

CVPR 2023 論文概要! CV の最もホットな分野はマルチモーダル モデルと拡散モデルに与えられます

年次CVPRは、6月18日から22日までカナダのバンクーバーで正式に開幕します。
毎年、世界中から数千人の CV 研究者やエンジニアがサミットに集まります。この権威あるカンファレンスは 1983 年に遡り、コンピューター ビジョン開発の頂点を表します。
現在、CVPR の h5 インデックスは、すべての会議や出版物の中で、Nature、Science、New England Journal of Medicine に次いで 4 位にランクされています。

#少し前に、CVPR が論文の受理結果を発表しました。公式ウェブサイトの統計によると、論文総数は9,155件、採択数は2,359件、採択率は25.8%でした。
また、受賞候補論文12本が発表されました。

それでは、今年の CVPR のハイライトは何でしょうか?受理された論文から履歴書分野ではどのような傾向が見えますか?
は次回発表します。
CVPR の概要スタートアップ Voxel51 は、受理されたすべての論文のリストを分析しました。
まず、論文のタイトルの概要図を見てみましょう。各単語のサイズは、データ セット内の出現頻度に比例します。

簡単な説明
#- 2359 件の論文受理されました(9155 件の論文が提出されました)#- 1724 件の Arxiv 論文
#- 68 件の論文が他のアドレスに送信されました
論文あたりの著者数
-CVPR論文の平均的な著者は約5.4人です
-最も多くの著者がいる論文は、「なぜ勝者が最も優れているのか?」です。著者は 125 人です。
- 著者が 1 人だけの論文が 13 件あります。
Arxiv の主な分類
1,724 件の Arxiv 論文のうち、1,545 件、または 90% 近くが含まれます。 cs.CV をメイン カテゴリとしてリストします。
cs.LG は 101 件の記事で 2 位にランクされました。 eess.IV (26) と cs.RO (16) もパイの分け前を獲得します。
CVPR 論文のその他のカテゴリには、cs.HC、cs.CV、cs.AR、cs.DC、cs.NE、cs.SD、cs.CL、cs.IT が含まれます。 、cs.CR、cs.AI、cs.MM、cs.GR、eess.SP、eess.AS、math.OC、math.NT、physics.data-an、および stat.ML。
「メタ」データ
- 「データセット」と「モデル」という 2 つの単語が、Among 567 で一緒に表示されます。要約。 「データセット」は 265 件の論文抄録に単独で出現し、「モデル」は単独で 613 回出現します。 CVPR に受理された論文のうち、これら 2 つの単語が含まれていない論文はわずか 16.2% でした。
#- CVPR 論文の要約によると、今年最も人気のあるデータセットは ImageNet (105)、COCO (94)、KITTI (55)、CIFAR (36) です。
#- 28 の論文が新しい「ベンチマーク」を提案します。
頭字語はたくさんあります
頭字語のない機械学習プロジェクトは存在しないように思えます。 2,359本の論文のうち、タイトルに複数の略語や複合語を大文字で含む論文は1,487本で63%を占めた。
これらの頭字語の中には、覚えやすく、思わず口から出てしまうものもあります:
##- CLAMP: 言語と動物のポーズを結び付けるためのプロンプトベースの対照学習CLAMP
#- PATS: ローカル フィーチャ マッチングのためのサブディビジョンによるパッチ エリアのトランスポート##- CIRCLE: リッチ コンテキスト環境でのキャプチャ
##もっと複雑なものもあります:
- SIEDOB: オブジェクトと背景のもつれを解くことによるセマンティック画像編集
- FJMP : 因数分解されたジョイント マルチ-学習された有向非巡回インタラクション グラフに対するエージェント動作予測FJMP
そのうちのいくつかは、頭字語の構築に関して他の人からアイデアを借用しているようです:
- SCOTCH とSODA: Transformer Video Shadow Detection Framework (オランダの人気ブランド Scotch & Soda)
- EXCALIBUR: 身体的探索の奨励と評価 (例: カレースティック、笑)
一番ホットなものは何ですか?
