
 テクノロジー周辺機器
AI
単一の GPU で LLM を微調整してコンピューティング能力の制限を回避するにはどうすればよいでしょうか?これは「勾配累積」アルゴリズムに関するチュートリアルです。
テクノロジー周辺機器
AI
単一の GPU で LLM を微調整してコンピューティング能力の制限を回避するにはどうすればよいでしょうか?これは「勾配累積」アルゴリズムに関するチュートリアルです。
単一の GPU で LLM を微調整してコンピューティング能力の制限を回避するにはどうすればよいでしょうか?これは「勾配累積」アルゴリズムに関するチュートリアルです。

大型モデルが人気のトレンドになって以来、GPU は希少品になりました。個人の開発者はもちろんのこと、多くの企業の準備金も十分ではない可能性があります。コンピューティング能力を使用してモデルをより効率的にトレーニングする方法はありますか?
最近のブログで、Sebastian Raschka は、GPU メモリが制限されている場合に、ハードウェアの制限を回避して、より大きなバッチ サイズを使用してモデルをトレーニングできる「勾配累積」手法を紹介しました。

これに先立ち、Sebastian Raschka もマルチ GPU トレーニング戦略を使用して微調整を加速する記事を共有しました。これには、GPU のメモリ制限に対処するためにモデルの重みと計算をさまざまなデバイス間で分散する、モデルまたはテンソル シャーディングなどのメカニズムが含まれます。
分類用の BLOOM モデルの微調整
テキスト分類などの下流タスクを処理するために、最近事前トレーニングされた大規模な言語モデルを採用することに興味があるとします。その場合、GPT-3 のオープンソースの代替 BLOOM モデル、特に 5 億 6,000 万個のパラメータ「のみ」を備えた BLOOM バージョンを使用することを選択するかもしれません。従来の GPU の RAM に問題なく収まるはずです (Google Colab の無料バージョンには、 15GB RAM)。
開始すると、問題が発生する可能性があります。トレーニングまたは微調整中にメモリが急速に増加します。このモデルをトレーニングする唯一の方法は、バッチ サイズ 1 を使用することです。

#バッチ サイズ 1 を使用してターゲット分類タスク用に BLOOM を微調整するコード (バッチ サイズ=1) ) 以下のとおりであります。 GitHub プロジェクト ページで完全なコードをダウンロードすることもできます:
https://github.com/rasbt/gradient-accumulation-blog/blob/main/src/1_batchsize-1 .py
このコードをコピーして Google Colab に直接貼り付けることもできますが、一部のデータセット ユーティリティがインポートされる付属の local_dataset_utilities.py ファイルをドラッグ アンド ドロップする必要もあります。同じフォルダーです。
<code># pip install torch lightning matplotlib pandas torchmetrics watermark transformers datasets -Uimport osimport os.path as opimport timefrom datasets import load_datasetfrom lightning import Fabricimport torchfrom torch.utils.data import DataLoaderimport torchmetricsfrom transformers import AutoTokenizerfrom transformers import AutoModelForSequenceClassificationfrom watermark import watermarkfrom local_dataset_utilities import download_dataset, load_dataset_into_to_dataframe, partition_datasetfrom local_dataset_utilities import IMDBDatasetdef tokenize_text (batch):return tokenizer (batch ["text"], truncatinotallow=True, padding=True, max_length=1024)def train (num_epochs, model, optimizer, train_loader, val_loader, fabric):for epoch in range (num_epochs):train_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch_idx, batch in enumerate (train_loader):model.train ()### FORWARD AND BACK PROPoutputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"]) fabric.backward (outputs ["loss"])### UPDATE MODEL PARAMETERSoptimizer.step ()optimizer.zero_grad ()### LOGGINGif not batch_idx % 300:print (f"Epoch: {epoch+1:04d}/{num_epochs:04d}"f"| Batch {batch_idx:04d}/{len (train_loader):04d}"f"| Loss: {outputs ['loss']:.4f}")model.eval ()with torch.no_grad ():predicted_labels = torch.argmax (outputs ["logits"], 1)train_acc.update (predicted_labels, batch ["label"])### MORE LOGGINGmodel.eval ()with torch.no_grad ():val_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch in val_loader:outputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"])predicted_labels = torch.argmax (outputs ["logits"], 1)val_acc.update (predicted_labels, batch ["label"])print (f"Epoch: {epoch+1:04d}/{num_epochs:04d}"f"| Train acc.: {train_acc.compute ()*100:.2f}%"f"| Val acc.: {val_acc.compute ()*100:.2f}%")train_acc.reset (), val_acc.reset ()if __name__ == "__main__":print (watermark (packages="torch,lightning,transformers", pythnotallow=True))print ("Torch CUDA available?", torch.cuda.is_available ())device = "cuda" if torch.cuda.is_available () else "cpu"torch.manual_seed (123)# torch.use_deterministic_algorithms (True)############################# 