

スターマークが10万個を突破しました! Auto-GPT の後、Transformer は新たなマイルストーンに到達

2017 年、Google チームは論文「Attending Is All You Need」で画期的な NLP アーキテクチャ Transformer を提案し、それ以来不正行為を続けています。
このアーキテクチャは、長年にわたり、Microsoft、Google、Meta などの大手テクノロジー企業で人気がありました。一世を風靡したChatGPTもTransformerをベースに開発されました。
そして本日、GitHub での Transformer のスター評価が 100,000 を超えました。
チャットボット プログラムとして始まった Hugging Face は、Transformer モデルの中心的存在として名声を高め、世界的に有名なオープンソース コミュニティ。
このマイルストーンを記念して、Hugging Face は Transformer アーキテクチャに基づいた 100 のプロジェクトもまとめました。
Transformer は機械学習界に爆発をもたらしました
2017 年 6 月に Google が「必要なのは注意だけです」という論文を発表したとき、おそらく誰もこのディープ ラーニング アーキテクチャについて思いつきませんでした。トランスフォーマー それはどれほど多くの驚きをもたらすことができますか。
Transformer は、その誕生以来、AI 分野の礎の王となりました。 2019年、Googleもこれに特化した特許を申請した。

Transformer が NLP 分野で主流の地位を占めるにつれて、国境を越えて他の分野にも進出し始めており、ますます多くの仕事が行われています。それを CV 領域に誘導してみてください。
多くのネチズンは、トランスフォーマーがこのマイルストーンを突破するのを見て非常に興奮しました。
「私は多くの人気のあるオープンソース プロジェクトに貢献してきましたが、Transformer が GitHub で 10,000 スターに達したのを見て、
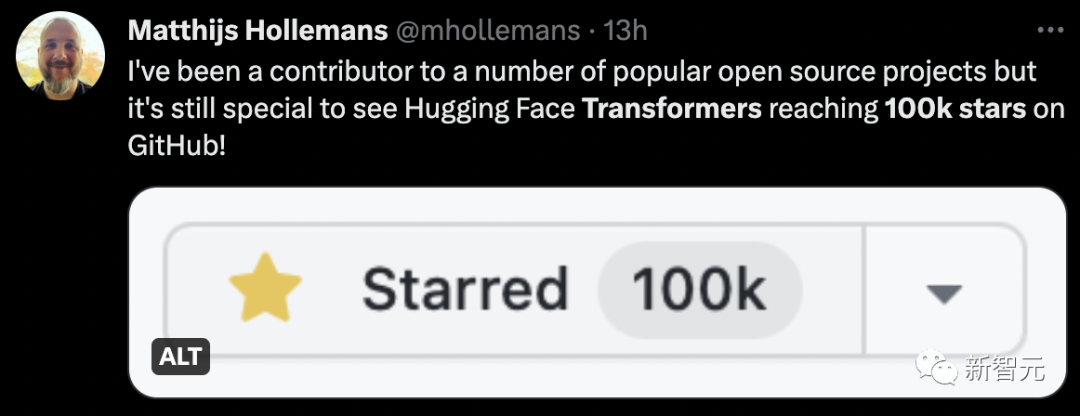
#少し前に、Auto-GPT の GitHub スターの数が、 pytorch. は大きな波紋を引き起こしました。
ネチズンは、Auto-GPT が Transformer とどう違うのか疑問に思わずにはいられませんか?

