

Baidu Wenxinyiyanは国内モデルの中で最下位にランクされますか?私は混乱していた

Xi Xiaoyao Technology Talk 原文
著者 | 孟江の販売 ここ数日、私たちのパブリック アカウント コミュニティが SuperClue レビューと呼ばれるスクリーンショットを転送しています。 iFlytek は公式アカウントでもこの製品を宣伝しています:

# iFlytek Spark モデルはリリースされたばかりなので、あまりプレイしていません。本当に最強ですか?中国製? 著者はあえて結論を出さない。
しかし、この評価のスクリーンショットでは、現時点で最も人気のある国内モデルである Baidu Wenxinyiyan は、小規模な学術オープンソース モデル ChatGLM-6B にも勝てません。これは著者自身の経験と大きく矛盾しているだけでなく、私たちのプロの NLP 技術コミュニティでも誰もが混乱を表明しました。好奇心から、著者はこの超手がかりリストの github にアクセスして、この評価結論にどのように到達したかを確認しました:
https://www.php.cn/link/97c8dd44858d3568fdf9537c4b8743b2
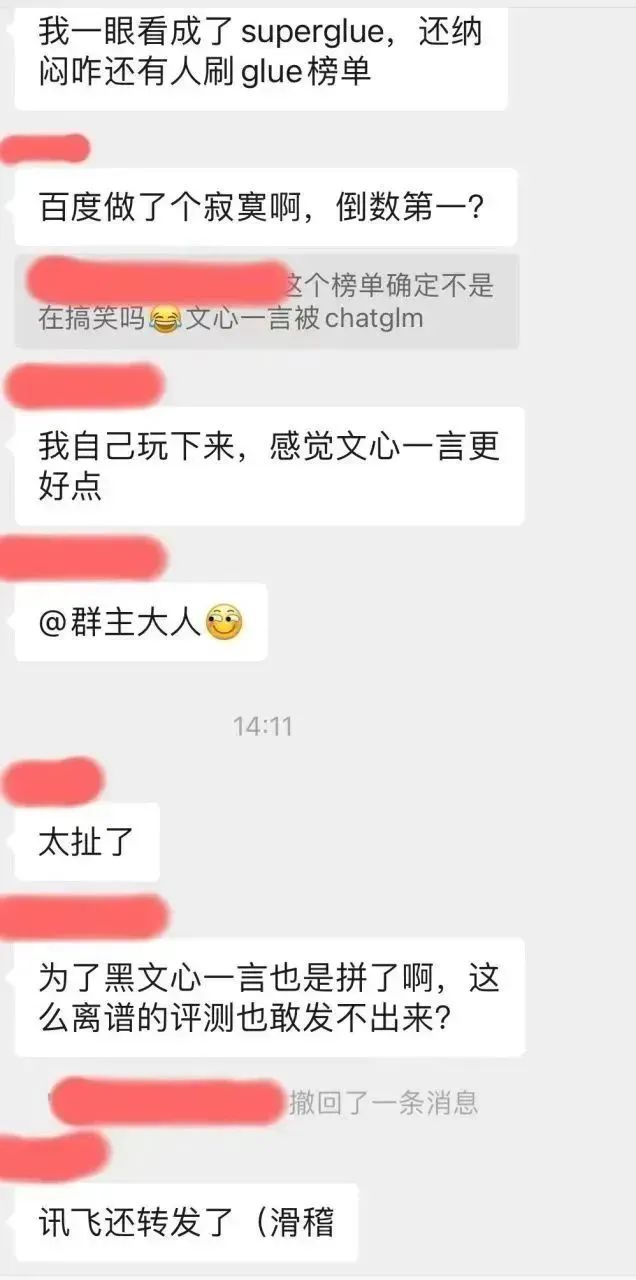
このとんでもない感情は、作者だけが抱えているわけではないようです。それは確かに、大衆の目は依然として鋭いです。 。 。
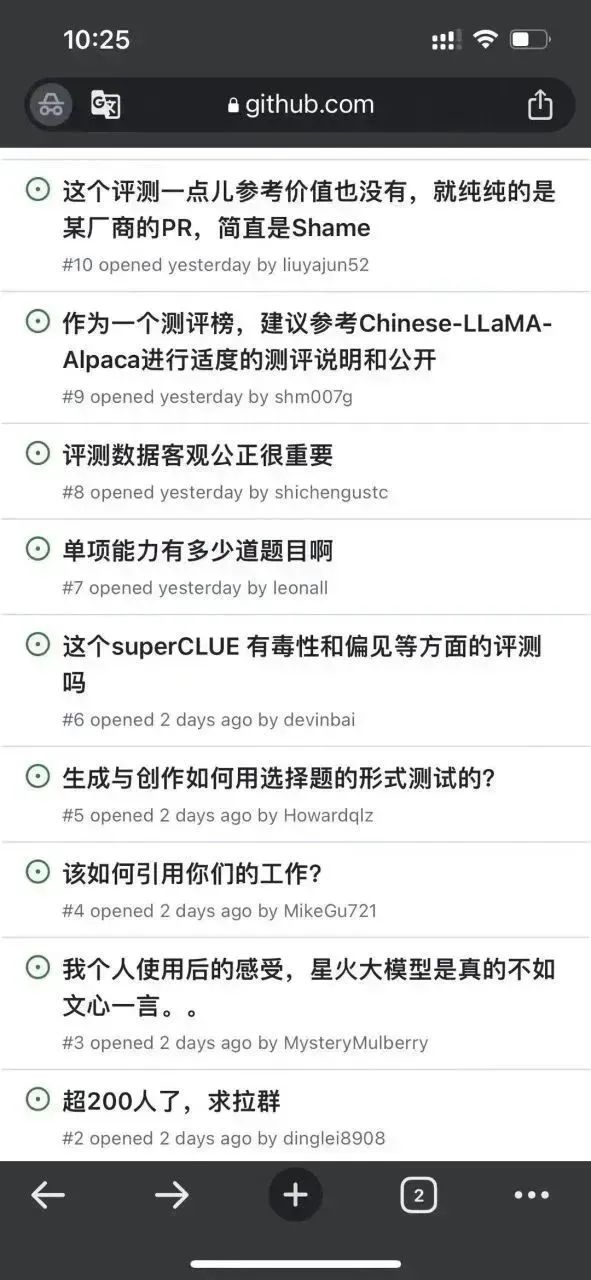
著者は、このリストの評価方法をさらに検討しました: 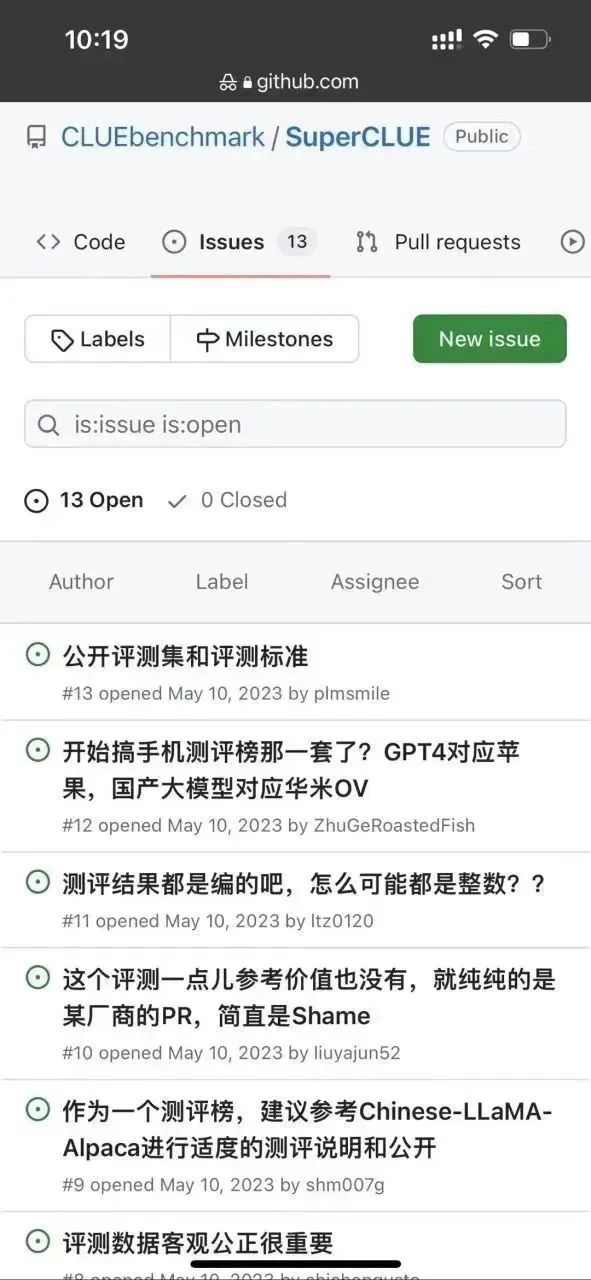