1 Loading the Dataset##########################download_dataset ()df = load_dataset_into_to_dataframe ()if not (op.exists ("train.csv") and op.exists ("val.csv") and op.exists ("test.csv")):partition_dataset (df)imdb_dataset = load_dataset ("csv",data_files={"train": "train.csv","validation": "val.csv","test": "test.csv",},)############################################ 2 Tokenization and Numericalization#########################################tokenizer = AutoTokenizer.from_pretrained ("bigscience/bloom-560m", max_length=1024)print ("Tokenizer input max length:", tokenizer.model_max_length, flush=True)print ("Tokenizer vocabulary size:", tokenizer.vocab_size, flush=True)print ("Tokenizing ...", flush=True)imdb_tokenized = imdb_dataset.map (tokenize_text, batched=True, batch_size=None)del imdb_datasetimdb_tokenized.set_format ("torch", columns=["input_ids", "attention_mask", "label"])os.environ ["TOKENIZERS_PARALLELISM"] = "false"############################################ 3 Set Up DataLoaders#########################################train_dataset = IMDBDataset (imdb_tokenized, partition_key="train")val_dataset = IMDBDataset (imdb_tokenized, partition_key="validation")test_dataset = IMDBDataset (imdb_tokenized, partition_key="test")train_loader = DataLoader (dataset=train_dataset,batch_size=1,shuffle=True,num_workers=4,drop_last=True,)val_loader = DataLoader (dataset=val_dataset,batch_size=1,num_workers=4,drop_last=True,)test_loader = DataLoader (dataset=test_dataset,batch_size=1,num_workers=2,drop_last=True,)############################################ 4 Initializing the Model#########################################fabric = Fabric (accelerator="cuda", devices=1, precisinotallow="16-mixed")fabric.launch ()model = AutoModelForSequenceClassification.from_pretrained ("bigscience/bloom-560m", num_labels=2)optimizer = torch.optim.Adam (model.parameters (), lr=5e-5)model, optimizer = fabric.setup (model, optimizer)train_loader, val_loader, test_loader = fabric.setup_dataloaders (train_loader, val_loader, test_loader)############################################ 5 Finetuning#########################################start = time.time ()train (num_epochs=1,model=model,optimizer=optimizer,train_loader=train_loader,val_loader=val_loader,fabric=fabric,)end = time.time ()elapsed = end-startprint (f"Time elapsed {elapsed/60:.2f} min")with torch.no_grad ():model.eval ()test_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch in test_loader:outputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"])predicted_labels = torch.argmax (outputs ["logits"], 1)test_acc.update (predicted_labels, batch ["label"])print (f"Test accuracy {test_acc.compute ()*100:.2f}%")</code>著者は、このコードを別のハードウェアで実行するときに、開発者が GPU の数とマルチ GPU トレーニング戦略を変更できる柔軟性を提供するため、Lightning Fabric を使用しました。また、精度フラグを調整するだけで混合精度トレーニングを有効にすることもできます。この場合、混合精度トレーニングによりトレーニング速度が 3 倍向上し、メモリ要件が約 25% 削減されます。
上記のメイン コードは main 関数で実行されます (__name__ == "__main__" コンテキストの場合)。単一の GPU のみが使用されている場合でも、PyTorch を使用することをお勧めします。実行用の実行環境、マルチ GPU トレーニング。次に、if __name__ == "__main__" に含まれる次の 3 つのコード セクションがデータの読み込みを担当します。
# 1 データ セットを読み込みます
# 2 トークン化と数値化
# 3 データローダーの設定
#セクション 4 は「モデルの初期化」にあり、その後のセクションにあります。 5 微調整では、train 関数が呼び出されます。ここから興味深いことが始まります。 train (...) 関数では、標準の PyTorch ループが実装されています。コア トレーニング ループの注釈付きバージョンは次のようになります。
バッチ サイズ 1 (Batch size=1) の問題は、勾配更新が非常に混乱し、困難になることです。次のトレーニングに示されています。このモデルは、次のとおり、変動するトレーニング損失とテスト セットのパフォーマンスの低下に基づいています。 ? より大きなバッチ サイズでモデルをトレーニングするにはどうすればよいですか?
