

自己認識 AI: AutoGPT

1. はじめに
ChatGPT は現在非常に人気があります。自然言語処理モデルのリーダーとしての ChatGPT の利点は、スムーズで一貫した会話を生成できると同時に、コンテキストを理解できることです。そしてコンテキストに従って行動します。さまざまなアプリケーション シナリオに合わせて迅速にカスタマイズでき、たとえば、顧客サービス、教育、エンターテイメントなどの分野で、ChatGPT をインテリジェント アシスタントとして使用して、ユーザーに便利なサービスとエンターテイメント体験を提供できます。
GPT-3 から GPT-4 まで、高度な推論、入力設定、動作の微調整、およびより長いコンテキスト情報の理解という点で、ChatGPT が継続的な最適化トレーニングにおいて大幅な進歩を遂げていることがわかります。
しかし、このインタラクティブな GPT モデルについては、むしろ、映画に登場する人工知能のような、自己認識と、自ら学習して進化する能力を備えたモデルであることを望んでいます。頻繁な指導や対話は必要なく、目標を提案するだけで、AIが実行計画や論理処理をすべて自律的に実行し、自己実証と最適化を継続して最終的に提案した目標を達成します。
そこで今日登場したのが、ChatGPT の進化版である AutoGPT です。
2. AutoGPT とは何ですか?
AutoGPT は、OpenAI の GPT-4 言語モデルを活用して、完全に自律的でカスタマイズ可能な AI エージェントを作成する実験的なオープン ソース アプリケーションです。トーラン・ブルース・リチャーズによって2023年3月30日にリリースされた。
ゲーム開発者のトランは、Significant Gravitas というゲーム会社を設立しました。
わずか 1 か月あまりで、AutoGPT の Git プロジェクトは 120 万以上のスターを獲得しました。完全に自律的に実行される GPT-4 の最初の例の 1 つとして、AutoGPT は AI の可能性の限界を突破しました。
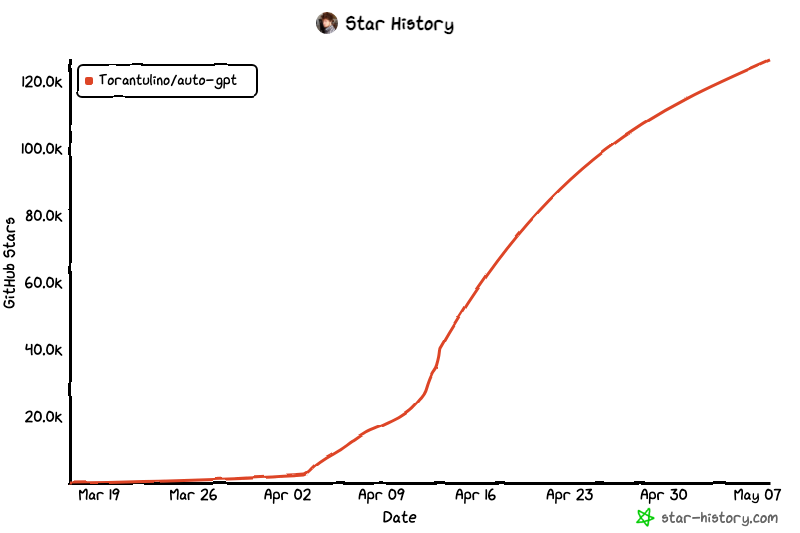
AutoGPT は、他の AI ツールと比較して、独立して実行されるという点で独特です。つまり、ニーズに合わせてモデルを操作する必要がなくなりました。代わりに、目標を書き留めるだけで、残りは AI が代わりにやってくれます。その結果、AutoGPT は AI と人間の対話方法を根本的に変え、人間が積極的な役割を果たす必要がなくなり、同時に ChatGPT などの他の AI アプリケーションと同等以上の結果の品質を維持します。
