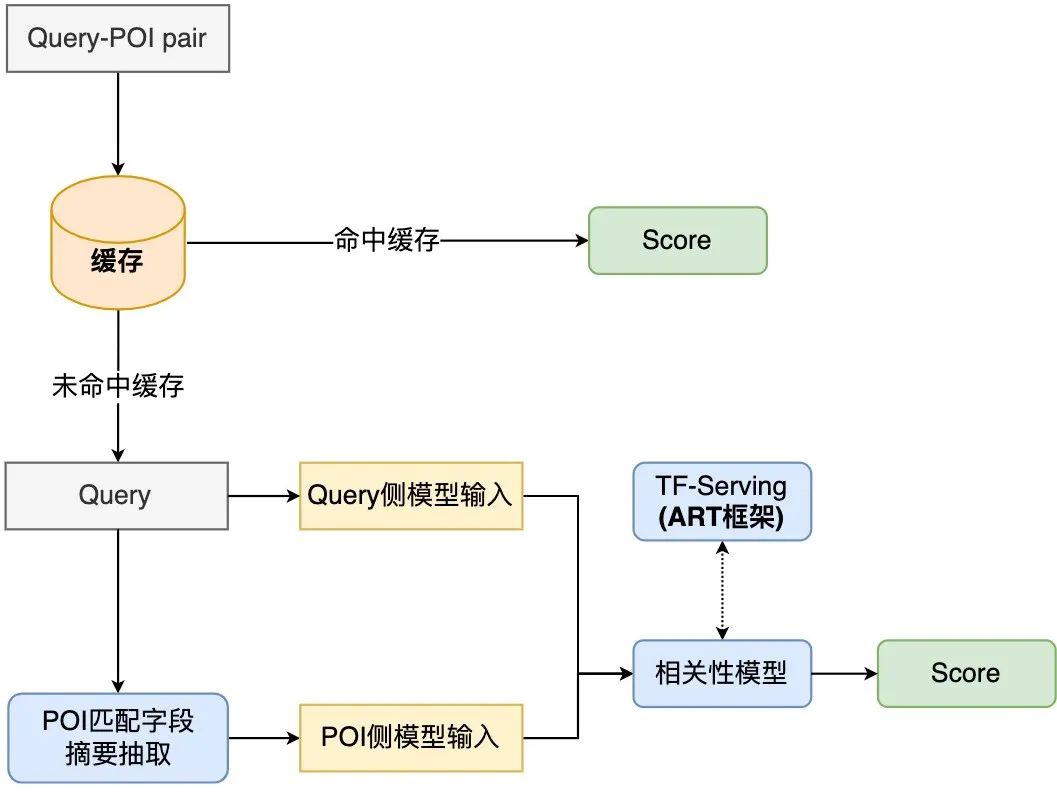
継続的な調査と実験の後、POI 側の複雑なマルチソース情報のレビュー検索シナリオに適応した POI テキストの概要を構築しました。点平検索相関計算では、2 段階のトレーニング方法が採用され、相関計算の特性に応じてモデル構造が変換され、最終的に、計算プロセスの最適化、キャッシュなどの手段の導入により、リアルタイム計算とモデル全体のアプリケーション リンクの時間が短縮され、BERT のオンライン リアルタイム計算のパフォーマンス要件を満たしました。
3.1 POI 側モデルの入力情報をより適切に構築する方法
クエリと POI の間の相関関係を判断する場合、POI 側には十数個のフィールドがあります。特定のフィールドには多くのコンテンツがあるため (たとえば、販売者には数百のおすすめ料理がある場合があります)、POI のサイド情報を抽出して整理する適切な方法を見つける必要があります。そしてそれを相関モデルに入力します。一般的な検索エンジン (Baidu など)、または一般的な垂直型検索エンジン (Taobao など) では、ドキュメントの Web タイトルまたは製品タイトルには、通常、プロセス中に豊富な情報が含まれています。関連性を判断するための Doc 側モデル入力の主な内容。
図3(a)に示すように、一般的な検索エンジンでは、検索結果のタイトルから、該当するWebサイトの重要な情報とクエリに関連するかどうかが一目でわかります。図3(b)点評 アプリの検索結果では、加盟店名フィールドだけでは十分な加盟店情報が得られず、加盟店カテゴリ(ミルクティージュース)とユーザーを組み合わせる必要があります。推奨料理 (olioli milktea)、タグ (网有名店)、住所 (武林広場)、およびクエリに対する販売者の関連性を判断するための複数のフィールド「武林広場インターネットセレブミルクティー」。
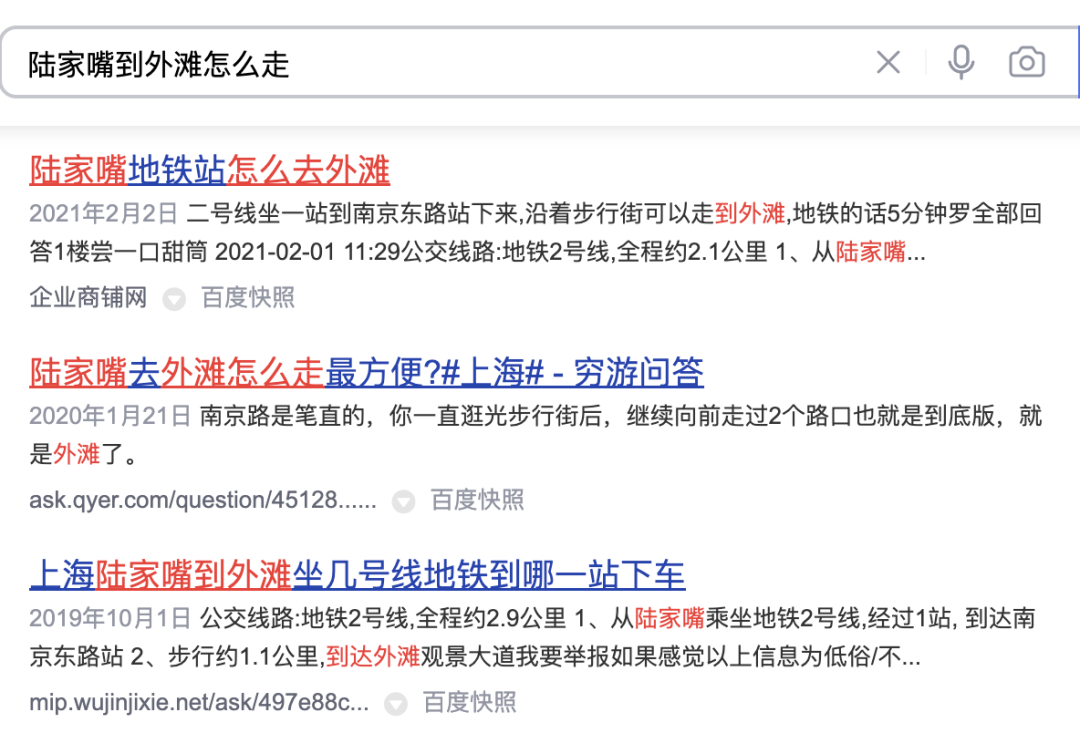
#(a) 一般的な検索エンジンの検索結果の例
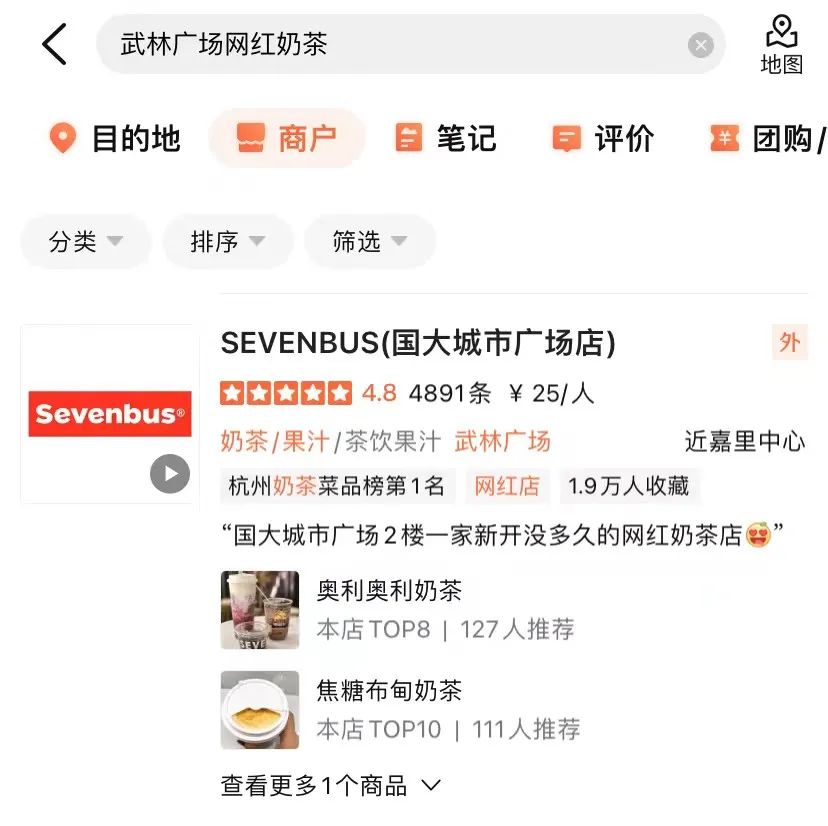
# #(b) 点平アプリの検索結果の例
図 3 一般的な検索エンジンと点平の検索結果の比較
#タグ抽出は業界で一般的なトピック情報抽出方法であるため、まず加盟店タグによるPOI側のモデル入力方式の構築を試み、加盟店のコメント、基本情報、料理、メニューなどからクリックワードを検索しました。販売者の対応するヘッダーなど。代表的な販売者のキーワードを販売者タグとして抽出します。オンラインで利用する場合は、抽出した加盟店タグ、加盟店名、カテゴリの基本情報をモデルのPOI側の入力情報として利用し、Queryで対話型の計算を行います。しかし、加盟店タグによる加盟店情報の網羅性はまだ十分ではなく、例えば、ユーザーが「茶碗蒸し」という料理を検索すると、ユーザーの近くの韓国料理店では茶碗蒸しが売られているのに、その店の看板メニューである「茶碗蒸し」がヒットしてしまう。単語は「茶碗蒸し」と関連性がなく、その結果、店舗が抽出したラベル単語も「茶碗蒸し」との相関が低いため、モデルは店舗が無関係であると判断し、ユーザーエクスペリエンスに悪影響を及ぼします。最も包括的な POI 表現を取得するには、キーワードを抽出せずに販売者のすべてのフィールドをモデル入力に直接接続することが 1 つの解決策ですが、この方法では次のような問題が発生します。長すぎると、オンラインのパフォーマンスに重大な影響を及ぼし、大量の冗長な情報もモデルのパフォーマンスに影響を与えます。