2023 年の論文タイトルに加えて、2022 年に承認されたすべての論文タイトルをクロールしました。これら 2 つのリストから、上昇トレンドと下降トレンドについてより深く理解できるように、さまざまなキーワードの相対頻度を計算しました。#モデル
2023 年には、ディフュージョン モデルが主流になります。
#拡散モデル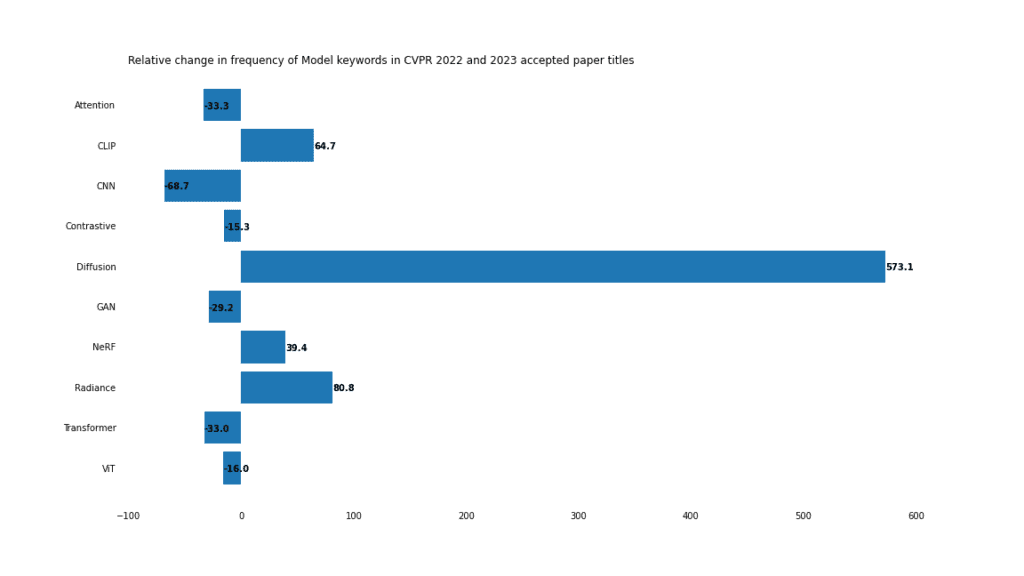
安定性あり ありDiffusion や Midjourney などの画像生成モデルの人気を考えると、拡散モデルの開発が熱いトレンドであることは驚くべきことではありません。
拡散モデルは、ノイズ除去、画像編集、スタイル転送にも応用できます。すべてを合計すると、前年比 573% 増で、すべてのカテゴリで断トツの最大の勝者となっています。
放射線場
神経放射線場 (NERF) もますます人気が高まっており、「」という言葉も使われるようになりました。 「ラディアンス」は80%増加、「NERF」は39%増加しました。 NeRF は概念実証から編集、アプリケーション、トレーニング プロセスの最適化に移行しました。
Transformers
「Transformer」と「ViT」の使用が減少しているからといって、Transformer モデルが廃止されるというわけではありません。むしろ、2022 年におけるこれらのモデルの優位性を反映しています。 2021年に「トランスフォーマー」という言葉が登場したのはわずか37紙だった。 2022 年には、この数は 201 人にまで増加します。トランスフォーマーがすぐになくなるわけではありません。
CNN
CNN はかつてはコンピューター ビジョンの最愛の人でしたが、2023 年にはその地位を失ったようです。使用量は 68% 減少しました。 CNN について言及している見出しの多くは、他のモデルについても言及しています。たとえば、次の論文では CNN とトランスフォーマーについて言及しています:
- Lite-Mono: A Lightweight CNN and Transformer Architecture for Self-Supervised Monocular Depth EstimationLite-Mono- 混合トランスフォーマーと CNN アーキテクチャを使用した学習済み画像圧縮
タスク
