

単語の集合から視覚言語モデルを構築する可能性に関する研究

翻訳者 | Zhu Xianzhong
査読者| Chonglou
現在、マルチモーダル人工知能が巷で話題のホットな話題になっています。 GPT-4 の最近のリリースにより、わずか 6 か月前には想像できなかった無数の新しいアプリケーションや将来のテクノロジーの可能性が見えてきました。実際、視覚言語モデルは一般に、さまざまなタスクに役立ちます。たとえば、CLIP (対比言語イメージ事前トレーニング、、つまり「対比言語イメージ事前トレーニング」、リンク: # を使用できます。 ## https://www.php.cn/link/b02d46e8a3d8d9fd6028f3f2c2495864 目に見えないデータセットのゼロショット画像分類;通常この場合、トレーニングなしでも優れたパフォーマンスを得ることができます。
同時に、視覚言語モデルは完璧ではありません。この記事の内容では、これらのモデルの限界を調査し、モデルが失敗する可能性がある場所と理由を強調します。実際には、 この 記事 は、最近公開される 論文 についての短い/概要の説明です。 計画は、 ICLR 2023 口頭 の形式で提示されます。 公開済み。完全なソース コードに関する この記事を表示したい場合は、 リンク https://www.php.cn をクリックしてください。 /link/afb992000fcf79ef7a53fffde9c8e044.はじめに ビジュアル言語モデルとは何ですか?
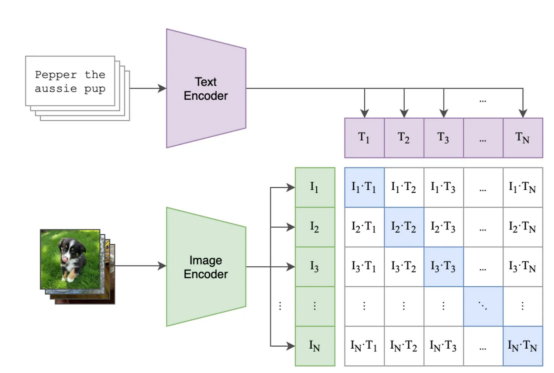
ビジュアル言語モデルは、視覚データと言語データの接続 さまざまなタスクを実行するための相乗効果がこの分野に革命をもたらしました。多くの視覚言語モデルが既存の文献で紹介されていますが、CLIP (言語と画像の事前トレーニングの比較) ) は、今でも最もよく知られ、最も広く使用されているモデルです。 画像とキャプションを埋め込むことで、同じベクトル空間で、CLIP モデルは クロスモーダル推論を可能にし、ユーザーがゼロショット画像などのタスクを高い精度で実行できるようにし、分類やテキストから画像への検索などのタスクを実行できます。モデルは、画像とタイトルの埋め込みを学習するために対照的な学習方法を使用します。
対照的な学習の概要 対照的な学習により、CLIP モデルは共有ベクトル空間内の画像間の距離を最小限に抑えることで、画像を対応する キャプションと関連付けます。 CLIP モデルとその他 コントラストベースのモデルによって達成された印象的な結果は、このアプローチが非常に優れていることを証明しています。効果的です。
画像と title ペアの比較バッチでコントラスト損失が使用され、モデルが最適化されます。一致する画像とテキストのペアの埋め込み間の類似性を最大化し、バッチ類似性内の他の画像とテキストのペア間の類似性を低減します。
下の図は、可能なバッチ処理とトレーニングのステップの例を示しています , ここ
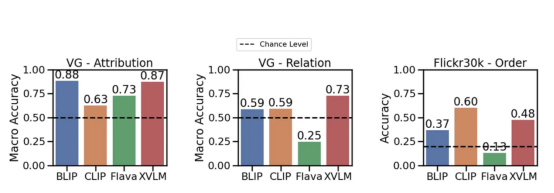
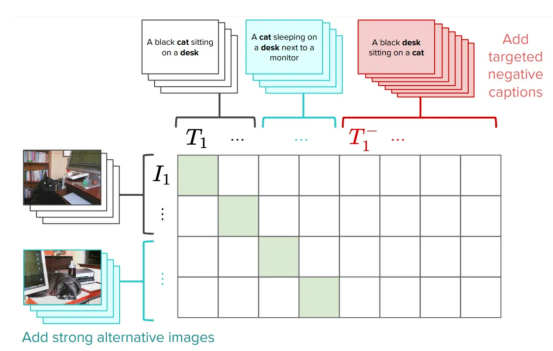
: ( 青い四角は画像テキストです類似性を最適化したいペア )トレーニング後は、画像と ## をエンコードする意味のあるベクトル空間を生成できるはずです。 #titles。各画像と各テキストのコンテンツを埋め込んだら、どの画像がタイトルとより一致するかを確認するなど、さまざまなタスクを実行できます (例: "dogs" を検索する)または、どのテキスト ラベルが特定の画像により近いかを見つけます (例: 犬と猫の画像が大量にあり、 CLIP などの視覚言語モデルは、視覚情報と言語情報を統合することで、複雑な人工知能タスクを解決するための強力なツールとなっています。両方のタイプのデータを共有ベクトル空間に埋め込むことにより、幅広いアプリケーションで前例のない成功が得られ、精度と優れたパフォーマンスが実現しました。 視覚言語モデルは言語を理解できますか? 私たち の仕事は、まさにこの質問に答えるために何らかの手段を講じようとしているのです。深層モデルが言語を理解できるかどうか、またはどの程度理解できるかという問題に関しては、 まだ重要な議論があります まず、成分の理解をテストするための新しいデータセットを提案します。この新しいベンチマークは ARO (属性,) と呼ばれます。 Relations,and Order: Attributes 、関係と順序) 次に、コントラスト損失が発生する理由を検討します。最後に、この問題に対するシンプルだが有望な解決策を提案します。 新しいベンチマーク: ARO (属性、関係、順序) CLIP (および Salesforce の最近の BLIP) のようなモデルは、言語理解においてどの程度の能力を発揮しますか。? 属性ベースの作品のセットを収集しました タイトル (例: 「赤いドアと立っている男」(赤いドアと立っている人)) および関係ベースの構成のセット title(たとえば、「馬が草を食べている」 (马在吃草)) と一致する画像です。次に、 「草が馬を食べている」 ( ## など) など、 の代わりに偽の タイトル # を生成します。 #草が馬を食べています)。モデルたちは正しいタイトルを見つけることができるでしょうか?