より有益な POI サイド情報をモデル入力として構築するために、
POI マッチング フィールド サマリ抽出メソッドを提案しました。つまり、オンライン クエリ マッチングと組み合わせたものです。 POIの一致フィールドテキストがリアルタイムに抽出され、POI側モデル入力情報として一致フィールドのサマリが構築されます。 POI 一致フィールドの概要抽出プロセスを図 4 に示します。いくつかのテキスト類似性特徴に基づいて、クエリに最も関連性が高く情報量の多いテキスト フィールドを抽出し、フィールド タイプ情報を統合して一致フィールドの概要を構築します。オンラインで利用する場合、抽出したPOIマッチングフィールド概要、加盟店名、カテゴリ基本情報をPOI側モデルとして入力します。
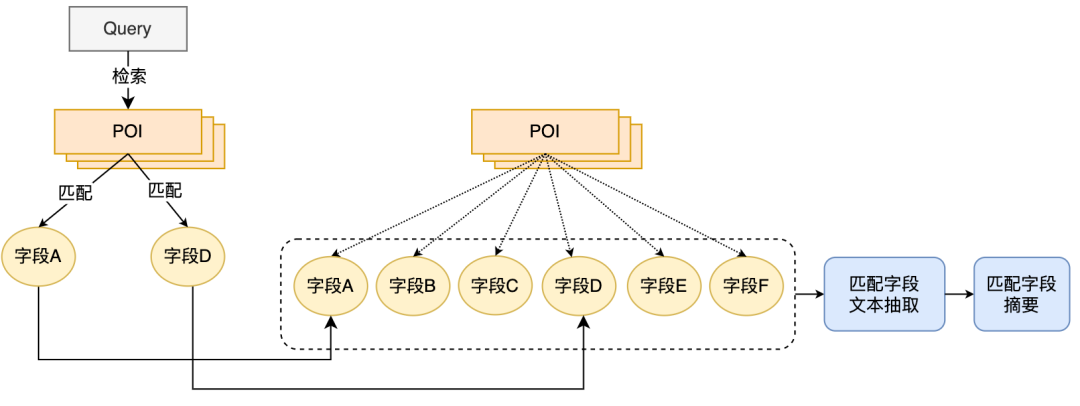
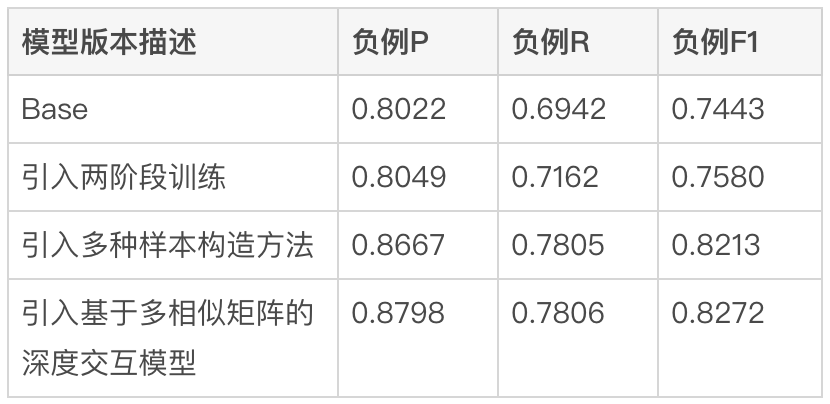
POI 側のモデル入力情報を決定した後、BERT 文間を使用します。関係タスクでは、まず MT-BERT を使用してクエリ側と POI 側で一致するフィールド概要情報をエンコードし、次にプールされた文ベクトルを使用して相関スコアを計算します。 POI マッチング フィールド サマリー スキームを使用して POI サイド モデルを構築し、情報を入力した後、サンプル反復と組み合わせると、モデルの効果はラベルベースの方法と比較して大幅に向上しました。 3.2 レビュー検索の関連性計算に適切に適応するためにモデルを最適化する方法
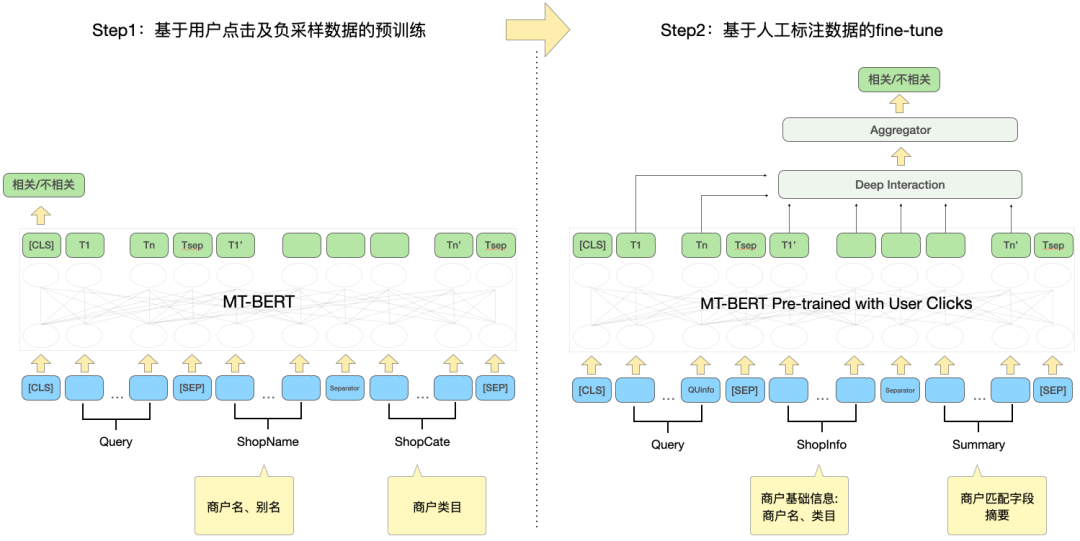
レビュー検索の関連性計算タスクにモデルをより適切に適応させるには、2 つのレベルの意味が含まれます: 点平検索シナリオのテキスト情報と MT-BERT 事前学習モデルで使用されるコーパスとの間の分布には特定の違いがあり、事前学習モデルの文間関係タスクも相関タスクとは若干異なります。クエリと POI のモデル構造の変更が必要です。継続的な調査の後、事前トレーニング モデルをレビュー検索シナリオの関連性タスクにより適したものにするために、ドメイン データに基づく2 段階トレーニング スキームをトレーニング サンプル構造と組み合わせて採用し、提案しました。 多重類似性に基づくマトリックスの深い対話型相関モデルは、クエリとPOIの間の相互作用を強化し、複雑なクエリとPOI情報を表現するモデルの能力を向上させ、相関計算効果を最適化します。 ユーザーのクリック データを効果的に利用し、事前トレーニング済みモデル MT-BERT をレビュー検索関連性タスクにより適したものにするために、 Baidu 検索から学びます相関[12]の考えに基づいて、ユーザーのクリックとネガティブサンプリングデータを使用してドメインの最初の段階の事前トレーニングを行う多段階トレーニング方法が導入されています適応 (継続的ドメイン適応型事前トレーニング) では、トレーニングの第 2 段階 (Fine-Tune) に手動でラベル付けされたデータを使用します。モデル構造は、以下の図 5 に示されています。 ##図 5 クリックおよび手動アノテーション データに基づく 2 段階のトレーニング モデル構造 クリック データに基づく第 1 段階のトレーニング クリック データを第 1 段階のトレーニング タスクとして導入する直接の理由は、レビュー検索シナリオにいくつかの固有の問題があるためです。たとえば、一般的なシナリオでは、「ハッピー」と「ハッピー」という単語はほぼ完全に同義語ですが、レビュー検索シナリオでは、「ハッピー BBQ」と「ハッピー BBQ」はまったく異なるブランド販売者であるため、クリック データの導入モデルが検索シナリオで固有の知識を学習するのに役立ちます。ただし、クリックサンプルを直接相関判定に使用すると、上位にあるため誤ってクリックしてしまう可能性や、遠方にあるためクリックしない可能性があり、ノイズが多くなります。相関関係の問題が原因ではないため、トレーニング サンプルの自動アノテーションの精度を向上させるために、さまざまな機能とルールを導入しました。 サンプル構築時は、クリックの有無、クリック位置、最大クリックマーチャントとユーザーとの距離などをカウントし、クエリを用いて候補サンプルを選別します。 - クリック率が一定の閾値を超えるPOIを公開 これをポジティブな例として使用し、ビジネスの特性に基づいてマーチャントの種類ごとに異なる閾値を調整します。ネガティブ サンプルの構造に関して、Skip-Above サンプリング戦略では、クリックされた販売業者の前に位置し、クリック率がしきい値未満の販売業者をネガティブ サンプルとして使用します。さらに、ランダムネガティブサンプリング法は、単純なネガティブサンプルでトレーニングサンプルを補うことができますが、ランダムネガティブサンプリングを考慮すると、いくつかのノイズデータも導入されるため、人為的に設計されたルールを使用してトレーニングデータのノイズを除去します。 POI のカテゴリ システムが比較的一貫しているか、POI 名と高度に一致する場合、その施設はネガティブ サンプルから除外されます。 #人工的にラベル付けされたデータに基づくトレーニングの第 2 段階 1) 難しいサンプルマイニング コントラスト サンプルの強化: 対照学習のアイデアを活用し、データ強化のために一致度の高いサンプルのコントラスト サンプルを生成します。手動アノテーションを実行する サンプルラベルの精度を確認します。サンプル間の違いを比較することで、モデルは真に有用な情報に焦点を当て、同義語の汎化能力を向上させ、より良い結果を達成できます。 #図 6 比較サンプル拡張例 相互相関問題を解決するには、料理マッチング 例えば、上図6のように、クエリを分割して販売者の複数のおすすめ料理フィールドにマッチングする場合もあり、クエリ「ドリアンケーキ」は、おすすめ料理「ドリアンサウザンドクレープ、シュヴァルツヴァルト」と関連付けられている「ケーキ」ですが、クエリ「フォアグラ バーガー」と「熱々のフォアグラ、チーズビーフ バーガー」は関連しません。このタイプの非常に一致しているが反対の結果を識別するモデルの能力を強化するために、「ドリアン ケーキ」と「」を構築しました。ドリアンミルフィーユ「 」、「フォアグラバーガー」、「熱々フォアグラ」の 2 つの比較サンプルです。クエリテキストと一致するが、モデルの判断に役に立たない情報は削除され、モデルがキーを学習できるようになります。同時に、「ケーキ」や「千層」などの同義語に対するモデルの汎化能力も向上します。