 たとえば、機械翻訳などの特殊な生成タスクの場合、モデルによって生成された応答と参照応答の間の「語彙とフレーズのカバレッジ」を検出するために、BLEU などの評価指標が一般的に使用されます。ただし、機械翻訳などの参照応答を伴う生成タスクはほとんどなく、生成評価の大部分は手動評価を必要とします。
たとえば、機械翻訳などの特殊な生成タスクの場合、モデルによって生成された応答と参照応答の間の「語彙とフレーズのカバレッジ」を検出するために、BLEU などの評価指標が一般的に使用されます。ただし、機械翻訳などの参照応答を伴う生成タスクはほとんどなく、生成評価の大部分は手動評価を必要とします。
たとえば、チャット スタイルのダイアログの生成、テキスト スタイルの転送、章の生成、タイトルの生成、テキストの要約などの生成タスクでは、各モデルを評価して応答を自由に生成し、手動で比較する必要があります。これらのさまざまなモデルによって生成される応答、品質、またはタスクの要件が満たされているかどうかに関する人間の判断。
現在の AI コンテストはモデル生成能力のコンテストであり、モデル識別能力のコンテストではありません。評価すべき最も強力なものは、もはや冷淡な学術リストではなく、実際のユーザーの評判です。さらに、これはモデル生成機能をまったくテストしていないリストです。
過去数年を振り返る-
2019 年に OpenAI が GPT-2 をリリースしたとき、私たちはランキングをブラッシュアップするためのコツを積み上げていました;
2020 年には、 OpenAI がリリース GPT-3 中に、私たちはリストを更新するためのトリックを積み上げていました;
