

機械学習とは何かを 1 つの記事で理解する

世界はデータで満たされています。人々やコンピューターによって生成された画像、ビデオ、スプレッドシート、音声、テキストがインターネットに溢れ、私たちを情報の海に溺れさせます。
伝統的に、人間はより多くの情報に基づいた意思決定を行うためにデータを分析し、データ パターンの変化を制御するためにシステムを調整しようとしています。しかし、入ってくる情報の量が増えると、それを理解する能力が低下し、次のような課題が残ります:
このすべてのデータを使用して、手動ではなく自動化された方法で意味を導き出すにはどうすればよいでしょうか?
ここで機械学習が登場します。この記事では次の内容を紹介します:
- 機械学習とは
- 機械学習アルゴリズムの重要な要素
- 機械学習の仕組み
- 6 つの実際の事実 機械世界の学習アプリケーション
- 機械学習の課題と限界
これらの予測は、「トレーニング データ」と呼ばれる一連のデータからパターンを学習する機械によって行われ、人々の生活を改善するためのさらなる技術開発を推進することができます。
1 機械学習とは
機械学習とは、明示的にプログラムすることなく、コンピューターが例や経験から自動的に学習し、人間の意思決定を模倣できるようにする概念です。
機械学習は、アルゴリズムと統計手法を使用してデータから学習し、パターンや隠れた洞察を導き出す人工知能の分野です。
ここで、機械学習の詳細をさらに詳しく見てみましょう。
2 機械学習アルゴリズムの重要な要素
機械学習には何万ものアルゴリズムがあり、学習スタイルや解決する問題の性質に応じてグループ化できます。ただし、すべての機械学習アルゴリズムには、次の重要なコンポーネントが含まれています。
- トレーニング データ – 機械学習システムが学習する必要があるテキスト、画像、ビデオ、または時系列情報を指します。 。トレーニング データには、顔検出器の顔の周囲の境界ボックスや株価予測器の将来の株価パフォーマンスなど、ML システムに「正しい答え」が何であるかを示すためにラベルが付けられることがよくあります。
- は の略です。これは、「目」などの特徴によって表される顔など、トレーニング データ内のオブジェクトのエンコードされた表現を指します。一部のモデルは他のモデルよりもコーディングが簡単であり、これがモデルの選択の推進要因となります。たとえば、ニューラル ネットワークは 1 つの表現を形成し、別のベクトル マシンをサポートします。最新の手法のほとんどはニューラル ネットワークを使用します。
- 評価 - これは、あるモデルを別のモデルよりも判断または識別する方法についてです。通常、これを効用関数、損失関数、またはスコアリング関数と呼びます。平均二乗誤差 (モデルの出力対データ出力) または尤度 (観測データを考慮したモデルの推定確率) は、さまざまな評価関数の例です。
- 最適化 - これは、より良い評価を得るために、モデルを表す空間を検索したり、トレーニング データ内のラベルを改善したりする方法を指します。最適化とは、損失関数の値を最小化するためにモデル パラメーターを更新することを意味します。これにより、モデルの精度がより速く向上します。
上記は、機械学習アルゴリズムの 4 つのコンポーネントの詳細な分類です。
機械学習システムの機能
説明: このシステムは履歴データを収集し、整理して、わかりやすい方法で表示します。
主な焦点は、調査結果から推論や予測を引き出すのではなく、企業内ですでに何が起こっているかを把握することです。記述的分析では、予測分析や処方分析に必要な複雑な計算ではなく、算術、平均、パーセンテージなどの単純な数学的および統計的ツールを使用します。
記述分析は主に履歴データを分析して推測するのに対し、予測分析は起こり得る将来の状況を予測して理解することに重点を置きます。
過去のデータを見て過去のデータのパターンと傾向を分析すると、将来何が起こるかを予測できます。
処方的分析はどのように行動すべきかを教えてくれますが、記述的分析は過去に何が起こったのかを教えてくれます。予測分析は、過去から学ぶことで将来何が起こるかを教えてくれます。しかし、何が起こっているのかを理解したら、何をすべきでしょうか?