マスク タスクとマスク イメージ モデリングの組み合わせ、 CVPRにおいて支配的な地位を占めています。 ##############################生成する#########
検出、分類、セグメンテーションなどの従来の識別タスクは人気が衰えたわけではありませんが、「編集」、「合成」、「世代」の台頭がこれを証明しています。
マスク
キーワード「マスク」は前年同期比 263% 増加し、採用されましたin 2023 は論文に 92 回登場し、タイトルに 2 回登場することもあります。
#- SIM: ボックス監視インスタンス セグメンテーション用のセマンティック認識インスタンス マスク生成SIM
- DynaMask: インスタンス セグメンテーション用の動的マスク選択DynaMask
しかし、実際には大多数 (64%) が「マスキング」タスクに言及しており、その中には 8 件の「マスク イメージ モデリング」タスクと 15 件の「マスク オートエンコーダー」タスクが含まれています。また、「マスク」は8記事に登場しました。
また、「マスク」という単語が含まれる 3 つの論文のタイトルが、実際には「マスクなし」タスクを指していることにも注目してください。
ゼロサンプルと小規模サンプル
転移学習、生成手法、ヒント、および一般的なモデルの台頭により、 「ゼロショット」学習が注目を集めています。同時に、「少数のサンプル」学習は昨年より減少しました。ただし、生の数値に関しては、少なくとも現時点では、「小規模サンプル」(45) が「ゼロ サンプル」(35) よりわずかに有利です。
モダリティ
2023 年には、マルチモーダルおよびクロスモーダル アプリケーションの開発が加速します。
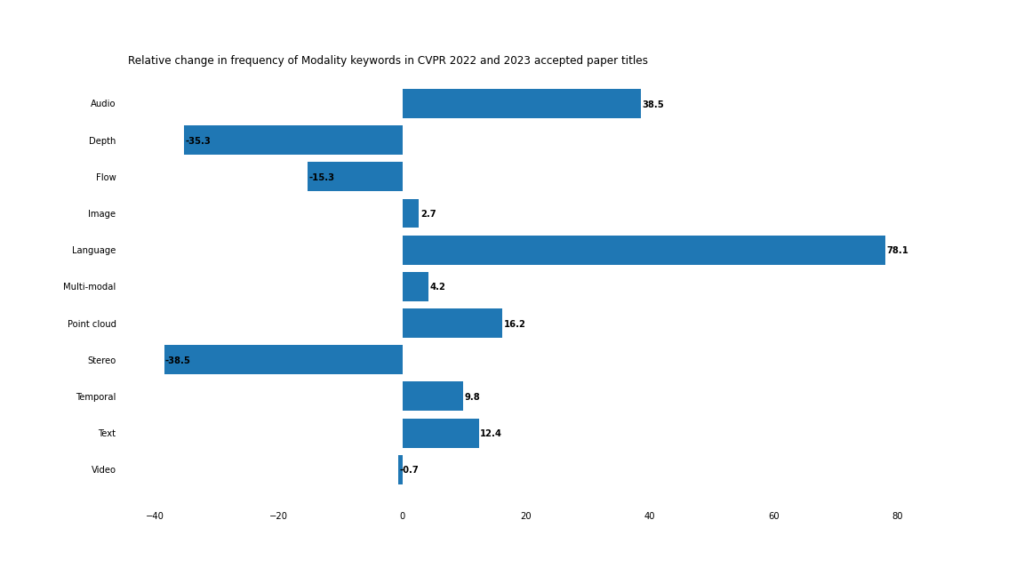
##曖昧な境界
従来のコンピュータではありますが、 「画像」や「ビデオ」などのビジュアルキーワードの頻度は比較的変化がありませんが、「テキスト」/「言語」および「音声」の出現頻度が高くなります。「マルチモーダル」という言葉自体が論文のタイトルに含まれていないとしても、コンピューター ビジョンがマルチモーダルな未来に向かっているということを否定するのは困難です。
これは、Open、Prompt、Vocabulary の急激な上昇が示すように、視覚的言語的タスクで特に顕著です。
この状況の最も極端な例は、「オープンボキャブラリー」という複合語で、2022 年には 3 回しか出現しませんでしたが、2023 年には 18 回出現しました。
