

ブレイン コンピューター インターフェイス、脳波、fMRI、AI が読心術を習得

読心力は人間が最も望む超能力の一つであると言えますが、同時に他人に最も持たれたくない超能力でもあるはずです。検索エンジンに「読心」というキーワードを入力するだけで、関連する書籍、ビデオ、チュートリアルが多数見つかります。これは、人々がこの能力に夢中になっていることを示しています。しかし、そうした心理的、行動的、神秘的な内容はさておき、技術的な観点から言えば、人間の脳信号にはパターンがあり、したがってマインドリーディング(脳信号のパターンを分析すること)は可能です。
現在、AI技術の発展により、そのパターン分析能力はますます高度になり、マインドリーディングが現実のものとなりつつあります。
数日前、テキサス大学オースティン校が Nature Neuroscience 誌に発表した論文は、激しい議論を呼び起こしましたが、この論文は、脳信号を非侵襲的に読み取ることで意味的に一貫したシーケンスを再構築できるというものです。当然のことながら、このモデルは現在一般的な GPT 言語モデルも使用しています。しかし、この最新の結果はひとまず横に置いて、このテーマに関する現在の研究状況を大まかに理解するために、AI 読心術に関する他の初期の研究結果を見てみましょう。
大まかに言って、読心術は、直接的な読心術と間接的な読心術の 2 つのカテゴリに分類できます。
間接読心とは、間接的な特徴を通じて人の思考や感情を推測することを指します。これらの特徴には、顔の表情、体の姿勢、体温、心拍数、呼吸のリズム、話す速度と口調などが含まれます。近年、ビッグデータに基づくディープラーニング技術により、AIは顔の表情から感情を非常に正確に識別できるようになり、例えば、軽量のオープンソースの顔認識ソフトウェアライブラリであるDeepfaceでは、年齢、性別、感情、表情などの複数の特徴を包括的に分析できます。 97.53% のテストセット精度を達成。しかし、上記の特徴に基づく感情解析技術は、通常は読心とはみなされず、結局のところ、人間自身が表情などから相手の感情を多かれ少なかれ推測することができるため、本記事で注目する読心技術は、心を直接読み取ることに限定されます。

ディープフェイク ライブラリを使用して顔属性分析結果を取得します
ダイレクトマインドリーディングとは、脳の信号をテキスト、音声、画像など、他の人が理解できる形式に直接「翻訳」することを指します。現在、研究者が注目している脳信号には主に 3 つのタイプがあります。侵襲性脳コンピューター インターフェイス、脳波、神経画像です。