これは規範的な分析です。これは、システムが過去の知識を使用して、人が実行できる行動について複数の推奨事項を作成するのに役立ちます。規範的分析はシナリオをシミュレートし、望ましい結果を達成するための道筋を提供します。
3 機械学習の仕組み
ML アルゴリズムの学習は、3 つの主要な部分に分けることができます。
意思決定プロセス
機械学習モデルは、データからパターンを学習し、この知識を適用して予測を行うように設計されています。問題は、モデルがどのように予測を行うのかということです。
プロセスは非常に基本的なものです。入力データ (ラベル付きまたはラベルなし) からパターンを見つけ、それを適用して結果を導き出します。
誤差関数
機械学習モデルは、行った予測をグラウンド トゥルースと比較するように設計されています。目標は、学習が正しい方向に進んでいるかどうかを理解することです。これによりモデルの精度が決まり、モデルのトレーニングを改善する方法が示唆されます。
モデル最適化プロセス
モデルの最終的な目標は、予測を改善することです。これは、既知の結果と対応するモデル推定値との差を減らすことを意味します。
モデルは、重みを継続的に更新することでトレーニング データ サンプルにさらに適応する必要があります。このアルゴリズムはループ内で動作し、モデルの精度に関して最大値が得られるまで、結果を評価および最適化し、重みを更新します。
機械学習手法の種類
機械学習には主に4つの種類があります。
1. 教師あり機械学習
教師あり学習では、その名前が示すように、機械は指導の下で学習します。
これは、ラベル付きデータのセットをコンピューターに供給することで行われ、コンピューターが入力が何で、出力が何であるべきかを理解できるようになります。ここでは、人間がガイドとして機能し、機械がパターンを学習するラベル付きトレーニング データ (入出力ペア) をモデルに提供します。
入力と出力の関係を以前のデータセットから学習すると、マシンは新しいデータの出力値を簡単に予測できます。
教師あり学習はどこで使用できますか?
答えは、入力データで何を探すべきか、そして出力として何を求めるかがわかっているときです。
