

ビデオの生成は非常に簡単です。ヒントを与えるだけで、オンラインで試すこともできます。

文字を入力してAIに動画を生成させる、これまでは想像の範囲でしか考えられなかった機能が、テクノロジーの発展により実現されました。
近年、生成人工知能はコンピューター ビジョンの分野で大きな注目を集めています。拡散モデルの出現により、テキスト プロンプトから高品質の画像を生成すること、つまりテキストと画像の合成が非常に一般的になり、成功しました。
最近の研究では、テキストから画像への拡散モデルをビデオ領域で再利用することで、テキストからビデオへの生成と編集のタスクまで拡張することに成功しました。このような方法では有望な結果が得られていますが、そのほとんどは大量のラベル付きデータを使用する広範なトレーニングを必要とし、多くのユーザーにとって費用が高すぎる可能性があります。
ビデオ生成を安価にするために、Jay Zhangjie Wu らが昨年提案した Tune-A-Video は、ビデオに安定拡散 (SD) モデルを適用するメカニズムを導入しました。分野 。調整する必要があるビデオは 1 つだけなので、トレーニングの負荷が大幅に軽減されます。これは以前の方法よりもはるかに効率的ですが、それでも最適化が必要です。さらに、Tune-A-Video の生成機能はテキストガイド付きビデオ編集アプリケーションに限定されており、ゼロからビデオを合成することは依然としてその能力を超えています。
この記事では、Picsart AI Research (PAIR)、テキサス大学オースティン校、およびその他の機関の研究者が、ゼロショットとトレーニングなしで新しいテキスト手法を実現しました。ビデオへの合成: 最適化や微調整を行わずに、テキスト プロンプトに基づいてビデオを生成するという問題の方向に一歩前進しました。

- 論文アドレス: https://arxiv.org/pdf /2303.13439.pdf
- プロジェクト アドレス: https://github.com/Picsart-AI-Research/Text2Video-Zero
- #トライアルアドレス: https://huggingface.co/spaces/PAIR/Text2Video-Zero



時間的一貫性を高めるために、この論文では 2 つの革新的な修正を提案します: (1) まず、生成されたフレームの潜在エンコーディングを動き情報で強化し、グローバル シーンと背景の時間的一貫性を維持します。 ; (2) ) 次に、クロスフレーム アテンション メカニズムを使用して、シーケンス全体にわたって前景オブジェクトのコンテキスト、外観、およびアイデンティティを保存します。実験によれば、これらの簡単な変更により、高品質で時間的に一貫したビデオが生成されることがわかりました (図 1 を参照)。
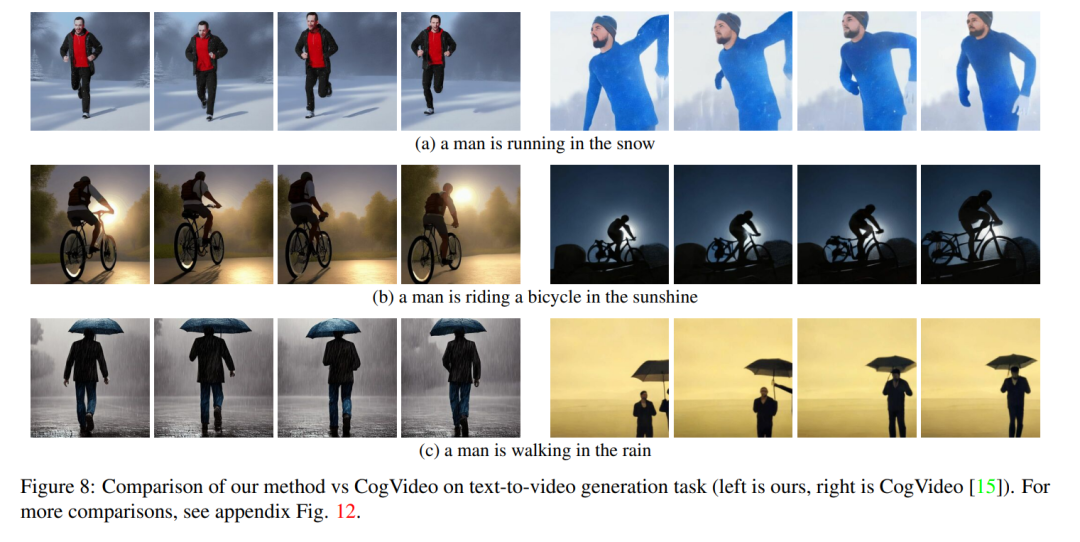
他の人の作業は大規模なビデオ データでトレーニングされましたが、私たちの方法は同様の、または場合によってはより優れたパフォーマンスを達成します (図 8 および 9 を参照)。
 #
#

