

軌跡予測のための視覚的手法のレビュー

最近のレビュー論文「ビジョンによる軌道予測: 調査」は、ヒュンダイと Aptiv の会社 Motional からのものですが、これはオックスフォードのレビュー記事「自動運転車におけるビジョンベースの意図と軌道予測: 調査」を参照しています。大学 "。
予測タスクは基本的に 2 つの部分に分かれています: 1) 意図、エージェント用に一連の意図クラスを事前に設計する分類タスクです。通常、教師あり学習問題とみなされます。エージェントの分類意図の可能性をラベル付けするために必要である; 2) 軌道、ウェイポイントと呼ばれる、後続の将来のフレームにおけるエージェントの可能な位置のセットを予測する必要がある; これは、エージェント間およびエージェントと道路の間の相互作用を構成する。
これまでの行動予測モデルは、物理ベース、操作ベース、およびインタラクション知覚モデルの 3 つのカテゴリに分類できます。この文は次のように書き換えることができます: 物理モデルの力学的方程式を使用して、人工的に制御可能な動作がさまざまなタイプのエージェント向けに設計されます。この方法では、状況全体の潜在的な状態をモデル化することはできませんが、通常は特定のエージェントにのみ焦点を当てます。しかし、ディープラーニング以前の時代には、この傾向は SOTA でした。マニューバベースのモデルは、エージェントが予期する動きのタイプに基づいたモデルです。インタラクション対応モデルは通常、シーン内の各エージェントに対してペアごとの推論を実行し、すべての動的エージェントに対してインタラクション対応予測を生成する機械学習ベースのシステムです。シーン内で近くにあるさまざまなエージェント ターゲット間には高度な相関関係があります。複雑なエージェント軌跡注意モジュールをモデル化すると、より良い一般化につながる可能性があります。
将来のアクションやイベントの予測は、暗黙的に表現することも、将来の軌道を明示的に表現することもできます。エージェントの意図は次の影響を受ける可能性があります: a) エージェント自身の信念や願望 (これらは観察されないことが多く、モデル化が困難です); b) さまざまな方法でモデル化できる社会的相互作用 (例: プーリング、グラフ ニューラル ネットワーク、注意)など; c) 高解像度 (HD) マップを通じてエンコードできる道路レイアウトなどの環境制約; d) RGB 画像フレーム、LIDAR 点群、オプティカル フロー、セグメンテーション図などの形式の背景情報。一方、軌道予測は、意図の認識とは異なり、分類問題ではなく回帰 (連続) が関係するため、より困難な問題です。
軌道と意図は、相互作用の認識から始める必要があります。交通量の多い高速道路に積極的に進入しようとすると、追い越し車が急ブレーキをかける可能性があると考えるのが合理的です。モデリング。 軌道予測が可能な BEV 空間でモデル化することをお勧めしますが、画像ビュー (遠近法とも呼ばれます) でもモデル化することができます。この文は、「関心領域 (RoI) をグリッドの形式で専用の距離範囲に割り当てることができるためです。」と書き直すことができます。ただし、遠近法の消失線により、画像遠近法は理論的には RoI を無限に拡大できます。 BEV 空間は動きをより線形にモデル化するため、オクルージョンのモデル化に適しています。姿勢推定(自車両の平行移動と回転)を行うことで、自車両の動きの補償を簡単に行うことができます。さらに、このスペースはエージェントの動きとスケールを維持します。つまり、周囲の車両は、自車両からどれだけ離れていても、同じ数の BEV ピクセルを占有します。ただし、これは画像には当てはまりません。視点。未来を予測するには、過去を理解する必要があります。これは通常、追跡を通じて実行することも、過去の集約された BEV 特徴を使用して実行することもできます。