侵入型ブレイン・コンピューター・インターフェースに基づく読心術侵入型ブレイン・コンピューター・インターフェースは、サイバーパンク作品の標準機能とも言えます。「」で読むことができます。サイバーパンク「2077」やその他多くの映画やゲーム。基本的な考え方は、脳または神経系内またはその近くの神経細胞間を通過する電気信号を読み取ることです。侵襲的に読み取られる脳信号は、一般に非侵襲的方法よりも正確でノイズが少ないです。
2021年、カリフォルニア大学サンフランシスコ校の研究者は、論文「無関節症の麻痺者の音声を解読するための神経人工器官」の中で、言語障害のある障害者を支援するためにAIを使用することを提案しました。通信する 。この研究では、片腕に障害があり、言語が不明瞭な人が対象となった。注目すべき点は、彼らの実験では信号を取得するために神経インプラントが使用され、高密度皮質EEG電極アレイと経皮コネクタの組み合わせが使用されました。この侵襲的なアプローチは、当然のことながら精度の向上につながります。モデルのデコード速度は毎分最大 18 ワードで、最大精度 98%、デコード率中央値 75% を達成します。さらに、言語モデルの適用により、単なる文字列の蓄積ではなく、解読結果の意味表現も大幅に向上します。
その後、チームは 2022 年の Nature Neuroscience 論文「重度の四肢および音声麻痺を持つ個人における音声神経人工装具を使用した一般化可能なスペル」でシステムをさらに改良し、新興言語モデルを統合しました。 GPT によりパフォーマンスがさらに向上します。
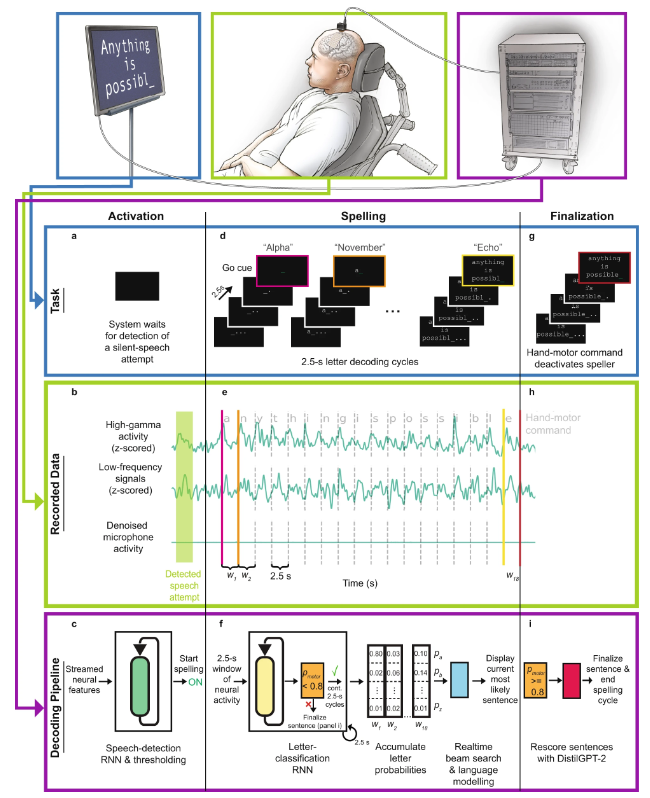
直接音声ブレイン コンピューター インターフェイスのワークフロー図
具体的には、ワークフローは次のとおりです:
- a 文のスペリング試験の開始時に、参加者は黙って単語を話すことによって精神的にスペリングを活性化しようとしました。
- b 神経特徴 (高ガンマ活動と低周波信号) は、タスク中に記録された皮質データからリアルタイムで抽出されます。マイク信号は、タスク中に音声信号が存在しないことを示します。
- c 音声検出モデルはリカレント ニューラル ネットワーク (RNN) としきい値演算で構成され、そのタスクは音声表現の試行の神経特性を検出することです。被験者の発話の試みが検出されると、綴りのプロセスが開始されます。
- d スペルのプロセスでは、被験者は 2.5 秒ごとに行われる文字解読サイクルを通じて、意図したメッセージをスペルします。各サイクルで被験者はカウントダウンを見ることができ、カウントダウンの終わりが開始の合図でした。開始の合図を受け取った後、被験者は目的の文字を表す暗号語を静かに言うことを試みました。