3. AutoGPT はどのように機能しますか?
AutoGPT は自律型 AI メカニズムに基づいて動作し、AI システムは次のような特定のタスクを満たすさまざまな AI エージェントを作成します。
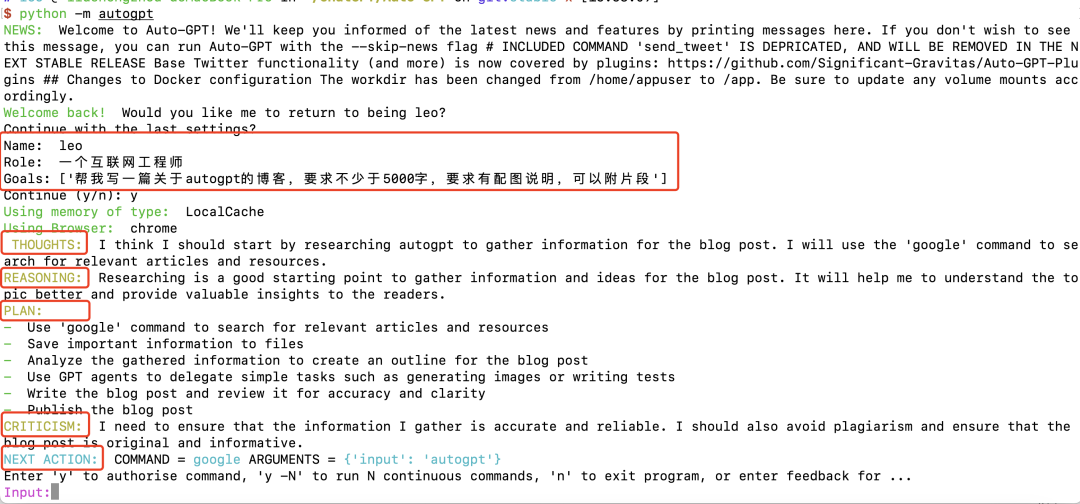
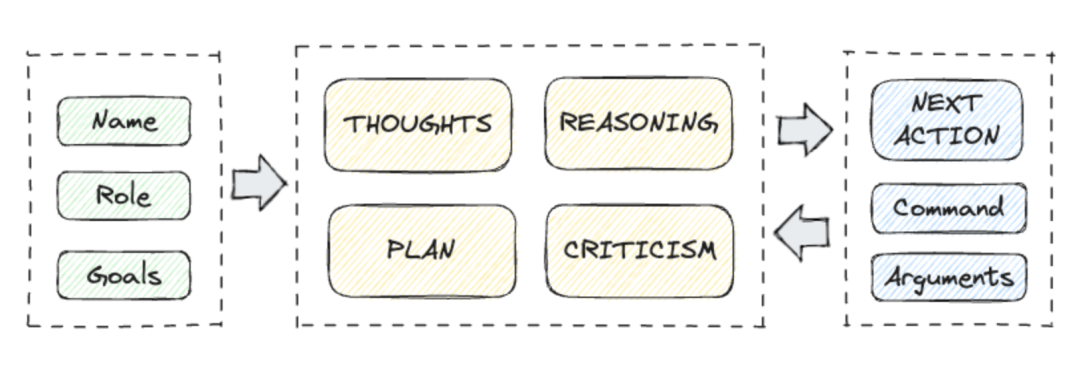
- タスク作成エージェント: ターゲットを入力したときAutoGPT では、タスク作成エージェントと対話する最初の AI エージェントです。あなたの目標に基づいて、タスクとそれを達成するためのステップのリストを作成し、優先エージェントに送信します。
- Task Priority Agent: タスクのリストを受信した後、Priority AI エージェントは、実行エージェントに送信する前に、順序が正しく論理的であることを確認します。
- タスク実行エージェント: 優先順位付けが完了すると、実行エージェントはタスクを 1 つずつ完了します。これには、GPT-4、インターネット、その他のリソースを活用して結果を取得することが含まれます。
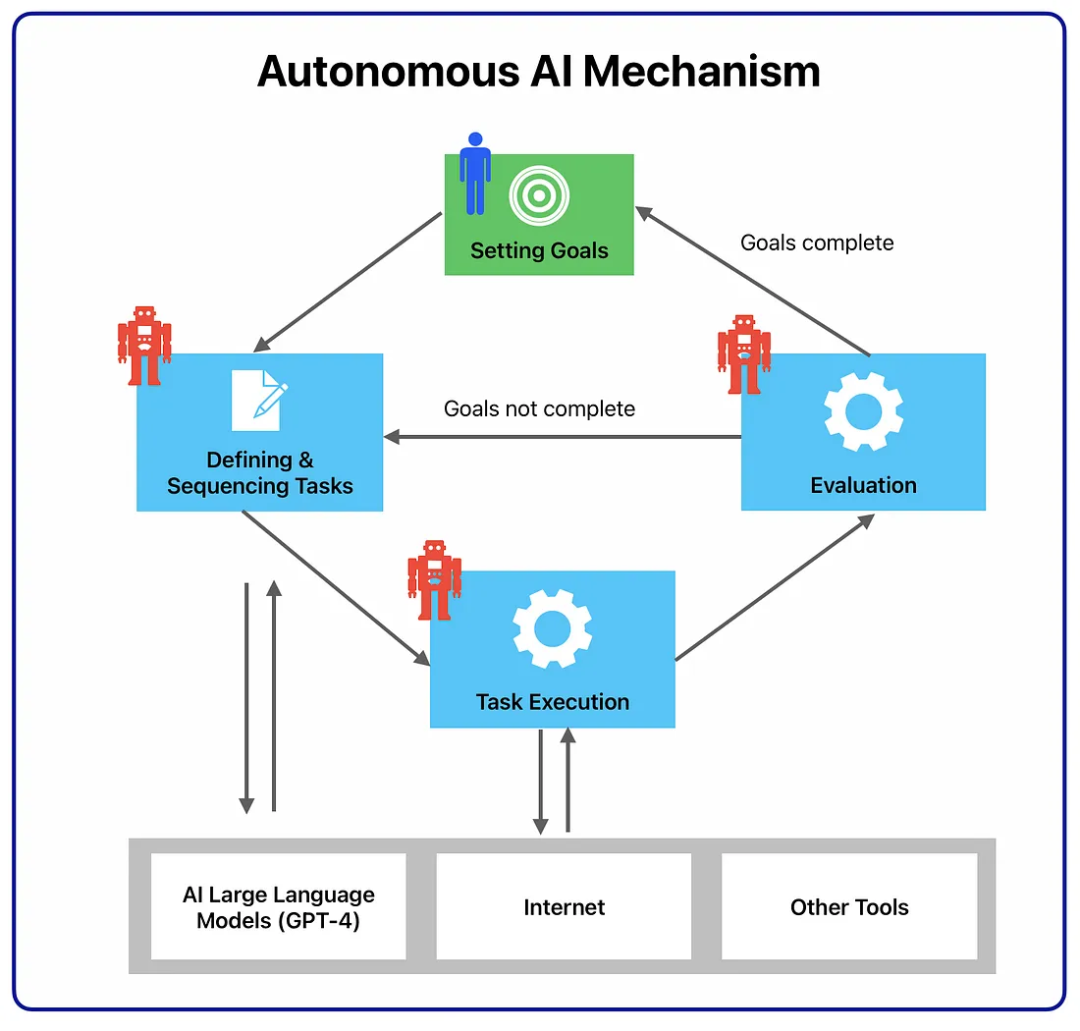
- 思考: AI エージェントはターゲットについての考えを共有します。
- REASONING: AI エージェントの推論がどのように開発され、そのアイデアが実現されるか。
- 計画 (PLAN): AI エージェントは分析を通じて、完了すべきタスクの計画を列挙します。
- 判断 (批判): AI が自ら判断し、エラーを修正し、制限的な問題を克服します。
4.1 リアルタイム インサイト
ChatGPT で使用される最新の GPT-4 モデルは、GPT-3.5 と同じデータでトレーニングされており、GPT-3.5 は 2021 年 9 月までのみ利用可能です。ChatGPT を使用してリアルタイムの分析情報を取得することはできません。時間データ情報。情報を取得したり抽出したりするために Web サイトやオンライン プラットフォームにアクセスできないためです。
