

Pythonをベースに単眼3D再構成を実現する方法

#1. 単眼 3 次元再構成の概要
対象世界の物体は 3 次元ですが、得られる画像は 2 次元ですが、この二次元画像から対象物の三次元情報をセンシングします。三次元再構成技術は、画像を何らかの方法で処理してコンピュータが認識できる三次元情報を取得し、対象物を解析する技術です。単眼 3D 再構成は、単一のカメラの動きに基づいて両眼視をシミュレートし、空間内のオブジェクトの 3 次元視覚情報を取得します。ここで、単眼とは単一のカメラを指します。
2. 実装プロセス
オブジェクトの単眼 3 次元再構築プロセスでは、関連する動作環境は次のとおりです:
matplotlib 3.3.4
numpy 1.19.5
opencv-contrib-python 3.4.2.16
opencv-python 3.4.2.16
pillow 8.2.0
python 3.6.2
再構成には主に以下の手順が含まれます。
#(1) カメラキャリブレーション#(2) 画像特徴抽出とマッチング
#(3) 3 次元再構成 次に、各ステップの具体的な実装を詳しく見てみましょう: (1) カメラのキャリブレーション 携帯電話のカメラなど、私たちの日常生活には多くのカメラがあります。デジタルカメラと機能モジュールの種類 カメラなど 各カメラのパラメータ、つまり、カメラで撮影される写真の解像度やモードなどが異なります。オブジェクトの 3 次元再構成を実行するときに、カメラの行列パラメータが事前にわからないと仮定すると、カメラの行列パラメータを計算する必要があります。この手順はカメラ キャリブレーションと呼ばれます。カメラのキャリブレーションに関する原理については、インターネット上の多くの方が詳しく説明しているので、ここでは紹介しません。キャリブレーションの具体的な実装は次のとおりです。def camera_calibration(ImagePath):
# 循环中断
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
# 棋盘格尺寸(棋盘格的交叉点的个数)
row = 11
column = 8
objpoint = np.zeros((row * column, 3), np.float32)
objpoint[:, :2] = np.mgrid[0:row, 0:column].T.reshape(-1, 2)
objpoints = [] # 3d point in real world space
imgpoints = [] # 2d points in image plane.
batch_images = glob.glob(ImagePath + '/*.jpg')
for i, fname in enumerate(batch_images):
img = cv2.imread(batch_images[i])
imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# find chess board corners
ret, corners = cv2.findChessboardCorners(imgGray, (row, column), None)
# if found, add object points, image points (after refining them)
if ret:
objpoints.append(objpoint)
corners2 = cv2.cornerSubPix(imgGray, corners, (11, 11), (-1, -1), criteria)
imgpoints.append(corners2)
# Draw and display the corners
img = cv2.drawChessboardCorners(img, (row, column), corners2, ret)
cv2.imwrite('Checkerboard_Image/Temp_JPG/Temp_' + str(i) + '.jpg', img)
print("成功提取:", len(batch_images), "张图片角点!")
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, imgGray.shape[::-1], None, None)ログイン後にコピー
このうち、cv2.calibrateCamera 関数で取得した mtx 行列が K 行列です。 対応するパラメータを変更し、キャリブレーションを完了した後、チェッカーボードのコーナー ポイントの画像を出力して、チェッカーボードのコーナー ポイントが正常に抽出されたかどうかを確認できます。出力されるコーナー ポイントの画像は次のとおりです: def camera_calibration(ImagePath):
# 循环中断
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
# 棋盘格尺寸(棋盘格的交叉点的个数)
row = 11
column = 8
objpoint = np.zeros((row * column, 3), np.float32)
objpoint[:, :2] = np.mgrid[0:row, 0:column].T.reshape(-1, 2)
objpoints = [] # 3d point in real world space
imgpoints = [] # 2d points in image plane.
batch_images = glob.glob(ImagePath + '/*.jpg')
for i, fname in enumerate(batch_images):
img = cv2.imread(batch_images[i])
imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# find chess board corners
ret, corners = cv2.findChessboardCorners(imgGray, (row, column), None)
# if found, add object points, image points (after refining them)
if ret:
objpoints.append(objpoint)
corners2 = cv2.cornerSubPix(imgGray, corners, (11, 11), (-1, -1), criteria)
imgpoints.append(corners2)
# Draw and display the corners
img = cv2.drawChessboardCorners(img, (row, column), corners2, ret)
cv2.imwrite('Checkerboard_Image/Temp_JPG/Temp_' + str(i) + '.jpg', img)
print("成功提取:", len(batch_images), "张图片角点!")