次の図は、予測モデルのいくつかのコンポーネントとデータ フローのブロック図です。
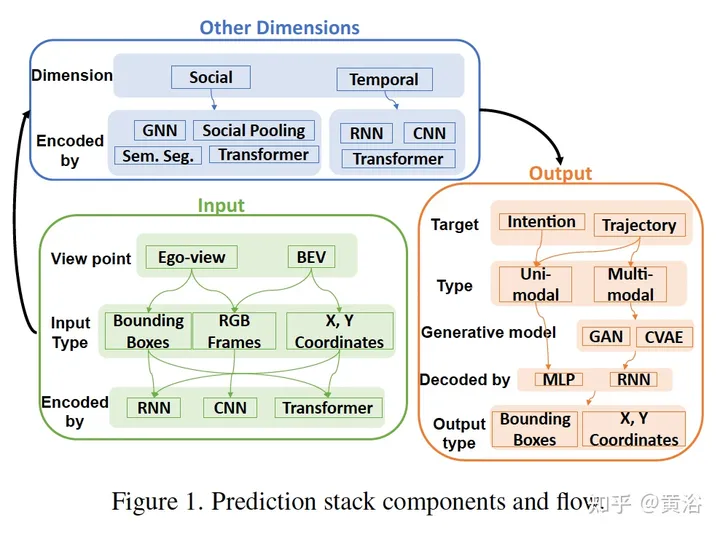
次の表は、予測モデルの概要です。
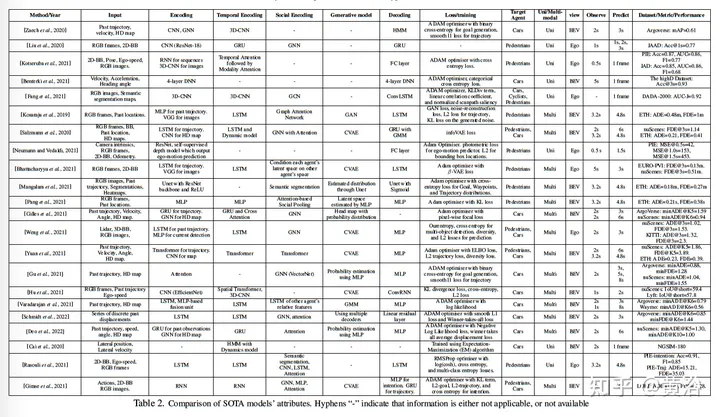
以下では基本的に、入力/出力から始まる予測モデルについて説明します。
1) トラックレット: 認識モジュールは、すべての動的エージェントの現在のステータスを予測します。この状態には、3D 中心、寸法、速度、加速度、その他の属性が含まれます。トラッカーはこのデータを利用して一時的な関連付けを確立し、各トラッカーがすべてのエージェントの状態の履歴を保存できるようにします。ここで、各トラックレットはエージェントの過去の動きを表します。この形式の予測モデルは、入力がまばらな軌跡のみで構成されているため、最も単純です。優れたトラッカーは、現在のフレームでエージェントが遮られている場合でも、エージェントを追跡できます。従来のトラッカーは非機械学習ネットワークに基づいているため、エンドツーエンドのモデルを実装することが非常に困難になります。
2) 生のセンサー データ: これはエンドツーエンドの方法であり、モデルは生のセンサー データ情報を取得し、シーン内の各エージェントの軌道予測を直接予測します。この方法には、複雑なトレーニングを監視するための補助出力とその損失がある場合とない場合があります。このタイプのアプローチの欠点は、入力が大量の情報を必要とし、計算コストがかかることです。これは、知覚、追跡、予測の 3 つの問題が融合しているため、モデルの開発が困難になり、収束の達成がさらに難しくなります。
3) カメラ vs BEV: BEV 手法は、上面図の地図のようなビューからデータを処理し、カメラ予測アルゴリズムは自車の視点から世界を認識します。後者は通常、BEV 手法よりも困難です。前者にはさまざまな理由がありますが、第一に、BEV の知覚では、より広い視野とより豊富な予測情報を得ることができますが、それに比べてカメラの視野は短く、自動車は視野外で計画を立てることができないため、予測範囲が制限されます。ビュー; さらに、カメラはブロックされる可能性が高いため、カメラベースのカメラとは異なります カメラ方式と比較して、BEV 方式は「部分的な可観測性」の課題が少なくなります; 第 2 に、LIDAR データが利用できない限り、単眼視では、アルゴリズムが問題のエージェントの深度を推測することが困難になります。これはエージェントの動作を予測するための重要な手がかりになります。最後に、カメラが移動するため、エージェントと自車両の動きに対処する必要があります。 、静的 BEV とは異なります; 注意事項: 欠点として、BEV 表現方法にはまだ累積誤差の問題があります; ただし、カメラ ビューの処理には固有の課題がありますが、それでも BEV よりも実用的です。また、自動車は、BEV や路上で関係するエージェントの位置を示すカメラにアクセスできることはほとんどありません。結論としては、予測システムは、ライダーやステレオ カメラを含む自車両の視点から世界を見ることができ、そのデータは世界を 3D で認識するのに有利である可能性があるということです。関連するもう 1 つの重要な点は、エージェントの位置を予測する場合、純粋な中心点ではなく境界ボックスの位置を使用する方が良いです。前者の座標は、車両と歩行者の間の相対距離の変化も暗示するためです。カメラの自己の動きとして、言い換えれば、エージェントとして 物体が自車両に近づくにつれて、境界ボックスが大きくなり、追加の (暫定的ではあるが) 深さの推定値が提供されます。
