

人工知能の進歩を妨げる8つの問題


今日の人工知能 (AI) には限界があります。まだまだ先は長いです。
一部の AI 研究者は、コンピューターが試行錯誤を通じて学習する機械学習アルゴリズムが「不思議な力」になっていることに気づきました。
さまざまな種類の人工知能
人工知能 (AI) の最近の進歩により、私たちの生活の多くの側面が改善されています。
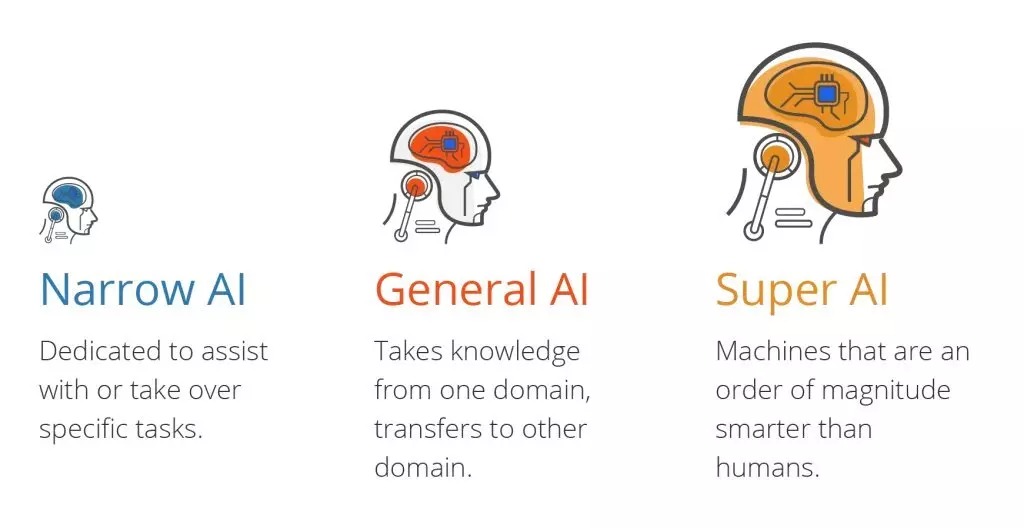
人工知能には 3 つのタイプがあります。
- 狭い範囲の機能を持つ狭い人工知能 (ANI)。
- 人間の能力と同等の汎用人工知能 (AGI)。
- 人間よりも賢い人工超知能 (ASI)。
今日の人工知能の何が問題になっているのでしょうか?
今日の人工知能は主に、データ分析、機械学習、人工ニューラル ネットワーク、または深層学習と呼ばれる統計学習モデルとアルゴリズムによって駆動されます。 IT インフラストラクチャ (ML プラットフォーム、アルゴリズム、データ、計算) と開発スタック (ライブラリから言語、IDE、ワークフロー、視覚化まで) の組み合わせとして実装されます。
つまり、これには以下が含まれます:
- 応用数学、確率論、統計
- いくつかの統計学習アルゴリズム、ロジスティック回帰、線形回帰、決定木、確率論Forest
- 一部の機械学習アルゴリズム (教師あり、教師なし、強化)
- 一部の人工ニューラル ネットワーク、深層学習アルゴリズム、および情報を予測および分類するために複数のレイヤーで入力データをフィルター処理するモデル
- いくつかの最適化 (圧縮と量子化) トレーニング済みニューラル ネットワーク モデル
- いくつかの統計モデルと推論 (Qualcomm Neural Processing SDK など)、
- いくつかのプログラミング言語 (Python や R など)
- PyTorch、ONNX、Apache MXNet、TensorFlow、Caffe2、CNTK、SciKit-Learn、Keras などの一部の ML プラットフォーム、フレームワーク、ランタイム、
- PyCharm などの一部の統合開発環境 (IDE)、 Microsoft VS Code、Jupyter、MATLAB など、
- 一部の物理サーバー、仮想マシン、コンテナ、特殊なハードウェア (GPU など)、クラウドベースのコンピューティング リソース (仮想マシン、コンテナ、サーバーレス コンピューティングを含む)。
現在使用されているほとんどの AI アプリケーションは、弱い AI として知られる狭い AI として分類できます。
それらはすべて、一般的な人工知能と機械学習を欠いており、これらは 3 つの主要なインタラクション エンジンによって定義されます:
- ワールド モデル [表現、学習、推論] マシン、または現実シミュレーション マシン (ワールド ハイパーグラフ ネットワーク)。
