

OpenAI は GPT-4 を使用して GPT-2 の 300,000 ニューロンを説明します: これが知恵の姿です

ChatGPT は人間を知能の再現に近づけるようですが、これまでのところ、自然か人工かにかかわらず、知能とは何かを完全には理解していません。
インテリジェンスの原理を理解することが明らかに必要ですが、大規模な言語モデルのインテリジェンスを理解するにはどうすればよいでしょうか? OpenAI が提供する解決策は、GPT-4 が何を言っているかを尋ねることです。
5 月 9 日、OpenAI は最新の研究を発表しました。この研究では、GPT-4 を使用して大規模な言語モデルにおけるニューロンの動作を自動的に解釈し、多くの興味深い結果を得ました。
解釈可能性を研究する簡単な方法は、まず AI モデルのさまざまなコンポーネント (ニューロンと注意) を理解することです。頭) )何をしているのですか。従来の方法では、ニューロンがデータのどの特徴を表しているかを判断するために、人間が手動でニューロンを検査する必要があります。このプロセスは拡張するのが難しく、数千億または数千億のパラメータを持つニューラル ネットワークに適用すると、法外な費用がかかります。
そこで OpenAI は自動化手法を提案しました - GPT-4 を使用してニューロンの動作の自然言語説明を生成してスコア付けし、それをモデル内の別の言語ニューロンに適用します - ここで彼らは GPT-2 を選択しましたを実験サンプルとして使用し、これらの GPT-2 ニューロンの解釈とスコアのデータセットを公開しました。