4) 自車の動きの予測: 自車両の動きをモデル化して、より正確な軌道を生成します。他のアプローチでは、ディープ ネットワークまたは動的モデルを使用して、ポーズ、オプティカル フロー、セマンティック マップ、ヒート マップなどのデータセット入力から計算される追加量を利用して、対象のエージェントの動きをモデル化します。
5) 時間領域エンコード: 運転環境は動的であり、アクティブなエージェントが多数存在するため、過去に何が起こったかを比較するより良い予測システムを構築するには、エージェントの時間次元でエンコードする必要があります。未来は現在起こっていることに結びついています。エージェントがどこから来たのかを知ることは、エージェントが次にどこへ行くかを推測するのに役立ちます。ほとんどのカメラベースのモデルはより短い時間スケールを扱いますが、より長い時間スケールでは予測を扱います。モデルにはより複雑な必要があります。構造。
6) ソーシャル エンコーディング: 「マルチエージェント」の課題に対処するために、最もパフォーマンスの高いアルゴリズムのほとんどは、さまざまなタイプのグラフ ニューラル ネットワーク (GNN) を使用してエージェント間のソーシャル インタラクションをエンコードします。時間的次元から始めて社会的次元を検討するか、またはその逆の順序で、社会的次元と社会的次元を別々に検討することができ、両方の次元を同時にエンコードする Transformer ベースのモデルがあります。
7) 期待される目標に基づく予測: シーンのコンテキストと同様に、行動意図の予測は通常、さまざまな期待される目標の影響を受けるため、説明を通じて推測する必要があります。期待される目標を条件とした将来の予測の場合、この目標は次のようにモデル化されます。将来の状態 (目的地座標として定義される) またはエージェントによって予期される動きのタイプ; 神経科学とコンピュータ ビジョンの研究によると、人間は通常、目標指向のエージェントであることが示されています; さらに、意思決定を行う際、人間は一連の連続したレベルに従います。推論し、最終的に短期または長期の計画を策定します。これに基づいて、質問は 2 つのカテゴリに分類できます。1 つ目は認知的なもので、エージェントがどこへ行くのかという質問に答えます。2 つ目は任意の性的なもので、次の質問に答えます。このエージェントが意図した目標をどのように達成するか。
8) マルチモーダル予測: 道路環境は確率的であるため、過去の軌跡が将来の異なる軌跡を展開する可能性があるため、「確率性」の課題を解決する実用的な予測システムは、この問題に大きな影響を与えるでしょう。不確実性はモデル化されます。離散変数の潜在空間モデリングの方法はありますが、マルチモダリティは軌跡にのみ適用され、意図の予測においてその可能性を十分に発揮します。重みの計算に使用できるアテンション メカニズムが使用されます。
以上が軌跡予測のための視覚的手法のレビューの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7700
7700
 15
1640
14
1393
52
1287
25
1230
29
15
1640
14
1393
52
1287
25
1230
29