同様に、他の種類の難しいサンプルでも、このサンプル強調方法を使用して効果を向上させることができます。 BERT 文間関係は一般的な NLP タスクであり、2 つの文間の関係を判断するために使用されます。相関タスクは、クエリと POI の間の相関を計算することです。計算プロセス中、文間関係タスクはクエリと POI の間の相互作用を計算するだけでなく、クエリ内および POI 内の相互作用も計算しますが、相関計算ではクエリと POI の間の相互作用により注意が払われます。さらに、モデルの反復プロセス中に、テキストが高度に一致しているが無関係であるタイプなど、一部の難易度 BadCase ではモデルの表現能力に対する要件が高いことがわかりました。したがって、複雑なクエリおよび POI 相関タスクに対するモデルの計算効果をさらに向上させるために、トレーニングの第 2 段階で BERT 文間関係タスクを変換し、複数の類似性行列に基づく深い相互作用モデルを提案しました。マトリックスはクエリと POI の間の詳細なインタラクションを実行するために使用され、インジケーター マトリックスは困難な BadCase 問題をより適切に解決するために導入されています。モデル構造は以下の図 7 に示されています: 図 7 複数の類似性行列に基づく深い相互相関モデル CEDR[8] からインスピレーションを得て、クエリ ベクトルと POI ベクトルの分割をエンコードすることは、2 つの部分間の詳細なインタラクション関係を明示的に計算するために使用されます。クエリ ベクトルと POI ベクトルを分割し、詳細なインタラクションを実行することは、特にクエリと POI の間の相関関係を学習するために使用できます。一方、パラメータの数が増えると、モデルのフィッティング能力が向上します。 MatchPyramid[13] モデルを参照すると、深い相互相関モデルは 4 つの異なる Query-Doc 類似性行列を計算し、それらを融合します。積、コサイン距離、およびユークリッド距離であり、POI 部分の出力でアテンションの重み付けが行われます。インジケーター マトリックスは、クエリのトークンと POI が一致しているかどうかを記述するために使用され、計算方法は次のとおりです。マッチング行列の行と列に対応する要素、クエリを表すトークン、および POI を表すトークン。 Indicator行列はQueryとPOIが文字通り一致するかどうかを示す行列であるため、他の3つの意味的一致行列の入力形式は異なり、内積、コサイン距離、ユークリッド距離の3つの一致行列が最初に融合されます。 、得られた結果が指標行列と結合され、最終的な相関スコアを計算する前に行列がさらに融合されます。 インジケーター マトリックスは、クエリと POI の間の一致関係をより適切に説明できます。このマトリックスの導入は主に、クエリと POI の間の相関の程度を決定する難しさを考慮しています。テキストが高度に一致している場合でも、場合によっては、 、この2つは無関係です。インタラクションベースの BERT モデル構造により、テキスト一致度の高いクエリと POI の関連性を判断しやすくなりますが、レビュー検索シナリオでは、これが当てはまらない場合があります。たとえば、「豆ジュース」と「緑豆ジュース」は一致度が高くなりますが、関連性はありません。 