 N (0, I) から m 個の潜在的なコードを個別にサンプリングし、適用することです。対応するテンソル
N (0, I) から m 個の潜在的なコードを個別にサンプリングし、適用することです。対応するテンソル 
(k = 1,…,m) を取得し、次のようにデコードする DDIM サンプル生成されたビデオ シーケンス
# を取得します。ただし、図 10 の最初の行に示すように、これにより完全にランダムな画像が生成され、オブジェクトの外観や動作の一貫性がなく、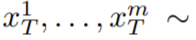
で記述されたセマンティクスのみが共有されます。
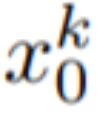
この問題を解決するために、この記事では次の 2 つの方法を推奨します。 (i) 潜在的なエンコーディング 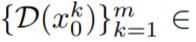 間にモーション ダイナミクスを導入して、グローバル シーンの時間的一貫性を維持します。(ii) クロスフレーム アテンション メカニズムを使用して、前景オブジェクトの外観とアイデンティティを保存します。この論文で使用されるメソッドの各コンポーネントについては以下で詳しく説明します。メソッドの概要は図 2 に示されています。
間にモーション ダイナミクスを導入して、グローバル シーンの時間的一貫性を維持します。(ii) クロスフレーム アテンション メカニズムを使用して、前景オブジェクトの外観とアイデンティティを保存します。この論文で使用されるメソッドの各コンポーネントについては以下で詳しく説明します。メソッドの概要は図 2 に示されています。 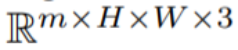
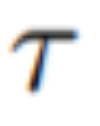
実験

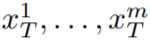 ## Text2Video-Zero のすべてのアプリケーションは、グローバル シーンと背景、前景、コンテキストの時間的一貫性を備えたビデオを正常に生成することを示しています。オブジェクトの外観とアイデンティティはシーケンス全体を通じて維持されます。
## Text2Video-Zero のすべてのアプリケーションは、グローバル シーンと背景、前景、コンテキストの時間的一貫性を備えたビデオを正常に生成することを示しています。オブジェクトの外観とアイデンティティはシーケンス全体を通じて維持されます。
テキストからビデオへの変換の場合、テキスト プロンプトとよく一致する高品質のビデオが生成されることがわかります (図 3 を参照)。例えば、パンダが自然に道を歩く姿が描かれています。同様に、追加のエッジまたはポーズ ガイダンス (図 5、図 6、および図 7 を参照) を使用すると、プロンプトとガイダンスに一致する高品質のビデオが生成され、良好な時間的一貫性とアイデンティティの保存が示されました。

