
 テクノロジー周辺機器
AI
トレーニング費用は 1,000 元未満で、90% 削減されます。 NUS と清華大学が VPGTrans をリリース: GPT-4 のようなマルチモーダル大規模モデルを簡単にカスタマイズ
テクノロジー周辺機器
AI
トレーニング費用は 1,000 元未満で、90% 削減されます。 NUS と清華大学が VPGTrans をリリース: GPT-4 のようなマルチモーダル大規模モデルを簡単にカスタマイズ
トレーニング費用は 1,000 元未満で、90% 削減されます。 NUS と清華大学が VPGTrans をリリース: GPT-4 のようなマルチモーダル大規模モデルを簡単にカスタマイズ

今年はAI技術が爆発的に発展した年で、ChatGPTに代表される大規模言語モデル(LLM)が普及しました。
自然言語の分野で大きな可能性を示すことに加えて、言語モデルは他のモダリティにも徐々に広がり始めています。たとえば、ヴィンセント グラフ モデルの安定拡散にも言語が必要です。モデル。
ビジュアル言語モデル (VL-LLM) を最初からトレーニングするには、多くの場合、大量のリソースが必要となるため、既存のソリューションでは、言語モデルとビジュアル キュー生成モデル (ビジュアル プロンプト ジェネレーター、VPG) を組み合わせています。 )、しかしそれでも、VPG の調整を続けるには、依然として数千の GPU 時間と数百万のトレーニング データが必要です。
最近、シンガポール国立大学と清華大学の研究者は、既存の VPG を既存の VL-LLM モデルに移行するためのソリューション VPGTrans を提案しました。低コストの方法。

論文リンク: https://arxiv.org/abs/2305.01278
コードリンク: https://github.com/VPGTrans/VPGTrans
マルチモーダル対話モデルのデモ :https: //vpgtrans.github.io/
著者: Zhang Ao、Fei Hao、Yao Yuan、Ji Wei、Li Li、Liu Zhiyuan、Chua Tat-Seng
単位: シンガポール国立大学、清華大学
この記事の主な革新点は次のとおりです。
1. 非常に低いトレーニングコスト:
私たちが提案した VPGTrans メソッドを通じて、 迅速に (トレーニング時間の 10% 未満) 既存のマルチモーダル対話モデルのビジュアル モジュールを新しい言語モデルに移行し、同様またはより良い結果を達成できます。
たとえば、ビジョン モジュールを最初からトレーニングする場合と比較して、BLIP-2 FlanT5-XXL のトレーニング オーバーヘッドを 19,000 RMB から 1,000 RMB 未満に削減できます:
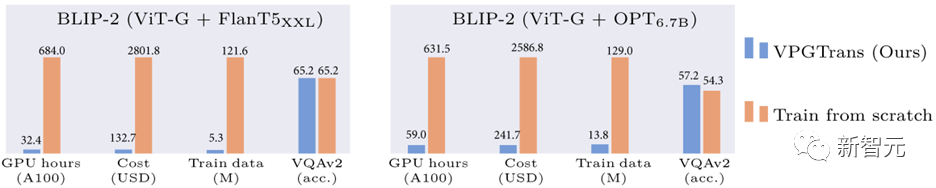
図 1: VPGTrans メソッドに基づく BLIP-2 トレーニングのオーバーヘッド削減の比較
#2. マルチモーダルな大規模モデルのカスタマイズ:
を通じて実行できます。 VPGTrans フレームワーク ニーズに応じて、さまざまな新しい大規模言語モデルのビジュアル モジュールを柔軟に追加します。例えば、LLaMA-7BとVicuna-7BをベースにしてVL-LLaMAとVL-Vicunaを作製しました。