実際、Auto-GPT は Transformer をはるかに上回り、すでに 130,000 個のスターを持っています。
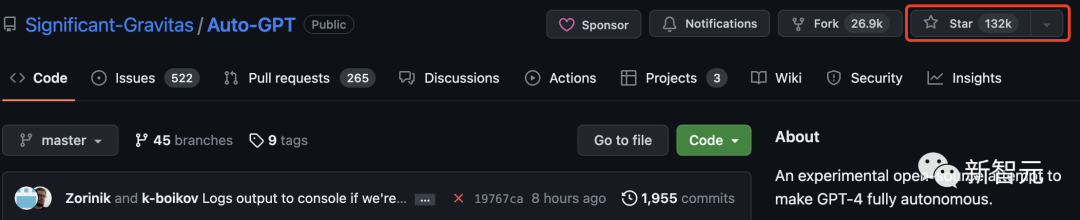
現在、Tensorflow には 170,000 個を超えるスターがあります。 Transformer は、これら 2 つのプロジェクトに次いで 100,000 を超える星評価を持つ 3 番目の機械学習ライブラリであることがわかります。
一部のネチズンは、Transformers ライブラリを初めて使用したとき、それが「pytorch-pretrained-BERT」と呼ばれていたことを思い出しました。
トランスフォーマーに基づく 50 の素晴らしいプロジェクト
トランスフォーマーは、事前トレーニングされたモデルを使用するツールキットであるだけでなく、トランスフォーマーとハギング フェイス ハブ コミュニティを中心に構築されたプロジェクトでもあります。
次のリストでは、Hugging Face がトランスフォーマーに基づいた 100 の驚くべき斬新なプロジェクトをまとめています。

以下に、紹介する最初の 50 プロジェクトを選択しました:
gpt4all
gpt4all は、オープンソースのチャットボット エコシステムです。コード、ストーリー、会話などのクリーンなアシスタント データの大規模なコレクションに基づいてトレーニングされます。 LLaMA や GPT-J などのオープンソースの大規模言語モデルを、アシスタント形式でトレーニングするために提供します。
#キーワード: オープンソース、LLaMa、GPT-J、手順、アシスタント
このリポジトリには、Jupiter ノートブックの形式で提供される、レコメンダー システムを構築するための例とベスト プラクティスが含まれています。データの準備、モデリング、評価、モデルの選択と最適化、運用化など、効果的なレコメンデーション システムを構築するために必要ないくつかの側面をカバーしています。
キーワード: レコメンデーション システム、AzureML
lama-cleaner安定拡散技術に基づく画像修復ツール。画像から不要な物体、欠陥、さらには人物を消去し、画像上のあらゆるものを置き換えることができます。
#キーワード: パッチ、SD、安定拡散
 ##フレア
##フレア
キーワード: NLP、テキスト埋め込み、ドキュメント埋め込み、生物医学、NER、PoS、感情分析
#mindsdb
キーワード: データベース、ローコード、AI テーブル
langchain
Langchain は、互換性のあるコードの開発を支援するように設計されています。 LLM およびその他のナレッジ ソース アプリケーション。このライブラリを使用すると、アプリケーションへの呼び出しを連鎖させて、多くのツールでシーケンスを作成できます。キーワード: LLM、大規模言語モデル、エージェント、チェーン
ParlAI
ParlAI は、オープンドメインのチャットからタスク指向の対話、視覚的な質問応答まで、対話モデルのトレーニングとテストのための Python フレームワーク。 100 を超えるデータセット、多くの事前トレーニング済みモデル、一連のエージェント、および同じ API の下でのいくつかの統合が提供されます。キーワード: ダイアログ、チャットボット、VQA、データセット、エージェント
文変換
このフレームワークは、シンプルな文、段落、画像の密なベクトル表現を計算する方法。これらのモデルは、BERT/RoBERTa/XLM-RoBERTa などの Transformer ベースのネットワークに基づいており、さまざまなタスクで SOTA を実現しています。テキストはベクトル空間に埋め込まれているため、類似したテキストが近くにあり、コサイン類似度によって効率的に見つけることができます。キーワード: 密ベクトル表現、テキスト埋め込み、文埋め込み