教師あり学習の問題の主なタイプには、回帰問題と分類問題が含まれます。
2. 教師なし機械学習
教師なし学習は、教師あり学習とは正反対の働きをします。
ラベルのないデータを使用します。マシンはデータを理解し、隠れたパターンを見つけて、それに応じて予測を行う必要があります。
ここでは、人間が何を探すべきかを指定することなく、機械がデータから隠されたパターンを独自に導き出した後、新しい発見を私たちに提供します。
教師なし学習の問題の主なタイプには、クラスタリングと相関ルール分析が含まれます。
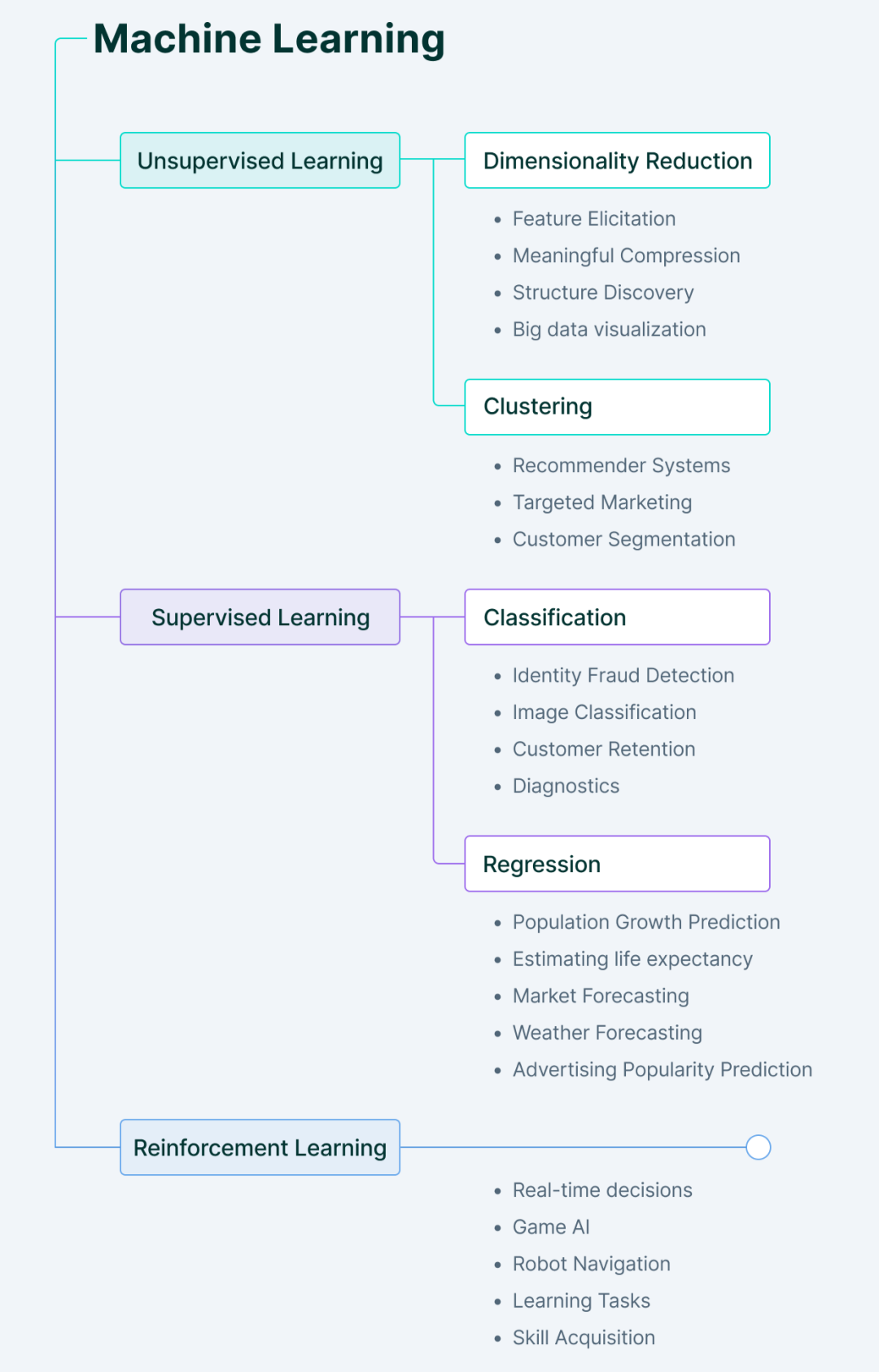
3. 強化学習
強化学習には、アクションを実行することによって環境内での動作を学習するエージェントが含まれます。
これらのアクションの結果に基づいて、エージェントはフィードバックを提供し、今後の方向性を調整します。すべての良いアクションに対して、エージェントは肯定的なフィードバックを受け取り、すべての悪いアクションに対して、エージェントは否定的なフィードバックまたは罰を受けます。
強化学習は、ラベル付きデータなしで学習します。ラベル付けされたデータがないため、エージェントは自身の経験に基づいてのみ学習できます。
4. 半教師あり学習
半教師あり学習とは、教師あり学習と教師なし学習の間の状態です。
これは、各学習からプラスの側面を取り入れています。つまり、分類をガイドするために小さなラベル付きデータセットを使用し、大きなラベルなしデータセットから教師なし特徴抽出を実行します。
半教師あり学習を使用する主な利点は、モデルをトレーニングするのに十分なラベル付きデータがない場合、または人間が何を調べればよいのかわからないために単にデータにラベルを付けることができない場合に、問題を解決できることです。その中で。
4 6 つの現実世界の機械学習アプリケーション
機械学習は、Google や Youtube 検索エンジンなどのビジネスを含む、最近のほぼすべてのテクノロジー企業の中核となっています。
以下に、あなたがよく知っているであろう機械学習の実際の応用例をいくつかまとめました。
自動運転車
車両は、地球上でさまざまな状況に遭遇します。道路、こんな状況。