- e スペリング中に、すべての電極チャネルに対して高ガンマ線活性と低周波信号が計算され、2.5 秒の長さの重複しない時間ウィンドウに割り当てられました。
- f 参加者が 26 の考えられるコードワードをそれぞれ黙って言いたいとき、または手の動きのコマンドを操作しようとしたとき、RNN ベースの文字分類モデルは各ニューラル タイム ウィンドウを処理して、そのコード ワードの予測を行いました。確率。
- #g 参加者が表現したいメッセージを綴り終えた後、右手を握って綴りのプロセスを終了し、文を終了しようとします。
- h 手の動きコマンドに関連付けられたニューラル時間ウィンドウが分類モデルに渡されます。
- i 参加者が手の動きのコマンドを使用しようとしたことを分類器が確認した場合、ニューラル ネットワーク ベースの言語モデル (DistilGPT-2) を使用して有効な文が再スコアリングされました。再採点後、最も可能性の高い文が最終予測として使用されます。
埋め込み型ブレインコンピューターインターフェースの別の研究では、効率的な手書き認識とEEG信号のテキストへの変換に成功したと主張しています。 Nature の論文「手書きによる高性能脳からテキストへのコミュニケーション」では、スタンフォード大学の研究者が、脊髄損傷による麻痺のある人々が毎分 90 文字の速度で入力できるようにすることに成功し、当初のオンライン精度は 94.1% に達しました。言語モデルのオフライン精度は 99% を超えています。
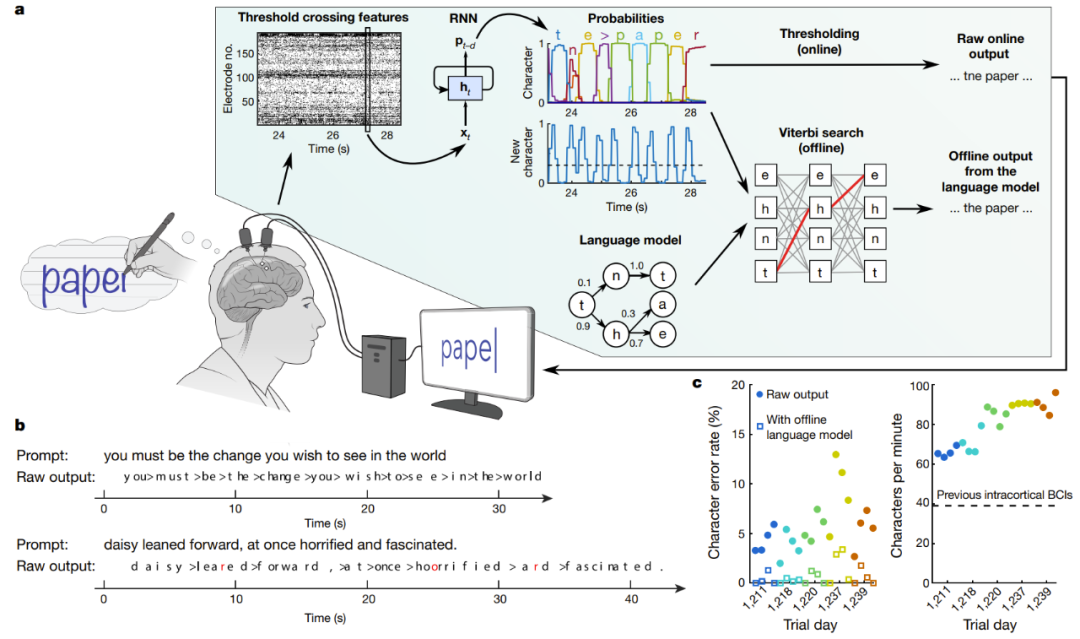
#手書きを試みる被験者の脳信号をリアルタイムでデコード
Aは復号アルゴリズムの模式図である。まず、各電極での神経活動が時間的に結合され、平滑化されます。次に、RNN を使用して、ニューラル集団の時系列が、各文字の可能性と新しい文字が開始される確率を記述する確率時系列に変換されます。 RNN の出力遅延 (d) は 1 秒で、各文字を完全に観察してからその ID を判断する時間が与えられます。最後に、リアルタイムで使用するための「元のオンライン出力」を取得するための文字確率のしきい値を設定します (時間 t で新しい文字の確率が特定のしきい値を超えると、最も可能性の高い文字が与えられ、時間 t 0.3 秒で表示されます)画面上)。オフラインでの遡及分析では、研究者らは文字の確率と語彙が豊富な言語モデルを組み合わせて、参加者が書く可能性が最も高いテキストを解読した。