対照的に、AutoGPT はインターネットにアクセスできます。インターネットをサーフィンできるだけでなく、ソースが正当なものかどうかを確認することもできます。さらに、AutoGPT は任意のプラットフォームにアクセスしてタスクを実行できます。たとえば、AI に製品の販売見込みを調査してアウトリーチ メールを送信するよう依頼すると、AI は Gmail アカウントを使用してメールの下書きを直接送信します。
4.2 メモリ管理
コンテキスト ウィンドウは、言語モデルが正確な答えを与えるために非常に重要です。ただし、GPT-4 のような LLM では、ウィンドウには 4000 ~ 8000 トークンの制限があります。したがって、要件が制限を超える場合、モデルはすべての指示に正しく従わない可能性があり、あるいは接線を逸脱して信頼性の低い出力を提供する可能性があります。
対照的に、AutoGPT は短期および長期のメモリ管理に優れています。メモリ管理にデータベース、ローカル キャッシュ、Redis を使用することで、大量のコンテキスト情報や以前の経験を保存でき、AI モデルがより適切な意思決定を行えるようになります。
4.3 イメージ生成
AutoGPT は、デフォルトで DALL-E を使用するさまざまなイメージ生成エンジンを使用できるため、イメージを生成できます。 AI エージェントの画像生成を有効にしたい場合は、DALL-E の API にアクセスする必要があります。マルチモーダル入力方法であるにもかかわらず、この機能は現在 ChatGPT-4 では利用できません。
3.4 テキスト読み上げ