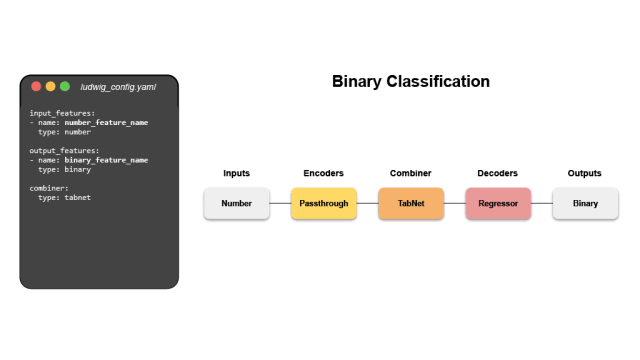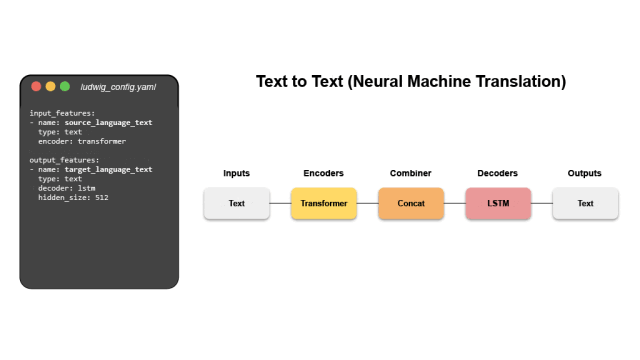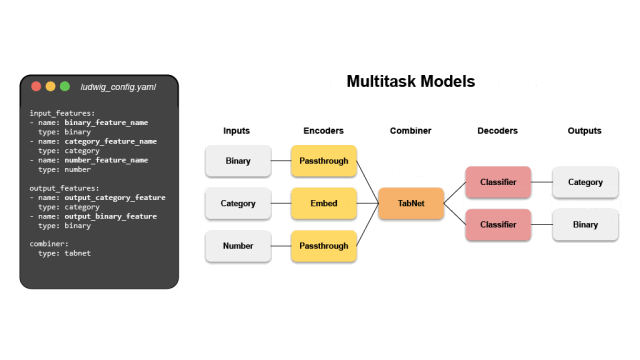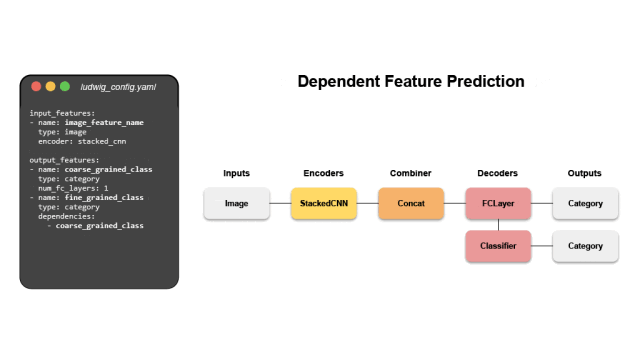
ludwig
Ludwig は宣言型機械学習フレームワークです。これにより、シンプルで柔軟なデータ駆動型構成システムを使用して、機械学習パイプラインを簡単に定義できます。 Ludwig はさまざまな AI タスクを対象とし、データ駆動型の構成システム、トレーニング、予測および評価スクリプト、プログラミング API を提供します。キーワード: 宣言型、データ駆動型、ML フレームワーク
InvokeAI
InvokeAI は、専門家、アーティスト、愛好家を対象とした安定拡散モデルのエンジンです。 CLI および WebUI を通じて最新の AI 駆動テクノロジーを活用します。
#キーワード: 安定拡散、WebUI、CLI
PaddleNLP は、特に中国語向けの使いやすく強力な NLP ライブラリです。複数の事前トレーニング済みモデル動物園をサポートし、研究から産業アプリケーションまで幅広い NLP タスクをサポートします。
キーワード: 自然言語処理、中国語、研究、産業
stanzaスタンフォード大学 NLP グループの公式 Python NLPライブラリ。 60 を超える言語での幅広い正確な自然言語処理ツールの実行をサポートし、Python から Java Stanford CoreNLP ソフトウェアへのアクセスをサポートします。
キーワード: NLP、多言語、CoreNLP
DeepPavlovDeepPavlov は、オープンソースの会話型人工知能ライブラリです。これは、本番環境に対応したチャットボットや複雑な対話システムの開発だけでなく、NLP 分野、特に対話システムの研究のために設計されています。
キーワード: ダイアログ、チャットボット
alpaca-loraAlpaca-lora には低ランク適応 ( LoRA) スタンフォード Alpaca の結果を再現するコード。このリポジトリは、トレーニング (微調整) および生成スクリプトを提供します。
キーワード: LoRA、パラメータの効率的な微調整
imagen-pytorchImagen のオープンソース実装。 Google のクローズド Source text-to-image ニューラル ネットワークは DALL-E2 を上回ります。 imagen-pytorch は、テキストから画像への合成のための新しい SOTA です。
#キーワード: Imagen、Wenshengtu
 ##アダプター変圧器
##アダプター変圧器
adapter-transformers は、事前トレーニングされたアダプター モジュールの中央リポジトリである AdaptorHub を組み込むことで、アダプターを最先端の言語モデルに統合する Transformers ライブラリの拡張機能です。これはトランスフォーマーのドロップイン代替品であり、トランスフォーマーの開発と歩調を合わせるために定期的に更新されます。
キーワード: アダプター、LoRA、パラメーターの効率的な微調整、ハブ
NeMo
NVIDIA NeMo は、自動化のために設計されています。 speech 認識 (ASR)、テキスト音声合成 (TTS)、大規模言語モデル、自然言語処理の研究者によって構築された会話型 AI ツールキット。 NeMo の主な目的は、産業界や学術界の研究者が以前の成果 (コードや事前トレーニングされたモデル) を再利用し、新しいプロジェクトの作成を容易にすることを支援することです。