脳波に基づく心を読むここ数十年の脳科学の研究結果に基づいて、神経細胞が伝達する過程で微小な電流があることがわかっています。これにより、微妙な電磁変動が生じます。多数の神経細胞が同時に活動している場合、これらの電磁変動は非侵襲性の精密機器を使用して捕捉できます。 1875 年、科学者たちは動物の脳波として知られる流れる電場現象を初めて観察しました。 1925 年、ハンス ベルガーは脳波図 (EEG) を発明し、人間の脳の電気活動を初めて記録しました。以来100年近くにわたり、脳波技術は進歩を続け、その精度とリアルタイム性は非常に高いレベルに達し、実用化され、今ではポータブルな脳波検出・解析装置も購入できるようになりました。
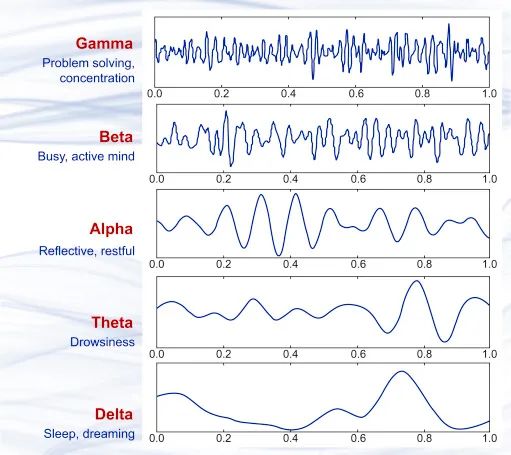
いくつかの異なる脳波波形サンプルは、上から下までガンマ波 (35Hz 以上)、ベータ波です。波(12 ~ 35 Hz)、アルファ波(8 ~ 12 Hz)、シータ波(4 ~ 8 Hz)、デルタ波(0.5 ~ 4 Hz)。これらはさまざまな脳の状態にほぼ相当します。
脳波を通じて人々の感情や思考を分析する最も一般的な方法は、刺激を見てから約 300 ミリ秒後に被験者の脳によって生成される脳波である P300 波を分析することです。脳波を解析する研究は、脳波の発見以来途切れることなく続けられており、たとえば、2001 年に、この分野で物議を醸している研究者ローレンス・ファーウェルは、脳波反応を評価することで被験者が何かを経験したかどうかを検出できるアルゴリズムを提案しました。 、そして被験者がそれを隠蔽しようとしても無駄です。言い換えれば、これは脳波ベースの嘘発見器です。
脳波自体はパターンを持った信号なので、ニューラルネットワークを使って脳波を解析するのは自然なことです。以下では、近年の研究を通じて科学者が脳波信号を音声、テキスト、画像に変換するために使用しているいくつかの方法を紹介します。
2019年、ロシアの研究チームは、脳波に基づいて画像を再構成できるビジュアル・ブレイン・コンピューター・インターフェース(BCI)システムを提案した。研究のアイデアは非常に単純で、脳波信号から特徴を抽出し、次に特徴ベクトルを抽出し、それをマッピングして隠れた空間内の特徴の位置を見つけ、最後に画像を復号して再構成するというものです。その中で、画像デコーダは画像間畳み込みオートエンコーダ モデルの一部であり、完全に接続された 1 つの入力層とそれに続く 5 つのデコンボリューション モジュールを含みます。各モジュールは 1 つのデコンボリューション層で構成され、ReLU アクティベーションで構成されます。最後のモジュールは双曲線正接活性化層です。