自動運転車が人間よりも優れたパフォーマンスを発揮するには、変化する道路状況や他の車両の動作を学習して適応する必要があります。
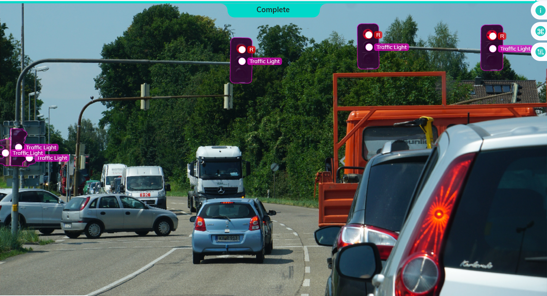
自動運転車は、センサーやカメラから周囲に関するデータを収集し、それを解釈して、それに応じて反応します。教師あり学習を使用して周囲の物体を識別し、教師なし学習を使用して他の車両のパターンを識別し、最終的に強化アルゴリズムの助けを借りてそれに応じたアクションを実行します。
画像分析と物体検出
画像分析は、画像からさまざまな情報を抽出するために使用されます。
製造上の欠陥のチェック、スマートシティの自動車交通の分析、Google レンズなどのビジュアル検索エンジンなどの分野に応用されています。
主なアイデアは、深層学習技術を使用して画像から特徴を抽出し、これらの特徴を物体検出に適用することです。
カスタマー サービス チャットボット
最近では、企業がカスタマー サポートや販売を提供するために AI チャットボットを使用することが非常に一般的になっています。 AI チャットボットは、24 時間年中無休のサポートを提供することで、企業が顧客からの大量の問い合わせを処理できるように支援します。これにより、サポート コストが削減され、追加の収益と顧客の満足が得られます。
AI ロボティクスは、自然言語処理 (NLP) を使用してテキストを処理し、クエリのキーワードを抽出し、それに応じて応答します。
医療画像処理と診断
事実は、医療画像データは最も豊富な情報源であると同時に、最も複雑な情報源の 1 つであるということです。
何千もの医療画像を手動で分析するのは面倒な作業であり、病理学者にとってもっと効率的に使用できるはずの貴重な時間を無駄にしています。
しかし、節約されたのは時間だけではありません。結節などのアーチファクトや小さな特徴は肉眼では見えない可能性があり、病気の診断の遅れや不正確な予測につながります。このため、画像から特徴を抽出するために使用できる、ニューラル ネットワークを含む深層学習技術を使用する可能性が非常に高いのです。
不正行為の特定