また、単語をシャッフルする効果についても調査しました。モデルは、シャッフルされた Title よりもシャッフルされていない Title を好みますか? 属性、関係と順序 (ARO) #作成された 4 つのデータセットを以下に示します (シーケンス パート には 2 つのデータセットが含まれていることに注意してください): 私たちが作成したさまざまなデータセット 関係、属性、順序が含まれます。データセットごとに、画像の例と異なるタイトルを示します。 そのうち、 1 つのタイトルだけが正しいので、モデルは この 正しいタイトルを識別する必要があります。 属性 #BLIP モデルは、「草が草を食べている」と「馬が草を食べている」の違いを理解していません(どこで Visual Genome データセットの要素が含まれます、著者提供の画像) さあ、、実験結果を見てみましょう: 関係を理解する可能性を大幅に超えるモデルはほとんどありません (例: 食べる—— ###食事します)。 ただし、CLIPModel は Attributes および Relationships## にあります# エッジ アスペクトは この 可能性 よりわずかに高くなります。 これは実際、視覚言語モデルにまだ問題があることを示しています。 #、関係、およびベンチマークでの順序 (Flick30k ) のパフォーマンス。 使用した CLIP、BLIP および その他の SoTA モデル 検索と対比損失の評価この研究の主な結果の 1 つは、言語を学習するには標準的な対比損失以上のものが必要になる可能性があるということです。 最初から始めましょう。視覚言語モデルは検索タスクで評価されることがよくあります。タイトルを取得し、それがマッピングされている画像を見つけます。これらのモデルの評価に使用されるデータセット (MSCOCO、Flickr30K など) を見ると、titles、these で記述された画像が多く含まれていることがわかります。タイトル 構成を理解する必要があります (たとえば、「オレンジ色の猫は赤いテーブルの上にいます」: オレンジ色の猫は赤いテーブルの上にあります)。では、title が複雑な場合、なぜモデルは構成の理解を学習できないのでしょうか? [注]これらのデータセットの検索には、必ずしも構成を理解する必要はありません。 私たちは問題をよりよく理解するために、タイトル内の単語の順序をシャッフルしたときの検索におけるモデルのパフォーマンスをテストしました。タイトル 「注目している人々がいる本」 に対する正しい画像を見つけることができますか?答えが「はい」の場合、; つまり、,正しい画像を見つけるための指示情報は必要ありません。 私たちのテスト モデルのタスクは、スクランブルされたタイトルを使用して取得することです。キャプションをスクランブルした場合でも、モデルは対応する画像を正しく見つけることができます (逆も同様)。これは、検索タスクが単純すぎる可能性があることを示唆しています。,画像は作成者によって提供されています。 さまざまな shuffle プロセスをテストしたところ、結果は良好でした。異なる ## を使用した場合でも、結果は良好でした。 #Out-of-order テクノロジーを使用しても、検索パフォーマンスには基本的に影響はありません。 もう一度言います。視覚言語モデルは、命令情報にアクセスできない場合でも、これらのデータセットで高パフォーマンスの検索を実現します。これらのモデルは、aスタックの words のように動作する可能性があり、順序は重要ではありません。モデルが理解する必要がない場合は、では、実際に検索で何を測定するのでしょうか? 問題があることがわかったので、解決策を探したいと思うかもしれません。最も簡単な方法は、「猫がテーブルの上にある」と「テーブルが猫の上にある」は異なることを CLIPmodel に理解させることです。 実際、私たちが提案した 方法の 1 つは次のとおりです。この問題を解決するために特別に作成されたハード ネガを追加して、CLIPトレーニングを改善します。これは非常にシンプルで効率的な解決策です。全体的なパフォーマンスに影響を与えることなく、元の CLIP 損失をごくわずかに編集するだけで済みます (論文でいくつかの注意事項を読むことができます)。このバージョンの CLIP を NegCLIP と呼びます。 モデル (画像とテキストのハードネガを追加しました、写真は著者提供) model に黒猫の画像を 「座っている黒猫」に配置するように依頼します。机の上」 (黑猫が机の上に座っています)この文の近くですが、文からは遠く離れています」猫の上に座っている黒い机。 後者は POS タグを使用して自動的に生成されることに注意してください。 この修正の効果は、取得パフォーマンスや取得などの下流タスクのパフォーマンスを損なうことなく、実際に ARO ベンチマークのパフォーマンスを向上させることです。と分類。さまざまなベンチマークの結果については、以下の図を参照してください (詳細については、この文書#対応する文書#を参照してください)。 NegCLIPmodel と CLIPmodel を異なるベンチマークで実行します。 このうち、 青いベンチマークは私たちが導入したベンチマークで、緑のベンチマークは networkliterature## からのものです。 #( 作者提供の画像) 比較すると、大幅な改善があることがわかります。 