2021 年から 2022 年に、FLAN、T0、InstructGPT などの命令チューニングと RLHF 作業が発生したとき、私たちはまだ多くのトリックを持っていましたリスト...
この生成モデル軍備競争の波で同じ過ちを繰り返さないことを願っています。
では、生成 AI モデルはどのようにテストすればよいのでしょうか?
申し訳ありませんが、前にも述べたように、公平なテストを達成することは非常に困難であり、自分で生成モデルを開発するよりもさらに困難です。何が難しいのでしょうか?いくつかの具体的な質問:
- 評価の次元をどのように分割するか?理解、記憶、推論、表現によって?専門分野別ですか?それとも従来の NLP 生成評価タスクを組み合わせますか?
- 評価者をトレーニングするにはどうすればよいですか?コーディング、デバッグ、数学的導出、財務、法律、医療に関する Q&A など、専門的基準が非常に高いテスト問題の場合、テストする人をどのように募集しますか?
- 非常に主観的なテスト問題 (小紅書風のコピーライティングの作成など) の評価基準を定義するにはどうすればよいですか?
- 一般的なライティングに関する質問をいくつかすることで、モデルのテキスト生成/ライティング能力を表すことができますか?
- モデルのテキスト生成のサブ機能を調べます。章の生成、質問と回答の生成、翻訳、要約、スタイルの転送はカバーされていますか?各タスクの割合は均等ですか?審査基準は明確ですか?統計学的に重要な?
- 上記の質問と回答の生成サブタスクでは、科学、医療、自動車、母子、金融、エンジニアリング、政治、軍事、エンターテイメントなどのすべての垂直カテゴリがカバーされていますか?割合は均等ですか?