 Windows 11 のスマート アプリ コントロール: オンまたはオフにする方法
Jun 06, 2023 pm 11:10 PM
Windows 11 のスマート アプリ コントロール: オンまたはオフにする方法
Jun 06, 2023 pm 11:10 PM
インテリジェント アプリ コントロールは、ランサムウェアやスパイウェアなど、データに損害を与える可能性のある不正なアプリから PC を保護する Windows 11 の非常に便利なツールです。この記事では、スマート アプリ コントロールとは何か、その仕組み、および Windows 11 でスマート アプリ コントロールをオンまたはオフにする方法について説明します。 Windows 11 のスマート アプリ コントロールとは何ですか? Smart App Control (SAC) は、Windows 1122H2 更新プログラムで導入された新しいセキュリティ機能です。 Microsoft Defender またはサードパーティのウイルス対策ソフトウェアと連携して、デバイスの速度を低下させたり、予期しない広告を表示したり、その他の予期しないアクションを実行したりする可能性のある不要なアプリをブロックします。スマートなアプリケーション
 ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
以前に書きましたが、今日は、深層学習テクノロジーが複雑な環境におけるビジョンベースの SLAM (同時ローカリゼーションとマッピング) のパフォーマンスをどのように向上させることができるかについて説明します。ここでは、深部特徴抽出と深度マッチング手法を組み合わせることで、低照度条件、動的照明、テクスチャの弱い領域、激しいセックスなどの困難なシナリオでの適応を改善するように設計された多用途のハイブリッド ビジュアル SLAM システムを紹介します。当社のシステムは、拡張単眼、ステレオ、単眼慣性、ステレオ慣性構成を含む複数のモードをサポートしています。さらに、他の研究にインスピレーションを与えるために、ビジュアル SLAM と深層学習手法を組み合わせる方法も分析します。公開データセットと自己サンプリングデータに関する広範な実験を通じて、測位精度と追跡堅牢性の点で SL-SLAM の優位性を実証しました。
 飛び回ったり、口を開けたり、見つめたり、眉毛を上げたりする顔の特徴をAIが完璧に模倣し、ビデオ詐欺を防ぐことは不可能
Dec 14, 2023 pm 11:30 PM
飛び回ったり、口を開けたり、見つめたり、眉毛を上げたりする顔の特徴をAIが完璧に模倣し、ビデオ詐欺を防ぐことは不可能
Dec 14, 2023 pm 11:30 PM
これほど強力なAIの模倣能力では、それを防ぐことは本当に不可能です。 AIの発展は今ここまで進んでいるのか?前足で顔の特徴を浮き上がらせ、後ろ足で全く同じ表情を再現し、見つめたり、眉を上げたり、口をとがらせたり、どんなに大袈裟な表情でも完璧に真似しています。難易度を上げて、眉毛を高く上げ、目を大きく開き、口の形も歪んでいるなど、バーチャルキャラクターアバターで表情を完璧に再現できます。左側のパラメータを調整すると、右側の仮想アバターもそれに合わせて動きが変化し、口や目の部分がアップになります。同じです(右端)。この研究は、GaussianAvatars を提案するミュンヘン工科大学などの機関によるものです。
 NeRFとは何ですか? NeRF ベースの 3D 再構成はボクセルベースですか?
Oct 16, 2023 am 11:33 AM
NeRFとは何ですか? NeRF ベースの 3D 再構成はボクセルベースですか?