ARO ベースラインに対して、edge の改善や他のダウンストリーム タスクの同様のパフォーマンスもあります。 Mert (論文の筆頭著者) は、視覚言語モデルをテストするための 小さなライブラリ を作成するという素晴らしい仕事をしました。彼のコードを使用して結果を再現したり、新しいモデルを実験したりできます。 データセットをダウンロードして実行を開始するのに必要なのは、数 数行Python 言語 : NegCLIP モデルも実装しました。 (実際には OpenCLIP の更新されたコピーです)、完全なコードのダウンロード アドレスは https://github.com/vinid/neg_clip です。 結論 視覚言語モデル現在 すでに多くのことができるようになっています。 次、GPT4 のような将来のモデルで何ができるようになるのか楽しみです。 翻訳者紹介 元のタイトル: あなたの視覚言語モデルは言葉の袋かもしれません 、著者: フェデリコ ビアンキ
。ここでの私たちの目標は、視覚言語モデルとその合成機能を研究することです。

属性の理解をテスト
そうですね、おそらくこれは BLIP モデルです。「馬が草を食べている」と「草が草を食べている」の違いが理解できないからです。 ”:
 属性
属性 ######これが理由です?
import clip
from dataset_zoo import VG_Relation, VG_Attribution
model, image_preprocess = clip.load("ViT-B/32", device="cuda")
root_dir="/path/to/aro/datasets"
#把 download设置为True将把数据集下载到路径`root_dir`——如果不存在的话
#对于VG-R和VG-A,这将是1GB大小的压缩zip文件——它是GQA的一个子集
vgr_dataset = VG_Relation(image_preprocess=preprocess,
download=True, root_dir=root_dir)
vga_dataset = VG_Attribution(image_preprocess=preprocess,
download=True, root_dir=root_dir)
#可以对数据集作任何处理。数据集中的每一项具有类似如下的形式:
# item = {"image_options": [image], "caption_options": [false_caption, true_caption]}つまり、
Zhu Xianzhong、51CTOコミュニティ編集者、51CTOエキスパートブロガー、講師、濰坊の大学のコンピューター教師、フリーランスプログラミングコミュニティ ベテラン。
以上が単語の集合から視覚言語モデルを構築する可能性に関する研究の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7554
7554
 15
1382
52
83
11
22
96
15
1382
52
83
11
22
96

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
検索強化生成およびセマンティック メモリを AI コーディング アシスタントに組み込むことで、開発者の生産性、効率、精度を向上させます。 JanakiramMSV 著者の EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG から翻訳。基本的な AI プログラミング アシスタントは当然役に立ちますが、ソフトウェア言語とソフトウェア作成の最も一般的なパターンに関する一般的な理解に依存しているため、最も適切で正しいコードの提案を提供できないことがよくあります。これらのコーディング アシスタントによって生成されたコードは、彼らが解決する責任を負っている問題の解決には適していますが、多くの場合、個々のチームのコーディング標準、規約、スタイルには準拠していません。これにより、コードがアプリケーションに受け入れられるように修正または調整する必要がある提案が得られることがよくあります。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
 SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
8月1日の本サイトのニュースによると、SKハイニックスは本日(8月1日)ブログ投稿を発表し、8月6日から8日まで米国カリフォルニア州サンタクララで開催されるグローバル半導体メモリサミットFMS2024に参加すると発表し、多くの新世代の製品。フューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) の紹介。以前は主に NAND サプライヤー向けのフラッシュ メモリ サミット (FlashMemorySummit) でしたが、人工知能技術への注目の高まりを背景に、今年はフューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) に名前が変更されました。 DRAM およびストレージ ベンダー、さらに多くのプレーヤーを招待します。昨年発売された新製品SKハイニックス