- #紙のアドレス: https://openaipublic.blob.core.windows.net/ neuron-explainer/paper/index.html
- GPT-2 ニューロン図: https://openaipublic.blob.core.windows.net/neuron-explainer /neuron-viewer/index.html
- コードとデータセット: https://github.com/openai/automated-interpretability
OpenAI は、自社が確立したベンチマークを使用して AI を説明すると、人間のレベルに近いスコアを達成できると述べています。
具体的な方法
AI を使用して AI を説明する方法には、各ニューロンで 3 つのステップを実行する必要があります:
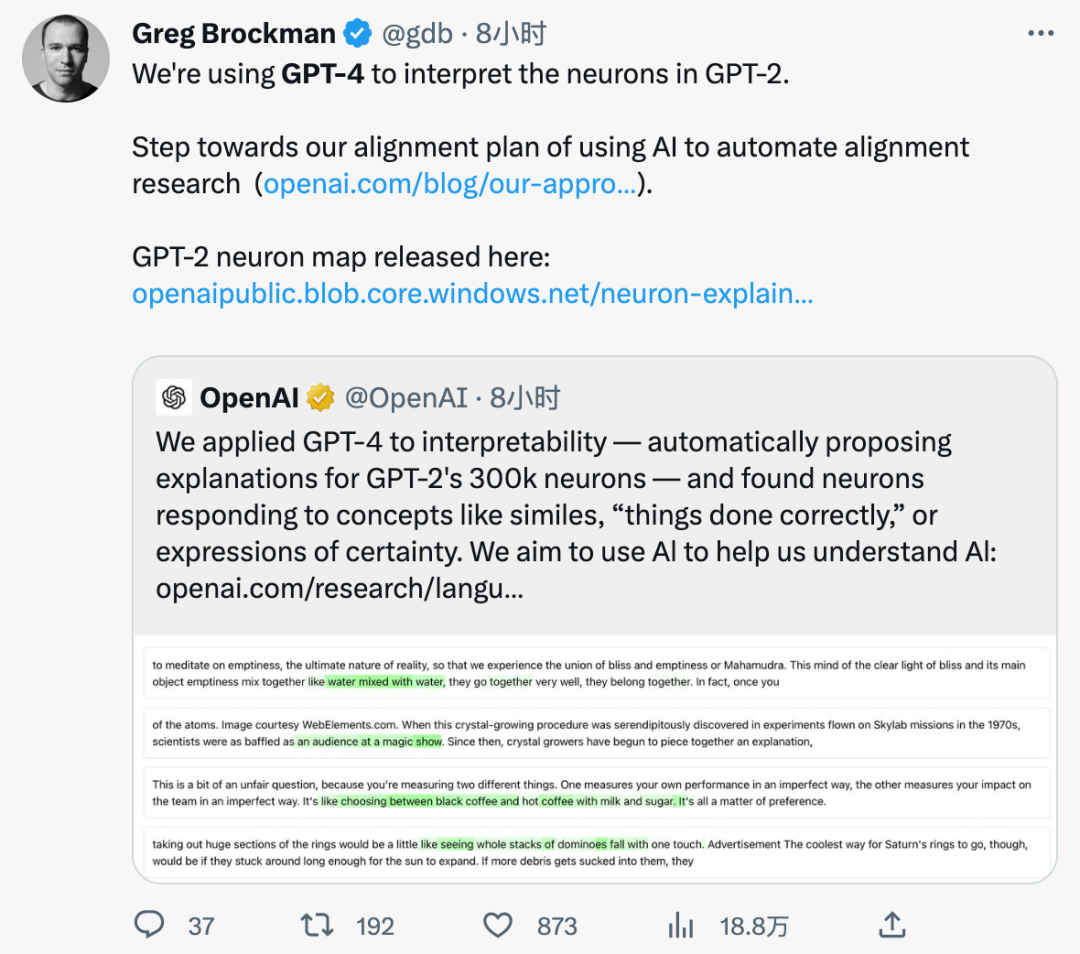
ステップ 1: GPT-4 を使用して説明を生成する
 ##GPT-2 ニューロンを与えて、GPT を表示する-4 つの関連するテキスト シーケンスとアクティベーションにより、その動作の説明が生成されます。
##GPT-2 ニューロンを与えて、GPT を表示する-4 つの関連するテキスト シーケンスとアクティベーションにより、その動作の説明が生成されます。