電子商取引分野の拡大に伴い、オンライン取引の数が増加し、利用可能な支払い方法が多様化していることがわかります。残念ながら、この状況を利用する人もいます。今日の世界の詐欺師は高度なスキルを持っており、新しいテクノロジーを非常に迅速に導入できます。
だからこそ、データ パターンを分析し、正確な予測を行い、偽のログイン試行やフィッシング攻撃などのオンライン サイバーセキュリティの脅威に対応できるシステムが必要なのです。
たとえば、詐欺防止システムは、過去に購入した場所やオンラインに滞在していた時間に基づいて、その購入が正当なものであるかどうかを検出できます。同様に、誰かがオンラインまたは電話であなたになりすまそうとしているかどうかを検出できます。
推奨アルゴリズム
推奨アルゴリズムのこの相関関係は、過去のデータの研究に基づいており、ユーザーの好みや興味などのいくつかの要因に依存します。
JD.com や Douyin などの企業は、レコメンデーション システムを使用して、関連するコンテンツや製品を厳選し、ユーザー/購入者に表示します。
機械学習の 5 つの課題と限界
過適合と過適合
ほとんどの場合、機械学習アルゴリズムのパフォーマンス低下の原因は過適合と過適合によるものです。
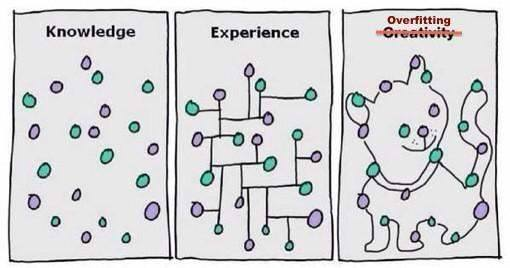
機械学習モデルのトレーニングという文脈でこれらの用語を詳しく見てみましょう。
- アンダーフィッティングとは、機械学習モデルがデータ内の変数間の関係を学習することも、新しいデータ ポイントを正しく予測することもできないシナリオです。言い換えれば、機械学習システムはデータ ポイント全体の傾向を検出しません。
- 過剰適合は、機械学習モデルがトレーニング データから多くのことを学習し、本質的にノイズが多い、またはデータ セットの範囲に無関係なデータ ポイントに注意を払うときに発生します。曲線上のすべての点を当てはめようとするため、データ パターンが記憶されます。
モデルには柔軟性がほとんどないため、新しいデータ ポイントを予測できません。言い換えれば、与えられた例に焦点を当てすぎて、全体像を見ることができていないのです。
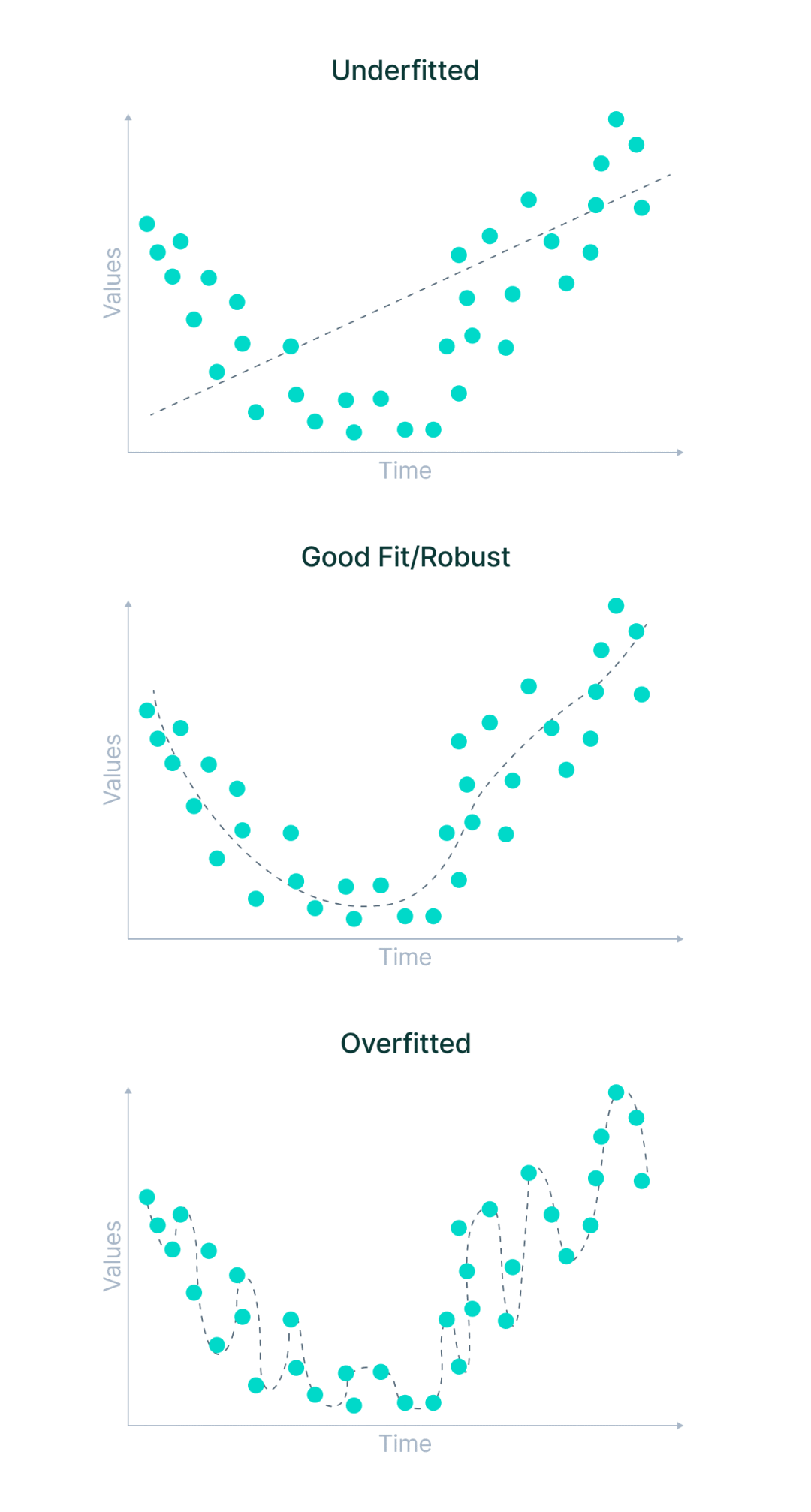
過適合と過適合の原因は何ですか?