「猫空」と「猫空城」は別の試合ですが、前者は後者の略称なので関連性があります。したがって、さまざまなテキスト マッチング状況がインジケーター マトリックスを通じてモデルに直接入力され、モデルが「含む」や「分割マッチング」などのテキスト マッチング状況を明示的に受け取ることができるようになり、モデルが困難なケースを区別する能力を向上させるだけでなく、だけでなく、ほとんどの通常のケースのパフォーマンスにも影響します。 複数の類似度マトリックスに基づく深い対話型相関モデルは、クエリと POI を分割してから類似度マトリックスを計算します。これは、モデルがクエリや POI と明示的に対話できるようにするのと同じで、関連するタスクを一致させます。複数の類似性マトリックスにより、クエリと POI の間の相関関係を計算する際のモデルの表現能力が向上します。一方、インジケーター マトリックスは相関タスクにおける複雑なテキストの一致状況向けに特別に設計されており、無関係な結果に対するモデルの判断がより正確になります。 相関計算をオンラインで展開する場合、既存のソリューションは通常、知識蒸留構造のツインタワーを使用します [10,14] はオンライン計算の効率を確保するために使用されますが、この処理方法はモデルの効果に多かれ少なかれ悪影響を及ぼします。検索相関計算の確認 モデルの効果を確実にするために、インタラクションに基づく 12 層 BERT の事前トレーニング済み相関モデルがオンラインで使用されます。これには、12 層 BERT モデルによって予測される各クエリの下の数百の POI が必要です。オンラインコンピューティングの効率を確保するために、モデルのリアルタイムコンピューティングプロセスとアプリケーションリンクの2つの観点から開始し、キャッシュメカニズムの導入、モデル予測の高速化、フロントエンドゴールデンルールレイヤーの導入、相関計算とコアソートの並列化によって最適化しました。オンラインで展開された場合の相関モデルのパフォーマンス ボトルネックにより、12 層のインタラクション ベースの BERT 相関モデルがオンラインで安定かつ効率的に実行できるようになり、数百の販売業者と Query の間の相関計算を確実にサポートできるようになります。 図 8 相関モデルのオンライン計算フローチャート レビュー検索相関モデルのオンライン計算プロセスを図 8 に示します。キャッシュ メカニズムと TF-Serving モデルの予測アクセラレーションを使用して、モデルのリアルタイム計算のパフォーマンスを最適化します。 コンピューティング リソースを効果的に利用するために、モデルのオンライン展開では、高頻度クエリの相関スコアをキャッシュに書き込むキャッシュ メカニズムが導入されています。以降の呼び出しでは、最初にキャッシュが読み取られ、キャッシュにヒットした場合はスコアが直接出力され、キャッシュにヒットしなかった場合はオンラインでリアルタイムにスコアが計算されます。キャッシュ メカニズムにより、コンピューティング リソースが大幅に節約され、オンライン コンピューティングのパフォーマンスのプレッシャーが効果的に軽減されます。 キャッシュが見つからないクエリの場合は、クエリ側のモデル入力として処理し、図 4 で説明されているプロセスを通じて各 POI の一致するフィールドの概要を取得し、POI として処理します。 -side model 形式を入力し、オンライン相関モデルを呼び出して相関スコアを出力します。