#3. オープンソースのマルチモーダル対話モデル:
高品質のマルチモーダル対話を実現できる GPT-4 のようなマルチモーダル対話モデルである VL-Vicuna をオープンソース化しました:
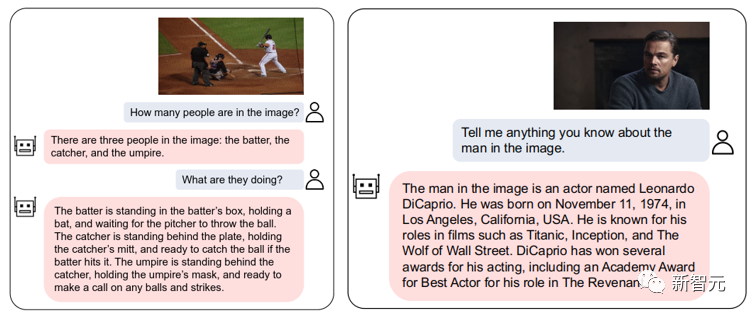
図 2: VL とビクーニャの相互作用の例
1. モチベーションの概要1.1 背景
LLM は、従来の事前トレーニング済み視覚言語モデル (VLM) から大規模言語モデルに基づく視覚言語モデル (VL-LLM) まで、マルチモーダル理解の分野で革命を引き起こしました。 )。
ビジュアルモジュールをLLMに接続することで、VL-LLMは既存のLLMの知識、ゼロサンプル汎化能力、推論能力、計画能力などを継承することができます。関連機種としては、BLIP-2[1]、Flamingo[2]、PALM-Eなどがあります。

#図 3: 一般的に使用される VL-LLM アーキテクチャ
既存の一般的に使用されている VL-LLM は、基本的に図 3 に示すアーキテクチャを採用しています。ビジュアル ソフト プロンプト生成モジュール (Visual Prompt Generator、VPG) は、ベース LLM と次元変換用の線形モデルに基づいてトレーニングされます。レイヤー(プロジェクター)。
パラメータのスケールに関しては、通常、LLM が主要な部分 (11B など) を占めます。 、VPG はマイナーな部分 (1.2B など) を占めます。プロジェクターは最小(4M)です。
トレーニング プロセス中、通常、LLM パラメータは更新されないか、 または非常に少数のパラメータのみが更新されます。トレーニング可能なパラメータは主に VPG とプロジェクターから取得されます。
1.2 動機
実際には、たとえベース LLM のパラメータが凍結されてトレーニングされなかったとしても、パラメータの量が大きいため、 LLM、VL のトレーニング - LLM の重要なオーバーヘッドは依然としてベース LLM のロードです。
したがって、VL-LLM をトレーニングしても、依然として膨大な計算コストが避けられません。たとえば、BLIP-2 (ベース LLM は FlanT5-XXL) を取得するには、600 時間以上の A100 トレーニング時間が必要です。 AmazonのA100-40G機をレンタルすると2万元近くかかります。
VPG を最初からトレーニングするのは非常に費用がかかるため、コストを節約するために既存の VPG を新しい LLM に移行できないかどうかを検討し始めました。
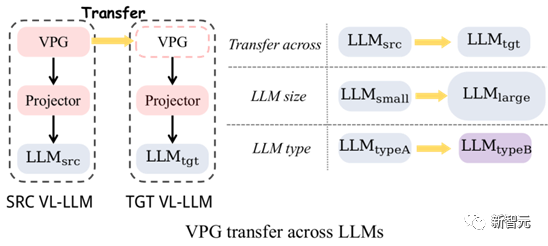
図 4: VPG の移行: LLM サイズ間の移行と LLM タイプ間の移行
図 4 に示すように、主に 2 種類の VPG の移行を調査しました。(1) LLM サイズ間の移行 (TaS) ) : たとえば、OPT-2.7B から OPT-6.7B へ。
(2) LLM 間タイプ移行 (TaT): OPT から FlanT5 など。
TaS の重要性は次のとおりです。LLM 関連の科学研究では、通常、小さな LLM でパラメータを調整してから、大きな LLM に拡張する必要があります。 TaS を使用すると、小さい LLM でトレーニングされた VPG をパラメーターを調整した後、大きい LLM に直接移行できます。