- World Knowledge Engine (グローバル ナレッジ グラフ)
- World Data Engine (グローバル データ グラフ ネットワーク)
一般的な AI および ML および DL アプリケーション/マシン/システム違いは、世界を、世界状態、そのリアリティマシン、グローバルナレッジエンジン、ワールドデータエンジンの複数のもっともらしい表現として理解することにあります。
これは、汎用/リアル AI スタックの最も重要なコンポーネントであり、実世界のデータ エンジンと対話し、インテリジェントな機能/機能を提供します:
- 世界に関する情報の処理
- 世界モデルの状態を推定/計算/学習します
- データ要素、点、セットを要約します
- データ構造と型を指定します
- そのデータを転送します学習
- その内容を文脈化する
- 因果パターン、ルール、パターンなどの因果データパターンを形成/発見する
- 考えられるすべての相互作用、原因、影響、サイクル、システム、および因果関係を推測するネットワークにおける関係
- さまざまな範囲と規模、さまざまなレベルの一般化と仕様で世界の状態を予測/レビューする
- 世界と対話し、それに適応し、効果的にナビゲートし、インテリジェントな予測と処方箋に基づいて環境を効率的に操作します。
実際、これは主にビッグ データ コンピューティング、アルゴリズムの革新、統計学習理論とコネクショニスト哲学に依存する統計的帰納的推論エンジンです。
ほとんどの人にとって、単純な機械学習 (ML) モデルを構築し、データ収集、管理、探索、特徴エンジニアリング、モデルのトレーニング、評価を経て、最後にデプロイするだけです。
EDA: 探索的データ分析
AI Ops — AI のエンドツーエンドのライフサイクルの管理
今日の人工知能の機能は「機械学習」に由来しており、現実世界のさまざまなシナリオごとにアルゴリズムを構成および調整する必要があります。そのため、非常に手作業が多くなり、開発の監督に多くの時間がかかります。この手動プロセスはエラーが発生しやすく、非効率的であり、管理が困難です。言うまでもなく、さまざまな種類のアルゴリズムを構成および調整できる専門知識が不足しています。
構成、チューニング、モデルの選択は自動化が進んでおり、Google、Microsoft、Amazon、IBM などの主要テクノロジー企業はすべて、機械学習モデルの構築プロセスを自動化するために同様の AutoML プラットフォームを立ち上げています。
AutoML には、機械学習アルゴリズムに基づいて予測モデルを構築するために必要なタスクの自動化が含まれます。これらのタスクには、データ クリーニングと前処理、特徴量エンジニアリング、特徴量の選択、モデルの選択、ハイパーパラメーターの調整が含まれますが、手動で実行するには面倒な場合があります。
SAS4485-2020.pdf