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, imgGray.shape[::-1], None, None)図 1: チェッカーボードの角点の抽出
画像特徴点抽出アルゴリズムには、SIFT アルゴリズム、SURF アルゴリズム、ORB アルゴリズムという 3 つのアルゴリズムがよく使われます。このステップでは、包括的な分析と比較を通じて、SURF アルゴリズムを使用して画像の特徴点を抽出します。 3 つのアルゴリズムの特徴点抽出効果を比較したい場合は、オンラインで検索して参照してください。ここでは 1 つずつの比較は行いません。具体的な実装は次のとおりです。
def epipolar_geometric(Images_Path, K):
IMG = glob.glob(Images_Path)
img1, img2 = cv2.imread(IMG[0]), cv2.imread(IMG[1])
img1_gray = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
img2_gray = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# Initiate SURF detector
SURF = cv2.xfeatures2d_SURF.create()
# compute keypoint & descriptions
keypoint1, descriptor1 = SURF.detectAndCompute(img1_gray, None)
keypoint2, descriptor2 = SURF.detectAndCompute(img2_gray, None)
print("角点数量:", len(keypoint1), len(keypoint2))
# Find point matches
bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=True)
matches = bf.match(descriptor1, descriptor2)
print("匹配点数量:", len(matches))
src_pts = np.asarray([keypoint1[m.queryIdx].pt for m in matches])
dst_pts = np.asarray([keypoint2[m.trainIdx].pt for m in matches])
# plot
knn_image = cv2.drawMatches(img1_gray, keypoint1, img2_gray, keypoint2, matches[:-1], None, flags=2)
image_ = Image.fromarray(np.uint8(knn_image))
image_.save("MatchesImage.jpg")
# Constrain matches to fit homography
retval, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 100.0)
# We select only inlier points
points1 = src_pts[mask.ravel() == 1]
points2 = dst_pts[mask.ravel() == 1]見つかった特徴点は次のとおりです。
図 2: 特徴点の抽出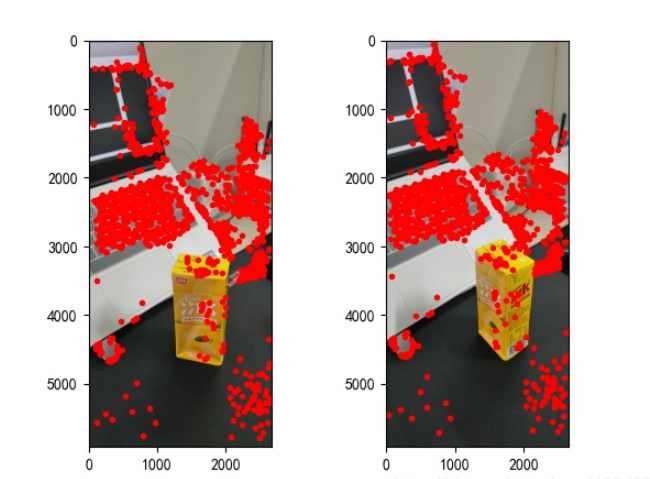
図 3: 3 次元再構成
#3. 結論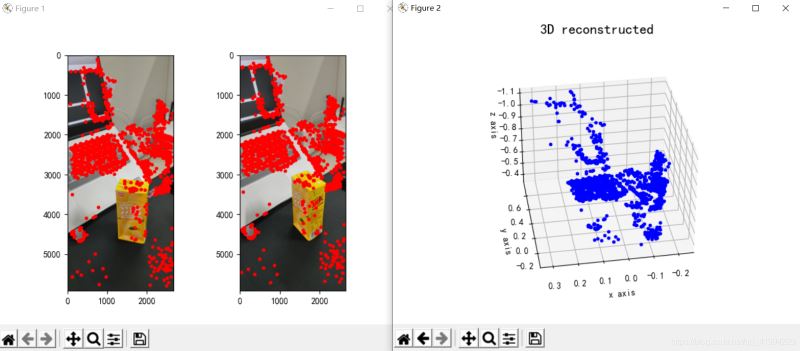
points1 = cart2hom(points1.T)
points2 = cart2hom(points2.T)
# plot
fig, ax = plt.subplots(1, 2)
ax[0].autoscale_view('tight')
ax[0].imshow(cv2.cvtColor(img1, cv2.COLOR_BGR2RGB))
ax[0].plot(points1[0], points1[1], 'r.')
ax[1].autoscale_view('tight')
ax[1].imshow(cv2.cvtColor(img2, cv2.COLOR_BGR2RGB))
ax[1].plot(points2[0], points2[1], 'r.')