相関モデルは TF-Serving にデプロイされ、モデル予測中に Meituan 機械学習プラットフォームのモデル最適化ツール ART フレームワークが使用されます (Based on Faster-Transformer[15]改善 ). アクセラレーションにより、精度を確保しながらモデルの予測速度が大幅に向上します。 図 9 レビュー検索リンクにおける相関モデルの適用 検索リンクにおける相関モデルの適用は、上の図 9 に示されています。プレゴールデン ルールを導入し、相関計算をコア並べ替えレイヤーと並列化することにより、検索リンク全体のパフォーマンスが最適化されます。 相関呼び出しリンクをさらに高速化するために、クエリを迂回するプレゴールデン ルールを導入し、一部のクエリのルールを通じて相関スコアを直接出力することで、モデルの計算を容易にしました。プレッシャー。ゴールデン ルール レイヤーでは、テキスト マッチング機能を使用してクエリと POI を判定します。たとえば、検索語と販売者名が完全に一致する場合、相関関係を計算することなく、ゴールデン ルール レイヤーを通じて「関連」判定が直接出力されます。相関モデルによるスコア。 全体計算リンクでは、相関計算プロセスとコア並べ替え層が同時に実行され、相関計算が検索リンク全体の時間に基本的に影響を与えないようにします。アプリケーション層では、相関計算は検索リンクの想起や並べ替えなどのさまざまな側面で使用されます。検索リストの最初の画面に表示される無関係な販売者の割合を減らすために、リスト ページを並べ替えるための LTR 多目的フュージョン ソートに関連性スコアを導入し、多方向リコール フュージョン戦略を採用しました。相関モデルの補足リコール パスに関連するマーチャントのみがリストにマージされます。 モデルの反復によるオフライン効果を正確に反映するために、複数のラウンドを通じてモデルを構築しました。バッチベンチマークでは、現在のオンラインでの実際の利用における主な目標がBadCase指標を減らすこと、つまり無関係な加盟店を正確に特定することであることを考慮し、精度、再現率、否定例のF1値を測定指標として使用します。 2 段階のトレーニング、サンプル構築、およびモデルの反復によってもたらされる利点を、以下の表 1 に示します。 #表 1 検索相関モデルの反復のレビューオフライン インジケーター 最初のメソッド (Base) は、クエリを使用して、BERT 文ペア分類タスクの POI 一致フィールドの概要情報を結合します。クエリ側モデルの入力は、ユーザーが入力したオリジナルのクエリ POI 側では、販売者名、販売者カテゴリ、および一致するフィールドの概要のテキスト結合方法を採用しています。クリックデータに基づく2段階トレーニングの導入後、比較サンプルと困難なサンプルサンプルを導入してトレーニングサンプルを継続的に反復し、第2段階のモデル入力構造と連携することにより、負のサンプルF1インデックスはBaseメソッドと比較して1.84%増加しました。 , Base 手法と比較した負の例 F1 インデックスは 10.35% の大幅な改善でしたが、複数の類似度行列に基づく深い相互作用手法の導入後、負の例 F1 は Base と比較して 11.14% 改善されました。ベンチマーク上のモデルの全体的な指標も、AUC 0.96、F1 0.97 という高い値に達しました。 