
 テクノロジー周辺機器
AI
ビデオセグメンテーションのフィナーレ!浙江大学は最近 SAM-Track をリリースしました: ワンクリックでユニバーサルなインテリジェントビデオセグメンテーション
テクノロジー周辺機器
AI
ビデオセグメンテーションのフィナーレ!浙江大学は最近 SAM-Track をリリースしました: ワンクリックでユニバーサルなインテリジェントビデオセグメンテーション
ビデオセグメンテーションのフィナーレ!浙江大学は最近 SAM-Track をリリースしました: ワンクリックでユニバーサルなインテリジェントビデオセグメンテーション

最近、浙江大学の ReLER 研究室は、SAM とビデオ セグメンテーションを深く組み合わせ、Segment-and-Track Anything (SAM-Track) をリリースしました。
SAM-Track は、SAM にビデオ ターゲットを追跡する機能を提供し、複数のインタラクション方法 (ポイント、ブラシ、テキスト) をサポートします。
これに基づいて、SAM-Track は複数の従来のビデオ セグメンテーション タスクを統合し、ワンクリックであらゆるビデオ内のあらゆるターゲットのセグメンテーションと追跡を実現し、従来のビデオ セグメンテーションをユニバーサルなビデオ セグメンテーションに推定します。
SAM-Track は優れたパフォーマンスを備えており、複雑なシナリオでも 1 枚のカードで数百のターゲットを高品質で安定して追跡できます。

プロジェクトアドレス: https://github.com/z-x-yang/Segment-and-Track -Anything
##論文アドレス: https://arxiv.org/abs/2305.06558
エフェクト表示SAM-Track は、プロンプトとしての言語入力をサポートしています。たとえば、カテゴリ テキスト「パンダ」がある場合、ワンクリックのインスタンス レベルのセグメンテーションを使用して、カテゴリ「パンダ」に属するすべてのターゲットを追跡できます。

「左端のパンダ」というテキストを入力するなど、より詳細な説明を入力することもできます。SAM-Trackセグメンテーション追跡の特定のターゲットを見つけることができます。

従来のビデオ追跡アルゴリズムと比較して、SAM-Track のもう 1 つの強力な特徴は、多数のビデオ トラッキング アルゴリズムをターゲットにできることです。追跡セグメンテーションを実行し、出現するオブジェクトを自動的に検出します。

SAM-Track は、複数の対話型メソッドの組み合わせもサポートしており、ユーザーは実際のニーズに応じてそれらを組み合わせることができます。たとえば、ブラシを使用して人体に密接に関係するスケートボードのフレームを作成し、冗長なオブジェクトのセグメント化を防ぎ、クリックを使用して人体を選択します。
全自動のビデオ ターゲットのセグメンテーションと追跡が当然の問題になります。ストリート ビュー、航空写真、AR、アニメーション、医療画像などのさまざまなアプリケーション シナリオはすべてセグメント化できます。ワンクリックで自動的に追跡され、出現するオブジェクトを検出します。


