

再現可能、自動化、低コスト、高レベルの評価を実現する、大規模モデルを自動評価する初の大規模モデル PandaLM が登場

大規模モデルの開発は急速であると言え、命令の微調整方法が春の雨後の筍のように芽生え、いわゆる ChatGPT の「代替」大規模モデルが多数リリースされました。続々。大規模モデルのトレーニングとアプリケーション開発において、オープンソース、クローズドソース、自己研究などのさまざまな大規模モデルの実際の機能を評価することは、研究開発の効率と品質を向上させる上で重要なリンクとなっています。
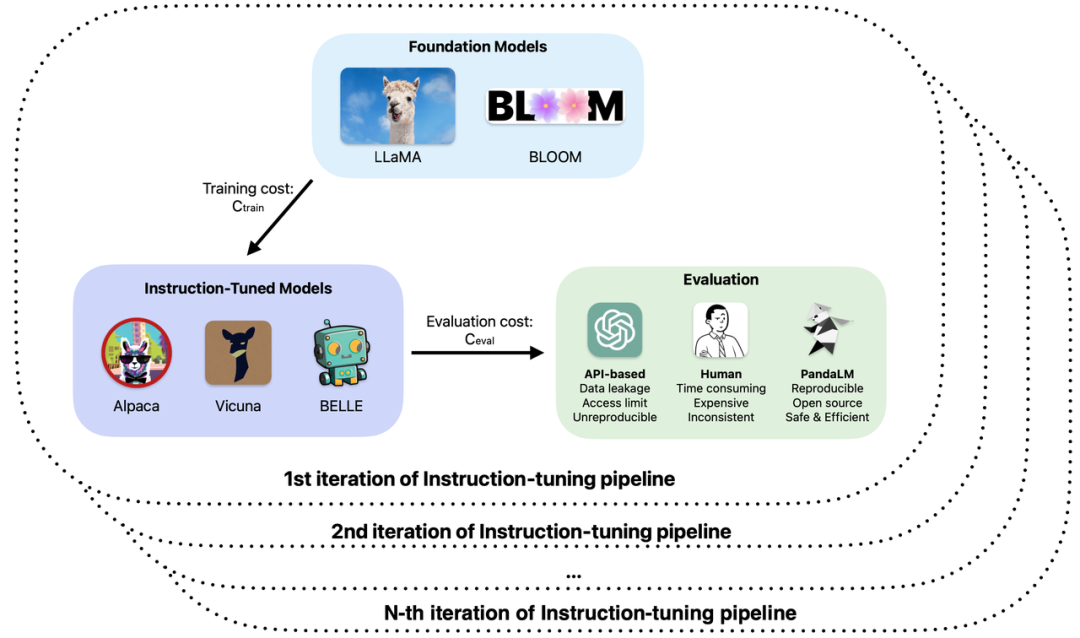
# 具体的には、大規模なモデルのトレーニングと適用において、次の問題が発生する可能性があります。
#1. 大規模モデルの微調整や強化された事前トレーニングでは、さまざまなベースとパラメーターが使用されます。観察されたサンプル効果によると、モデルのパフォーマンスには、さまざまなシナリオで独自の長所と短所があります。実際のアプリケーションでどのモデルを使用するかをどのように決定しますか?2. ChatGPT を使用してモデル出力を評価しますが、ChatGPT は同じ入力に対して異なる時点で異なる評価結果を取得します。どの評価結果を使用する必要がありますか?
3. 手動アノテーションを使用してモデルが生成した結果を評価するのは、時間も労力もかかります。予算が限られており、時間が限られている場合に、評価プロセスを高速化してコストを削減する方法きつい?
4. 機密データを扱う場合、ChatGPT/GPT4 を使用する場合でも、モデル評価に会社にラベルを付ける場合でも、データ漏洩の問題に直面することになります。
これらの問題に基づいて、北京大学、西湖大学、その他の機関の研究者が共同で、新しい大規模モデル評価パラダイムである PandaLM を提案しました。 PandaLM は、評価専用に大規模なモデルをトレーニングすることにより、大規模なモデルの機能の自動化された再現可能なテストと検証を実行します。 PandaLM は、4 月 30 日に GitHub で公開された、世界初の大規模評価モデルです。関連論文は近日中に出版される予定です。