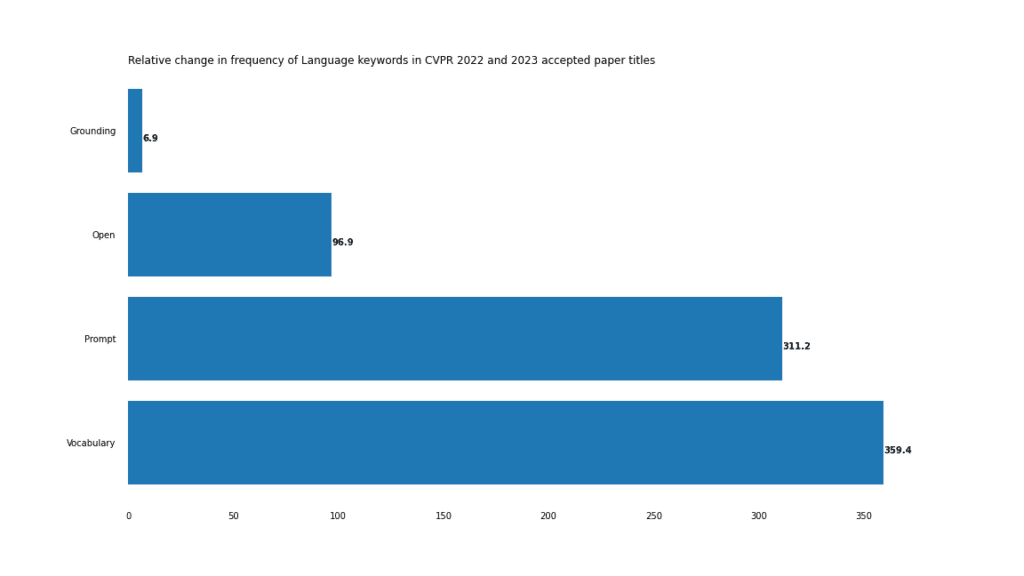
PointCloud9
3 次元コンピューター ビジョン アプリケーションは、2 次元画像から 3D 情報 (「深度」と「立体視」) を推論することから、3D 点群上で直接推論することに移行しています。データ 作業を行うコンピューター ビジョン システム。
履歴書タイトルの創造性
2023 年の機械学習関連の包括的な報道は、ChatGPT をミックスに含めなければ不完全になります。私たちは物事を面白くしておくことに決め、ChatGPT を使用して CVPR 2023 の最もクリエイティブな見出しを見つけました。
Arxiv にアップロードされた各論文について、要約をスクレイピングし、ChatGPT (GPT-3.5 API) に対応する CVPR 論文のタイトルを生成するよう依頼しました。
次に、ChatGPT によって生成されたこれらのタイトルと実際の論文のタイトルを組み合わせ、OpenAI の text-embedding-ada-002 モデルを使用して埋め込みベクトルを生成し、生成されたタイトルの合計を計算します。著者が生成したタイトル間のコサイン類似度。
これから何がわかるでしょうか? ChatGPT が実際の論文のタイトルに近いほど、タイトルはより予測可能になります。言い換えれば、ChatGPT の予測が「偏っている」ほど、著者が論文に名前を付ける際に「創造的」になるということです。
埋め込みとコサイン類似度は、完璧とは程遠いものの、興味深い定量化方法を提供します。
この指標に従って論文を並べ替えました。早速、最もクリエイティブな見出しをご紹介します。
実際の見出し: 野生のあらゆるものを追跡
予測される見出し: 分類を解きほぐすトラッキング: マルチカテゴリ複数オブジェクト追跡の包括的なベンチマークのための TETA の紹介
実際のタイトル: ラベル ノイズと戦うためのブートストラップの学習
予測タイトル: ディープ ニューラル ネットワークにおけるジョイント インスタンスとラベルの再重み付けの学習可能な損失目標
実際のタイトル: Seeing a Rose in Five Thousand Ways
予測タイトル: 優れたビジュアル レンダリングと合成のための単一のインターネット画像からのオブジェクト組み込み関数の学習
実際のタイトル: なぜ勝者が最も優れているのか?