提示されたエンドツーエンドの ML パイプラインは 3 つの主要なステージで構成されていますが、すべてのデータのソースが欠落しています。世界そのもの:
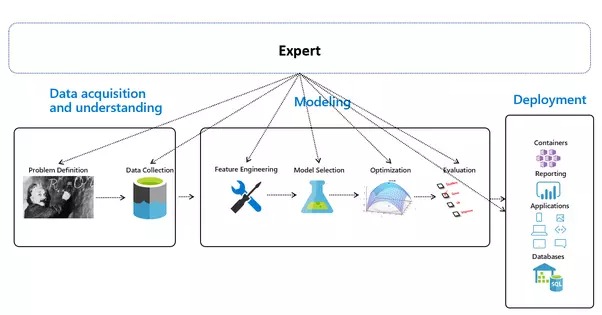
自動機械学習 - 概要
ビッグテック AI の重要な秘密は、ダークディープ ニューラル ネットワークとしてのスキンディープ機械学習ですモデルは、大量のラベル付きデータと、できるだけ多くの層を含むニューラル ネットワーク アーキテクチャを使用してトレーニングする必要があります。
各タスクには特別なネットワーク アーキテクチャが必要です。
- 回帰と分類用の人工ニューラル ネットワーク (ANN)
- コンピューター ビジョン用のボリューム畳み込みニューラル ネットワーク (CNN)
- 時系列分析のためのリカレント ニューラル ネットワーク (RNN)
- 特徴抽出のための自己組織化マップ
- 推奨システムの深度ボルツマン マシン
- 推奨システムのためのオートエンコーダー
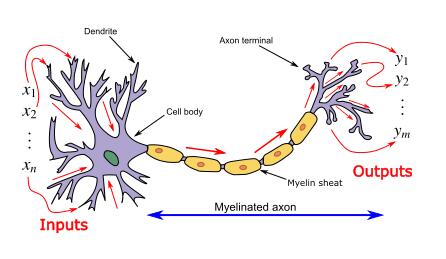
ANN は、生物学的な神経系/脳の情報処理方法に触発されたと思われる情報処理パラダイムとして導入されました。そして、そのような人工ニューラルネットワークは「汎用関数近似器」として表され、さまざまな活性化関数を学習/計算できます。
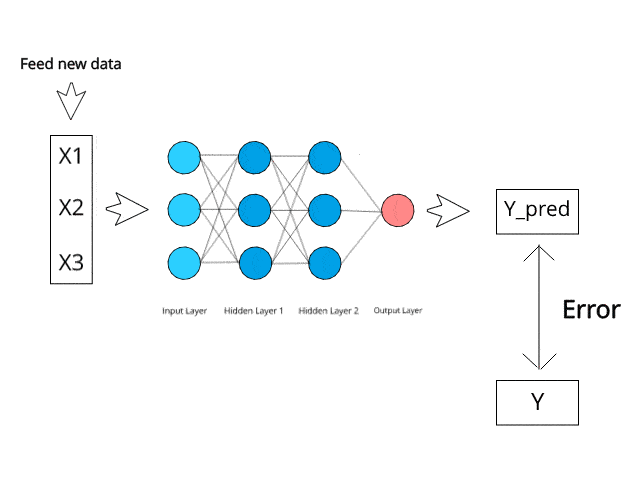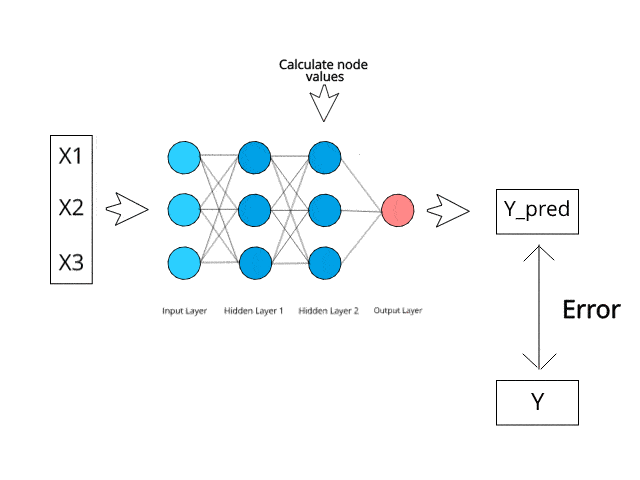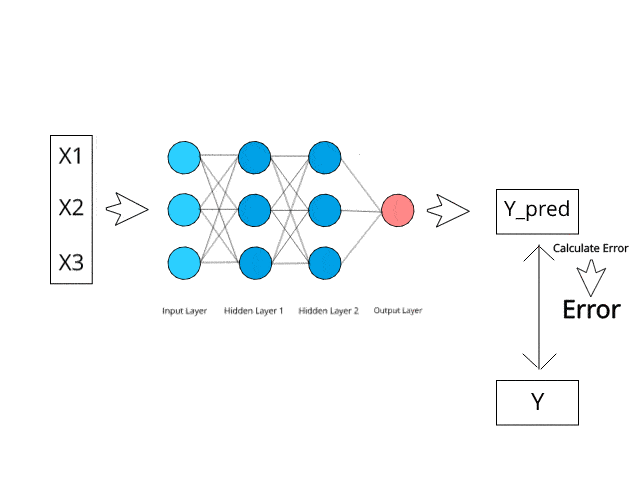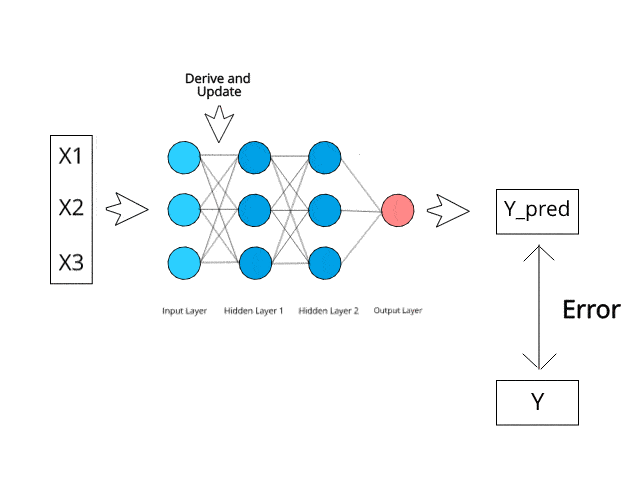
ニューラル ネットワークは、テスト段階で特定の逆伝播およびエラー修正メカニズムを通じて計算/学習します。
エラーを最小限に抑えることで、これらの多層システムがいつか独自にアイデアを学習し、概念化できるようになると想像してみてください。
人工ニューラル ネットワーク (ANN) の紹介
要約すると、マシン インテリジェンスを実装するには、数行の R または Python コードで十分であり、擬似的なトレーニングのためのオンライン リソースやチュートリアルが多数あります。さまざまな深さのニューラル ネットワーク ネットワークを構築し、画像、ビデオ、オーディオ、テキストを操作しますが、敵対的生成ネットワーク、BigGAN、CycleGAN、StyleGAN、GauGAN、Artbreeder、DeOldify などの世界をまったく理解していません。
彼らは、それが何であるかをまったく理解せずに、顔、風景、一般的な画像などを作成および変更します。
ペアになっていない画像間の変換にサイクル一貫性のある敵対的ネットワークを使用することで、2019 年はディープ ラーニングと機械学習の 14 の用途における新しい AI 時代となります。