解決策の 1 つは勾配累積であり、これを使用して前述のトレーニング ループを変更できます。
什么是梯度积累?
梯度累积是一种在训练期间虚拟增加批大小(batch size)的方法,当可用的 GPU 内存不足以容纳所需的批大小时,这非常有用。在梯度累积中,梯度是针对较小的批次计算的,并在多次迭代中累积(通常是求和或平均),而不是在每一批次之后更新模型权重。一旦累积梯度达到目标「虚拟」批大小,模型权重就会使用累积梯度进行更新。
参考下面更新的 PyTorch 训练循环:
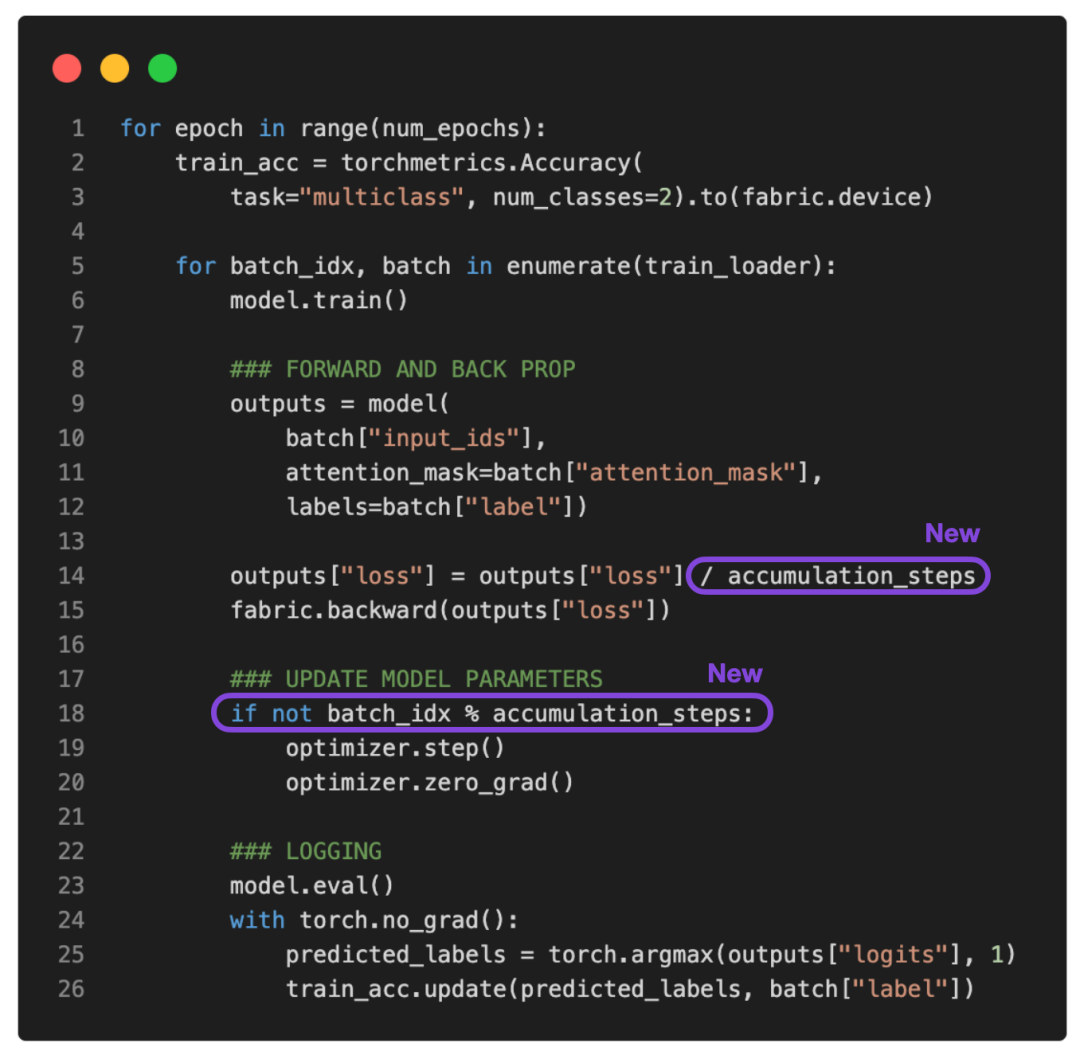
如果将 accumulation_steps 设置为 2,那么 zero_grad () 和 optimizer.step () 将只会每隔一秒调用一次。因此,使用 accumulation_steps=2 运行修改后的训练循环与将批大小(batch size)加倍具有相同的效果。
例如,如果想使用 256 的批大小,但只能将 64 的批大小放入 GPU 内存中,就可以对大小为 64 的四个批执行梯度累积。(处理完所有四个批次后,将获得相当于单个批大小为 256 的累积梯度。)这样能够有效地模拟更大的批大小,而无需更大的 GPU 内存或跨不同设备的张量分片。
虽然梯度累积可以帮助我们训练具有更大批量大小的模型,但它不会减少所需的总计算量。实际上,它有时会导致训练过程略慢一些,因为权重更新的执行频率较低。尽管如此,它却能帮我们解决限制问题,即批大小非常小时导致的更新频繁且混乱。
例如,现在让我们运行上面的代码,批大小为 1,需要 16 个累积步骤(accumulation steps)来模拟批大小等于 16。
输出如下:
<code>...torch : 2.0.0lightning : 2.0.0transformers: 4.27.2Torch CUDA available? True...Epoch: 0001/0001 | Batch 23700/35000 | Loss: 0.0168Epoch: 0001/0001 | Batch 24000/35000 | Loss: 0.0006Epoch: 0001/0001 | Batch 24300/35000 | Loss: 0.0152Epoch: 0001/0001 | Batch 24600/35000 | Loss: 0.0003Epoch: 0001/0001 | Batch 24900/35000 | Loss: 0.0623Epoch: 0001/0001 | Batch 25200/35000 | Loss: 0.0010Epoch: 0001/0001 | Batch 25500/35000 | Loss: 0.0001Epoch: 0001/0001 | Batch 25800/35000 | Loss: 0.0047Epoch: 0001/0001 | Batch 26100/35000 | Loss: 0.0004Epoch: 0001/0001 | Batch 26400/35000 | Loss: 0.1016Epoch: 0001/0001 | Batch 26700/35000 | Loss: 0.0021Epoch: 0001/0001 | Batch 27000/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 27300/35000 | Loss: 0.0008Epoch: 0001/0001 | Batch 27600/35000 | Loss: 0.0060Epoch: 0001/0001 | Batch 27900/35000 | Loss: 0.0001Epoch: 0001/0001 | Batch 28200/35000 | Loss: 0.0426Epoch: 0001/0001 | Batch 28500/35000 | Loss: 0.0012Epoch: 0001/0001 | Batch 28800/35000 | Loss: 0.0025Epoch: 0001/0001 | Batch 29100/35000 | Loss: 0.0025Epoch: 0001/0001 | Batch 29400/35000 | Loss: 0.0000Epoch: 0001/0001 | Batch 29700/35000 | Loss: 0.0495Epoch: 0001/0001 | Batch 30000/35000 | Loss: 0.0164Epoch: 0001/0001 | Batch 30300/35000 | Loss: 0.0067Epoch: 0001/0001 | Batch 30600/35000 | Loss: 0.0037Epoch: 0001/0001 | Batch 30900/35000 | Loss: 0.0005Epoch: 0001/0001 | Batch 31200/35000 | Loss: 0.0013Epoch: 0001/0001 | Batch 31500/35000 | Loss: 0.0112Epoch: 0001/0001 | Batch 31800/35000 | Loss: 0.0053Epoch: 0001/0001 | Batch 32100/35000 | Loss: 0.0012Epoch: 0001/0001 | Batch 32400/35000 | Loss: 0.1365Epoch: 0001/0001 | Batch 32700/35000 | Loss: 0.0210Epoch: 0001/0001 | Batch 33000/35000 | Loss: 0.0374Epoch: 0001/0001 | Batch 33300/35000 | Loss: 0.0007Epoch: 0001/0001 | Batch 33600/35000 | Loss: 0.0341Epoch: 0001/0001 | Batch 33900/35000 | Loss: 0.0259Epoch: 0001/0001 | Batch 34200/35000 | Loss: 0.0005Epoch: 0001/0001 | Batch 34500/35000 | Loss: 0.4792Epoch: 0001/0001 | Batch 34800/35000 | Loss: 0.0003Epoch: 0001/0001 | Train acc.: 78.67% | Val acc.: 87.28%Time elapsed 51.37 minTest accuracy 87.37%</code>
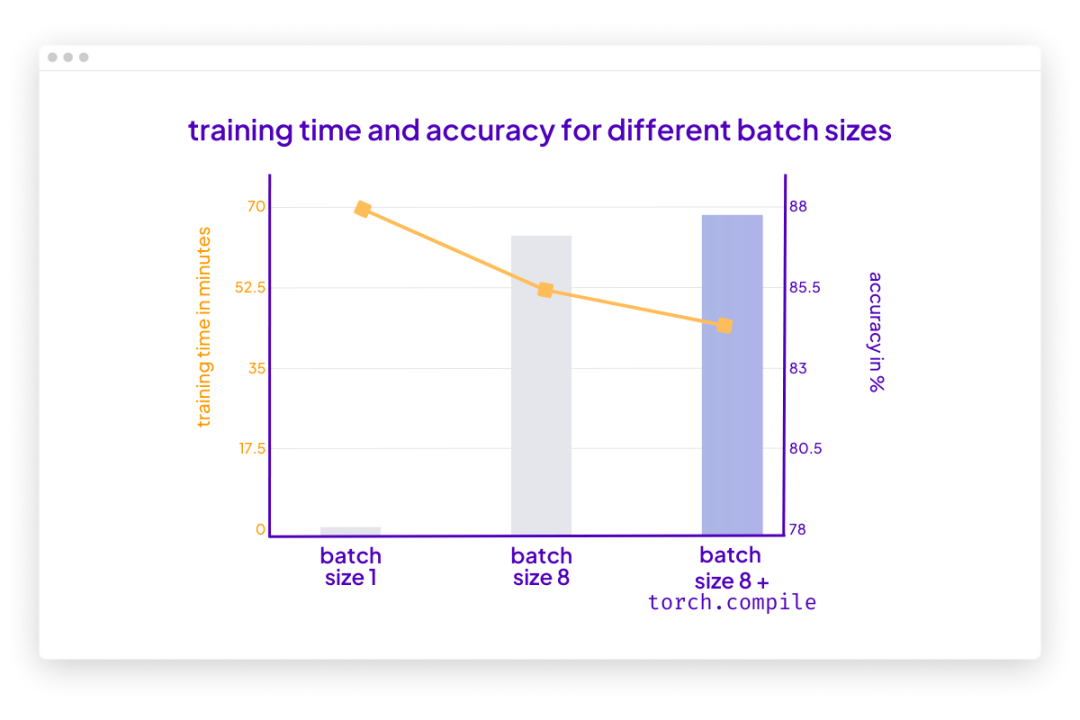
根据上面的结果,损失的波动比以前小了。此外,测试集性能提升了 10%。由于只迭代了训练集一次,因此每个训练样本只会遇到一次。训练用于 multiple epochs 的模型可以进一步提高预测性能。
你可能还会注意到,这段代码的执行速度也比之前使用的批大小为 1 的代码快。如果使用梯度累积将虚拟批大小增加到 8,仍然会有相同数量的前向传播(forward passes)。然而,由于每八个 epoch 只更新一次模型,因此反向传播(backward passes)会很少,这样可更快地在一个 epoch(训练轮数)内迭代样本。
结论
梯度累积是一种在执行权重更新之前通过累积多个小的批梯度来模拟更大的批大小的技术。该技术在可用内存有限且内存中可容纳批大小较小的情况下提供帮助。
但是,首先请思考一种你可以运行批大小的场景,这意味着可用内存大到足以容纳所需的批大小。在那种情况下,梯度累积可能不是必需的。事实上,运行更大的批大小可能更有效,因为它允许更多的并行性且能减少训练模型所需的权重更新次数。
总之,梯度累积是一种实用的技术,可以用于降低小批大小干扰信息对梯度更新准确性的影响。这是迄今一种简单而有效的技术,可以让我们绕过硬件的限制。
PS:可以让这个运行得更快吗?