キーワード: ダイアログ、ASR、TTS、LLM、NLP
Runhouse
Runhouse を使用すると、コードと Python を組み合わせることができます任意のコンピューターまたは基盤となるデータにデータを送信し、既存のコードや環境から通常どおりそれらとの対話を継続します。 Runhouse 開発者は次のように述べています:
#これは、リモート マシンをバイパスしたり、リモート データを操作したりできる Python インタープリターの拡張パッケージと考えることができます。
キーワード: MLOps、インフラストラクチャ、データ ストレージ、モデリング
MONAI
MONAI は PyTorch エコシステムの一部であり、医療画像分野における深層学習のための PyTorch に基づくオープンソース フレームワークです。その目的は次のとおりです:
- 学術、産業、臨床研究者の協力的なコミュニティを共通の基盤で発展させること;
- に貢献すること医用画像処理は、SOTA、エンドツーエンドのトレーニング ワークフローを作成します。
- 深層学習モデルの確立と評価のための最適化および標準化された方法を提供します。
キーワード: 医療画像、トレーニング、評価
simpletransformers
Simple Transformers を使用すると、Transformer モデルを迅速にトレーニングして評価できます。 。モデルの初期化、トレーニング、評価に必要なコードは 3 行だけです。さまざまな NLP タスクをサポートします。
キーワード: フレームワーク、シンプルさ、NLP
JARVIS
JARVIS は GPT-4 などです。LLM システムオープンソース機械学習コミュニティの他のモデルとマージし、最大 60 の下流モデルを活用して LLM によって特定されたタスクを実行します。
キーワード: LLM、エージェント、HF ハブ
transformers.js
transformers.js は、トランスフォーマーからのモデルをブラウザーで直接実行することを目的とした JavaScript ライブラリです。
キーワード: トランスフォーマー、JavaScript、ブラウザ
bumblebee
Bumblebee は、Axon ニューラル ネットワーク モデルに基づいて事前トレーニングされた機能を提供します, Axon は Elixir 言語のニューラル ネットワーク ライブラリです。これにはモデルとの統合が含まれており、誰でもわずか数行のコードで機械学習タスクをダウンロードして実行できます。
キーワード: Elixir、Axon
argilla
Argilla は、高度な NLP ラベル付け、モニタリング、ワークスペースを提供するツールです。ソースプラットフォーム。 Hugging Face、Stanza、FLAIR などの多くのオープンソース エコシステムと互換性があります。
キーワード: NLP、ラベリング、モニタリング、ワークスペース
干し草の山
Haystack は、Transformer モデルと LLM を使用してデータを操作できるオープンソースの NLP フレームワークです。複雑な意思決定、質問応答、セマンティック検索、テキスト生成アプリケーションなどを迅速に構築するための、本番環境に対応したツールを提供します。
#キーワード: NLP、フレームワーク、LLM

#SpaCy は、Python および Cython による高度な自然言語処理のためのライブラリです。最新の研究に基づいて構築されており、実際の製品で使用できるように一から設計されています。サードパーティ パッケージ spacy-transformers を通じて、Transformers モデルのサポートを提供します。
キーワード: NLP、アーキテクチャ