独自の方法で機能するデジタル ツールやフレームワークは無数にあります。
- オープン言語 - Python が最も人気がありますが、R や Scala もその中にあります。
- オープン フレームワーク - Scikit-learn、XGBoost、TensorFlow など。
- メソッドとテクニック – 回帰から最先端の GAN および RL までの古典的な ML テクニック
- 生産性向上機能 – ビジュアル モデリング、機能エンジニアリング、アルゴリズムの選択、およびアルゴリズムの選択を支援する AutoAIハイパーパラメータの最適化
- 開発ツール - DataRobot、H2O、Watson Studio、Azure ML Studio、Sagemaker、Anaconda など。
悲しいことに、データ サイエンティストの作業環境: scikit-learn、R、SparkML、Jupyter、R、Python、XGboost、Hadoop、Spark、TensorFlow、Keras、PyTorch、Docker、Plumbr リストは続きますそしてさらに。
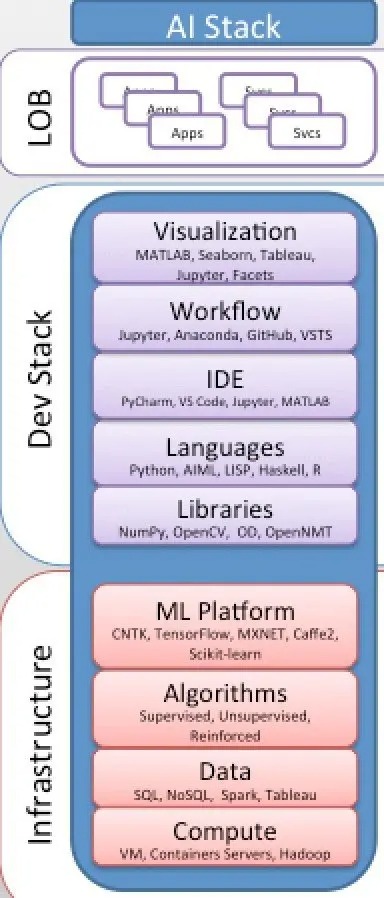
最新の AI スタックと AI-as-a-Service 消費モデル
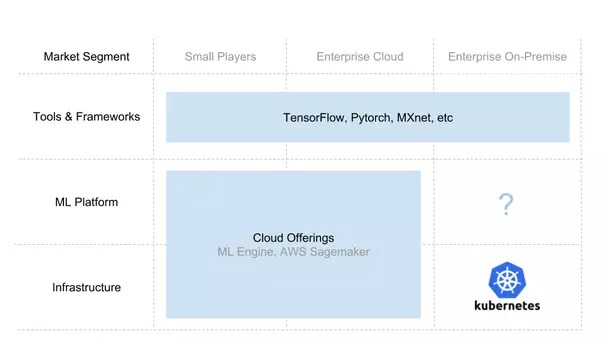
AI スタックの構築
人工知能のふりをして、実は偽の人工知能。最良の場合、これは自動学習技術、ML/DL/NN パターン認識装置であり、数学的かつ統計的な性質を持ち、直感的に行動したり環境をモデル化したりすることができず、知能、学習、理解がゼロです。
人工知能の進歩を妨げる問題
人工知能には多くの利点があるにもかかわらず、完璧ではありません。以下は、人工知能の進歩を妨げる 8 つの問題と根本的な間違いです:
1. データの欠如
人工知能にはトレーニング用に大規模なデータ セットが必要であり、これらのデータ セットは包括的である必要があります。公平で、品質は良好です。場合によっては、新しいデータが生成されるまで待たなければならないことがあります。
2. 時間がかかります
人工知能は、かなりの精度と関連性で目的を達成するためにアルゴリズムを学習し、開発するのに十分な時間を必要とします。また、機能するには大量のリソースも必要です。これは、コンピューターの能力に対する追加の要件を意味する場合があります。
3. 結果の解釈が不十分である
もう 1 つの大きな課題は、アルゴリズムによって生成された結果を正確に解釈する能力であり、アルゴリズムも目的に基づいて慎重に選択する必要があります。
4. 非常にエラーが発生しやすい