没问题。可以使用 PyTorch 2.0 中引入的 torch.compile 使其运行得更快。只需要添加一些 model = torch.compile,如下图所示:
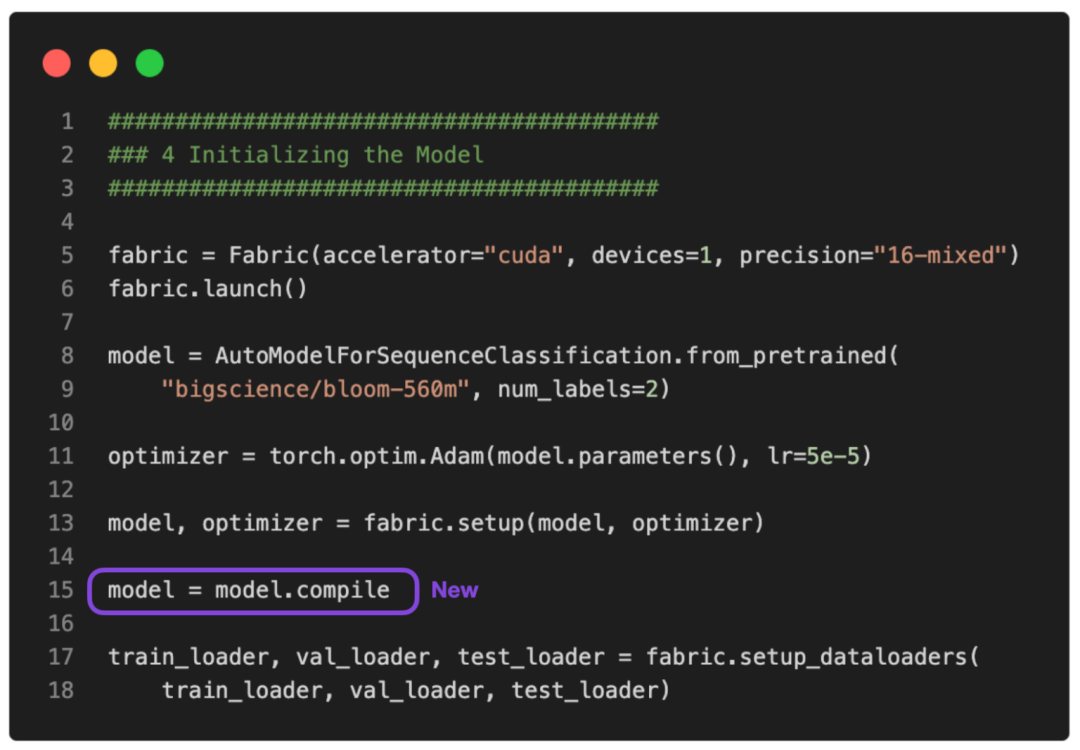
GitHub 上提供了完整的脚本。
在这种情况下,torch.compile 在不影响建模性能的情况下又减少了十分钟的训练时间:
<code>poch: 0001/0001 | Batch 26400/35000 | Loss: 0.0320Epoch: 0001/0001 | Batch 26700/35000 | Loss: 0.0010Epoch: 0001/0001 | Batch 27000/35000 | Loss: 0.0006Epoch: 0001/0001 | Batch 27300/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 27600/35000 | Loss: 0.0157Epoch: 0001/0001 | Batch 27900/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 28200/35000 | Loss: 0.0540Epoch: 0001/0001 | Batch 28500/35000 | Loss: 0.0035Epoch: 0001/0001 | Batch 28800/35000 | Loss: 0.0016Epoch: 0001/0001 | Batch 29100/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 29400/35000 | Loss: 0.0008Epoch: 0001/0001 | Batch 29700/35000 | Loss: 0.0877Epoch: 0001/0001 | Batch 30000/35000 | Loss: 0.0232Epoch: 0001/0001 | Batch 30300/35000 | Loss: 0.0014Epoch: 0001/0001 | Batch 30600/35000 | Loss: 0.0032Epoch: 0001/0001 | Batch 30900/35000 | Loss: 0.0004Epoch: 0001/0001 | Batch 31200/35000 | Loss: 0.0062Epoch: 0001/0001 | Batch 31500/35000 | Loss: 0.0032Epoch: 0001/0001 | Batch 31800/35000 | Loss: 0.0066Epoch: 0001/0001 | Batch 32100/35000 | Loss: 0.0017Epoch: 0001/0001 | Batch 32400/35000 | Loss: 0.1485Epoch: 0001/0001 | Batch 32700/35000 | Loss: 0.0324Epoch: 0001/0001 | Batch 33000/35000 | Loss: 0.0155Epoch: 0001/0001 | Batch 33300/35000 | Loss: 0.0007Epoch: 0001/0001 | Batch 33600/35000 | Loss: 0.0049Epoch: 0001/0001 | Batch 33900/35000 | Loss: 0.1170Epoch: 0001/0001 | Batch 34200/35000 | Loss: 0.0002Epoch: 0001/0001 | Batch 34500/35000 | Loss: 0.4201Epoch: 0001/0001 | Batch 34800/35000 | Loss: 0.0018Epoch: 0001/0001 | Train acc.: 78.39% | Val acc.: 86.84%Time elapsed 43.33 minTest accuracy 87.91%</code>
请注意,与之前相比准确率略有提高很可能是由于随机性。
以上が単一の GPU で LLM を微調整してコンピューティング能力の制限を回避するにはどうすればよいでしょうか?これは「勾配累積」アルゴリズムに関するチュートリアルです。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7715
7715
 15
1641
14