予測タイトル: 画像解析の国際ベンチマーク コンペティションでの勝利戦略の分析: IEEE ISBI および MICCAI 2021 のマルチセンター研究からの洞察
以上がCVPR 2023 論文概要! CV の最もホットな分野はマルチモーダル モデルと拡散モデルに与えられますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7513
7513
 15
1378
52
78
11
19
64
15
1378
52
78
11
19
64

 Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3 の論文がついに登場しました!このモデルは2週間前にリリースされ、Soraと同じDiT(DiffusionTransformer)アーキテクチャを採用しており、リリースされると大きな話題を呼びました。前バージョンと比較して、StableDiffusion3で生成される画像の品質が大幅に向上し、マルチテーマプロンプトに対応したほか、テキスト書き込み効果も向上し、文字化けが発生しなくなりました。 StabilityAI は、StableDiffusion3 はパラメータ サイズが 800M から 8B までの一連のモデルであると指摘しました。このパラメーター範囲は、モデルを多くのポータブル デバイス上で直接実行できることを意味し、AI の使用を大幅に削減します。
 ICCV'23論文賞「Fighting of Gods」! Meta Divide Everything と ControlNet が共同で選ばれました、審査員を驚かせた記事がもう 1 つありました
Oct 04, 2023 pm 08:37 PM
ICCV'23論文賞「Fighting of Gods」! Meta Divide Everything と ControlNet が共同で選ばれました、審査員を驚かせた記事がもう 1 つありました
Oct 04, 2023 pm 08:37 PM
フランスのパリで開催されたコンピュータービジョンのトップカンファレンス「ICCV2023」が閉幕しました。今年の論文賞はまさに「神と神の戦い」です。たとえば、最優秀論文賞を受賞した 2 つの論文には、ヴィンセント グラフ AI の分野を覆す研究である ControlNet が含まれていました。 ControlNet はオープンソース化されて以来、GitHub で 24,000 個のスターを獲得しています。拡散モデルであれ、コンピュータ ビジョンの全分野であれ、この論文の賞は当然のことです。最優秀論文賞の佳作は、同じく有名なもう 1 つの論文、Meta の「Separate Everything」「Model SAM」に授与されました。 「Segment Everything」は、発売以来、後発のものも含め、さまざまな画像セグメンテーション AI モデルの「ベンチマーク」となっています。
 NeRFと自動運転の過去と現在、10本近くの論文をまとめました!
Nov 14, 2023 pm 03:09 PM
NeRFと自動運転の過去と現在、10本近くの論文をまとめました!
Nov 14, 2023 pm 03:09 PM
Neural Radiance Fieldsは2020年に提案されて以来、関連論文の数が飛躍的に増加し、3次元再構成の重要な分野となっただけでなく、自動運転の重要なツールとして研究の最前線でも徐々に活発になってきています。 NeRF は、過去 2 年間で突然出現しました。その主な理由は、特徴点の抽出とマッチング、エピポーラ幾何学と三角形分割、PnP とバンドル調整、および従来の CV 再構成パイプラインのその他のステップをスキップし、メッシュ再構成、マッピング、ライト トレースさえもスキップするためです。 、2D から直接入力画像を使用して放射線野を学習し、実際の写真に近いレンダリング画像が放射線野から出力されます。言い換えれば、ニューラル ネットワークに基づく暗黙的な 3 次元モデルを指定されたパースペクティブに適合させます。
 紙のイラストも拡散モデルを使用して自動生成でき、ICLR にも受け入れられます。
Jun 27, 2023 pm 05:46 PM
紙のイラストも拡散モデルを使用して自動生成でき、ICLR にも受け入れられます。
Jun 27, 2023 pm 05:46 PM
生成 AI は人工知能コミュニティに旋風を巻き起こし、個人も企業も、Vincent 写真、Vincent ビデオ、Vincent 音楽など、関連するモーダル変換アプリケーションの作成に熱心になり始めています。最近、ServiceNow Research や LIVIA などの科学研究機関の数人の研究者が、テキストの説明に基づいて論文内のグラフを生成しようとしました。この目的のために、彼らは FigGen の新しい手法を提案し、関連する論文も TinyPaper として ICLR2023 に掲載されました。絵用紙のアドレス: https://arxiv.org/pdf/2306.00800.pdf 絵用紙のチャートを生成するのは何がそんなに難しいのかと疑問に思う人もいるかもしれません。これは科学研究にどのように役立ちますか?
 チャットのスクリーンショットから AI レビューの隠されたルールが明らかになります。 AAAI 3000元は強力に受け入れられますか?
Apr 12, 2023 am 08:34 AM
チャットのスクリーンショットから AI レビューの隠されたルールが明らかになります。 AAAI 3000元は強力に受け入れられますか?