より一般的な状況には、トレーニングに使用されるデータがクリーンではなく、多くのノイズやガベージ値が含まれている場合、またはデータのサイズが小さすぎる場合などがあります。ただし、より具体的な理由がいくつかあります。
これらを見てみましょう。
アンダーフィッティングは次の理由で発生する可能性があります:
- モデルは間違ったパラメーターでトレーニングされ、トレーニング データは完全には観察されませんでした
- モデルは単純すぎるため、十分な機能を記憶していません
- トレーニング データが多すぎます多様または複雑
過学習は次の場合に発生する可能性があります:
- モデルが間違ったパラメーターでトレーニングされ、トレーニング データが過剰に観察されます
- モデルは次のとおりです。複雑すぎて、より多様なデータで事前トレーニングされていません。
- トレーニング データのラベルが厳密すぎるか、元のデータが一様すぎて真の分布を表していません。

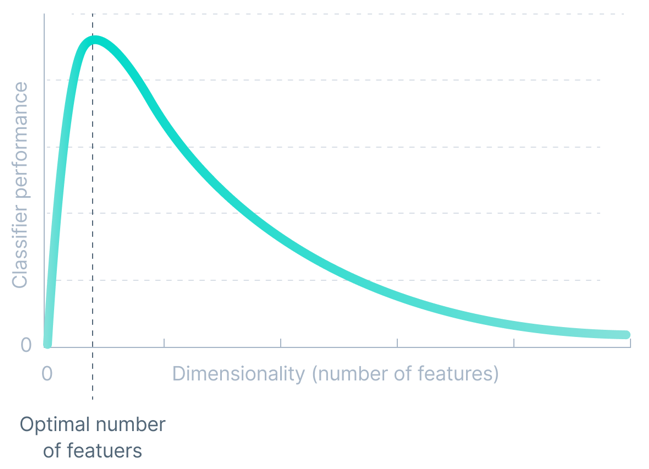
機械学習アルゴリズムは、低品質のトレーニング データに敏感です。
データの品質は、不正確なデータまたは欠損値によって引き起こされるデータ内のノイズにより影響を受ける可能性があります。トレーニング データ内の比較的小さなエラーであっても、システム出力に大規模なエラーが発生する可能性があります。
アルゴリズムのパフォーマンスが低い場合は、通常、データの量が不足している、データの歪みが多い、ノイズが多い、またはデータを説明するための特徴が不十分であるなどのデータ品質の問題が原因です。
したがって、機械学習モデルをトレーニングする前に、高品質のデータを取得するためにデータ クリーニングが必要になることがよくあります。
以上が機械学習とは何かを 1 つの記事で理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7484
7484
 15
1377
52
77
11
19
38
15
1377
52
77
11
19
38

 この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
機械学習とデータ サイエンスの分野では、モデルの解釈可能性が常に研究者や実務家に焦点を当ててきました。深層学習やアンサンブル手法などの複雑なモデルが広く適用されるようになったことで、モデルの意思決定プロセスを理解することが特に重要になってきました。 Explainable AI|XAI は、モデルの透明性を高めることで、機械学習モデルに対する信頼と自信を構築するのに役立ちます。モデルの透明性の向上は、複数の複雑なモデルの普及や、モデルを説明するための意思決定プロセスなどの方法によって実現できます。これらの方法には、特徴重要度分析、モデル予測間隔推定、ローカル解釈可能性アルゴリズムなどが含まれます。特徴重要度分析では、入力特徴に対するモデルの影響度を評価することで、モデルの意思決定プロセスを説明できます。モデルの予測間隔の推定
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
翻訳者 | Li Rui によるレビュー | 今日、人工知能 (AI) および機械学習 (ML) モデルはますます複雑になっており、これらのモデルによって生成される出力はブラックボックスになっており、関係者に説明することができません。 Explainable AI (XAI) は、利害関係者がこれらのモデルがどのように機能するかを理解できるようにし、これらのモデルが実際に意思決定を行う方法を確実に理解できるようにし、AI システムの透明性、信頼性、およびこの問題を解決するための説明責任を確保することで、この問題を解決することを目指しています。この記事では、さまざまな説明可能な人工知能 (XAI) 手法を検討して、その基礎となる原理を説明します。説明可能な AI が重要であるいくつかの理由 信頼と透明性: AI システムが広く受け入れられ、信頼されるためには、ユーザーは意思決定がどのように行われるかを理解する必要があります