speechbrain
SpeechBrain は、PyTorch に基づくオープンソースの統合会話型 AI ツールキットです。私たちの目標は、音声認識、話者識別、音声強調、音声分離、音声認識、マルチマイクなどの最先端の音声テクノロジーを簡単に開発するために使用できる、柔軟でユーザーフレンドリーな単一のツールキットを作成することです。信号処理およびその他のシステム。
キーワード: ダイアログ、スピーチ
skorch
Skorch は、scikit-learn と互換性のある PyTorch のラッパーです。ニューラル ネットワーク ライブラリです。 。 Transformers のモデルとトークナイザーのトークナイザーをサポートします。
キーワード: Scikit-Learning、PyTorch
bertviz
BertViz は、「注意を視覚化」などのアプリケーションで使用される対話型ツールです。 BERT、GPT2、T5 などの Transformer 言語モデルで。ほとんどの Huggingface モデルをサポートするシンプルな Python API を介して、Jupiter または Colab ノートブックで実行できます。
#キーワード: ビジュアライゼーション、トランスフォーマー

このライブラリは、TPUv3 で約 40B のパラメータに拡張するように設計されています。 GPT-J モデルをトレーニングするために使用されるライブラリです。
キーワード: Haiku、モデル並列処理、LLM、TPUdeepchem
OpenNRE
ニューラル関係抽出の手法 オープンソース パッケージ(NRE)。初心者から開発者、研究者、学生まで幅広いユーザーを対象としています。#キーワード: 神経関係抽出、フレームワーク
pycorrector
中国語テキストのエラー修正ツール。この方法では、言語モデル検出エラー、ピンイン特徴、および形状特徴を利用して中国語テキストのエラーを修正します。中国語のピンインとストロークの入力方法に使用できます。
#キーワード: 中国語、エラー修正ツール、言語モデル、ピンイン
##nlpaug
キーワード: データ拡張、合成データ生成、オーディオ、自然言語処理
dream-texturesdream-texturesは、Blender に安定した拡散サポートを提供するために設計されたライブラリです。画像生成、テクスチャ投影、イン/アウト ペイント、ControlNet、アップグレードなどの複数のユースケースをサポートします。
#キーワード: 安定拡散、ブレンダー
#セルドンコア
 Seldon コアは、ML モデル (Tensorflow、Pytorch、H2o など) または言語ラッパー (Python、Java など) を本番環境の REST/GRPC マイクロサービスに変換します。 Seldon は、数千の実稼働機械学習モデルへのスケーリングを処理でき、高度なメトリクス、リクエスト ログ、インタープリター、外れ値検出器、A/B テスト、カナリアなどを含む高度な機械学習機能を提供します。
Seldon コアは、ML モデル (Tensorflow、Pytorch、H2o など) または言語ラッパー (Python、Java など) を本番環境の REST/GRPC マイクロサービスに変換します。 Seldon は、数千の実稼働機械学習モデルへのスケーリングを処理でき、高度なメトリクス、リクエスト ログ、インタープリター、外れ値検出器、A/B テスト、カナリアなどを含む高度な機械学習機能を提供します。