モデルのもう 1 つの重要なコンポーネントは EEG 特徴マッパーです。その機能は、データを EEG 特徴ドメインから画像デコーダーの隠れた空間ドメインに変換することです。チームはモデル内の反復ユニットとして LSTM を使用し、さらに改良するためにアテンション メカニズムを使用しました。その損失関数は、EEG の特徴表現と画像の間の平均二乗誤差を最小限に抑えることです。詳細については、論文「脳波からの自然画像再構成: ネイティブ フィードバックを備えた新しい視覚 BCI システム」を参照してください。
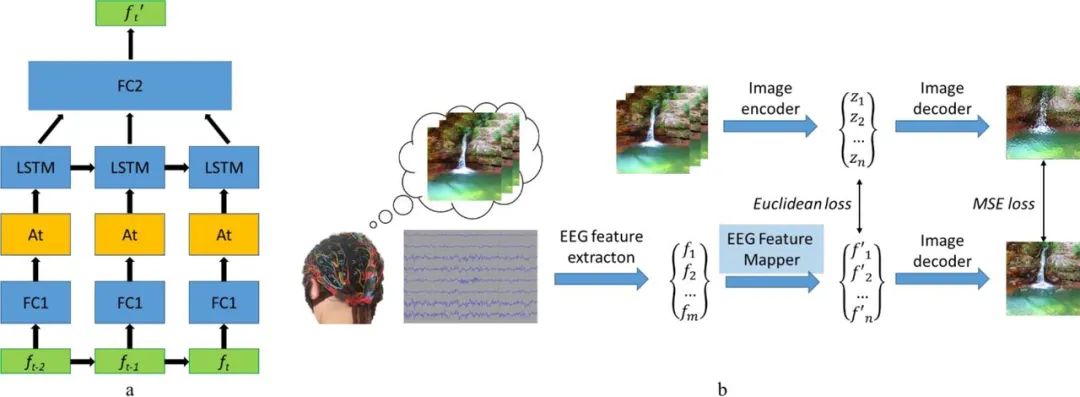
#EEG 特徴マッパーのモデル構造 (a) とトレーニング ルーチン (b)
以下にいくつかの結果の例を示します。再構成された画像と元の画像の間に有意な相関があることがわかります。

#被験者が見た元の画像 (画像の各ペアの左側) とそれに応じた元の画像被験者の脳への波動再構成画像 (各画像ペアの右)
2022 年、メタ AI チームは、非侵襲的な脳記録から音声を抽出する方法を提案しました。論文「非侵襲的脳記録からの音声のデコード」脳波記録 (EEG) または脳磁記録 (MEG) 信号から音声信号をデコードするニューラル ネットワーク アーキテクチャ。
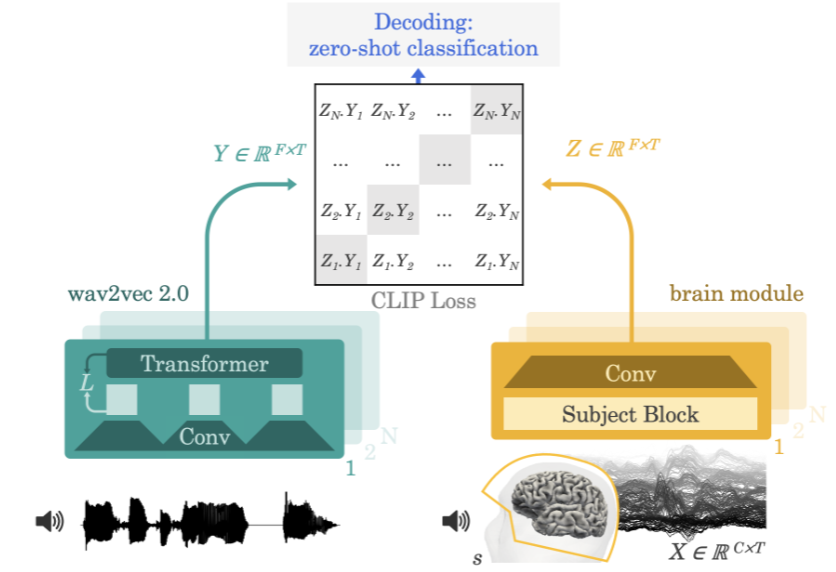
研究チームが使用した方法は、実験参加者に物語や文章を聞いてもらいながら、脳活動の脳波検査または脳磁図を記録するというものだった。これを行うために、モデルはまず、事前トレーニングされた自己教師ありモデル (wav2vec 2.0) を通じて 3 秒間の音声信号 (Y) の深い文脈表現を抽出し、対応する整列された 3 つの言語における脳活動の表現も学習します。 - 2 番目のウィンドウ (X) (Z)。表現 Z は、深い畳み込みネットワークによって与えられます。評価中、研究者らはモデルに残りの文を与え、各脳表現に基づいて言語の 3 秒ごとのセグメントを計算しました。結果として、このデコード プロセスをゼロショットにすることができ、モデルがトレーニング セットに含まれていないオーディオ クリップを予測できるようになります。
神経画像に基づく心の読み取り
科学者は、機能的磁気共鳴画像法 (fMRI) と呼ばれる技術を使用して脳の活動を理解することもできます。この技術は 1990 年代初頭に開発され、磁気共鳴画像法で脳内の血流を観察し、脳の活動を検出します。この技術により、脳の特定の機能領域が活動しているかどうかが明らかになります。
脳の特定の領域が「より活発になっている」と言うとき、それは何を意味するのでしょうか? fMRI はこの活動をどのように検出するのでしょうか?