Oct 16, 2023 am 11:33 AM
1 はじめに Neural Radiation Fields (NeRF) は、深層学習とコンピューター ビジョンの分野におけるかなり新しいパラダイムです。この技術は、ECCV2020 の論文「NeRF: Representing Scenes as Neural Radiation Fields for View Synthesis」(最優秀論文賞を受賞) で紹介され、それ以来非常に人気となり、現在までに 800 件近く引用されています [1]。このアプローチは、機械学習による 3D データの従来の処理方法に大きな変化をもたらします。神経放射線場のシーン表現と微分可能なレンダリング プロセス: カメラ光線に沿って 5D 座標 (位置と視線方向) をサンプリングして画像を合成し、これらの位置を MLP に入力して色と体積密度を生成し、体積レンダリング技術を使用してこれらの値を合成します。 ; レンダリング関数は微分可能であるため、渡すことができます。
 MotionLM: マルチエージェント動作予測のための言語モデリング技術
Oct 13, 2023 pm 12:09 PM
MotionLM: マルチエージェント動作予測のための言語モデリング技術
Oct 13, 2023 pm 12:09 PM
この記事は自動運転ハート公式アカウントより許可を得て転載しておりますので、転載については出典元までご連絡ください。原題: MotionLM: Multi-Agent Motion Forecasting as Language Modeling 論文リンク: https://arxiv.org/pdf/2309.16534.pdf 著者の所属: Waymo 会議: ICCV2023 論文のアイデア: 自動運転車の安全計画のために、将来の動作を確実に予測するロードエージェントの数は非常に重要です。この研究では、連続的な軌跡を離散的なモーション トークンのシーケンスとして表現し、マルチエージェントのモーション予測を言語モデリング タスクとして扱います。私たちが提案するモデル MotionLM には次の利点があります。
 自動運転の初の純粋な視覚的静的再構築
Jun 02, 2024 pm 03:24 PM
自動運転の初の純粋な視覚的静的再構築
Jun 02, 2024 pm 03:24 PM
純粋に視覚的な注釈ソリューションでは、主に視覚に加えて、GPS、IMU、および車輪速度センサーからのデータを動的注釈に使用します。もちろん、量産シナリオでは、純粋な視覚である必要はありません。一部の量産車両には固体レーダー (AT128) などのセンサーが搭載されています。大量生産の観点からデータの閉ループを作成し、これらすべてのセンサーを使用すると、動的オブジェクトのラベル付けの問題を効果的に解決できます。しかし、私たちの計画には固体レーダーはありません。したがって、この最も一般的な量産ラベル ソリューションを紹介します。純粋に視覚的な注釈ソリューションの中核は、高精度のポーズ再構築にあります。再構築の精度を確保するために、Structure from Motion (SFM) のポーズ再構築スキームを使用します。でもパスする
 3D ビジョンには点群の登録が不可欠です。すべての主流のソリューションと課題を 1 つの記事で理解する
Apr 02, 2024 am 11:31 AM
3D ビジョンには点群の登録が不可欠です。すべての主流のソリューションと課題を 1 つの記事で理解する
Apr 02, 2024 am 11:31 AM
点の集合体である点群は、3D再構築、工業用検査、ロボット操作などを通じて、物体の3次元(3D)表面情報の取得と生成に変化をもたらすことが期待されています。最も困難だが重要なプロセスは、点群の登録です。つまり、2 つの異なる座標で取得された 2 つの点群を位置合わせして一致させる空間変換を取得します。このレビューは、点群登録の概要と基本原理を紹介し、さまざまな方法を体系的に分類して比較し、点群登録に存在する技術的問題を解決することで、分野外の学術研究者やエンジニアに指導を提供し、統一されたビジョンに関する議論を促進することを目的としています。点群登録用。一般的な点群取得方法はアクティブ方式とパッシブ方式に分けられ、センサーが能動的に点群を取得するのがアクティブ方式で、点群は後で再構成されます。
 Occと自動運転の過去と現在を見てみよう!最初のレビューでは、機能強化/量産展開/アノテーションの効率化という 3 つの主要テーマを包括的にまとめています。
May 08, 2024 am 11:40 AM
Occと自動運転の過去と現在を見てみよう!最初のレビューでは、機能強化/量産展開/アノテーションの効率化という 3 つの主要テーマを包括的にまとめています。
May 08, 2024 am 11:40 AM
以上、筆者個人の理解 近年、自動運転はドライバーの負担軽減や運転の安全性の向上につながる可能性があるため、注目が高まっています。ビジョンベースの 3 次元占有予測は、自動運転の安全性に関する費用対効果の高い包括的な調査に適した新たな認識タスクです。オブジェクト中心の知覚タスクと比較して 3D 占有予測ツールの優位性は多くの研究で実証されていますが、この急速に発展している分野に特化したレビューはまだあります。このホワイトペーパーでは、まずビジョンベースの 3D 占有予測の背景を紹介し、このタスクで直面する課題について説明します。次に、現在の 3D 占有予測手法の現状と開発傾向を、機能強化、展開の容易さ、ラベル付けの効率という 3 つの側面から包括的に説明します。やっと