ユーザーの検索満足度を効果的に測定するために、Dianping Search は実際のオンライン トラフィックを毎日サンプリングし、最初の画面で BadCase を使用して手動で注釈を付けます。相関モデルの有効性を評価するための中心的な指標としてのリストのページ率。相関モデルの開始後、点評検索の月間平均 BadCase 率指標は、開始前と比較して 2.9pp (パーセント ポイント、パーセント絶対ポイント ) 大幅に低下し、BadCase 率指標は低い水準で安定しました。同時に、検索リスト ページの NDCG 指標も着実に 2pp 増加しました。相関モデルにより、無関係な販売者を効果的に特定し、検索の最初の画面で無関係な問題の割合を大幅に削減できるため、ユーザーの検索エクスペリエンスが向上することがわかります。 以下の図 10 は、オンライン BadCase ソリューションの例をいくつか示しています。サブタイトルは例に対応するクエリです。左側は相関モデルを適用した実験グループ、右側ははコントロールグループです。図 10(a) では、検索語が「Pei Jie」の場合、相関モデルはコアワードに「Pei Jie」を含む販売者「Pei Jie Famous Products」が関連していると判断し、ユーザーが好む高級品を選択します。探したいのに入力が間違っている場合、品質対象の販売者「Pei Jie Lao Hot Pot」も関連すると判断されます。同時に、住所フィールド識別子を導入することにより、住所の「Pei Jie」の隣にある販売者も該当すると判断されます。図 10(b) では、ユーザーはクエリ「Youzi Ri "Self-service Food" が "Yuzu" という名前の日本食セルフサービス店を見つけたいと考えています。相関モデルは、分割された単語と一致します。」ゆず関連商品を販売する和食セルフサービス店「竹和子まぐろ」を無関係と正しく判断しランク付けし、最終的に上位に表示される加盟店は、よりユーザーのニーズに沿った加盟店であることを保証します。主なニーズ。 #(a) シスター・ペイ この記事では、点評検索相関モデルの技術的ソリューションと実際の応用について紹介します。販売者側のモデル入力情報をより適切に構築するために、販売者一致フィールドの概要テキストをリアルタイムで抽出してモデル入力として販売者表現を構築する方法を導入しました; モデルを最適化して検索相関計算のレビューによりよく適応させるために、 2 段階のプロセスを使用 トレーニング方法は、点平のユーザーのクリック データを効果的に活用するために、クリックと手動の注釈データに基づいた 2 段階のトレーニング スキームを採用しています 相関計算の特性に従って、複数の類似性に基づく深い相互作用構造相関モデルをさらに改善するために行列が提案されています 効果: 相関モデルのオンライン コンピューティングのプレッシャーを軽減するために、オンライン展開中にキャッシュ メカニズムと TF-Serving 予測アクセラレーションが導入され、クエリをオフロードするために黄金律層が導入され、相関計算はコアソート層と並列化されるため、オンライン要件を満たし、BERT のリアルタイム計算のパフォーマンス要件を満たします。相関モデルを検索リンクの各リンクに適用することにより、無関係な質問の割合が大幅に減少し、ユーザーの検索エクスペリエンスが効果的に向上します。 