人工知能は自律的ですが、非常にエラーが発生しやすくなります。アルゴリズムが、包括的ではないほど十分に小さいデータセットでトレーニングされたとします。偏ったトレーニング セットから偏った予測が得られることになります。機械学習の場合、このようなミスが一連のエラーを引き起こし、長期間検出されない可能性があります。問題に気付いた場合、問題の原因を特定するのにかなりの時間がかかり、修正するにはさらに長い時間がかかることがあります。
5. 倫理的問題
私たち自身の判断よりもデータとアルゴリズムを信頼するという考えには、長所と短所があります。明らかに、私たちはこれらのアルゴリズムの恩恵を受けていますが、そうでなければ、そもそもそれらを使用していなかったでしょう。これらのアルゴリズムにより、利用可能なデータを使用して情報に基づいた判断を下すことでプロセスを自動化できます。ただし、場合によっては、これは誰かの仕事をアルゴリズムに置き換えることを意味し、これは倫理的な結果をもたらします。さらに、何か問題が起こった場合、誰を責めるべきでしょうか?
6. 技術リソースの不足
人工知能はまだ比較的新しいテクノロジーです。起動コードからプロセスのメンテナンスと監視に至るまで、プロセスを維持するには機械学習の専門家が必要です。人工知能と機械学習の業界はまだ比較的新しい市場です。人間の姿で適切なリソースを見つけることも困難です。したがって、機械学習の科学資料を開発および管理できる有能な代表者が不足しています。データ研究者は多くの場合、最初から最後まで数学的、技術的、科学的知識に加えて、空間的洞察を組み合わせて必要とします。
7. 不十分なインフラストラクチャ
人工知能には多くのデータ処理能力が必要です。継承フレームワークは、プレッシャーの下での責任と制約に対処できません。インフラストラクチャが AI の問題に対処できるかどうかをチェックする必要があります。そうでない場合は、優れたハードウェアと適応性のあるストレージで完全にアップグレードする必要があります。
8. 遅い結果と偏見
人工知能は非常に時間がかかります。データとリクエストの過負荷により、結果が配信されるまでに予想よりも時間がかかっています。結果を一般化するためにデータベース内の特定の特徴に焦点を当てることは機械学習モデルでは一般的ですが、これはバイアスにつながる可能性があります。
結論
人工知能は私たちの生活の多くの側面を引き継ぎました。完璧ではありませんが、人工知能は成長分野であり、高い需要があります。既存の処理済みデータを使用して、人間の介入なしでリアルタイムの結果が得られます。多くの場合、データ駆動型モデルを開発することにより、大量のデータの分析と評価に役立ちます。人工知能には多くの問題がありますが、進化している分野です。医療診断やワクチン開発から高度な取引アルゴリズムに至るまで、人工知能は科学の進歩の鍵となっています。
以上が人工知能の進歩を妨げる8つの問題の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 ブートストラップリストのサイズを変更する方法は?