1395
52
1289
25
1232
29
15
1641
14
1395
52
1289
25
1232
29

 おすすめのAI支援プログラミングツール4選
Apr 22, 2024 pm 05:34 PM
おすすめのAI支援プログラミングツール4選
Apr 22, 2024 pm 05:34 PM
この AI 支援プログラミング ツールは、急速な AI 開発のこの段階において、多数の有用な AI 支援プログラミング ツールを発掘しました。 AI 支援プログラミング ツールは、開発効率を向上させ、コードの品質を向上させ、バグ率を減らすことができます。これらは、現代のソフトウェア開発プロセスにおける重要なアシスタントです。今日は Dayao が 4 つの AI 支援プログラミング ツールを紹介します (すべて C# 言語をサポートしています)。皆さんのお役に立てれば幸いです。 https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot は、より少ない労力でより迅速にコードを作成できるようにする AI コーディング アシスタントであり、問題解決とコラボレーションにより集中できるようになります。ギット
 どのAIプログラマーが一番優れているでしょうか? Devin、Tongyi Lingma、SWE エージェントの可能性を探る
Apr 07, 2024 am 09:10 AM
どのAIプログラマーが一番優れているでしょうか? Devin、Tongyi Lingma、SWE エージェントの可能性を探る
Apr 07, 2024 am 09:10 AM
世界初の AI プログラマー Devin の誕生から 1 か月も経たない 2022 年 3 月 3 日、プリンストン大学の NLP チームはオープンソース AI プログラマー SWE-agent を開発しました。 GPT-4 モデルを利用して、GitHub リポジトリの問題を自動的に解決します。 SWE ベンチ テスト セットにおける SWE エージェントのパフォーマンスは Devin と同様で、平均 93 秒かかり、問題の 12.29% を解決しました。専用端末と対話することで、SWE エージェントはファイルの内容を開いて検索したり、自動構文チェックを使用したり、特定の行を編集したり、テストを作成して実行したりできます。 (注: 上記の内容は元の内容を若干調整したものですが、原文の重要な情報は保持されており、指定された文字数制限を超えていません。) SWE-A
 Go 言語を使用してモバイル アプリケーションを開発する方法を学ぶ
Mar 28, 2024 pm 10:00 PM
Go 言語を使用してモバイル アプリケーションを開発する方法を学ぶ
Mar 28, 2024 pm 10:00 PM
Go 言語開発モバイル アプリケーション チュートリアル モバイル アプリケーション市場が活況を続ける中、ますます多くの開発者が Go 言語を使用してモバイル アプリケーションを開発する方法を検討し始めています。シンプルで効率的なプログラミング言語として、Go 言語はモバイル アプリケーション開発でも大きな可能性を示しています。この記事では、Go 言語を使用してモバイル アプリケーションを開発する方法を詳しく紹介し、読者がすぐに始めて独自のモバイル アプリケーションの開発を開始できるように、具体的なコード例を添付します。 1. 準備 始める前に、開発環境とツールを準備する必要があります。頭
 最も人気のある 5 つの Go 言語ライブラリの概要: 開発に不可欠なツール
Feb 22, 2024 pm 02:33 PM
最も人気のある 5 つの Go 言語ライブラリの概要: 開発に不可欠なツール
Feb 22, 2024 pm 02:33 PM
最も人気のある 5 つの Go 言語ライブラリの概要: 特定のコード例が必要な、開発に不可欠なツール Go 言語は、その誕生以来、広く注目され、応用されてきました。新しい効率的で簡潔なプログラミング言語としての Go の急速な開発は、豊富なオープンソース ライブラリのサポートと切り離すことができません。この記事では、Go 言語ライブラリの中で最も人気のある 5 つを紹介します. これらのライブラリは Go 開発において重要な役割を果たし、開発者に強力な機能と便利な開発エクスペリエンスを提供します。同時に、これらのライブラリの用途と機能をよりよく理解するために、具体的なコード例を示して説明します。
 Android 開発に最適な Linux ディストリビューションはどれですか?