このライブラリには、高性能の深層学習推論アプリケーションの開発を加速する、最適化された深層学習モデルと一連のデモが含まれています。独自のトレーニングを行う代わりに、これらの無料の事前トレーニング済みモデルを使用して、開発および運用展開プロセスをスピードアップします。 キーワード: 最適化モデル、デモンストレーション ML-Stable-Diffusion は Apple の A リポジトリですこれにより、Apple シリコン デバイス上の Core ML に Stable Diffusion サポートがもたらされます。 Hugging Face Hub でホストされる安定した拡散チェックポイントをサポートします。 #キーワード: 安定拡散、Apple チップ、コア ML open_model_zoo
ml-stable-diffusion
#キーワード: テキストから 3D、安定した拡散
##txtai
##djl
Deep Java Library (DJL) は、開発者にとって使いやすい、オープンソースの高レベルでエンジンに依存しないディープ ラーニング用の Java フレームワークです。 DJL は、ネイティブ Java 開発エクスペリエンスと、他の通常の Java ライブラリと同様の機能を提供します。 DJL は、HuggingFace Tokenizer 用の Java バインディングと、Java で HuggingFace モデルを展開するための単純な変換ツールキットを提供します。 
lm-evaluation-harness
このプロジェクトは、多数の異なる評価タスクで生成言語モデルをテストするための統合フレームワークを提供します。 200 を超えるタスクをサポートし、HF Transformers、GPT-NeoX、DeepSpeed、OpenAI API などのさまざまなエコシステムをサポートします。

gpt-neox
このリソース ライブラリは、EleutherAI A の使用を記録します。 GPU 上で大規模な言語モデルをトレーニングするためのライブラリ。このフレームワークは、NVIDIA の Megatron 言語モデルに基づいており、DeepSpeed のテクノロジといくつかの新しい最適化によって強化されています。その焦点は、数十億のパラメーターを使用してモデルをトレーニングすることです。キーワード: トレーニング、LLM、メガトロン、DeepSpeed
muzic
Muzic は、人工知能に関する研究プロジェクトです。ディープラーニングと人工知能を通じて音楽を理解し、生成することができます。 Muzic は Microsoft Research Asia の研究者によって作成されました。#キーワード: 音楽理解、音楽生成
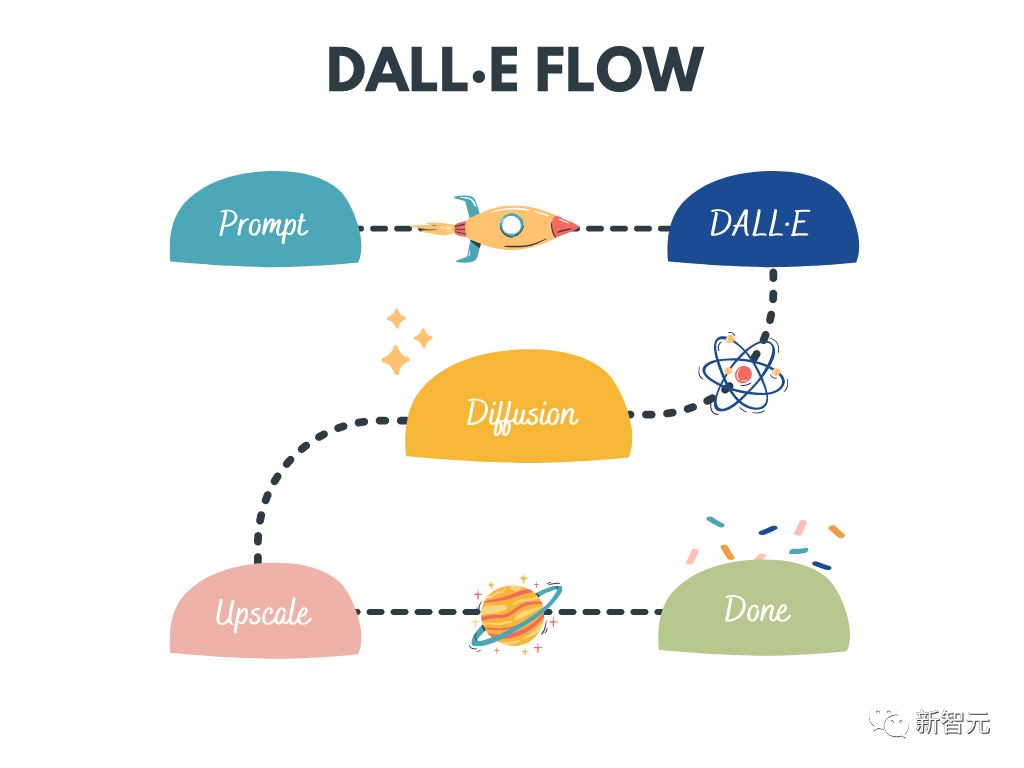
dalle-flow
DALL · E フローは、テキスト プロンプトから高解像度画像を生成するための対話型ワークフローです。 DALL・E-Mega、GLID-3 XL、Stable Diffusion を使用して候補画像を生成し、CLIP-as-service を呼び出して候補画像の並べ替えを促します。好ましい候補は拡散のために GLID-3 XL に供給され、多くの場合、テクスチャや背景が豊かになります。最後に、候補は SwinIR を介して 1024x1024 に拡張されます。
キーワード: 高精細画像生成、安定拡散、DALL-E Mega、GLID-3 XL、CLIP、SwinIR
#lightseq
LightSeq は、シーケンスの処理と生成のために CUDA に実装された高性能のトレーニングおよび推論ライブラリです。 BERT、GPT、Transformer などの最新の NLP および CV モデルを効率的に計算できます。したがって、機械翻訳、テキスト生成、画像分類、その他のシーケンス関連のタスクに役立ちます。
キーワード: トレーニング、推論、シーケンス処理、シーケンス生成

LaTeX- OCR
このプロジェクトの目標は、数式の画像を取得し、対応する LaTeX コードを返す学習ベースのシステムを作成することです。