脳領域のニューロンが以前よりも多くの電気信号を送信し始めると、脳領域がより活性化したと言われます。たとえば、脚を持ち上げたときに特定の脳領域がより活性化する場合、その脳の領域が脚の持ち上げを制御していると考えられます。
fMRI は、血液中の酸素レベルを検出することでこの電気活動を検出します。これは血中酸素濃度依存性 (BOLD) 反応と呼ばれます。その仕組みは、ニューロンがより活発になると、赤血球からより多くの酸素を必要とすることです。これを行うために、周囲の血管が広がり、より多くの血液が流れることができるようになります。したがって、ニューロンがより活発になると、酸素レベルが上昇します。酸素化された血液は、脱酸素化された血液よりも場の干渉が少ないため、ニューロンの信号(本質的には水中の水素)が長く持続します。そのため、信号が長く続くと、fMRI はその領域に酸素が多く存在し、より活性化していることを認識します。このアクティビティを色分けした後、fMRI 画像が取得されます。
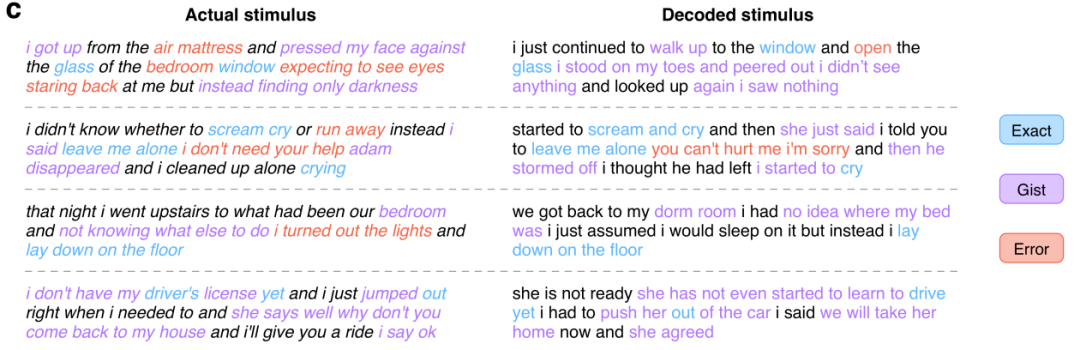
次に、GPT を使用して意味的に一貫した連続文を再構築する前述の研究「非侵襲的脳記録からの連続言語の意味的再構築」を見てみましょう。彼らは、fMRI 記録における意味論的意味の皮質表現に基づいて連続自然言語を再構築できる非侵襲的デコーダを提案しています。新しい脳記録を提示すると、デコーダーは、被験者が聞いた音声、想像上の音声、さらには無声ビデオの意味を再現する理解可能な単語シーケンスを生成することができ、単一の言語デコーダーを使用できることが示唆されました。 。この言語デコーダのワークフローは次のとおりです。
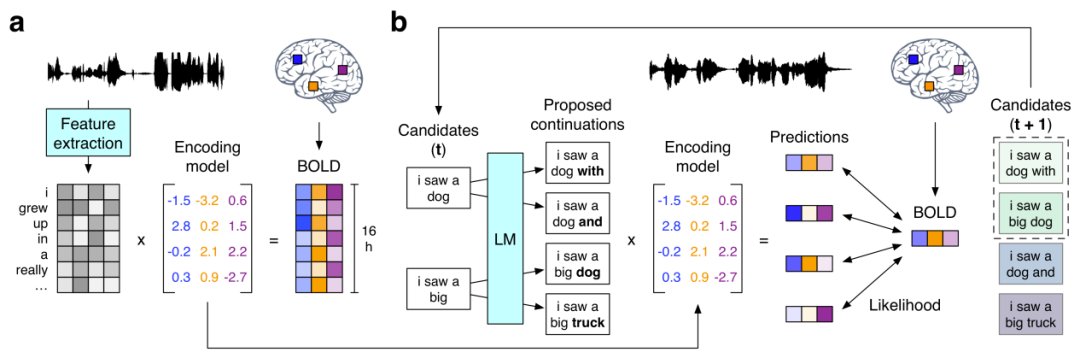
(a) 3 人の被験者が 16 時間の物語 BOLD を聞いたときストーリータイム中に記録された fMRI 応答。このシステムは、刺激として使用される単語の意味的特徴によって引き起こされる脳反応を予測するエンコード モデルを被験者ごとに推定します。 (b) 新鮮な脳記録に基づいて言語を再構築するために、デコーダは一連の候補単語シーケンスを維持します。新しい単語が検出されると、言語モデルが各シーケンスの連続性を提案し、エンコード モデルを使用して各連続性条件について記録された脳反応の尤度を評価します。最も可能性の高い連続シーケンスが最後に保持されます。
このうち、言語モデルには現在AI研究の中心となっているGPTモデルが使われています。研究者らは、2億語を超えるRedditのコメントと、The Moth Radio HourとModern Loveからの240の自伝的物語からなる大規模なコーパスで使用したGPTを微調整した。モデルは、最大コンテキスト長 100 で 50 エポックに対してトレーニングされました。いくつかの実験結果を以下に示します。
#最後に、この CVPR 2023 論文「脳を超えたものを見る」を見てみましょう。 「:ビジョンデコーディングのためのスパースマスクモデリングによる条件付き拡散モデル」。シンガポール国立大学、香港中文大学、スタンフォード大学の研究者らは、彼らが提案したMinD-Visモデルにより、fMRIベースの脳活動信号を画像にデコードするという成果を初めて達成し、再構成された画像が得られたと主張している。詳細が豊富なだけでなく、正確なセマンティックおよび画像の特徴 (テクスチャ、形状など) も含まれています。
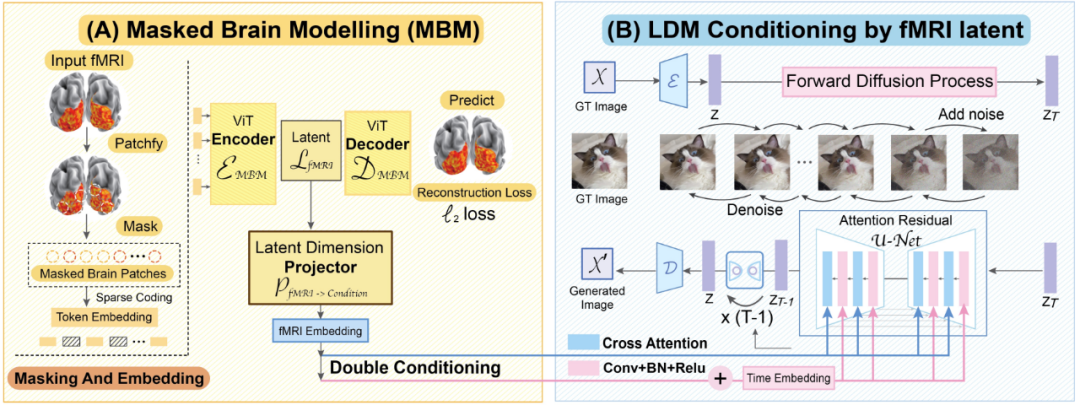
MinD-Vis ワークフロー図