 #ユーザーのオンライン エクスペリエンスを容易にするために、このプロジェクトでは、Colab を介してワンクリックでデプロイできる WebUI を提供します。
#ユーザーのオンライン エクスペリエンスを容易にするために、このプロジェクトでは、Colab を介してワンクリックでデプロイできる WebUI を提供します。
モデル構成
SAM-Track モデルは、ECCV'22 VOT ワークショップの 4 トラックチャンピオンシップスキーム DeAOT に基づいています。
DeAOT は効率的な多目的 VOS モデルであり、最初のフレームのオブジェクト アノテーションが与えられると、ビデオの残りのフレーム内のオブジェクトを追跡してセグメント化できます。
DeAOT は、認識メカニズムを使用してビデオ内の複数のターゲットを同じ高次元空間に埋め込み、それによって複数のオブジェクトの同時追跡を実現します。
DeAOT の複数オブジェクト追跡における速度パフォーマンスは、単一オブジェクト追跡の他の VOS 方式と同等です。
さらに、DeAOT は、階層化された Transformer ベースの伝播メカニズムを通じて、長期情報と短期情報をより適切に集約し、優れた追跡パフォーマンスを示します。
DeAOT では初期化に参照フレームのアノテーションが必要なため、利便性を高めるために、SAM-Track では最近画像分野で話題になっている Segment Anything Model (SAM) モデルを使用しています。ラベル情報を取得するためのセグメンテーション。
SAM の優れたゼロサンプル マイグレーション機能と複数のインタラクション手法を使用して、SAM-Track は DeAOT の高品質の参照フレーム アノテーション情報を効率的に取得できます。
SAM モデルは画像セグメンテーションの分野では良好に機能しますが、セマンティック ラベルを出力できず、テキスト プロンプトはオブジェクトのセグメンテーションの参照や、セマンティックの深い理解に依存するその他のタスクを十分にサポートできません。
したがって、SAM-Track モデルは、Grounding-DINO をさらに統合して、高精度の言語ガイド付きビデオ セグメンテーションを実現します。 Grounding DINO は、優れた言語理解機能を備えたオープンセットの物体検出モデルです。
入力カテゴリまたはターゲット オブジェクトの詳細な説明に基づいて、Grounding-DINO はターゲットを検出し、ロケーション ボックスを返すことができます。
SAM-Track モデル アーキテクチャ
下の図に示すように、SAM-Track モデルは、対話型追跡モード、自動追跡モード、およびフュージョンモード。
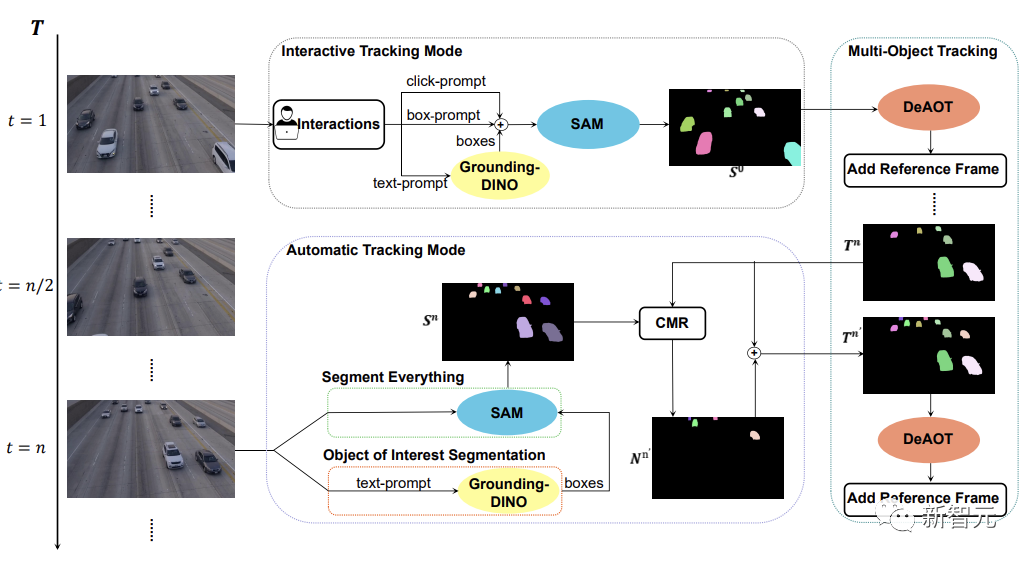
インタラクティブ トラッキング モードの場合、SAM-Track モデルはまず、参照フレーム内のクリックまたはフレームを使用して SAM を適用します。このようにして、ユーザーが満足するインタラクティブなセグメンテーション結果が得られるまでターゲットを絞り込みます。
言語ガイド付きビデオ オブジェクト セグメンテーションを実装する場合、SAM-Track は入力テキストに基づいて Grounding-DINO を呼び出し、まずターゲット オブジェクトの位置フレームを取得します。 SAM を通じて対象オブジェクトのセグメンテーション結果を取得します。
最後に、DeAOT は、選択されたターゲットを追跡するための参照フレームとしてインタラクティブ セグメンテーションの結果を使用します。追跡プロセス中に、DeAOT は、過去のフレームに埋め込まれた視覚的埋め込みと高次元 ID 埋め込みを現在のフレームに階層的に伝播させ、複数のターゲット オブジェクトのフレームごとの追跡とセグメンテーションを実現します。したがって、SAM-Track は、マルチモーダル インタラクションをサポートすることで、セグメント化されたビデオ内の対象オブジェクトを追跡できます。
ただし、インタラクティブ追跡モードでは、ビデオ内に出現する新たに出現したオブジェクトを処理できません。自動運転、スマートシティなどの特定の分野での SAM-Track の適用を制限します。
SAM-Track の適用範囲とパフォーマンスをさらに拡張するために、SAM-Track はビデオに表示される新しいオブジェクトを追跡する自動追跡モードを実装しています。
自動追跡モードは、すべてをセグメント化および対象オブジェクトのセグメント化を使用して、n フレームごとに出現する新しいオブジェクトの注釈を取得します。新しく出現したオブジェクトの ID 割り当ての問題については、SAM-Track は比較マスク モジュール (CMR) を使用して新しいオブジェクトの ID を決定します。
フュージョン モードは、インタラクティブ トラッキング モードと自動トラッキング モードを組み合わせたものです。インタラクティブ トラッキング モードでは、ビデオの最初のフレームの注釈を簡単に取得できます。一方、自動トラッキング モードでは、ビデオの後続のフレームに表示される選択されていない新しいオブジェクトを処理します。追跡方法を組み合わせることで、SAM-Track の適用範囲が広がり、SAM-Track の実用性が高まります。
以上がビデオセグメンテーションのフィナーレ!浙江大学は最近 SAM-Track をリリースしました: ワンクリックでユニバーサルなインテリジェントビデオセグメンテーションの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1657
1657
 14
1415
52
1309
25
1257
29
1231
24
14
1415
52
1309
25
1257
29
1231
24