plt.savefig('MatchesPoints.jpg')
fig.show()
#
points1n = np.dot(np.linalg.inv(K), points1)
points2n = np.dot(np.linalg.inv(K), points2)
E = compute_essential_normalized(points1n, points2n)
print('Computed essential matrix:', (-E / E[0][1]))
P1 = np.array([[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0]])
P2s = compute_P_from_essential(E)
ind = -1
for i, P2 in enumerate(P2s):
# Find the correct camera parameters
d1 = reconstruct_one_point(points1n[:, 0], points2n[:, 0], P1, P2)
# Convert P2 from camera view to world view
P2_homogenous = np.linalg.inv(np.vstack([P2, [0, 0, 0, 1]]))
d2 = np.dot(P2_homogenous[:3, :4], d1)
if d1[2] > 0 and d2[2] > 0:
ind = i
P2 = np.linalg.inv(np.vstack([P2s[ind], [0, 0, 0, 1]]))[:3, :4]
Points3D = linear_triangulation(points1n, points2n, P1, P2)
fig = plt.figure()
fig.suptitle('3D reconstructed', fontsize=16)
ax = fig.gca(projection='3d')
ax.plot(Points3D[0], Points3D[1], Points3D[2], 'b.')
ax.set_xlabel('x axis')
ax.set_ylabel('y axis')
ax.set_zlabel('z axis')
ax.view_init(elev=135, azim=90)
plt.savefig('Reconstruction.jpg')
plt.show()以上がPythonをベースに単眼3D再構成を実現する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7338
7338
 9
1627
14
1352
46
1265
25
1210
29
9
1627
14
1352
46
1265
25
1210
29

 PythonインタープリターはLinuxシステムで削除できますか?
Apr 02, 2025 am 07:00 AM
PythonインタープリターはLinuxシステムで削除できますか?
Apr 02, 2025 am 07:00 AM
Linux Systemsに付属するPythonインタープリターを削除する問題に関して、多くのLinuxディストリビューションは、インストール時にPythonインタープリターをプリインストールし、パッケージマネージャーを使用しません...
 Pythonでのカスタムデコレータのパイランスタイプ検出の問題を解決する方法は?
Apr 02, 2025 am 06:42 AM
Pythonでのカスタムデコレータのパイランスタイプ検出の問題を解決する方法は?
Apr 02, 2025 am 06:42 AM
Pythonプログラミングでカスタムデコレーターを使用する場合、Pylance Type検出問題解決策デコレーターは、行を追加するために使用できる強力なツールです...
 Python Asyncio Telnet接続はすぐに切断されます:サーバー側のブロッキング問題を解決する方法は?
Apr 02, 2025 am 06:30 AM
Python Asyncio Telnet接続はすぐに切断されます:サーバー側のブロッキング問題を解決する方法は?
Apr 02, 2025 am 06:30 AM
Pythonasyncioについて...

 Python 3.6のロードピクルスファイルエラーmodulenotfounderror:ピクルスファイル「__builtin__」をロードした場合はどうすればよいですか?
Apr 02, 2025 am 06:27 AM
Python 3.6のロードピクルスファイルエラーmodulenotfounderror:ピクルスファイル「__builtin__」をロードした場合はどうすればよいですか?
Apr 02, 2025 am 06:27 AM
Python 3.6のピクルスファイルの読み込みエラー:modulenotfounderror:nomodulenamed ...
 FastapiとAIOHTTPは同じグローバルイベントループを共有していますか?
Apr 02, 2025 am 06:12 AM
FastapiとAIOHTTPは同じグローバルイベントループを共有していますか?
Apr 02, 2025 am 06:12 AM
Pythonの非同期ライブラリ間の互換性の問題Python、非同期プログラミングは、高い並行性とI/Oのプロセスになりました...
 Python 3.6にピクルスファイルをロードするときに「__Builtin__」モジュールが見つからない場合はどうすればよいですか?
Apr 02, 2025 am 07:12 AM
Python 3.6にピクルスファイルをロードするときに「__Builtin__」モジュールが見つからない場合はどうすればよいですか?
Apr 02, 2025 am 07:12 AM
Python 3.6のピクルスファイルのロードレポートエラー:modulenotFounderror:nomodulenamed ...
 Pythonの信号を介して親プロセスを殺した後に子プロセスも終了することを確認する方法は?
Apr 02, 2025 am 06:39 AM
Pythonの信号を介して親プロセスを殺した後に子プロセスも終了することを確認する方法は?
Apr 02, 2025 am 06:39 AM
子どものプロセスを使用して親プロセスを殺すときに実行され続ける子プロセスの問題と解決策。 Pythonプログラミングでは、信号を通じて親のプロセスを殺した後、子のプロセスはまだ...