やってみようMinD-Vis の 2 つの作業段階を見てください。図に示すように、ステージ A では、SC-MBM (Sparsecoding Masked Brain Modeling) を使用して fMRI に対して事前トレーニングが実行されます。次に、fMRI をランダムにマスクし、それらを大きな埋め込みにトークン化します。研究者らは、マスクされたパッチを復元するためにオートエンコーダーを訓練しました。ステージ B では、二重条件付けを通じて潜在拡散モデル (LDM) と統合されます。潜在次元投影アルゴリズムを使用して、2 つのパスを介して fMRI 潜在空間を LDM 条件付き空間に投影しました。パスの 1 つは、LDM でクロスアテンション ヘッドを直接接続することです。別の方法は、時間的埋め込みに fMRI の影響を追加することです。
論文に記載された実験結果から判断すると、このモデルの読心能力は確かに非常に優れています:

#左の写真は被験者が見た元の写真、赤枠は MinD-Vis の再構成結果、次の 3 列はは他のメソッドの結果です。
結論データ量の増加とアルゴリズムの改善により、人工知能は私たちの世界をますます深く理解し、私たち人間を理解しています。この世界の核心 自然の一部も理解すべき対象です。人間の脳の活動パターンを調査することで、機械は人間が考えていることを根底から理解する能力を獲得しつつあります。おそらく将来、AI は真の読心術の達人となり、人間の夢を忠実に捉える能力さえも持つようになるかもしれません。
上記は、AI の直接読心における最近の研究成果を簡単に紹介したものですが、実際、Neuralink や Brain など関連技術の商用化に取り組み始めている企業もあります。 Blackrock Neurotech に代表されるコンピューター インターフェイスおよびニューロテクノロジー企業の将来の可能性のある製品には、言葉では言い表せない障害を持つ人々が世界とのつながりを再確立するのを支援したり、深海や宇宙などの危険な領域で動作するロボットを遠隔制御したりするなど、エキサイティングな応用の見通しがあるでしょう。機械。同時に、これらのテクノロジーの発展は、多くの人々に人間の意識の謎を解読するという希望を与えています。
もちろん、この種のテクノロジーは多くの人々にプライバシー、セキュリティ、倫理についての懸念を引き起こしています。結局のところ、私たちはこの種のテクノロジーが多くの映画や小説で使用されているのを見てきました。 . 邪悪な目的のため。昨今、こうした技術の更なる発展は避けられず、これらの技術を人類の利益といかに両立させるかが重要な課題となっており、関係者や政策立案者全員が考え、議論する必要がある。
以上がブレイン コンピューター インターフェイス、脳波、fMRI、AI が読心術を習得の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7478
7478
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
MySQLはJSONデータを返すことができます。 json_extract関数はフィールド値を抽出します。複雑なクエリについては、Where句を使用してJSONデータをフィルタリングすることを検討できますが、そのパフォーマンスへの影響に注意してください。 JSONに対するMySQLのサポートは絶えず増加しており、最新バージョンと機能に注意を払うことをお勧めします。
 マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