 動画ファイルはブラウザのキャッシュのどこに保存されますか?
Feb 19, 2024 pm 05:09 PM
動画ファイルはブラウザのキャッシュのどこに保存されますか?
Feb 19, 2024 pm 05:09 PM
ブラウザはビデオをどのフォルダにキャッシュしますか? 私たちは毎日インターネット ブラウザを使用するときに、YouTube でミュージック ビデオを視聴したり、Netflix で映画を視聴したりするなど、さまざまなオンライン ビデオを視聴することがよくあります。これらのビデオは読み込みプロセス中にブラウザによってキャッシュされるため、将来再び再生するときにすぐに読み込むことができます。そこで問題は、これらのキャッシュされたビデオが実際にどのフォルダーに保存されるのかということです。ブラウザーが異なれば、キャッシュされたビデオ フォルダーは異なる場所に保存されます。以下に、いくつかの一般的なブラウザとそのブラウザを紹介します。
 他人の動画をDouyinに投稿することは侵害になりますか?侵害せずにビデオを編集するにはどうすればよいですか?
Mar 21, 2024 pm 05:57 PM
他人の動画をDouyinに投稿することは侵害になりますか?侵害せずにビデオを編集するにはどうすればよいですか?
Mar 21, 2024 pm 05:57 PM
ショートビデオプラットフォームの台頭により、Douyinはみんなの日常生活に欠かせないものになりました。 TikTokでは世界中の面白い動画を見ることができます。他人のビデオを投稿することを好む人もいますが、「Douyin は他人のビデオを投稿することを侵害しているのでしょうか?」という疑問が生じます。この記事では、この問題について説明し、著作権を侵害せずに動画を編集する方法と、著作権侵害の問題を回避する方法について説明します。 1.Douyin による他人の動画の投稿は侵害ですか?私の国の著作権法の規定によれば、著作権者の著作物を著作権者の許可なく無断で使用することは侵害となります。したがって、オリジナルの作者または著作権所有者の許可なしに他人のビデオをDouyinに投稿することは侵害となります。 2. 著作権を侵害せずにビデオを編集するにはどうすればよいですか? 1. パブリックドメインまたはライセンスされたコンテンツの使用: パブリック
 Wink でビデオの透かしを削除する方法
Feb 23, 2024 pm 07:22 PM
Wink でビデオの透かしを削除する方法
Feb 23, 2024 pm 07:22 PM
Wink でビデオからウォーターマークを削除するにはどうすればよいですか? winkAPP にはビデオからウォーターマークを削除するツールがありますが、ほとんどの友達は wink でビデオからウォーターマークを削除する方法を知りません。次は Wink でビデオからウォーターマークを削除する方法の画像です。編集者が持参したテキストチュートリアルですので、興味のある方はぜひ見に来てください! Wink でビデオ透かしを削除する方法 1. まず、Wink APP を開き、ホームページ領域で [透かしを削除] 機能を選択します; 2. 次に、アルバムで透かしを削除したいビデオを選択します; 3. 次に、ビデオを選択してクリックしますビデオ編集後、右上隅にある [√]; 4. 最後に、下図のように [ワンクリック印刷] をクリックし、[処理] をクリックします。
 MobileSAM: モバイル デバイス向けの高性能で軽量な画像セグメンテーション モデル
Jan 05, 2024 pm 02:50 PM
MobileSAM: モバイル デバイス向けの高性能で軽量な画像セグメンテーション モデル
Jan 05, 2024 pm 02:50 PM
1. はじめに モバイル デバイスの普及とコンピューティング能力の向上に伴い、画像セグメンテーション技術が研究のホットスポットになっています。 MobileSAM (MobileSegmentAnythingModel) は、モバイル デバイス向けに最適化された画像セグメンテーション モデルであり、高品質のセグメンテーション結果を維持しながら計算の複雑さとメモリ使用量を削減し、リソースが限られたモバイル デバイスで効率的に実行することを目的としています。この記事では、MobileSAM の原理、利点、適用シナリオについて詳しく紹介します。 2. MobileSAM モデルの設計思想 MobileSAM モデルの設計思想には主に次の側面が含まれます: 軽量モデル: モバイル デバイスのリソース制限に適応するために、MobileSAM モデルは軽量モデルを採用します。