モデル生成の説明: 映画、キャラクター、エンターテイメントへの参照。
ステップ 2: GPT-4 を使用してシミュレートします。
GPT-4 を再度使用して、解釈されたニューラルをシミュレートします。袁はそうするだろうか。
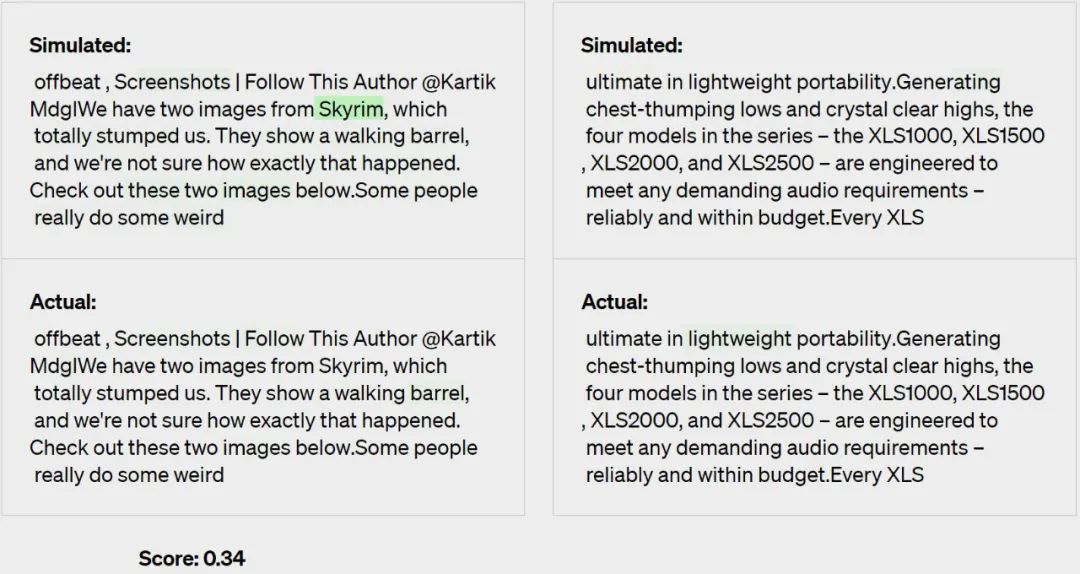
#ステップ 3: 比較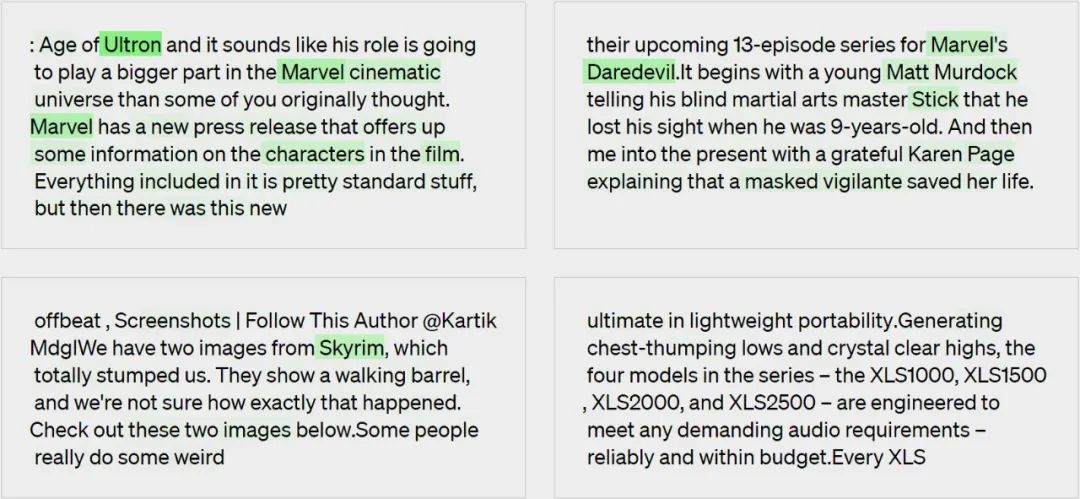
説明は、シミュレートされたアクティベーションが実際のアクティベーションとどの程度一致するかに基づいてスコア付けされます。この場合、GPT-4 のスコアは 0.34 でした。

- 反復的な説明。 GPT-4 に考えられる反例を考えさせ、その反例の発動に基づいて説明を修正することで、スコアを向上させることができました。
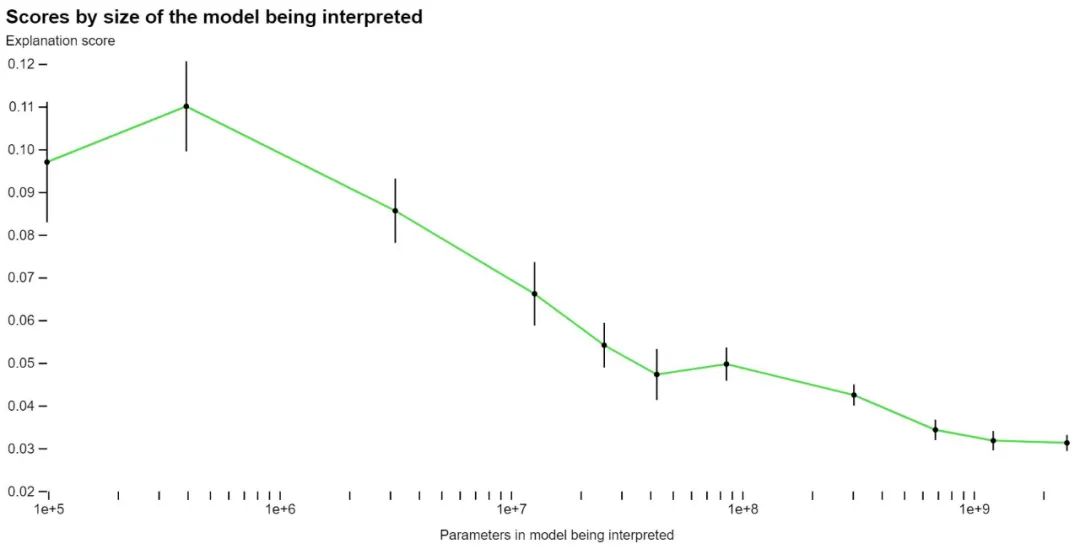
- 説明には大きなモデルを使用します。説明者モデルの能力が向上すると、平均スコアも向上します。しかし、GPT-4でさえ人間よりも悪い説明をしており、改善の余地があることを示唆しています。
- 説明されたモデルの構造を変更します。さまざまな活性化関数を使用してモデルをトレーニングすると、説明スコアが向上します。