#Video Instruct-Pix2Pix (図 1 を参照) の場合、生成されたビデオ指示に厳密に従いながら、入力ビデオに対して高い忠実度を実現します。
ベースラインとの比較
この文書では、その手法を 2 つの公的に利用可能なベースライン (CogVideo および Tune -A-) と比較します。ビデオ。 CogVideo はテキストからビデオへの変換方法であるため、この記事では、Tune-A-Video との比較に Video Instruct-Pix2Pix を使用して、プレーン テキスト ガイド付きビデオ合成シナリオで CogVideo と比較します。
定量的な比較のために、この記事ではビデオ テキストの整列度を表す CLIP スコアを使用してモデルを評価します。 CogVideo で生成された 25 個のビデオをランダムに取得し、この記事の方法に従って同じヒントを使用して対応するビデオを合成します。私たちの方法と CogVideo の CLIP スコアはそれぞれ 31.19 と 29.63 です。したがって、私たちの方法は CogVideo よりわずかに優れていますが、後者には 94 億のパラメーターがあり、ビデオでの大規模なトレーニングが必要です。
図 8 は、この論文で提案した方法のいくつかの結果を示し、CogVideo との定性的な比較を示しています。どちらの方法も、シーケンス全体を通じて良好な時間的一貫性を示し、オブジェクトのアイデンティティとそのコンテキストを維持します。私たちの方法は、より優れたテキストとビデオの位置合わせ機能を示しています。たとえば、図 8 (b) では、私たちのメソッドは太陽の下で自転車に乗っている人のビデオを正しく生成しますが、CogVideo は背景を月明かりに設定します。また、図 8 (a) では、私たちの方法では雪の中を走っている人が正しく表示されていますが、CogVideo によって生成されたビデオでは雪と走っている人がはっきりと見えません。
ビデオ Instruct-Pix2Pix の定性的結果と、フレームごとの Instruct-Pix2Pix および Tune-AVideo との視覚的比較を図 9 に示します。 Instruct-Pix2Pix はフレームごとに優れた編集パフォーマンスを示しますが、時間的な一貫性に欠けています。これは、スキーヤーを描いたビデオで特に顕著で、雪と空がさまざまなスタイルと色を使用して描かれています。これらの問題は、Video Instruct-Pix2Pix メソッドを使用して解決され、シーケンス全体で時間的に一貫したビデオ編集が可能になりました。
Tune-A-Video は時間一貫性のあるビデオ生成を作成しますが、この記事の方法と比較すると、指示ガイダンスとの一貫性が低く、ローカル編集の作成が難しく、入力の詳細が異なります。順序が失われます。これは、図 9 左に示されているダンサーのビデオの編集を見ると明らかです。 Tune-A-Video と比較して、私たちの方法では、ダンサーの後ろの壁はほとんど変化せずに残るなど、背景をよりよく保存しながら、衣装全体をより明るくペイントします。 Tune-A-Video は大きく変形した壁をペイントします。さらに、私たちの方法は入力の詳細により忠実です。たとえば、Tune-A-Video と比較して、Video struction-Pix2Pix は提供されたポーズを使用してダンサーを描画し (図 9 左)、入力ビデオに登場するすべてのスキーヤーを表示します。図 9 の右側の最後のフレームに示すように)。 Tune-A-Video の上記の弱点はすべて、図 23、24 でも確認できます。

 #
#
以上がビデオの生成は非常に簡単です。ヒントを与えるだけで、オンラインで試すこともできます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7449
7449
 15
1374
52
77
11
14
7
15
1374
52
77
11
14
7