 改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
01 今後の概要 現時点では、検出効率と検出結果の適切なバランスを実現することが困難です。我々は、光学リモートセンシング画像におけるターゲット検出ネットワークの効果を向上させるために、多層特徴ピラミッド、マルチ検出ヘッド戦略、およびハイブリッドアテンションモジュールを使用して、高解像度光学リモートセンシング画像におけるターゲット検出のための強化されたYOLOv5アルゴリズムを開発しました。 SIMD データセットによると、新しいアルゴリズムの mAP は YOLOv5 より 2.2%、YOLOX より 8.48% 優れており、検出結果と速度のバランスがより優れています。 02 背景と動機 リモート センシング技術の急速な発展に伴い、航空機、自動車、建物など、地表上の多くの物体を記述するために高解像度の光学式リモート センシング画像が使用されています。リモートセンシング画像の判読における物体検出
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
MetaFAIR はハーバード大学と協力して、大規模な機械学習の実行時に生成されるデータの偏りを最適化するための新しい研究フレームワークを提供しました。大規模な言語モデルのトレーニングには数か月かかることが多く、数百、さらには数千の GPU を使用することが知られています。 LLaMA270B モデルを例にとると、そのトレーニングには合計 1,720,320 GPU 時間が必要です。大規模なモデルのトレーニングには、これらのワークロードの規模と複雑さにより、特有のシステム上の課題が生じます。最近、多くの機関が、SOTA 生成 AI モデルをトレーニングする際のトレーニング プロセスの不安定性を報告しています。これらは通常、損失スパイクの形で現れます。たとえば、Google の PaLM モデルでは、トレーニング プロセス中に最大 20 回の損失スパイクが発生しました。数値的なバイアスがこのトレーニングの不正確さの根本原因です。
 C++ の機械学習: C++ で一般的な機械学習アルゴリズムを実装するためのガイド
Jun 03, 2024 pm 07:33 PM
C++ の機械学習: C++ で一般的な機械学習アルゴリズムを実装するためのガイド
Jun 03, 2024 pm 07:33 PM
C++ では、機械学習アルゴリズムの実装には以下が含まれます。 線形回帰: 連続変数を予測するために使用されるステップには、データの読み込み、重みとバイアスの計算、パラメーターと予測の更新が含まれます。ロジスティック回帰: 離散変数の予測に使用されます。このプロセスは線形回帰に似ていますが、予測にシグモイド関数を使用します。サポート ベクター マシン: サポート ベクターの計算とラベルの予測を含む強力な分類および回帰アルゴリズム。
 機械学習における Golang テクノロジーの今後の動向の展望
May 08, 2024 am 10:15 AM
機械学習における Golang テクノロジーの今後の動向の展望
May 08, 2024 am 10:15 AM
機械学習の分野における Go 言語の応用可能性は次のとおりです。 同時実行性: 並列プログラミングをサポートし、機械学習タスクにおける計算量の多い操作に適しています。効率: ガベージ コレクターと言語機能により、大規模なデータ セットを処理する場合でもコードの効率が保証されます。使いやすさ: 構文が簡潔なので、機械学習アプリケーションの学習と作成が簡単です。