 小紅書ビデオ作品を公開するにはどうすればよいですか?動画を投稿する際に注意すべきことは何ですか?
Mar 23, 2024 pm 08:50 PM
小紅書ビデオ作品を公開するにはどうすればよいですか?動画を投稿する際に注意すべきことは何ですか?
Mar 23, 2024 pm 08:50 PM
短編ビデオ プラットフォームの台頭により、Xiaohongshu は多くの人々が自分の生活を共有し、自分自身を表現し、トラフィックを獲得するためのプラットフォームになりました。このプラットフォームでは、ビデオ作品の公開が非常に人気のある交流方法です。では、小紅書ビデオ作品を公開するにはどうすればよいでしょうか? 1.小紅書ビデオ作品を公開するにはどうすればよいですか?まず、共有できるビデオ コンテンツがあることを確認します。携帯電話やその他のカメラ機器を使用して撮影することもできますが、画質と音声の明瞭さには注意する必要があります。 2.ビデオを編集する:作品をより魅力的にするために、ビデオを編集できます。 Douyin、Kuaishou などのプロ仕様のビデオ編集ソフトウェアを使用して、フィルター、音楽、字幕、その他の要素を追加できます。 3. 表紙を選択する: 表紙はユーザーのクリックを誘致するための鍵です。ユーザーのクリックを誘致するために、表紙には鮮明で興味深い写真を選択してください。
 iPhoneのビデオからスローモーションを削除する2つの方法
Mar 04, 2024 am 10:46 AM
iPhoneのビデオからスローモーションを削除する2つの方法
Mar 04, 2024 am 10:46 AM
iOS デバイスでは、カメラ アプリを使用してスローモーション ビデオを撮影できます。最新の iPhone を使用している場合は、1 秒あたり 240 フレームのビデオを撮影することもできます。この機能により、高速アクションを詳細にキャプチャできます。ただし、ビデオの詳細やアクションをよりよく理解するために、スローモーション ビデオを通常の速度で再生したい場合もあります。この記事では、iPhone上の既存のビデオからスローモーションを削除するすべての方法を説明します。 iPhoneでビデオからスローモーションを削除する方法[2つの方法] 写真アプリまたはiMovieアプリを使用して、デバイス上のビデオからスローモーションを削除できます。方法 1: 写真アプリを使用して iPhone で開く
 Douyin に動画を投稿して収益を得るにはどうすればよいですか?初心者はどうやってDouyinでお金を稼ぐことができますか?
Mar 21, 2024 pm 08:17 PM
Douyin に動画を投稿して収益を得るにはどうすればよいですか?初心者はどうやってDouyinでお金を稼ぐことができますか?
Mar 21, 2024 pm 08:17 PM
全国的なショートビデオプラットフォームであるDouyinは、自由な時間にさまざまな興味深く斬新なショートビデオを楽しむことができるだけでなく、自分自身を示し、自分の価値観を実現するステージも提供します。では、Douyin に動画を投稿してお金を稼ぐにはどうすればよいでしょうか?この記事ではこの質問に詳しく答え、TikTokでより多くのお金を稼ぐのに役立ちます。 1.Douyin に動画を投稿してお金を稼ぐにはどうすればよいですか?動画を投稿し、Douyin で一定の再生回数を獲得すると、広告共有プランに参加できるようになります。この収入方法はDouyinユーザーにとって最も馴染みのある方法の1つであり、多くのクリエイターにとって主な収入源でもあります。 Douyin は、アカウントの重み、動画コンテンツ、視聴者のフィードバックなどのさまざまな要素に基づいて、広告共有の機会を提供するかどうかを決定します。 TikTok プラットフォームでは、視聴者がギフトを送ったり、
 画質を圧縮せずにWeiboに動画を投稿する方法_画質を圧縮せずにWeiboに動画を投稿する方法
Mar 30, 2024 pm 12:26 PM
画質を圧縮せずにWeiboに動画を投稿する方法_画質を圧縮せずにWeiboに動画を投稿する方法
Mar 30, 2024 pm 12:26 PM
1. まず携帯電話で Weibo を開き、右下隅の [Me] をクリックします (図を参照)。 2. 次に、右上隅の [歯車] をクリックして設定を開きます (図を参照)。 3. 次に、[一般設定] を見つけて開きます (図を参照)。 4. 次に、[Video Follow] オプションを入力します (図を参照)。 5. 次に、[ビデオアップロード解像度]設定を開きます(図を参照)。 6. 最後に、圧縮を避けるために [オリジナルの画質] を選択します (図を参照)。