研究者らは、1,000 個を超えるニューロンの説明スコアが少なくとも 0.8 であることを発見しました。これは、GPT-4 によるニューロンの最上位の活性化動作のほとんどをそれらのニューロンが占めていることを意味します。これらの十分に説明されたニューロンのほとんどは、あまり興味深いものではありません。しかし、GPT-4 が理解できない興味深いニューロンも多数発見されました。 OpenAI は、説明が改善されるにつれて、モデルの計算に関する興味深い定性的な洞察がすぐに明らかになるかもしれないと期待しています。
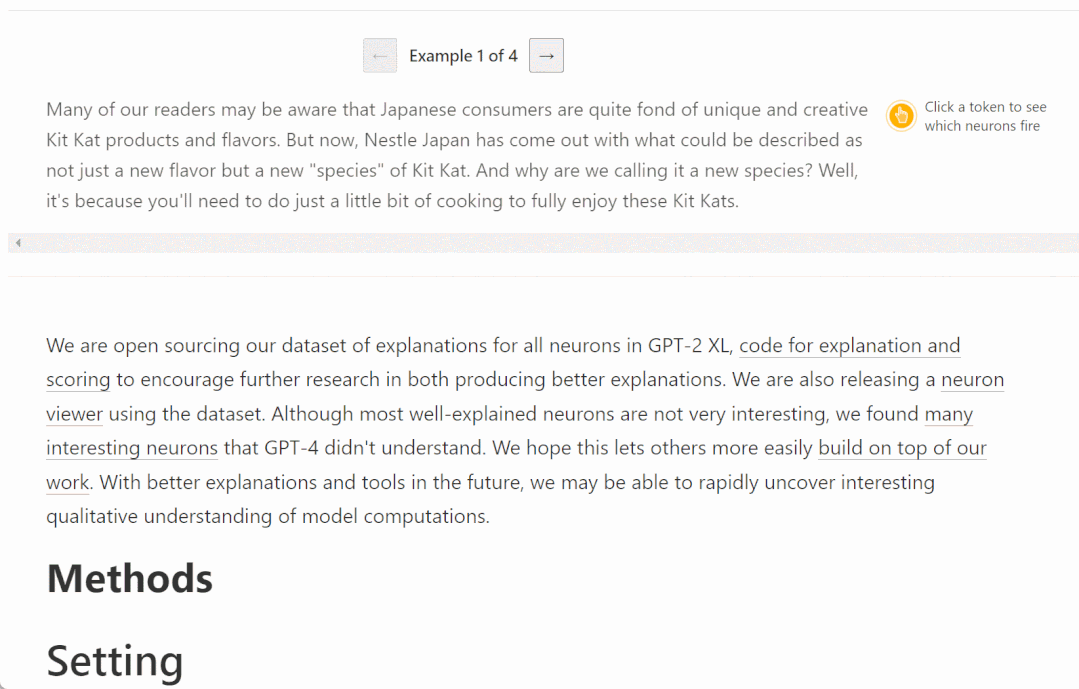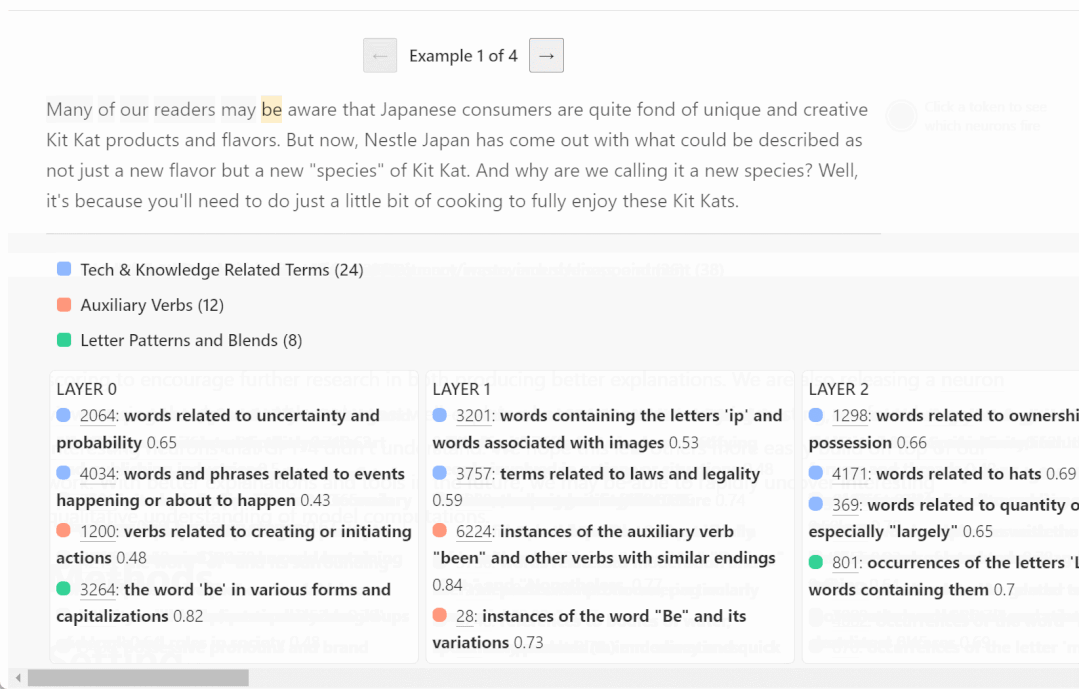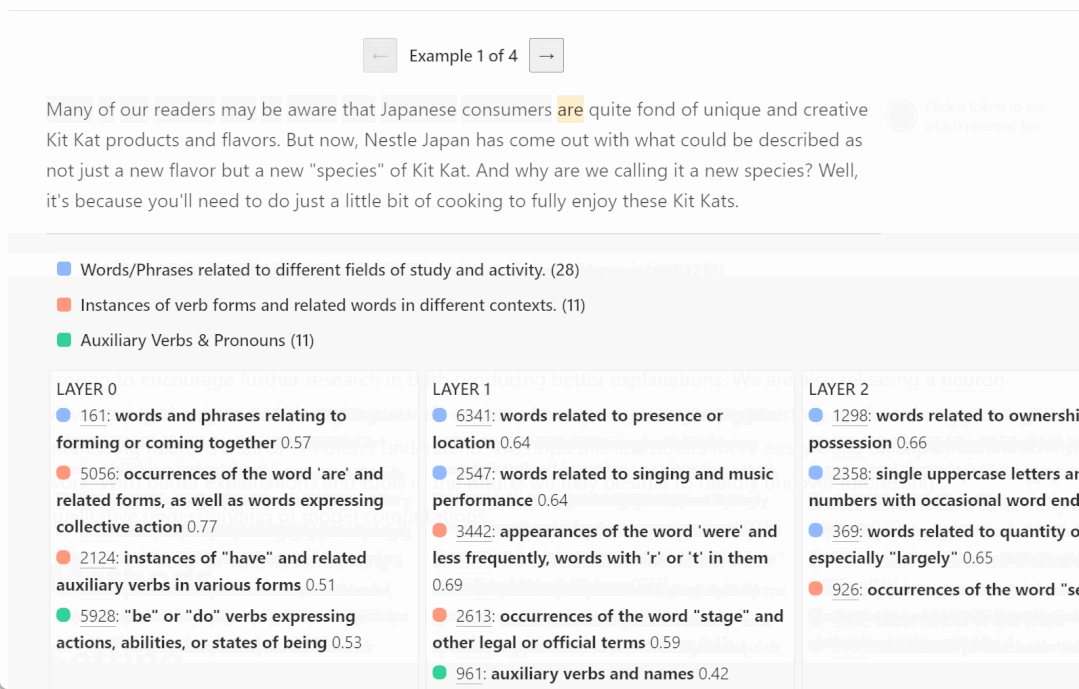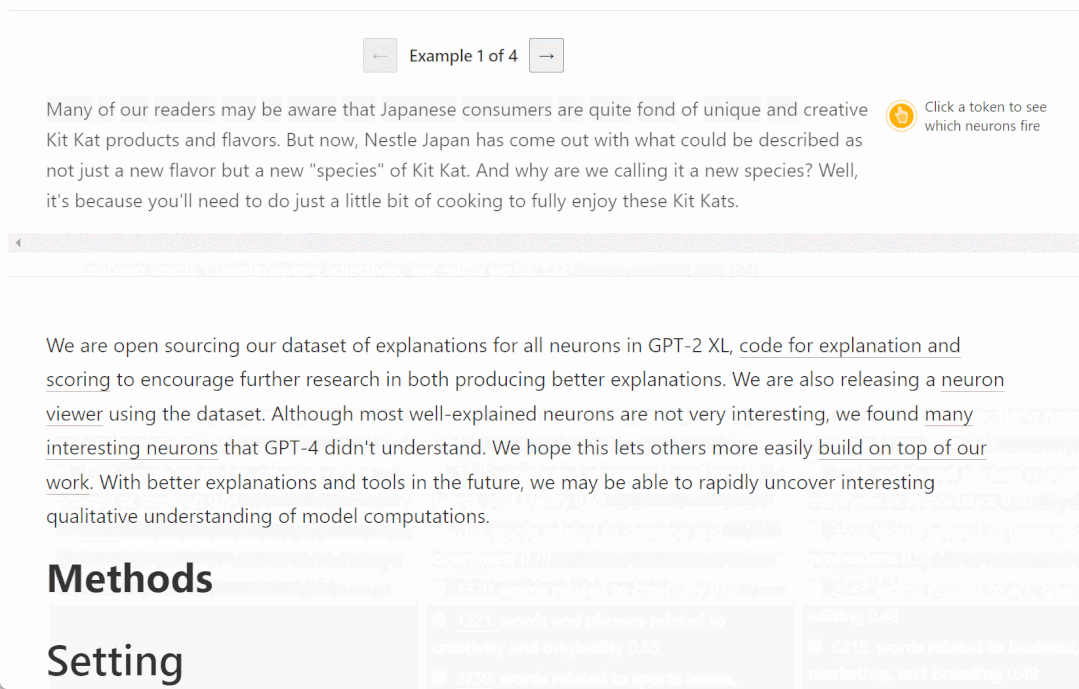
#ここでは、さまざまな層で活性化されるニューロンの例をいくつか示します。上位層ほど抽象的になります。



 # # GPT が理解している概念が人間とは違うようですが?
# # GPT が理解している概念が人間とは違うようですが?
OpenAI の今後の取り組み
現時点では、この方法にはまだいくつかの制限があり、OpenAI は将来の取り組みでこれらの問題を解決したいと考えています:- この方法は短い自然言語の説明に焦点を当てていますが、ニューロンは簡潔に説明できない非常に複雑な動作をする可能性があります;
