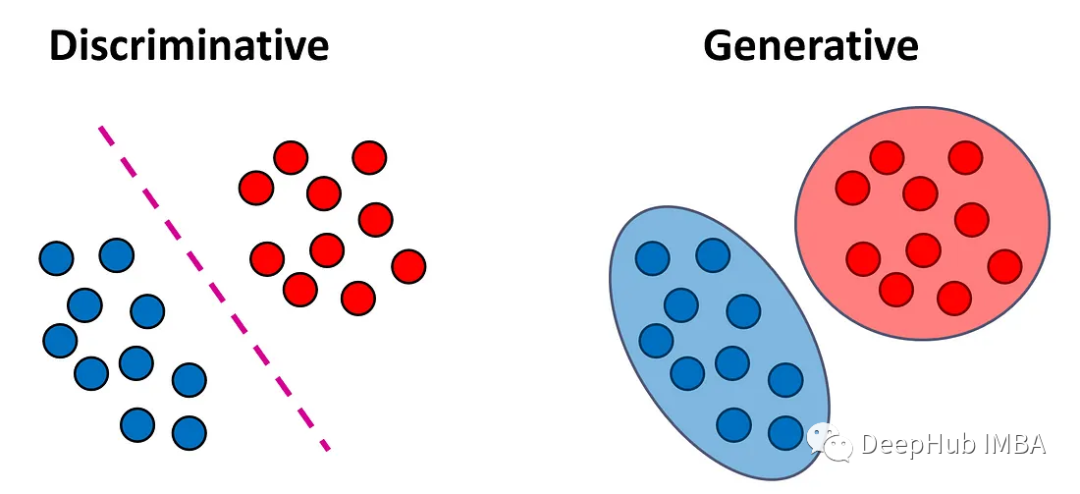
分類モデルは、生成モデルと識別モデルの 2 つのカテゴリに分類できます。この記事では、これら 2 つのモデル タイプの違いを説明し、それぞれのアプローチの長所と短所について説明します。