Apr 12, 2023 am 08:34 AM
AAAI 2023 の論文提出期限が近づいていたとき、AI 投稿グループの匿名チャットのスクリーンショットが突然 Zhihu に表示されました。そのうちの1人は、「3,000元で強力なサービスを提供できる」と主張した。このニュースが発表されるとすぐに、ネットユーザーの間で国民の怒りを引き起こした。ただし、まだ急ぐ必要はありません。 Zhihuのボス「Fine Tuning」は、これはおそらく単に「言葉による喜び」である可能性が高いと述べた。 『ファイン・チューニング』によると、挨拶や集団犯罪はどの分野でも避けられない問題だという。 openreview の台頭により、cmt のさまざまな欠点がますます明らかになり、小さなサークルが活動できる余地は将来的には小さくなるでしょうが、余地は常にあります。これは個人の問題であり、投稿システムや仕組みの問題ではないからです。オープンRの紹介
 中国チームが最優秀論文賞と最優秀システム論文賞を受賞し、CoRLの研究成果が発表されました。
Nov 10, 2023 pm 02:21 PM
中国チームが最優秀論文賞と最優秀システム論文賞を受賞し、CoRLの研究成果が発表されました。
Nov 10, 2023 pm 02:21 PM
2017 年に初めて開催されて以来、CoRL はロボット工学と機械学習の交差点における世界トップクラスの学術会議の 1 つになりました。 CoRL は、理論と応用を含むロボット工学、機械学習、制御などの複数のトピックをカバーするロボット学習研究のための単一テーマのカンファレンスであり、2023 年 CoRL カンファレンスは 11 月 6 日から 9 日まで米国アトランタで開催されます。公式データによると、今年は25か国から199本の論文がCoRLに選ばれた。人気のあるトピックには、演算、強化学習などが含まれます。 CoRLはAAAIやCVPRといった大規模なAI学会に比べて規模は小さいものの、今年は大型モデル、身体化知能、ヒューマノイドロボットなどの概念の人気が高まる中、関連研究も注目されるだろう。
 CVPR 2023 ランキング発表、採択率は 25.78%! 2,360 件の論文が受理され、投稿数は 9,155 件に急増しました。
Apr 13, 2023 am 09:37 AM
CVPR 2023 ランキング発表、採択率は 25.78%! 2,360 件の論文が受理され、投稿数は 9,155 件に急増しました。
Apr 13, 2023 am 09:37 AM
ちょうど今、CVPR 2023 が次のような記事を発表しました: 今年は記録的な 9,155 件の論文 (CVPR2022 より 12% 増) を受け取り、2,360 件の論文を受理し、受理率は 25.78% でした。統計によると、CVPRへの投稿数は2010年から2016年の7年間で1,724件から2,145件に増加しただけです。 2017年以降は急上昇して高度成長期に入り、2019年には初めて5,000件を超え、2022年には投稿数が8,161件に達した。ご覧のとおり、今年は合計 9,155 件の論文が投稿され、確かに記録を樹立しました。流行が緩和された後、今年のCVPRサミットはカナダで開催される予定だ。今年はシングルトラックカンファレンスとなり、従来の口頭選考は中止される。グーグルリサーチ
 中国のチームによって作成されたユニバーサル セグメンテーション モデルである SEEM は、ワンタイム セグメンテーションを新たなレベルに引き上げます
Apr 26, 2023 pm 10:07 PM
中国のチームによって作成されたユニバーサル セグメンテーション モデルである SEEM は、ワンタイム セグメンテーションを新たなレベルに引き上げます
Apr 26, 2023 pm 10:07 PM
今月初め、Meta は「すべてをセグメント化する」AI モデル、SegmentAnythingModel (SAM) をリリースしました。 SAM は画像セグメンテーションの普遍的な基本モデルと考えられており、オブジェクトに関する一般的な概念を学習し、トレーニング プロセス中に遭遇しなかったオブジェクトや画像タイプを含む、あらゆる画像またはビデオ内のあらゆるオブジェクトのマスクを生成できます。この「ゼロサンプルマイグレーション」機能は驚くべきもので、CV分野に「GPT-3の瞬間」が到来したとさえ言う人もいる。最近、「SegmentEverythingEverywhereAllatOnce」に関する新しい論文「SegmentEverythingEverywhereAllatOnce」が再び注目を集めている。論文の中で、ウィスコンシン大学マディソン校の研究者らは、