TaTの意義は、今日はLLaMA、明日はアルパカとビクーニャというように、異なる機能を持ったLLMが無限に現れることにあります。 TaT を使用すると、既存の VPG を使用して、新しい言語モデルに視覚認識機能を迅速に追加できます。
#1.3 貢献
(1) 効率的な手法の提案:
私たちはまず、一連の探索的実験を通じて、VPG の移行効率に影響を与える主要な要因を調査しました。探索的な実験結果に基づいて、2 段階の効率的な移行フレームワークVPGTrans を提案します。このフレームワークにより、計算オーバーヘッドと VL-LLM のトレーニングに必要なトレーニング データを大幅に削減できます。
たとえば、最初からトレーニングする場合と比較して、BLIP-2 OPT-2.7B を 6.7B VPG に移行することで使用できるデータと計算時間は約 10% のみです。 各データセットで同様またはより良い結果を達成します (図 1) 。 トレーニング費用の範囲は 17,901 RMB ~ 1,673 RMB です。
(2) 興味深い発見を得る:
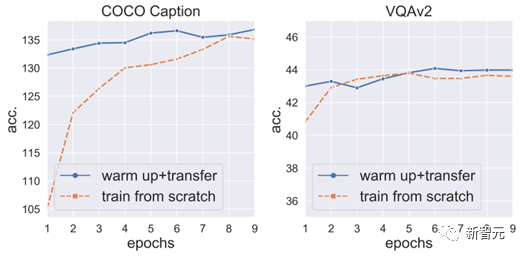
TaS シナリオと TaT シナリオの両方でいくつかの興味深い結果を提供します。説明してみてください:a) TaS シナリオでは、VPGTrans を使用して小規模から大規模に移行しても、最終的なモデルの効果には影響しません。 b) TaS シナリオでは、言語モデルでトレーニングされた VPG が小さいほど、大規模モデルへの移行時の効率が高くなり、最終的な効果が向上します。 c) TaT シナリオでは、モデルが小さいほど、移行ギャップは大きくなります。私たちの検証実験では、VPGTrans を使用した OPT350M と FlanT5 ベース間の相互移行は、最初からトレーニングするのとほぼ同じくらい遅くなります。 (3) オープンソース: VPGTrans VL を使用して 2 つの新しいソースを入手しました-LLM: VL-LLaMA および VL-Vicuna は、コミュニティでオープンソース化されています。その中でも、VL-Vicuna は GPT4 と同様の高品質なマルチモーダル対話を実装しています。 まず、VPG の移行効率を最大化する方法を分析するために、一連の探索および検証実験を実施します。次に、これらの重要な観察に基づいてソリューションを提案します。 基本モデルとして BLIP-2 アーキテクチャを選択し、事前トレーニング コーパスは COCO と SBU を使用します。合計 140 万の画像とテキストのペア。 ダウンストリーム タスクは、COCO Caption、NoCaps、VQAv2、GQA、および OK-VQA のゼロショット設定を使用して評価されます (キャプション タスクは厳密にはゼロショットではありません)。以下は私たちの主な発見です: (1) トレーニングされた VPG を直接継承すると収束を加速できますが、その効果は限定的です: LLM でトレーニングされた VPG を大規模な LLM に直接移行すると、モデルの収束を加速できることがわかりましたが、その加速効果は限られており、収束後のモデルの効果は と比較されます。 VPG を最初からトレーニングすると、ポイントが低下します (図 5 の VQAv2 と GQA の青い線の最高点は両方ともオレンジ色の線よりも低くなります) 。 この低下は、ランダムに初期化されたプロジェクターがトレーニングの開始時に VPG の既存の視覚認識能力にダメージを与えるという事実によるものと推測されます。 2. 高効率の VPG 移行ソリューション: VPGTrans