コマンド ラインで python -m autogpt --speak と入力すると、AutoGPT でテキスト読み上げを有効にできます。ただし、AutoGPT を操作するたびにコマンドを入力する必要があります。 AutoGPT を多用途 AI 音声ソフトウェア イレブン ラボに接続することで、音声にさまざまなサウンドを追加することもできます。
5. AutoGPT の制限
自律性が AI システムに新たな次元を追加することは疑いの余地がありません。同時に、AutoGPT の制限とリスクを無視することはできません。以下に、注意しなければならない重要な制限をいくつか示します。
5.1 高コスト
AutoGPT の機能は素晴らしいですが、その実用性にはがっかりするかもしれません。 AutoGPT は高価な GPT-4 モデルを使用しているため、たとえ小さなタスクであっても、各タスクを完了するコストが高くなる可能性があります。これは主に、AutoGPT が特定のタスクのステップ中に GPT-4 を複数回使用することが原因です。
5.2 頻繁にループに陥る
AutoGPT を使用するときにユーザーが直面する最も一般的な問題は、ループに陥ることです。これが数分以上続く場合は、プロセスを再起動する必要がある可能性があります。これは、AutoGPT がタスクを正しく定義および分解するために GPT-4 に依存しているために発生します。したがって、基盤となる LLM が AutoGPT がアクションを実行するには不十分な結果を返した場合、試行錯誤の問題が発生します。
5.3 データ セキュリティ
AutoGPT は完全に承認されているため、twitter アカウントの使用、github へのログイン、検索エンジンの使用など、自律的に実行してシステムやインターネットにアクセスできます。 . なので、データが漏洩する可能性があります。 AutoGPT にはセキュリティ エージェントがないため、AutoGPT を使用する場合は注意が必要です。正しい指示とセキュリティ ガイドラインを提供せずにモデルの実行を継続させることはできません。