Apr 07, 2025 am 10:45 AM
ブートストラップリストのサイズを変更する方法は?
Apr 07, 2025 am 10:45 AM
ブートストラップリストのサイズは、リスト自体ではなく、リストを含むコンテナのサイズに依存します。 BootstrapのグリッドシステムまたはFlexBoxを使用すると、コンテナのサイズを制御することで、リスト項目を間接的に変更します。
 ブートストラップリストのネストを実装する方法は?
Apr 07, 2025 am 10:27 AM
ブートストラップリストのネストを実装する方法は?
Apr 07, 2025 am 10:27 AM
ブートストラップのネストされたリストでは、スタイルを制御するためにブートストラップのグリッドシステムを使用する必要があります。まず、外層< ul>を使用します。および< li>リストを作成するには、内側のレイヤーリストを< div class =" row>に巻き付けます。 and< div class =" col-md-6">内側のレイヤーリストに、内側の層リストが行の幅の半分を占めることを指定します。このように、内側のリストは正しいものを持つことができます
 ブートストラップリストにアイコンを追加する方法は?
Apr 07, 2025 am 10:42 AM
ブートストラップリストにアイコンを追加する方法は?
Apr 07, 2025 am 10:42 AM
アイコンをブートストラップリストに追加する方法:アイコンライブラリ(Font Awesomeなど)が提供するクラス名を使用して、アイコンをリストアイテム< li>に直接詰めます。 Bootstrapクラスを使用して、アイコンとテキストを調整します(たとえば、d-flex、Justify-content-wether、align-Items-center)。ブートストラップタグコンポーネント(バッジ)を使用して、数字またはステータスを表示します。アイコンの位置(Flex-Direction:Row-Reverse;)を調整し、スタイル(CSSスタイル)を制御します。一般的なエラー:アイコンは表示されません(違います
 vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのオブジェクトに文字列を変換する場合、標準のjson文字列にはjson.parse()が推奨されます。非標準のJSON文字列の場合、文字列は正規表現を使用して処理し、フォーマットまたはデコードされたURLエンコードに従ってメソッドを削減できます。文字列形式に従って適切な方法を選択し、バグを避けるためにセキュリティとエンコードの問題に注意してください。
 VUEでエクスポートデフォルトによってエクスポートされたコンポーネントを登録する方法
Apr 07, 2025 pm 06:24 PM
VUEでエクスポートデフォルトによってエクスポートされたコンポーネントを登録する方法
Apr 07, 2025 pm 06:24 PM
質問:エクスポートデフォルトを通じてエクスポートされるVUEコンポーネントを登録する方法は?回答:3つの登録方法があります。グローバル登録:vue.component()メソッドを使用して、グローバルコンポーネントとして登録します。ローカル登録:現在のコンポーネントとそのサブコンポーネントでのみ利用可能なコンポーネントオプションに登録します。動的登録:vue.component()メソッドを使用して、コンポーネントが読み込まれた後に登録します。
 Bootstrapのグリッドシステムを表示する方法
Apr 07, 2025 am 09:48 AM
Bootstrapのグリッドシステムを表示する方法
Apr 07, 2025 am 09:48 AM
Bootstrapのメッシュシステムは、コンテナ(コンテナ)、行(行)、およびcol(列)の3つのメインクラスで構成されるレスポンシブレイアウトを迅速に構築するためのルールです。デフォルトでは、12列のグリッドが提供され、各列の幅はCol-MD-などの補助クラスを通じて調整でき、それにより、さまざまな画面サイズのレイアウト最適化を実現できます。オフセットクラスとネストされたメッシュを使用することにより、レイアウトの柔軟性を拡張できます。グリッドシステムを使用する場合は、各要素が正しいネスト構造を持っていることを確認し、パフォーマンスの最適化を検討してページの読み込み速度を改善します。詳細な理解と実践によってのみ、ブートストラップグリッドシステムを習熟させることができます。
 ブートストラップ5のリストスタイルでどのような変更が加えられましたか?
Apr 07, 2025 am 11:09 AM
ブートストラップ5のリストスタイルでどのような変更が加えられましたか?
Apr 07, 2025 am 11:09 AM
Bootstrap 5リストスタイルの変更は、主に詳細の最適化とセマンティック改善が原因です。これには、以下を含みます。リストスタイルはセマンティクスを強調し、アクセシビリティと保守性を向上させます。
 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