2.1 探索実験

#実装された VPG を直接継承した結果を次の図に示します (青い曲線)。 VPG の再トレーニング (オレンジ色の線): VPG を最初から再トレーニングします。実施されるトレーニングはリニア プロジェクターに関するものだけであり、VPG に関するトレーニングは行われません。
(2) 最初にプロジェクターのウォームアップ トレーニングを行うと、ポイントの低下を防ぎ、収束をさらに加速できます:
そこで、VPG と LLM を修正し、最初にプロジェクターを 3 エポックの間ウォームアップ トレーニングし、次にトレーニングの次のステップのために VPG を解凍しました。
これにより、ポイントのドロップが回避されるだけでなく、VPG の収束がさらに加速されることがわかりました (図 6)。
しかし、トレーニングの主なコストは LLM (巨大なパラメータ) であるため、プロジェクターのトレーニングのみのコストであることを強調する価値があります。 VPG とプロジェクターを同時にトレーニングする よりもはるかに安価ではありません。 そこで、私たちはプロジェクターのウォームアップを加速するための主要なテクノロジーの探索を開始しました。
(3) ワード ベクトル コンバーターの初期化により、プロジェクターのウォームアップが高速化されます:
まず、VPG は画像を LLM が理解できるソフト プロンプトに変換することでエフェクトを生成します。 ソフト プロンプト の使用法は実際には と非常によく似ており、すべて言語モデルを直接入力します。モデルに対応するコンテンツを生成するように促します。 #そこで、ソフト プロンプトのプロキシとして単語ベクトルを使用し、 を # にトレーニングしました。 次に、ワード ベクトル コンバーターとプロジェクターを 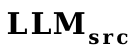 ## のワード ベクトル コンバーター (線形層)。
## のワード ベクトル コンバーター (線形層)。 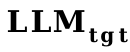
この初期化により、プロジェクターのウォームアップ トレーニングを 3 エポックから 2 エポック に減らすことができます。 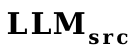
(4) プロジェクターは、非常に大きな学習率で迅速に収束できます。
さらに実験を行った結果、次のことがわかりました。パラメーターの数が少ないため、クラッシュすることなく通常の学習率の 5 倍を使用してトレーニングできます。学習率 5 倍のトレーニングにより、プロジェクターのウォームアップを さらに 1 エポック
に短縮できます。(5) 追加の発見:
プロジェクターのウォームアップは重要ですが、プロジェクターのトレーニングだけでは十分ではありません。特にキャプション タスクでは、プロジェクターのみをトレーニングした場合の効果は、VPG を同時にトレーニングした場合の効果よりも悪くなります (図 5 の緑の線は、COCO Caption と NoCaps の両方の青の線よりもはるかに低くなります)。
これは、プロジェクターをトレーニングするだけではアンダーフィッティングにつながる
、つまり、をトレーニング データと完全に一致させることができないことを意味します。
#2.2 提案手法
# #図 7: VPGTrans フレームワーク: (1) フェーズ 1: プロジェクターのウォームアップ (2) フェーズ 2: 全体的な微調整
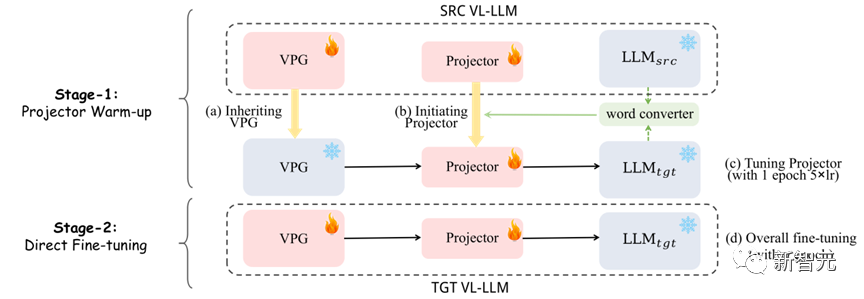 図 7 に示すように、私たちの方法
図 7 に示すように、私たちの方法
(1) 第 1 段階: 最初にワード ベクトル コンバーターを使用して、新しいプロジェクターの初期化として元のプロジェクターと融合し、次に、新しいプロジェクターは、1 エポックで 5 倍の学習率でトレーニングされます。
(2) 第 2 段階: VPG とプロジェクターを通常どおり直接トレーニングします。3. 実験結果
3.1 高速化率
表 1: さまざまなデータ セットで最初からトレーニングした場合と比較した VPGTrans の高速化率
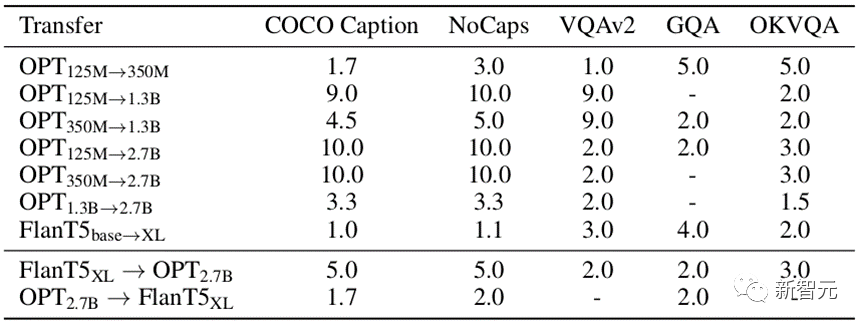 表 1 に示すように、さまざまな移行タイプをテストしました。さまざまなデータセットでの VPGTrans の速度向上率。
表 1 に示すように、さまざまな移行タイプをテストしました。さまざまなデータセットでの VPGTrans の速度向上率。
指定されたデータセット A に対する VPGTrans の加速率は、A に対する最良の効果 a を達成するためのゼロからのトレーニングのラウンド数を、A に対する VPGTrans の効果が超える最小トレーニング ラウンド数で割ることによって得られます。 a.
たとえば、OPT-2.7B で VPG を最初からトレーニングするには、COCO キャプションで最高の効果を得るには 10 エポックが必要ですが、VPG を OPT-125M から OPT-2.7B に移行する場合は、わずか 10 エポックしかかかりませんこの最適な効果を達成するには 1 エポックかかります。加速比は10/1=10倍となります。
TaS シナリオでも TaT シナリオでも、当社の VPGTrans は安定した加速を達成できることがわかります。
3.2 興味深い調査結果
説明するために、より興味深い調査結果の 1 つを選択しました。さらに興味深い調査結果については、論文を参照してください。
#TaS シナリオでは、言語モデルでトレーニングされた VPG が小さいほど、移行効率が高くなり、最終的なモデル効果が向上します。表 1 を参照すると、OPT-1.3B から OPT-2.7B への加速比は、OPT-125M および OPT-350M から OPT-2.7b への加速比よりもはるかに小さいことがわかります。
説明を提供しようとしました: 一般に、言語モデルが大きくなるほど、テキスト空間の次元が高くなるため、 の可能性が高くなります。 VPG (VPG は通常、CLIP に似た事前トレーニング済みモデル) 独自の視覚認識能力を損傷します。線形プローブと同様の方法で検証しました。