 他人の動画をDouyinに投稿することは侵害になりますか?侵害せずにビデオを編集するにはどうすればよいですか?
Mar 21, 2024 pm 05:57 PM
他人の動画をDouyinに投稿することは侵害になりますか?侵害せずにビデオを編集するにはどうすればよいですか?
Mar 21, 2024 pm 05:57 PM
ショートビデオプラットフォームの台頭により、Douyinはみんなの日常生活に欠かせないものになりました。 TikTokでは世界中の面白い動画を見ることができます。他人のビデオを投稿することを好む人もいますが、「Douyin は他人のビデオを投稿することを侵害しているのでしょうか?」という疑問が生じます。この記事では、この問題について説明し、著作権を侵害せずに動画を編集する方法と、著作権侵害の問題を回避する方法について説明します。 1.Douyin による他人の動画の投稿は侵害ですか?私の国の著作権法の規定によれば、著作権者の著作物を著作権者の許可なく無断で使用することは侵害となります。したがって、オリジナルの作者または著作権所有者の許可なしに他人のビデオをDouyinに投稿することは侵害となります。 2. 著作権を侵害せずにビデオを編集するにはどうすればよいですか? 1. パブリックドメインまたはライセンスされたコンテンツの使用: パブリック
 Douyin に動画を投稿して収益を得るにはどうすればよいですか?初心者はどうやってDouyinでお金を稼ぐことができますか?
Mar 21, 2024 pm 08:17 PM
Douyin に動画を投稿して収益を得るにはどうすればよいですか?初心者はどうやってDouyinでお金を稼ぐことができますか?
Mar 21, 2024 pm 08:17 PM
全国的なショートビデオプラットフォームであるDouyinは、自由な時間にさまざまな興味深く斬新なショートビデオを楽しむことができるだけでなく、自分自身を示し、自分の価値観を実現するステージも提供します。では、Douyin に動画を投稿してお金を稼ぐにはどうすればよいでしょうか?この記事ではこの質問に詳しく答え、TikTokでより多くのお金を稼ぐのに役立ちます。 1.Douyin に動画を投稿してお金を稼ぐにはどうすればよいですか?動画を投稿し、Douyin で一定の再生回数を獲得すると、広告共有プランに参加できるようになります。この収入方法はDouyinユーザーにとって最も馴染みのある方法の1つであり、多くのクリエイターにとって主な収入源でもあります。 Douyin は、アカウントの重み、動画コンテンツ、視聴者のフィードバックなどのさまざまな要素に基づいて、広告共有の機会を提供するかどうかを決定します。 TikTok プラットフォームでは、視聴者がギフトを送ったり、
 画質を圧縮せずにWeiboに動画を投稿する方法_画質を圧縮せずにWeiboに動画を投稿する方法
Mar 30, 2024 pm 12:26 PM
画質を圧縮せずにWeiboに動画を投稿する方法_画質を圧縮せずにWeiboに動画を投稿する方法
Mar 30, 2024 pm 12:26 PM
1. まず携帯電話で Weibo を開き、右下隅の [Me] をクリックします (図を参照)。 2. 次に、右上隅の [歯車] をクリックして設定を開きます (図を参照)。 3. 次に、[一般設定] を見つけて開きます (図を参照)。 4. 次に、[Video Follow] オプションを入力します (図を参照)。 5. 次に、[ビデオアップロード解像度]設定を開きます(図を参照)。 6. 最後に、圧縮を避けるために [オリジナルの画質] を選択します (図を参照)。
 おすすめのAI支援プログラミングツール4選
Apr 22, 2024 pm 05:34 PM
おすすめのAI支援プログラミングツール4選
Apr 22, 2024 pm 05:34 PM
この AI 支援プログラミング ツールは、急速な AI 開発のこの段階において、多数の有用な AI 支援プログラミング ツールを発掘しました。 AI 支援プログラミング ツールは、開発効率を向上させ、コードの品質を向上させ、バグ率を減らすことができます。これらは、現代のソフトウェア開発プロセスにおける重要なアシスタントです。今日は Dayao が 4 つの AI 支援プログラミング ツールを紹介します (すべて C# 言語をサポートしています)。皆さんのお役に立てれば幸いです。 https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot は、より少ない労力でより迅速にコードを作成できるようにする AI コーディング アシスタントであり、問題解決とコラボレーションにより集中できるようになります。ギット