現時点では、レビュー検索相関モデルは、モデルのパフォーマンスとオンライン アプリケーションにおいてまだ改善の余地があります。モデル構造の観点から、より多くの分野で事前知識を導入する方法を検討していきます。例えば、クエリ内のエンティティタイプを識別するためのマルチタスク学習、外部知識最適化モデルからの入力など、実用的なアプリケーションに関しては、より詳細な店舗検索に対するユーザーのニーズを満たすために、さらに多くのレベルに洗練されます。また、関連性の機能を非販売者モジュールに適用して、検索リスト全体の検索エクスペリエンスを最適化することも試みます。 xiaoya*、Shen Yuan*、Zhu Di、Tang Biao、Zhang Gong など、すべて Meituan/Dianping Division の Search Technology Center からのものです。 * はこの記事の共著者です。 3.2.1 ドメイン データに基づく 2 段階のトレーニング
2)
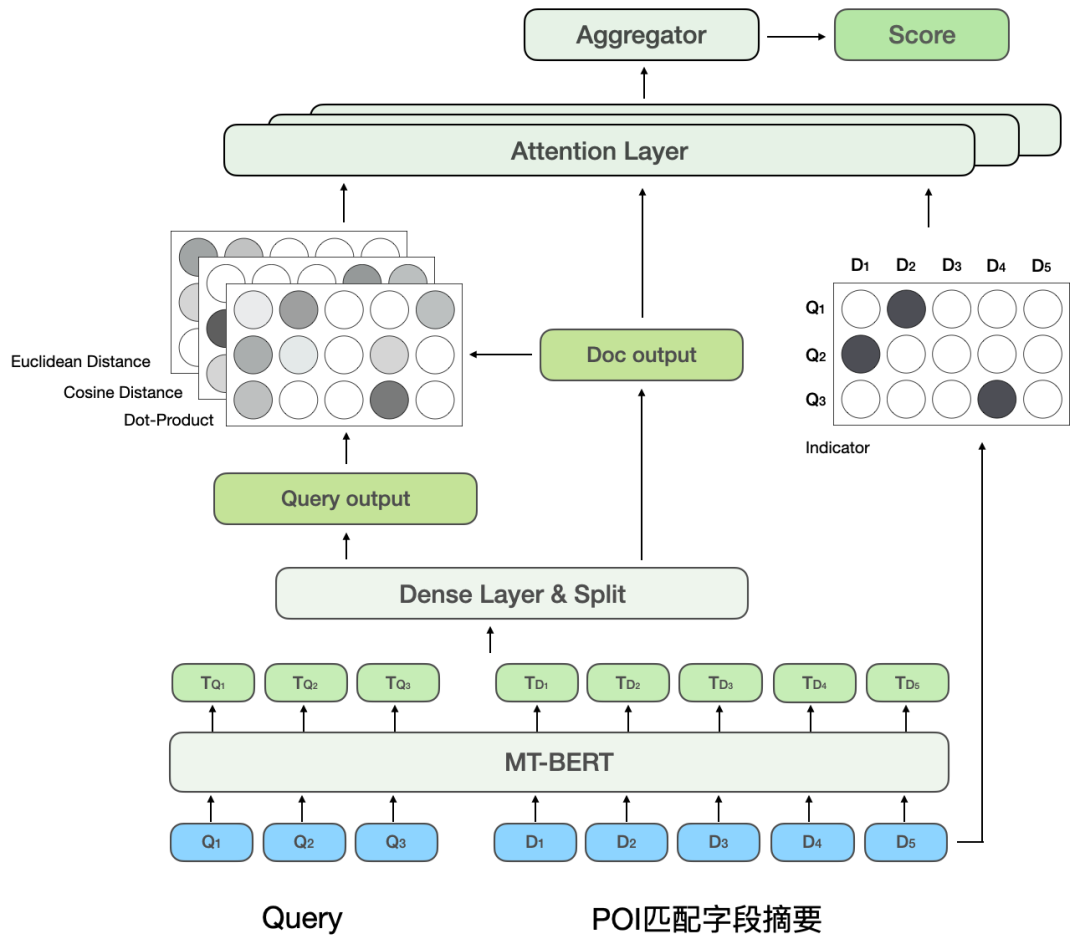
3.3 事前トレーニングされた相関モデルのオンライン パフォーマンスのボトルネックを解決する方法
3.3.1 相関モデル計算プロセスのパフォーマンスの最適化
3.3.2 アプリケーション リンクのパフォーマンスの最適化
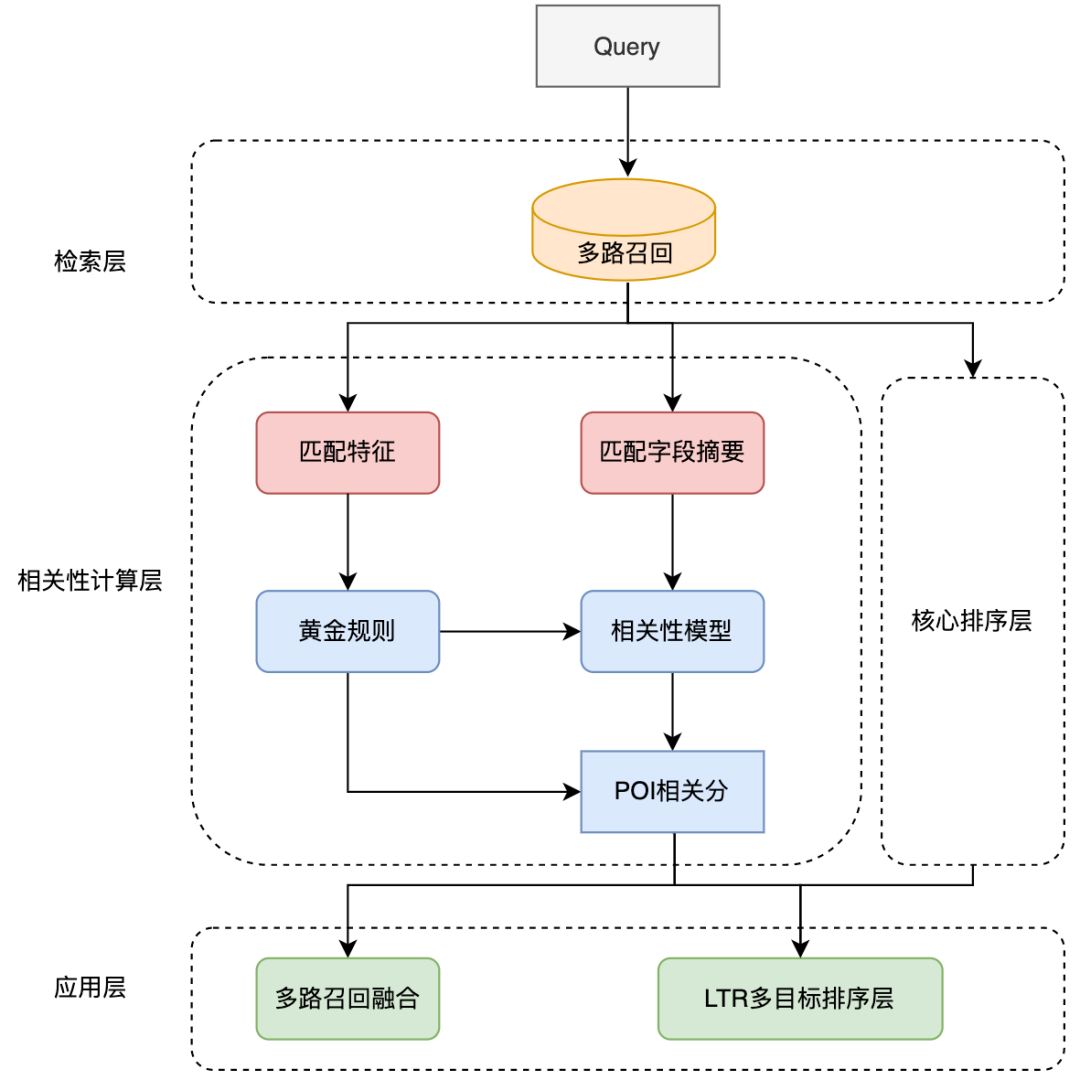
4. 実践的な応用
4.1 オフライン効果
4.2 オンライン効果
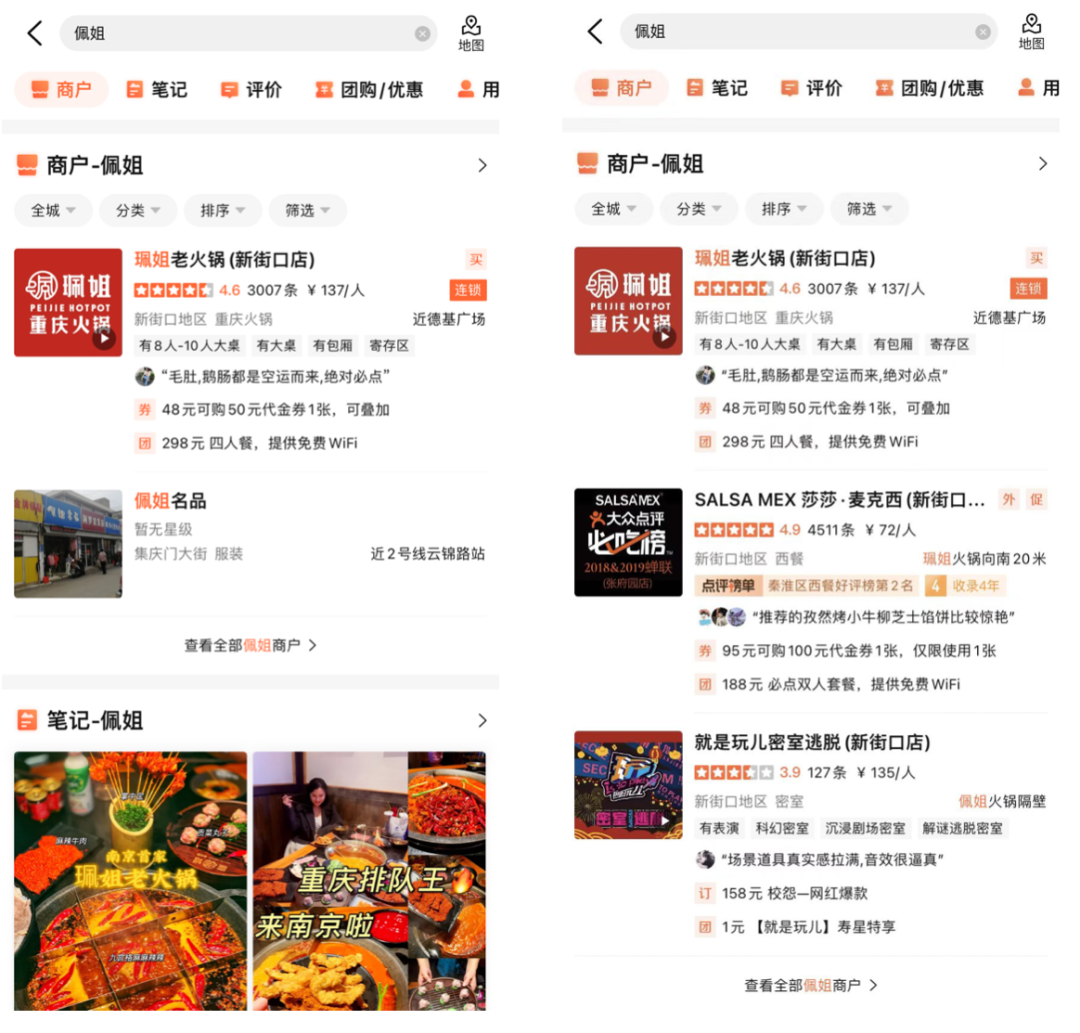
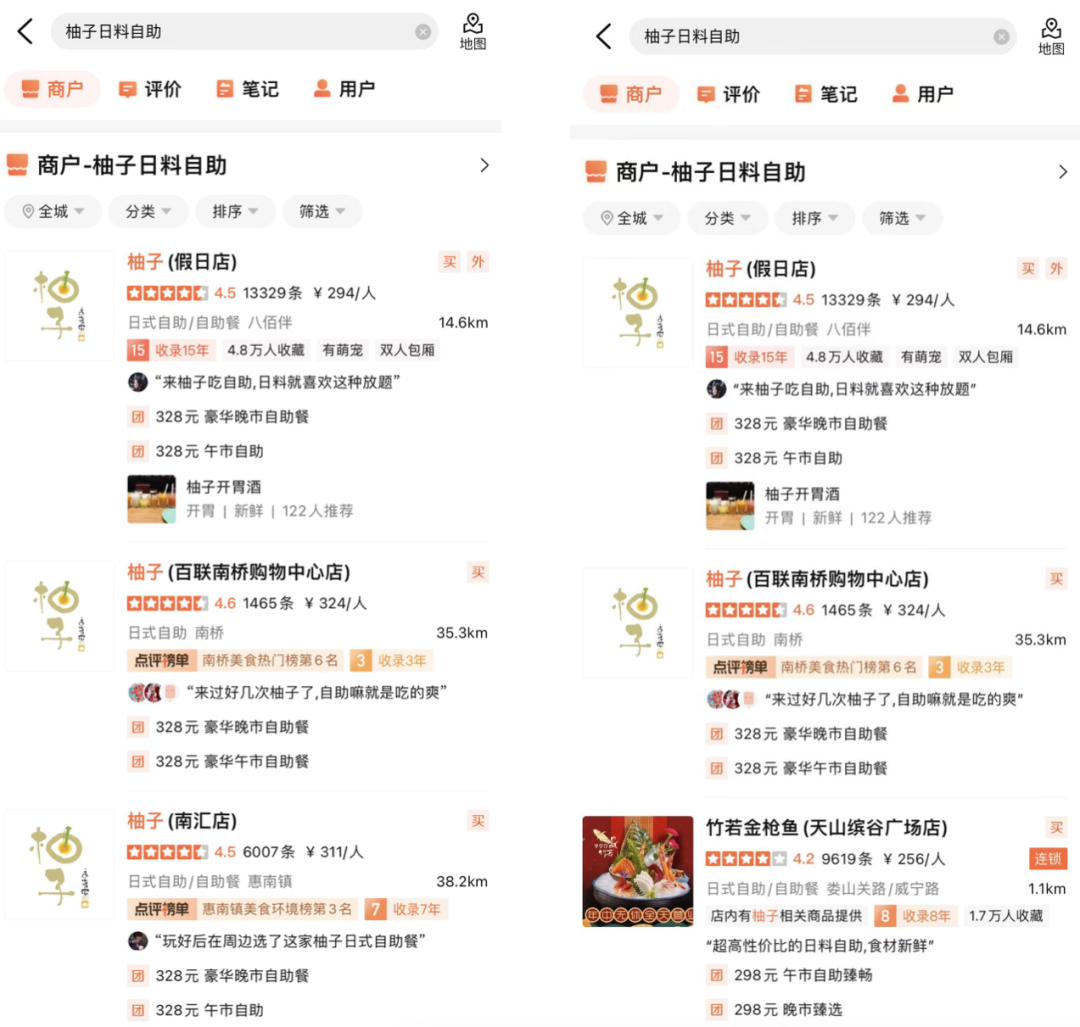 (b) 文旦和食ビュッフェ図 10 オンライン BadCase ソリューションの例
(b) 文旦和食ビュッフェ図 10 オンライン BadCase ソリューションの例5. 概要と展望
6. 著者紹介
以上が点平検索関連技術の探求と実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7471
7471
 15
1377
52
77
11
19
30
15
1377
52
77
11
19
30

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
FP8 以下の浮動小数点数値化精度は、もはや H100 の「特許」ではありません。 Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考え、Microsoft DeepSpeed チームは NVIDIA からの公式サポートなしで A100 上で FP6 の実行を開始しました。テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化が INT4 に近いか、場合によってはそれよりも高速であり、後者よりも精度が高いことを示しています。これに加えて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeed などの深層学習推論フレームワークに統合されています。この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットの 2.65 倍になります。 1つ