- OpenAI 最終的には自動的に実行されることが期待されています。神経回路全体を見つけて解釈し、ニューロンとアテンションヘッドが連携して複雑な動作を実現します。現在の方法は、下流の影響を考慮せずに、生のテキスト入力の関数としてニューロンの動作を単に解釈します。たとえば、ピリオドで起動するニューロンは、次の単語が大文字で始まるか、文カウンターをインクリメントする必要があることを示すことができます。
- #OpenAI は、このニューロンの動作を説明します。この動作を生み出すメカニズムを説明しようとしています。これは、スコアの高い説明であっても、単に相関関係を説明しているだけであるため、配布されていないテキストではパフォーマンスが低下する可能性があることを意味します;
- プロセス全体で大量の計算能力を消費します。
最終的に、OpenAI は、説明可能性の研究者が行うのと同じように、モデルを使用して完全に一般的な仮説を形成、テスト、反復することを望んでいます。さらに、OpenAI は、その最大のモデルを、展開の前後に調整とセキュリティの問題を検出する方法として解釈したいと考えています。しかし、それが起こるまでにはまだ長い道のりがあります。
以上がOpenAI は GPT-4 を使用して GPT-2 の 300,000 ニューロンを説明します: これが知恵の姿ですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7555
7555
 15
1384
52
83
11
28
96
15
1384
52
83
11
28
96

 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
SSHサービスを再起動するコマンドは次のとおりです。SystemCTL再起動SSHD。詳細な手順:1。端子にアクセスし、サーバーに接続します。 2。コマンドを入力します:SystemCtl RestArt SSHD; 3.サービスステータスの確認:SystemCTLステータスSSHD。
 CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
Pytorchの分散トレーニングでは、Centosシステムでトレーニングには次の手順が必要です。Pytorchのインストール:PythonとPipがCentosシステムにインストールされていることです。 CUDAバージョンに応じて、Pytorchの公式Webサイトから適切なインストールコマンドを入手してください。 CPUのみのトレーニングには、次のコマンドを使用できます。PipinstalltorchtorchtorchvisionTorchaudioGPUサポートが必要な場合は、CUDAとCUDNNの対応するバージョンがインストールされ、インストールに対応するPytorchバージョンを使用してください。分散環境構成:分散トレーニングには、通常、複数のマシンまたは単一マシンの複数GPUが必要です。場所