sqllimit句:クエリ結果の行数を制御します。 SQLの制限条項は、クエリによって返される行数を制限するために使用されます。これは、大規模なデータセット、パジネートされたディスプレイ、テストデータを処理する場合に非常に便利であり、クエリ効率を効果的に改善することができます。構文の基本的な構文:SelectColumn1、column2、... FromTable_nameLimitnumber_of_rows; number_of_rows:返された行の数を指定します。オフセットの構文:SelectColumn1、column2、... FromTable_nameLimitoffset、number_of_rows; offset:skip
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 Prometheus MySQL ExporterでMySQLおよびMariadb液滴を監視します
Apr 08, 2025 pm 02:42 PM
Prometheus MySQL ExporterでMySQLおよびMariadb液滴を監視します
Apr 08, 2025 pm 02:42 PM
MySQLおよびMariaDBデータベースの効果的な監視は、最適なパフォーマンスを維持し、潜在的なボトルネックを特定し、システム全体の信頼性を確保するために重要です。 Prometheus MySQL Exporterは、プロアクティブな管理とトラブルシューティングに重要なデータベースメトリックに関する詳細な洞察を提供する強力なツールです。
 MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLプライマリキーは、データベース内の各行を一意に識別するキー属性であるため、空にすることはできません。主キーが空になる可能性がある場合、レコードを一意に識別することはできません。これにより、データの混乱が発生します。一次キーとして自己挿入整数列またはUUIDを使用する場合、効率やスペース占有などの要因を考慮し、適切なソリューションを選択する必要があります。
 MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
Hash値として保存されているため、Navicatを介してMongoDBパスワードを直接表示することは不可能です。紛失したパスワードを取得する方法:1。パスワードのリセット。 2。構成ファイルを確認します(ハッシュ値が含まれる場合があります)。 3.コードを確認します(パスワードをハードコードできます)。
 SQLで条項ごとに注文をマスターする:効果的にデータを並べ替える
Apr 08, 2025 pm 07:03 PM
SQLで条項ごとに注文をマスターする:効果的にデータを並べ替える
Apr 08, 2025 pm 07:03 PM
SQLORDERBY句の詳細な説明:Data OrderBY句の効率的なソートは、クエリ結果セットをソートするために使用されるSQLの重要なステートメントです。単一の列または複数の列で昇順(ASC)または下降順序(DESC)で配置でき、データの読みやすさと分析効率を大幅に改善できます。 Orderby Syntax SelectColumn1、column2、... fromTable_nameOrderByColumn_name [asc | desc]; column_name:列ごとに並べ替えます。 ASC:昇順の注文ソート(デフォルト)。 DESC:降順で並べ替えます。 Orderbyの主な機能:マルチコラムソート:複数の列のソートをサポートし、列の順序によりソートの優先度が決まります。以来