キーワード: OCR、LaTeX、数式
open_clip
OpenCLIP は、OpenAI の CLIP のオープンソース実装です。
このリポジトリの目標は、対照的な画像とテキストの監視によるモデルのトレーニングを可能にし、分布の変化に対する堅牢性などのモデルの特性を研究することです。プロジェクトの開始点は、同じデータセットでトレーニングされた場合に元の CLIP モデルの精度と一致する CLIP の実装です。
具体的には、OpenAI の 1,500 万画像サブセット YFCC をコードベースとしてトレーニングされた ResNet-50 モデルは、ImageNet 上で 32.7% という最高精度を達成しました。
キーワード: CLIP、オープンソース、比較、画像テキスト

dale-playground
安定拡散と Dall-E mini を使用して、任意のテキスト プロンプトから画像を生成するプレイグラウンド。
#キーワード: WebUI、安定拡散、Dall-E mini
キーワード: フェデレーテッド ラーニング、分析、協調機械学習、分散型
以上がスターマークが10万個を突破しました! Auto-GPT の後、Transformer は新たなマイルストーンに到達の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1655
1655
 14
1414
52
1307
25
1254
29
1228
24
14
1414
52
1307
25
1254
29
1228
24

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 時系列予測 NLP 大規模モデルの新機能: 時系列予測の暗黙的なプロンプトを自動的に生成
Mar 18, 2024 am 09:20 AM
時系列予測 NLP 大規模モデルの新機能: 時系列予測の暗黙的なプロンプトを自動的に生成
Mar 18, 2024 am 09:20 AM
今日は、時系列予測のパフォーマンスを向上させるために、時系列データを潜在空間上の大規模な自然言語処理 (NLP) モデルと整合させる方法を提案するコネチカット大学の最近の研究成果を紹介したいと思います。この方法の鍵は、潜在的な空間ヒント (プロンプト) を使用して時系列予測の精度を高めることです。論文タイトル: S2IP-LLM: SemanticSpaceInformedPromptLearningwithLLMforTimeSeriesForecasting ダウンロードアドレス: https://arxiv.org/pdf/2403.05798v1.pdf 1. 大きな問題の背景モデル
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
この論文では、自動運転においてさまざまな視野角 (遠近法や鳥瞰図など) から物体を正確に検出するという問題、特に、特徴を遠近法 (PV) 空間から鳥瞰図 (BEV) 空間に効果的に変換する方法について検討します。 Visual Transformation (VT) モジュールを介して実装されます。既存の手法は、2D から 3D への変換と 3D から 2D への変換という 2 つの戦略に大別されます。 2D から 3D への手法は、深さの確率を予測することで高密度の 2D フィーチャを改善しますが、特に遠方の領域では、深さ予測に固有の不確実性により不正確さが生じる可能性があります。 3D から 2D への方法では通常、3D クエリを使用して 2D フィーチャをサンプリングし、Transformer を通じて 3D と 2D フィーチャ間の対応のアテンション ウェイトを学習します。これにより、計算時間と展開時間が増加します。