5. AutoGPT をインストールするにはどうすればよいですか?
他の AI ツールとは異なり、AutoGPT にはプラットフォームや機能にアクセスするための単純な登録プロセスがありません。 AutoGPT の使用を開始する前に、要件を満たすさまざまなソフトウェアをダウンロードする必要があります。ステップの詳細な要件は次のとおりです:
ステップ 1: 必要なソフトウェアをダウンロードします
まず、Git アカウントが必要で、Python3.1.0 以降をインストールする必要があります。また、一般的なシェル コマンドを巧みに使用できること、またはプロジェクトの起動と構成に Docker コンテナを使用できることも必要です。
ステップ 2: OpenAI API キーを設定する
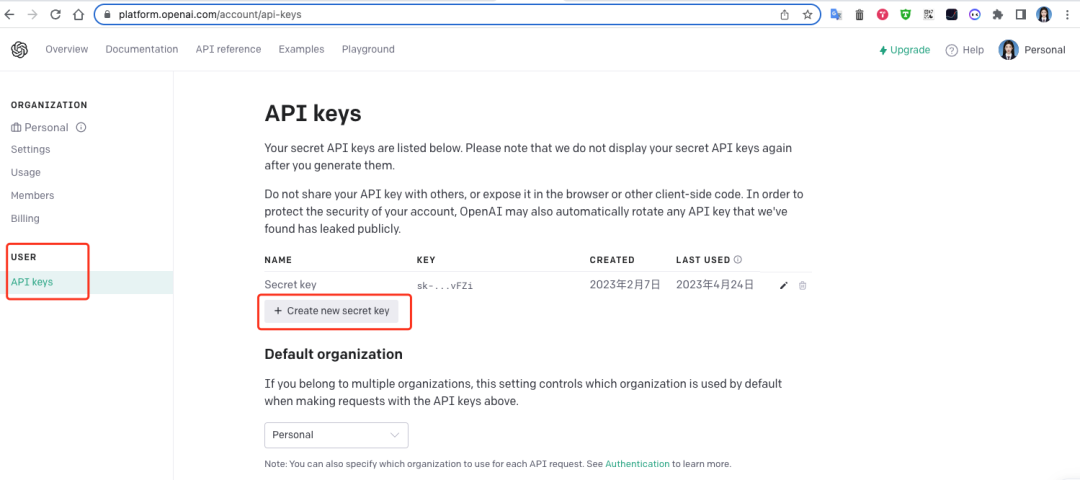
まだ持っていない場合は、OpenAI アカウントを作成してください (もちろん、中国でアカウントを作成したい場合は、簡単なことではありません。インターネット上の他の記事を参照してアカウントを申請してください)。 OpenAI アカウントを開いたら、「USER - API キー」を開き、「API キー」タブに移動します。キーを作成するオプションが表示されます。それをクリックしてキーをコピーします。
ステップ 3: 最新バージョンの AutoGPT のクローンを作成します
(1)クローン プロジェクト
コマンドを開きます行ツールは、コマンド git clone https://github.com/Torantulino/Auto-GPT.git を使用して、プロジェクトをローカルにクローンします。

(2) インストールを実行します。
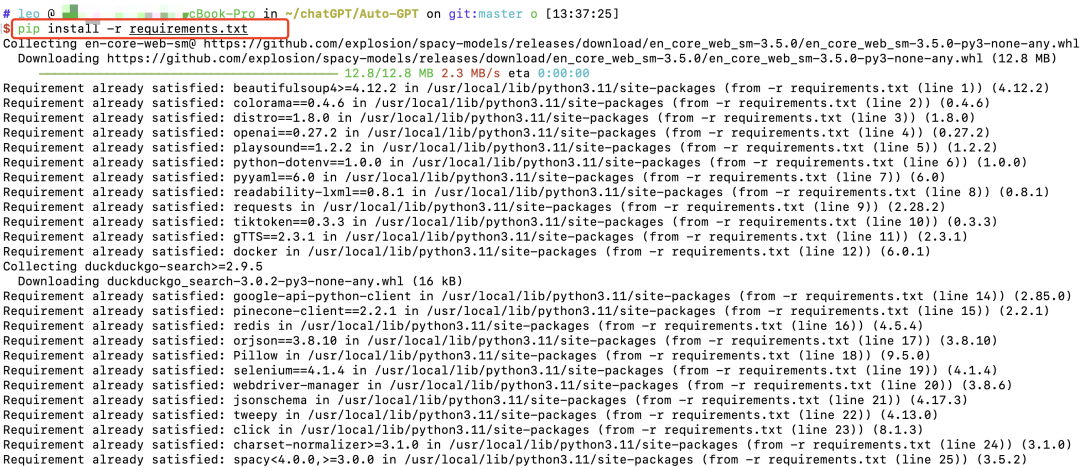
コマンド cd Auto-GPT && ls -al を使用してディレクトリに入ると、多数のファイルがあることがわかります。そのうちの 1 つはrequirements.txtです。このファイルには、AutoGPT を実行するために必要なモジュールが含まれています。
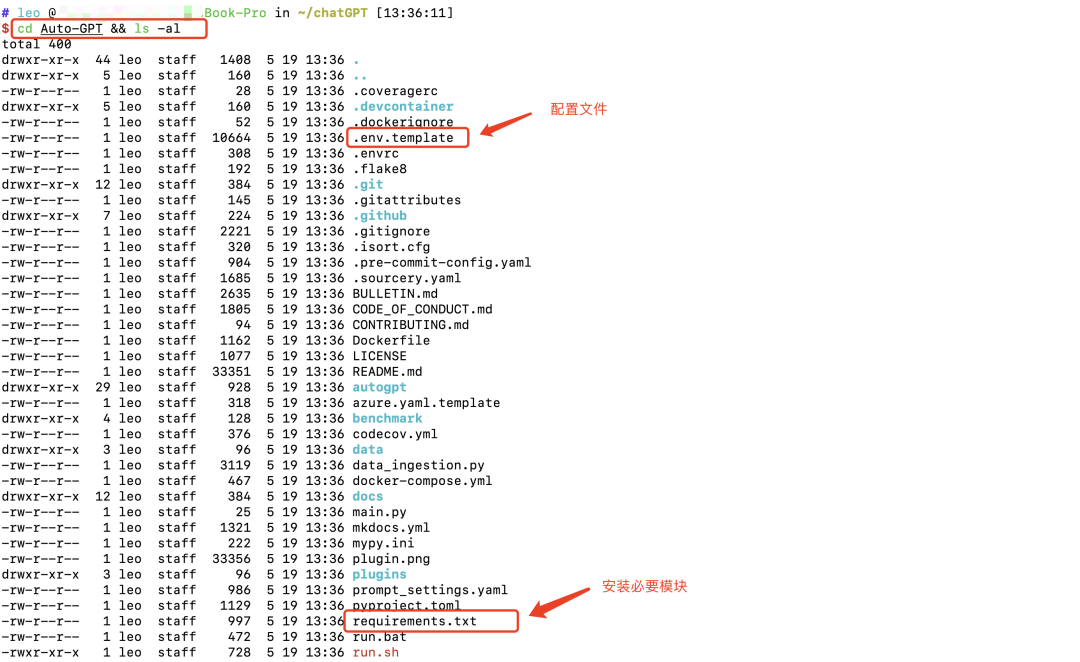
これらのモジュールをインストールするには、コマンド pip install -rrequirements.txt を使用してダウンロードしてインストールします。
(3) 設定を変更します
コマンド vim .env.template your-openai-api-key) を渡します。設定が完了したら、 mv .env.template .env を実行して設定を有効にします。
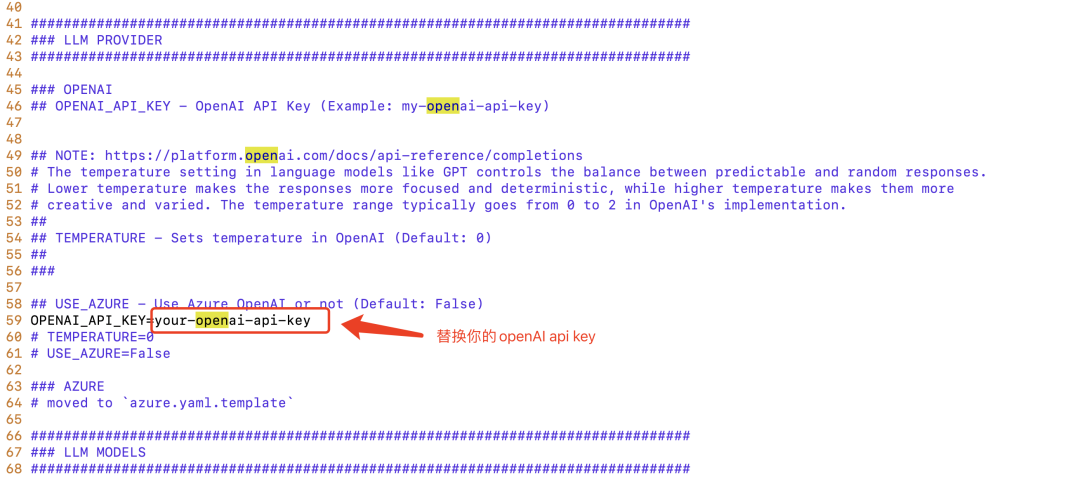
その他の関連設定は、必要に応じて参照して行うことができます。