- 会話能力を評価するにはどうすればよいですか?対話の一貫性、多様性、話題の深さ、個性化のための検査タスクをどのように設計するか?
- 同じ実力テストでも、簡単な問題、中程度の難易度の問題、複雑な長期問題が対象になりますか?定義方法は?それらはどのような割合を占めていますか?
これらは解決すべき基本的な問題のほんの一部ですが、実際のベンチマーク設計の過程では、上記の問題よりもさらに難しい問題が数多く発生します。
したがって、AI 実践者として、著者はさまざまな AI モデルのランキングを合理的に見るよう皆さんに呼びかけます。公平なテストベンチマークさえ存在しないのに、このランキングは何の役に立つのでしょうか?
繰り返しになりますが、生成モデルが良いかどうかは実際のユーザーに依存します。
モデルがリストでどれほど上位にランクされていても、関心のある問題を解決できない場合、それはあなたにとっては単なる平均的なモデルになります。つまり、最下位の機種が気になるシナリオに非常に強い機種であれば、それはあなたにとってお宝機種ということになります。
ここでは、著者が私たちのチームによって強化され書かれたハードケース (難しい例) のテスト セットを公開します。このテスト セットは、難しい問題や命令を解決するモデルの能力に焦点を当てています。
この難しいテスト セットは、モデルの言語理解、複雑な命令の理解とそれに従うこと、テキスト生成、複雑なコンテンツ生成、複数回の対話、矛盾検出、常識的推論、数学的推論、反事実的推論、および危険に焦点を当てています。情報 身分証明、法的および倫理的意識、中国文学の知識、異言語能力およびコーディング能力など。
繰り返しになりますが、これは、困難な例を解決する生成モデルの能力をテストするために、著者のチームが作成したケースセットです。評価結果は、「著者のチームにとってどのモデルがより良いと感じられるか」を表すだけであり、とは程遠いです。公平なテストの結論を表す 公平なテストの結論が必要な場合は、まず上記の評価質問に答えてから、信頼できるテスト ベンチマークを定義してください。
自分で評価して検証したい友人は、この公開アカウント「Xi Xiaoyao Technology」のバックグラウンドで [AI 評価] のパスワードに返信して、テスト ファイルをダウンロードできます
以下は、超手がかりリストで最も物議を醸している 3 つのモデル、iFlytek Spark、Wenxin Yiyan、ChatGPT の評価結果です。



- ChatGPT (GPT-3.5-turbo): 11/24=45.83%
- Wen Xinyi Words (2023.5) .10 バージョン): 13/24=54.16%
- iFlytek Spark (2023.5.10 バージョン): 7/24=29.16%
素朴な疑問ですが、実は国内モデルとChatGPTには大きな違いはありません。難しい問題に対しては、各モデルに独自の強みがあります。著者のチームの包括的な経験から判断すると、Wen Xinyiyan は、学術テストでは ChatGLM-6B などのオープン ソース モデルを上回るのに十分ですが、ChatGPT よりも劣る機能もあれば、ChatGPT を上回る機能もあります。
Alibaba Tongyi Qianwen や iFlytek Spark など、他の大手メーカーが製造する国内モデルも同様です。
そうは言っても、現在では公平なテスト ベンチマークさえ存在しないのに、モデルをランク付けすることに何の意味があるのでしょうか?