Mar 14, 2024 pm 12:30 PM
Android 開発に最適な Linux ディストリビューションはどれですか?
Mar 14, 2024 pm 12:30 PM
Android 開発は多忙で刺激的な仕事であり、開発に適した Linux ディストリビューションを選択することが特に重要です。数多くある Linux ディストリビューションの中で、Android 開発に最適なのはどれでしょうか?この記事では、この問題をいくつかの側面から検討し、具体的なコード例を示します。まず、現在人気のある Linux ディストリビューション (Ubuntu、Fedora、Debian、CentOS など) をいくつか見てみましょう。これらにはそれぞれ独自の利点と特徴があります。
 Go 言語のフロントエンド テクノロジーの探求: フロントエンド開発の新しいビジョン
Mar 28, 2024 pm 01:06 PM
Go 言語のフロントエンド テクノロジーの探求: フロントエンド開発の新しいビジョン
Mar 28, 2024 pm 01:06 PM
Go 言語は、高速で効率的なプログラミング言語として、バックエンド開発の分野で広く普及しています。ただし、Go 言語をフロントエンド開発と結びつける人はほとんどいません。実際、フロントエンド開発に Go 言語を使用すると、効率が向上するだけでなく、開発者に新たな視野をもたらすことができます。この記事では、フロントエンド開発に Go 言語を使用する可能性を探り、読者がこの分野をよりよく理解できるように具体的なコード例を示します。従来のフロントエンド開発では、ユーザー インターフェイスの構築に JavaScript、HTML、CSS がよく使用されます。
 VSCode について: このツールは何に使用されますか?
Mar 25, 2024 pm 03:06 PM
VSCode について: このツールは何に使用されますか?
Mar 25, 2024 pm 03:06 PM
「VSCode について: このツールは何に使用されますか?」 》初心者でも経験豊富な開発者でも、プログラマーとしてはコード編集ツールを使わずにはいられません。数ある編集ツールの中でも、Visual Studio Code (略して VSCode) は、オープンソースで軽量かつ強力なコード エディターとして開発者の間で非常に人気があります。では、VSCode は正確に何に使用されるのでしょうか?この記事では、VSCode の機能と使用法を詳しく説明し、読者に役立つ具体的なコード例を提供します。
 総合ガイド: Java 仮想マシンのインストール プロセスの詳細
Jan 24, 2024 am 09:02 AM
総合ガイド: Java 仮想マシンのインストール プロセスの詳細
Jan 24, 2024 am 09:02 AM
Java 開発の必需品: Java 仮想マシンのインストール手順の詳細な説明、必要な特定のコード例 コンピューター科学技術の発展に伴い、Java 言語は最も広く使用されるプログラミング言語の 1 つになりました。クロスプラットフォームとオブジェクト指向という利点があり、開発者にとって徐々に好まれる言語になってきました。開発に Java を使用する前に、まず Java 仮想マシン (JavaVirtualMachine、JVM) をインストールする必要があります。この記事では、Java 仮想マシンのインストール手順を詳細に説明し、具体的なコード例を示します。