| OPENAI_API_KEY をテーブルに設定できます、AZURE を使用するかどうか |
|
| 過剰なトークンを避けるために、openAI によって提供されるトークン制限を構成できます。通話コストの無駄。デフォルトは 4000-8000 | |
| LLM の基礎となる言語モデルを選択できます。デフォルトでは GPT-4 または gpt-3.5-turbo |
|
| メモリ管理。ローカルで構成できます。 redis、PINECONE、MILVUS など。 | |
| 画像生成、画像サイズを構成できます画像生成エンジン: dalle、HUGGGINGFACE、安定した拡散 WEBUI | |
| 音声からテキストへ、 HUGGGINGFACE | を設定できます|
| ##リポジトリ アクション用の GIT プロバイダー | github 構成。github API キーを構成することで Github にアクセスして管理するために使用されます |
| 検索エンジン管理。Firefox、Chrome、Safari、検索エンジン: Google など、さまざまなブラウザを設定できます。認可されたオープン API は、インターネットにアクセスして情報を取得し、アクセスの深さを管理するために使用されます | |
| 音声合成設定には MAC OS、STREAMELEMENTS、ELEVENLABS を使用します | |
| Twitter アカウント管理、 Twitter アカウントを管理および構成し、対応する API にアクセスするためのトークンを構成します | |
| AutoGPT のデフォルト構成の一部 (ストレージ ディレクトリ、スイッチ、ユーザー エージェント、AI 設定など)。 |
以上が自己認識 AI: AutoGPTの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7926
7926
 15
1652
14
1411
52
1303
25
1249
29
15
1652
14
1411
52
1303
25
1249
29

 世界のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの最新バージョンです
Apr 28, 2025 pm 08:09 PM
世界のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの最新バージョンです
Apr 28, 2025 pm 08:09 PM
世界の上位10の暗号通貨取引プラットフォームには、Binance、Okx、Gate.io、Coinbase、Kraken、Huobi Global、Bitfinex、Bittrex、Kucoin、Poloniexが含まれます。これらはすべて、さまざまな取引方法と強力なセキュリティ対策を提供します。