さまざまな偏ったランキングについて議論するよりも、著者のチームが行ったように、関心のあるテスト セットを作成する方が良いでしょう。
問題を解決できるモデルは、優れたモデルです。
以上がBaidu Wenxinyiyanは国内モデルの中で最下位にランクされますか?私は混乱していたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7698
7698
 15
1640
14
1393
52
1287
25
1229
29
15
1640
14
1393
52
1287
25
1229
29

 OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
ソフトウェア テクノロジの最前線に立つ UIUC Zhang Lingming のグループは、BigCode 組織の研究者とともに、最近 StarCoder2-15B-Instruct 大規模コード モデルを発表しました。この革新的な成果により、コード生成タスクにおいて大きな進歩が達成され、CodeLlama-70B-Instruct を上回り、コード生成パフォーマンス リストのトップに到達しました。 StarCoder2-15B-Instruct のユニークな特徴は、その純粋な自己調整戦略であり、トレーニング プロセス全体がオープンで透過的で、完全に自律的で制御可能です。このモデルは、高価な手動アノテーションに頼ることなく、StarCoder-15B 基本モデルの微調整に応じて、StarCoder2-15B を介して数千の命令を生成します。
 Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。
Jun 07, 2024 pm 12:05 PM
Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。
Jun 07, 2024 pm 12:05 PM
1. はじめに ここ数年、YOLO は、計算コストと検出パフォーマンスの効果的なバランスにより、リアルタイム物体検出の分野で主流のパラダイムとなっています。研究者たちは、YOLO のアーキテクチャ設計、最適化目標、データ拡張戦略などを調査し、大きな進歩を遂げました。同時に、後処理に非最大抑制 (NMS) に依存すると、YOLO のエンドツーエンドの展開が妨げられ、推論レイテンシに悪影響を及ぼします。 YOLO では、さまざまなコンポーネントの設計に包括的かつ徹底的な検査が欠けており、その結果、大幅な計算冗長性が生じ、モデルの機能が制限されます。効率は最適ではありませんが、パフォーマンス向上の可能性は比較的大きくなります。この作業の目標は、後処理とモデル アーキテクチャの両方から YOLO のパフォーマンス効率の境界をさらに改善することです。この目的を達成するために
 清華大学が引き継ぎ、YOLOv10 が登場しました。パフォーマンスが大幅に向上し、GitHub のホット リストに掲載されました。
Jun 06, 2024 pm 12:20 PM
清華大学が引き継ぎ、YOLOv10 が登場しました。パフォーマンスが大幅に向上し、GitHub のホット リストに掲載されました。
Jun 06, 2024 pm 12:20 PM
ターゲット検出システムのベンチマークである YOLO シリーズが再び大幅にアップグレードされました。今年 2 月の YOLOv9 のリリース以来、YOLO (YouOnlyLookOnce) シリーズのバトンは清華大学の研究者の手に渡されました。先週末、YOLOv10 のリリースのニュースが AI コミュニティの注目を集めました。これは、コンピュータ ビジョンの分野における画期的なフレームワークと考えられており、リアルタイムのエンドツーエンドの物体検出機能で知られており、効率と精度を組み合わせた強力なソリューションを提供することで YOLO シリーズの伝統を継承しています。論文アドレス: https://arxiv.org/pdf/2405.14458 プロジェクトアドレス: https://github.com/THU-MIG/yo
 Deepseek Webバージョンの入り口Deepseek公式ウェブサイトの入り口
Feb 19, 2025 pm 04:54 PM
Deepseek Webバージョンの入り口Deepseek公式ウェブサイトの入り口
Feb 19, 2025 pm 04:54 PM
DeepSeekは、Webバージョンと公式Webサイトの2つのアクセス方法を提供する強力なインテリジェント検索および分析ツールです。 Webバージョンは便利で効率的であり、公式ウェブサイトは包括的な製品情報、ダウンロードリソース、サポートサービスを提供できます。個人であろうと企業ユーザーであろうと、DeepSeekを通じて大規模なデータを簡単に取得および分析して、仕事の効率を向上させ、意思決定を支援し、イノベーションを促進することができます。
 Google Gemini 1.5 テクニカル レポート: 数学オリンピックの問題を簡単に証明、Flash バージョンは GPT-4 Turbo より 5 倍高速