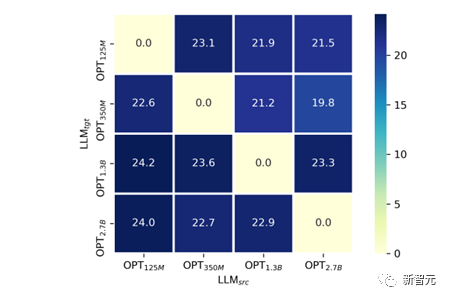
図 8 に示すように、OPT-125M、350M、1.3B、および 2.7B の間でクロス LLM サイズ移行を実行しました。サイズ移行。
実験では、
さまざまなモデル サイズでトレーニングされた VPG の視覚認識能力を公平に比較するために、VPG のパラメーターを固定し、リニア プロジェクター層のみをトレーニングしました。視覚認識能力の尺度として、COCO Caption の SPICE 指標を選択しました。与えられたそれぞれの
について、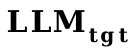 が小さいほど、ほぼ一致していることを見つけるのは難しくありません。最終的な SPICE A 高現象が小さいほど。
が小さいほど、ほぼ一致していることを見つけるのは難しくありません。最終的な SPICE A 高現象が小さいほど。 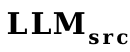 3.3 大規模実験
3.3 大規模実験
これまでの実験は主に小規模シナリオでの推測を検証することを目的としています。私たちの方法の有効性を証明するために、BLIP-2 の事前トレーニング プロセスをシミュレートし、大規模な実験を実施しました。
##表 2: 実際のシナリオにおける大規模な実験結果
表 2 に示すように、VPGTrans は大規模なシナリオでも依然として有効です。 。 OPT-2.7B から OPT-6.7B に移行することにより、同等以上の結果を達成するために使用したデータは 10.8% のみ、トレーニング時間は 10% 未満でした。
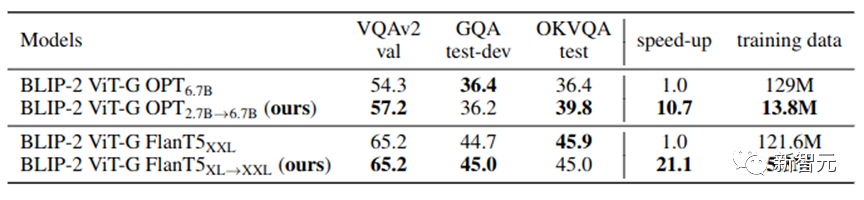
4.7% のトレーニングコスト制御 を達成しています。 4. VL-LLM をカスタマイズする
当社の VPGTrans は、視覚認識モジュールを新しい LLM にすばやく追加し、それによってまったく新しい高品質 VL-LLM を取得できます。この作業では、VL-LLaMA と VL-Vicuna を追加でトレーニングします。 VL-LLaMA の効果は次のとおりです。
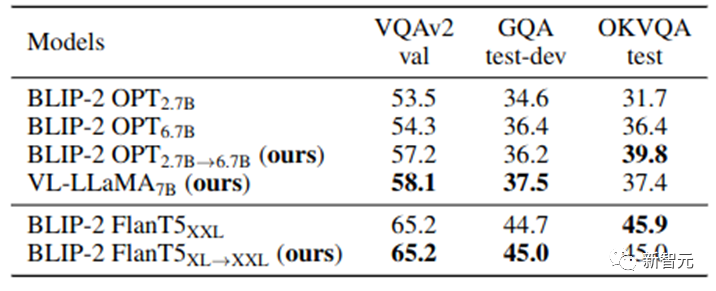
#表 3: VL-LLaMA の効果表示
At the同時に、当社の VL-Vicuna は GPT-4 のようなマルチモーダルな会話を行うことができます。 MiniGPT-4 と簡単に比較しました:
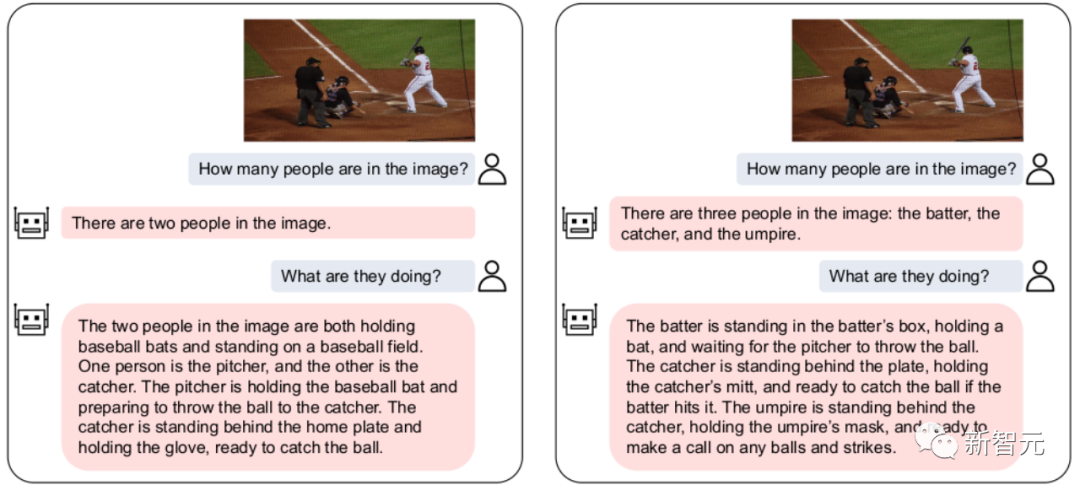
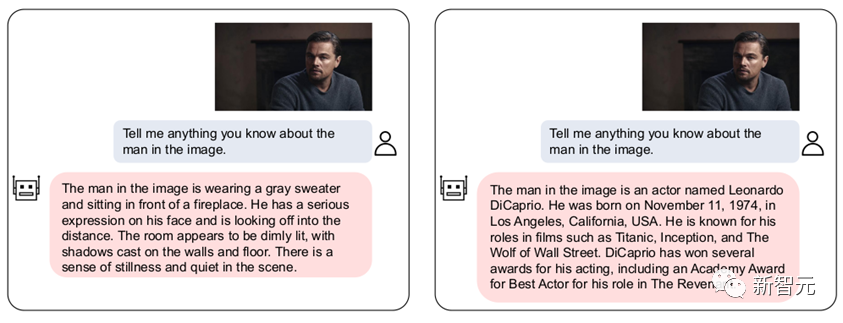
この作業では、LLM 間の VPG の移植性の問題について包括的な調査を実施しました。まず、移行効率を最大化する重要な要素を検討します。
主要な観察に基づいて、私たちは新しい 2 段階の移行フレームワーク、つまり VPGTrans を提案します。トレーニング コストを大幅に削減しながら、同等以上のパフォーマンスを達成できます。
VPGTrans を通じて、BLIP-2 OPT 2.7B から BLIP-2 OPT 6.7B への VPG の移行を実現しました。 VPG を最初から OPT 6.7B に接続する場合と比較して、VPGTrans に必要なトレーニング データは 10.7% のみで、トレーニング時間は 10% 未満です。