 復号化GATE.IO戦略のアップグレード:Memebox 2.0でCrypto Asset Managementを再定義する方法は?
Apr 28, 2025 pm 03:33 PM
復号化GATE.IO戦略のアップグレード:Memebox 2.0でCrypto Asset Managementを再定義する方法は?
Apr 28, 2025 pm 03:33 PM
Memebox 2.0は、革新的なアーキテクチャとパフォーマンスのブレークスルーを通じて、暗号資産管理を再定義します。 1)3つの主要な問題点を解決します。資産サイロ、収入の減少、セキュリティと利便性のパラドックスです。 2)インテリジェントアセットハブ、動的リスク管理およびリターンエンハンスメントエンジン、クロスチェーン移動速度、平均降伏率、およびセキュリティインシデント応答速度が向上します。 3)ユーザーに、ユーザー価値の再構築を実現し、資産の視覚化、ポリシーの自動化、ガバナンス統合を提供します。 4)生態学的なコラボレーションとコンプライアンスの革新により、プラットフォームの全体的な有効性が向上しました。 5)将来的には、スマート契約保険プール、予測市場統合、AI主導の資産配分が開始され、引き続き業界の発展をリードします。
 トップ通貨取引プラットフォームは何ですか?トップ10の最新の仮想通貨交換
Apr 28, 2025 pm 08:06 PM
トップ通貨取引プラットフォームは何ですか?トップ10の最新の仮想通貨交換
Apr 28, 2025 pm 08:06 PM
現在、上位10の仮想通貨交換にランクされています。1。Binance、2。Okx、3。Gate.io、4。CoinLibrary、5。Siren、6。HuobiGlobal Station、7。Bybit、8。Kucoin、9。Bitcoin、10。BitStamp。
 推奨される信頼できるデジタル通貨取引プラットフォーム。世界のトップ10のデジタル通貨交換。 2025
Apr 28, 2025 pm 04:30 PM
推奨される信頼できるデジタル通貨取引プラットフォーム。世界のトップ10のデジタル通貨交換。 2025
Apr 28, 2025 pm 04:30 PM
推奨される信頼できるデジタル通貨取引プラットフォーム:1。OKX、2。Binance、3。Coinbase、4。Kraken、5。Huobi、6。Kucoin、7。Bitfinex、8。Gemini、9。Bitstamp、10。Poloniex、これらのプラットフォームは、セキュリティ、ユーザーエクスペリエンス、ユーザーエクスペリエンス、ユーザーエクスペリエンス、ユーザーエクスペリエンスのデジタルエクスペリエンス、デジタルエクスペリエンスのデジタルエクスペリエンス、デジタルエクスペリエンスのために知られています。
 CでChronoライブラリを使用する方法は?