Jun 13, 2024 pm 01:52 PM
Google Gemini 1.5 テクニカル レポート: 数学オリンピックの問題を簡単に証明、Flash バージョンは GPT-4 Turbo より 5 倍高速
Jun 13, 2024 pm 01:52 PM
今年 2 月、Google はマルチモーダル大型モデル Gemini 1.5 を発表しました。これは、エンジニアリングとインフラストラクチャの最適化、MoE アーキテクチャ、その他の戦略を通じてパフォーマンスと速度を大幅に向上させました。より長いコンテキスト、より強力な推論機能、およびクロスモーダル コンテンツのより適切な処理が可能になります。今週金曜日、Google DeepMind は Gemini 1.5 の技術レポートを正式にリリースしました。このレポートには Flash バージョンとその他の最近のアップグレードが含まれています。このドキュメントは 153 ページあります。技術レポートのリンク: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf このレポートでは、Google が Gemini1 を紹介しています。
 レビュー!自動運転推進におけるベーシックモデルの重要な役割を総まとめ
Jun 11, 2024 pm 05:29 PM
レビュー!自動運転推進におけるベーシックモデルの重要な役割を総まとめ
Jun 11, 2024 pm 05:29 PM
上記および著者の個人的な理解: 最近、ディープラーニング技術の発展と進歩により、大規模な基盤モデル (Foundation Model) が自然言語処理とコンピューター ビジョンの分野で大きな成果を上げています。自動運転における基本モデルの応用にも大きな発展の可能性があり、シナリオの理解と推論を向上させることができます。豊富な言語と視覚データの事前トレーニングを通じて、基本モデルは自動運転シナリオのさまざまな要素を理解して解釈し、推論を実行して、運転の意思決定と計画のための言語とアクションのコマンドを提供します。基本モデルは、運転シナリオを理解してデータを拡張することで、日常的な運転やデータ収集では遭遇する可能性が低い、ロングテール分布におけるまれな実現可能な機能を提供できます。
 データセットが異なればスケーリング則も異なりますか?圧縮アルゴリズムを使用してそれを予測できます
Jun 07, 2024 pm 05:51 PM
データセットが異なればスケーリング則も異なりますか?圧縮アルゴリズムを使用してそれを予測できます
Jun 07, 2024 pm 05:51 PM
一般に、ニューラル ネットワークのトレーニングに必要な計算が増えるほど、パフォーマンスが向上します。計算をスケールアップするときは、モデル パラメーターの数を増やすか、データ セットのサイズを増やすかを決定する必要があります。この 2 つの要素は、固定された計算予算内で比較検討する必要があります。モデル パラメーターの数を増やす利点は、モデルの複雑さと表現能力が向上し、それによってトレーニング データの適合性が向上することです。ただし、パラメーターが多すぎると過剰適合が発生し、目に見えないデータに対するモデルのパフォーマンスが低下する可能性があります。一方、データセットのサイズを拡張すると、モデルの汎化能力が向上し、過剰適合の問題が軽減されます。パラメーターとデータを適切に割り当てている限り、固定されたコンピューティング予算内でパフォーマンスを最大化できます。これまでの多くの研究では、神経言語モデルの Scalingl が検討されてきました。
 LLaVA をモジュール的に再構築します。コンポーネントを置き換えるには、1 ~ 2 個のファイルを追加するだけです。オープンソースの TinyLLaVA Factory がここにあります。
Jun 08, 2024 pm 09:21 PM
LLaVA をモジュール的に再構築します。コンポーネントを置き換えるには、1 ~ 2 個のファイルを追加するだけです。オープンソースの TinyLLaVA Factory がここにあります。
Jun 08, 2024 pm 09:21 PM
TinyLLaVA+ プロジェクトは、清華大学電子学部マルチメディア信号知能情報処理研究室 (MSIIP) の Wu Ji 教授のチームと、北航大学人工知能学部の Huang Lei 教授のチームによって共同で作成されました。清華大学の MSIIP 研究室は、インテリジェント医療、自然言語処理と知識発見、マルチモダリティなどの研究分野に長年取り組んできました。北京航空のチームは、ディープラーニング、マルチモダリティ、コンピュータービジョンなどの研究分野に長年取り組んできました。 TinyLLaVA+ プロジェクトの目標は、言語理解、質疑応答、対話などのマルチモーダル機能を備えた小型の言語を越えたインテリジェント アシスタントを開発することです。プロジェクトチームはそれぞれの利点を最大限に発揮し、技術的課題を共同で克服し、インテリジェントアシスタントの設計と開発を実現していきます。これにより、インテリジェントな医療、自然言語処理、知識の機会が提供されます。