 小紅書ビデオ作品を公開するにはどうすればよいですか?動画を投稿する際に注意すべきことは何ですか?
Mar 23, 2024 pm 08:50 PM
小紅書ビデオ作品を公開するにはどうすればよいですか?動画を投稿する際に注意すべきことは何ですか?
Mar 23, 2024 pm 08:50 PM
短編ビデオ プラットフォームの台頭により、Xiaohongshu は多くの人々が自分の生活を共有し、自分自身を表現し、トラフィックを獲得するためのプラットフォームになりました。このプラットフォームでは、ビデオ作品の公開が非常に人気のある交流方法です。では、小紅書ビデオ作品を公開するにはどうすればよいでしょうか? 1.小紅書ビデオ作品を公開するにはどうすればよいですか?まず、共有できるビデオ コンテンツがあることを確認します。携帯電話やその他のカメラ機器を使用して撮影することもできますが、画質と音声の明瞭さには注意する必要があります。 2.ビデオを編集する:作品をより魅力的にするために、ビデオを編集できます。 Douyin、Kuaishou などのプロ仕様のビデオ編集ソフトウェアを使用して、フィルター、音楽、字幕、その他の要素を追加できます。 3. 表紙を選択する: 表紙はユーザーのクリックを誘致するための鍵です。ユーザーのクリックを誘致するために、表紙には鮮明で興味深い写真を選択してください。
 音声なしのエッジブラウザ Web ビデオを共有するための 2 つのソリューション
Mar 14, 2024 pm 02:22 PM
音声なしのエッジブラウザ Web ビデオを共有するための 2 つのソリューション
Mar 14, 2024 pm 02:22 PM
多くのユーザーはブラウザで動画を視聴することを好みますが、Edge ブラウザで Web 動画を視聴するときに音が出ない場合は、どうすれば問題を解決できますか?この問題は難しいことではありません. 次に、Edge ブラウザの Web 動画で音が出ない問題を解決する方法を説明します。 Edge ブラウザの Web ビデオに音声がありませんか?方法 1: 1. まず、Edge ブラウザの上部タブを確認します。 2. タブの左側に「サウンドボタン」がありますので、ミュートになっていないことを確認してください。方法 2: 1. サウンドがミュートされていないことが確認された場合は、サウンド設定に問題がある可能性があります。 2. 右下隅にあるサウンドデバイスを右クリックし、「ボリュームシンセサイザーを開く」を選択します。 3. 開く
 Go 言語を使用してモバイル アプリケーションを開発する方法を学ぶ
Mar 28, 2024 pm 10:00 PM
Go 言語を使用してモバイル アプリケーションを開発する方法を学ぶ
Mar 28, 2024 pm 10:00 PM
Go 言語開発モバイル アプリケーション チュートリアル モバイル アプリケーション市場が活況を続ける中、ますます多くの開発者が Go 言語を使用してモバイル アプリケーションを開発する方法を検討し始めています。シンプルで効率的なプログラミング言語として、Go 言語はモバイル アプリケーション開発でも大きな可能性を示しています。この記事では、Go 言語を使用してモバイル アプリケーションを開発する方法を詳しく紹介し、読者がすぐに始めて独自のモバイル アプリケーションの開発を開始できるように、具体的なコード例を添付します。 1. 準備 始める前に、開発環境とツールを準備する必要があります。頭
 どのAIプログラマーが一番優れているでしょうか? Devin、Tongyi Lingma、SWE エージェントの可能性を探る
Apr 07, 2024 am 09:10 AM
どのAIプログラマーが一番優れているでしょうか? Devin、Tongyi Lingma、SWE エージェントの可能性を探る
Apr 07, 2024 am 09:10 AM
世界初の AI プログラマー Devin の誕生から 1 か月も経たない 2022 年 3 月 3 日、プリンストン大学の NLP チームはオープンソース AI プログラマー SWE-agent を開発しました。 GPT-4 モデルを利用して、GitHub リポジトリの問題を自動的に解決します。 SWE ベンチ テスト セットにおける SWE エージェントのパフォーマンスは Devin と同様で、平均 93 秒かかり、問題の 12.29% を解決しました。専用端末と対話することで、SWE エージェントはファイルの内容を開いて検索したり、自動構文チェックを使用したり、特定の行を編集したり、テストを作成して実行したりできます。 (注: 上記の内容は元の内容を若干調整したものですが、原文の重要な情報は保持されており、指定された文字数制限を超えていません。) SWE-A