Apr 28, 2025 pm 10:18 PM
CでChronoライブラリを使用する方法は?
Apr 28, 2025 pm 10:18 PM
CでChronoライブラリを使用すると、時間と時間の間隔をより正確に制御できます。このライブラリの魅力を探りましょう。 CのChronoライブラリは、時間と時間の間隔に対処するための最新の方法を提供する標準ライブラリの一部です。 Time.HとCtimeに苦しんでいるプログラマーにとって、Chronoは間違いなく恩恵です。コードの読みやすさと保守性を向上させるだけでなく、より高い精度と柔軟性も提供します。基本から始めましょう。 Chronoライブラリには、主に次の重要なコンポーネントが含まれています。STD:: Chrono :: System_Clock:現在の時間を取得するために使用されるシステムクロックを表します。 STD :: Chron
 ビットコインの価値はいくらですか
Apr 28, 2025 pm 07:42 PM
ビットコインの価値はいくらですか
Apr 28, 2025 pm 07:42 PM
ビットコインの価格は20,000ドルから30,000ドルの範囲です。 1。ビットコインの価格は2009年以来劇的に変動し、2017年には20,000ドル近くに達し、2021年にはほぼ60,000ドルに達しました。2。価格は、市場需要、供給、マクロ経済環境などの要因の影響を受けます。 3.取引所、モバイルアプリ、ウェブサイトを通じてリアルタイム価格を取得します。 4。ビットコインの価格は非常に不安定であり、市場の感情と外部要因によって駆動されます。 5.従来の金融市場と特定の関係を持ち、世界の株式市場、米ドルの強さなどの影響を受けています。6。長期的な傾向は強気ですが、リスクを慎重に評価する必要があります。
 トップ10の仮想通貨取引アプリは何ですか?最新のデジタル通貨交換ランキング
Apr 28, 2025 pm 08:03 PM
トップ10の仮想通貨取引アプリは何ですか?最新のデジタル通貨交換ランキング
Apr 28, 2025 pm 08:03 PM
Binance、OKX、Gate.ioなどの上位10のデジタル通貨交換は、システムを改善し、効率的な多様化したトランザクション、厳格なセキュリティ対策を改善しました。
 Cのスレッドパフォーマンスを測定する方法は?
Apr 28, 2025 pm 10:21 PM
Cのスレッドパフォーマンスを測定する方法は?
Apr 28, 2025 pm 10:21 PM
Cのスレッドパフォーマンスの測定は、標準ライブラリのタイミングツール、パフォーマンス分析ツール、およびカスタムタイマーを使用できます。 1.ライブラリを使用して、実行時間を測定します。 2。パフォーマンス分析にはGPROFを使用します。手順には、コンピレーション中に-pgオプションを追加し、プログラムを実行してGmon.outファイルを生成し、パフォーマンスレポートの生成が含まれます。 3. ValgrindのCallGrindモジュールを使用して、より詳細な分析を実行します。手順には、プログラムを実行してCallGrind.outファイルを生成し、Kcachegrindを使用して結果を表示することが含まれます。 4.カスタムタイマーは、特定のコードセグメントの実行時間を柔軟に測定できます。これらの方法は、スレッドのパフォーマンスを完全に理解し、コードを最適化するのに役立ちます。