さらに、一連の興味深い調査結果とその背後にある考えられる理由を紹介し、議論します。最後に、VL-LLaMA と LL-Vicuna をトレーニングすることにより、新しい VL-LLM をカスタマイズする際の VPGTrans の実用的な価値を示します。
以上がトレーニング費用は 1,000 元未満で、90% 削減されます。 NUS と清華大学が VPGTrans をリリース: GPT-4 のようなマルチモーダル大規模モデルを簡単にカスタマイズの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7450
7450
 15
1374
52
77
11
14
8
15
1374
52
77
11
14
8

 ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
DALL-E 3は、前モデルより大幅に改良されたモデルとして2023年9月に正式導入されました。これは、複雑な詳細を含む画像を作成できる、これまでで最高の AI 画像ジェネレーターの 1 つと考えられています。ただし、発売当初は対象外でした
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
FP8 以下の浮動小数点数値化精度は、もはや H100 の「特許」ではありません。 Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考え、Microsoft DeepSpeed チームは NVIDIA からの公式サポートなしで A100 上で FP6 の実行を開始しました。テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化が INT4 に近いか、場合によってはそれよりも高速であり、後者よりも精度が高いことを示しています。これに加えて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeed などの深層学習推論フレームワークに統合されています。この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットの 2.65 倍になります。 1つ
 オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
前に書かれたプロジェクトのリンク: https://nianticlabs.github.io/mickey/ 2 枚の写真が与えられた場合、それらの写真間の対応関係を確立することで、それらの間のカメラのポーズを推定できます。通常、これらの対応は 2D 対 2D であり、推定されたポーズはスケール不定です。いつでもどこでもインスタント拡張現実などの一部のアプリケーションでは、スケール メトリクスの姿勢推定が必要なため、スケールを回復するために外部深度推定器に依存します。この論文では、3D カメラ空間でのメトリックの対応を予測できるキーポイント マッチング プロセスである MicKey を提案します。画像全体の 3D 座標マッチングを学習することで、相対的なメトリックを推測できるようになります。