#判別モデル
判別モデルは、入力データの特徴を学習して予測することで、入力データと出力ラベルの関係を学習できるモデルです。出力ラベル。分類問題における目標は、各入力ベクトル x をラベル y に割り当てることです。識別モデルは、入力ベクトルをラベルにマッピングする関数 f(x) を直接学習しようとします。これらのモデルは、さらに 2 つのサブタイプに分類できます。
分類子は、確率分布を使用せずに f(x) を見つけようとします。これらの分類器は、クラスの確率推定を提供せずに、各サンプルのラベルを直接出力します。これらの分類子は、決定論的分類子または分布自由分類子と呼ばれることがよくあります。このような分類子の例には、k 最近傍法、決定木、SVM などがあります。
分類器はまずトレーニング データから事後クラス確率 P(y = k|x) を学習し、以下に基づいて新しいサンプル x をクラスの 1 つ (通常は事後確率が最も高いクラス) に割り当てます。これらの確率)。
これらの分類子は、確率的分類子と呼ばれることがよくあります。このような分類器の例には、ロジスティック回帰や、出力層でシグモイド関数またはソフトマックス関数を使用するニューラル ネットワークが含まれます。
すべての条件が等しい場合、私は通常、決定的分類子ではなく確率的分類子を使用します。これは、この分類子がサンプルを特定のクラスに割り当てる際の信頼性に関する追加情報を提供するためです。
一般的な判別モデルには次のものが含まれます。
ロジスティック回帰 (LR) - サポート ベクター マシン (SVM)
- デシジョン ツリー (DT)
-
生成モデル
生成モデルは、クラス確率を推定する前に入力の分布を学習します。生成モデルとは、データの生成過程を学習できるモデルで、入力データの確率分布を学習し、新しいデータサンプルを生成することができます。
より具体的には、生成モデルはまず、トレーニング データからカテゴリの条件付き密度 P(x|y = k) と事前カテゴリ確率 P(y = k) を推定します。彼らは、各カテゴリのデータがどのように生成されるかを理解しようとします。
次に、ベイズの定理を使用して事後クラス確率を推定します。
ベイズ則の分母は、分子に現れる変数で表すことができます。
生成モデルは、最初に入力とラベル P(x, y) の同時分布を学習し、それを正規化して事後確率 P(y = k | y) を取得することもできます。バツ)。事後確率を取得したら、それを使用して新しいサンプル x をクラスの 1 つ (通常は事後確率が最も高いクラス) に割り当てることができます。
たとえば、犬 (y = 1) と猫 (y = 0) の画像を区別する必要がある画像分類タスクを考えてみましょう。生成モデルでは、まず犬のモデル P(x|y = 1) と猫のモデル P(x|y = 0) を構築します。次に、新しい画像を分類するときに、それを両方のモデルと照合して、新しい画像が犬に似ているか、猫に似ているかを確認します。
生成モデルを使用すると、学習した入力分布 P(x|y) から新しいサンプルを生成できます。したがって、これを生成モデルと呼びます。最も単純な例は、上記のモデルの場合、P(x|y = 1) からサンプリングすることで新しい犬の画像を生成できることです。
一般的な生成モデルには、次のものが含まれます。
Naive Bayes(ナイーブ ベイズ)- ガウス混合モデル (GMM)
- 隠れマルコフ モデル (hmm)
- 線形判別分析 (LDA)
- # ディープ生成モデル (DGM) は、生成モデルとディープ ニューラル ネットワークを組み合わせます:
Because Encoder (Autoencoder、AE)
- Generative Adversarial Network (GAN)
- GPT (Generative Pretrained Transformer) などの自己回帰モデルは、数十億のパラメトリック自己回帰言語モデルを含むモデルです。
- 違い、長所と短所
生成モデルと判別モデルの主な違いは、学習目標の違いにあります。生成モデルは入力データの分布を学習し、新しいデータ サンプルを生成できます。識別モデルは入力データと出力ラベルの関係を学習し、新しいラベルを予測できます。
生成モデル:
生成モデルは入力分布とクラス確率を同時に学習するため、より多くの情報を提供します。学習された入力分布から新しいサンプルを生成できます。また、欠損値を使用せずに入力分布を推定できるため、欠損データを処理できます。ただし、ほとんどの識別モデルでは、すべての特徴が存在することが必要です。
生成モデルでは入力データと出力データの間の結合分布を確立するために大量のコンピューティング リソースとストレージ リソースが必要となるため、トレーニングの複雑さは高くなります。生成モデルは入力データと出力データの間の結合分布を確立する必要があり、データの分布を仮定してモデル化する必要があるため、データ分布の仮定は比較的強力です。したがって、複雑なデータ分布の場合、生成モデルは小規模な環境に適しています。コンピューティング リソースには適用されません。
生成モデルは入力データと出力データの間で多変量結合分布を確立できるため、生成モデルは多峰性データを処理できるようになり、多峰性データを処理できるようになります。
判別モデル:
データについて何らかの仮定を置かずに入力分布 P(x|y) を学習することは、生成モデルにとって計算上困難です。たとえば、x が m で構成されている場合、バイナリ特徴構成。P(x|y) をモデル化するには、各クラスのデータから 2 ᵐ パラメーターを推定する必要があります (これらのパラメーターは、m 特徴の 2 ᵐ 組み合わせのそれぞれの条件付き確率を表します)。 Naïve Bayes などのモデルは、学習する必要があるパラメーターの数を減らすために特徴の条件付き独立性を前提としているため、トレーニングの複雑さは低くなります。しかし、そのような仮定により、生成モデルのパフォーマンスが判別モデルよりも悪くなることがよくあります。
識別モデルは入力データと出力データの間のマッピング関係を柔軟にモデル化できるため、複雑なデータ分布や高次元データに対して優れたパフォーマンスを発揮します。
識別モデルは、入力データと出力データの間のマッピング関係のみを考慮し、欠損値を埋めるために入力データ内の情報を使用しないため、ノイズ データと欠損データの影響を受けやすくなります。そしてノイズを除去します。
概要
生成モデルと判別モデルはどちらも機械学習における重要なモデル タイプであり、それぞれに独自の利点と適用可能なシナリオがあります。実際のアプリケーションでは、特定のタスクのニーズに応じて適切なモデルを選択し、ハイブリッド モデルや他の技術的手段を組み合わせてモデルのパフォーマンスと効果を向上させる必要があります。
以上が生成モデルと識別モデルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


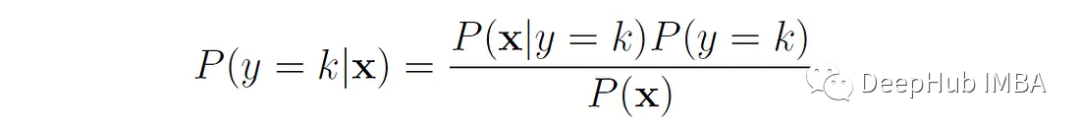
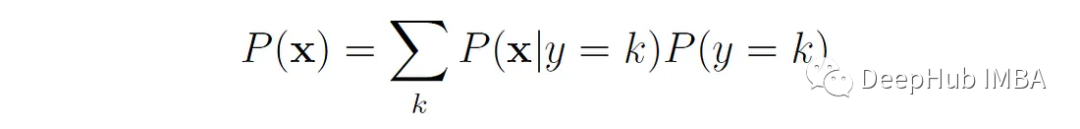

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