PandaLM は、大規模なモデルがトレーニングを通じてさまざまな大規模なモデルによって生成されたテキストに対する人間の全体的な好みを学習し、好みに基づいて相対評価を行うことで、手動または API ベースの評価方法を置き換えてコストを削減できるようにすることを目的としています。効率。 PandaLM の重みは完全に公開されており、ハードウェアしきい値が低い消費者向けハードウェアで実行できます。 PandaLM の評価結果は信頼性が高く、完全に再現可能で、データのセキュリティを保護できます。評価プロセスはローカルで完了できるため、機密データを必要とする学術機関や部門での使用に非常に適しています。 PandaLM の使用は非常に簡単で、呼び出すのに必要なコードは 3 行だけです。 PandaLM の評価機能を検証するために、PandaLM チームは 3 人のプロのアノテーターを招き、さまざまな大規模モデルの出力を独立して判断してもらい、50 分野の 1,000 サンプルを含む多様なテスト セットを構築しました。このテスト セットでは、PandaLM の精度は ChatGPT の 94% のレベルに達し、PandaLM はモデルの長所と短所について手動アノテーションと同じ結論を出しました。
PandaLM の概要
現在、大規模モデルを評価するには主に 2 つの方法があります:
(1) を呼び出すことによってサードパーティ企業の API インターフェイス;
(2) 手動アノテーションのために専門家を雇います。
ただし、データをサードパーティ企業に転送すると、Samsung 従業員がコードを漏洩した場合と同様のデータ侵害が発生する可能性があります [1]。大量のデータにラベルを付けるために専門家を雇う時期が来ています。 -消費量が多く高価です。解決すべき緊急の問題は、プライバシーを保護し、信頼性があり、再現可能で、安価な大規模モデルの評価をどのように達成するかということです。
これら 2 つの評価方法の限界を克服するために、この研究では、特に大規模モデルのパフォーマンスを評価するために使用される審判モデルである PandaLM を開発しました。 to PandaLM は、たった 1 行のコードで呼び出すことができ、プライバシーを保護し、信頼性が高く、再現性があり、経済的な大規模モデル評価を実現できます。 PandaLM のトレーニングの詳細については、オープンソース プロジェクトを参照してください。
PandaLM の大規模モデルを評価する能力を検証するために、研究チームは、人間が生成したコンテキストとラベルを備えた、人間が注釈を付けた約 1,000 個のサンプルからなる多様なテスト セットを構築しました。テスト データ セットでは、PandaLM-7B は ChatGPT (gpt-3.5-turbo) の 94% の精度を達成しました。
PandaLM の使用方法?
2 つの異なる大規模モデルが同じ命令とコンテキストに対して異なる応答を生成する場合、PandaLM の目標は、2 つのモデルの応答の品質を比較し、その比較結果を出力することです。結果、比較の根拠、および参考のための回答。比較結果は 3 つあります: 応答 1 の方が優れている、応答 2 の方が優れている、応答 1 と応答 2 は同等の品質です。複数の大規模モデルのパフォーマンスを比較する場合、PandaLM を使用してペアごとの比較を実行し、これらの比較を集計してモデルのパフォーマンスをランク付けしたり、モデルの半次数をプロットしたりするだけです。これにより、異なるモデル間のパフォーマンスの違いを視覚的に分析できます。 PandaLM はローカルに展開するだけで済み、人間の関与を必要としないため、プライバシーを保護し、低コストの方法で評価できます。より良い解釈を提供するために、PandaLM はその選択を自然言語で説明し、追加の参照応答セットを生成することもできます。
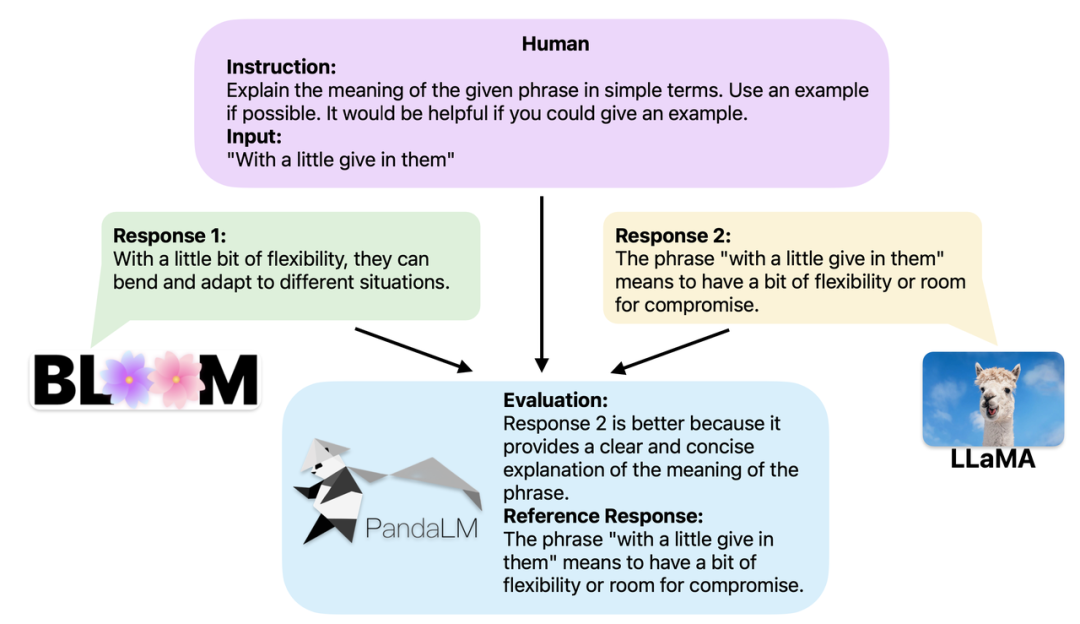
PandaLM は、ケース分析のための Web UI の使用をサポートするだけでなく、PandaLM を呼び出すための 3 行のコードもサポートします。任意のモデルとデータ生成テキストの評価。既存のモデルやフレームワークの多くがオープンソースではないか、ローカルでの推論が難しいことを考慮すると、PandaLM では、モデルの重みを指定するか、評価対象のテキストを含む .json ファイルを直接渡すことによって、評価対象のテキストを生成できます。ユーザーは、モデル名、HuggingFace モデル ID、または .json ファイル パスのリストを指定するだけで、PandaLM を利用してユーザー定義モデルを評価し、データを入力できます。以下は最小限の使用例です:

また、誰もが柔軟に PandaLM を使用できるようにするために、無料評価を行っています。 , 研究チームはHuggingFaceのWebサイトでPandaLMのモデル重量を公開しています。次のコマンドを使用して、PandaLM-7B モデルを簡単にロードできます。

PandaLM-7B モデルの機能
PandaLMの特徴としては、再現性、自動化、プライバシー保護、低コスト、高い評価レベルが挙げられます。
1. 再現性: PandaLM の重みは公開されているため、言語モデルの出力にランダム性がある場合でも、ランダム シードを修正した後の PandaLM の評価結果は一貫したままになります。オンライン API に依存する評価方法では、更新が不透明であるため、その時々で一貫性のない更新が行われる可能性があり、モデルが反復されると API 内の古いモデルにアクセスできなくなる可能性があるため、オンライン API に基づく評価は再現できないことがよくあります。
2. 自動化、プライバシー保護、低コスト: ユーザーは、PandaLM モデルをローカルにデプロイし、既成のコマンドを呼び出すだけで、さまざまな大規模なモデルを評価できます。専門家を雇うのと同じ時間でコミュニケーションを取り、データ侵害について心配することができます。同時に、PandaLM の評価プロセス全体には API 料金や人件費がかからず、非常に安価です。
3. 評価レベル: PandaLM の信頼性を検証するために、この研究では 3 人の専門家を雇い、繰り返しのアノテーションを独立して完了させ、手動のアノテーション テスト セットを作成しました。テスト セットには 50 の異なるシナリオが含まれており、それぞれに複数のタスクが含まれます。このテスト セットは多様性があり、信頼性が高く、テキストに対する人間の好みと一致しています。テスト セット内の各サンプルは、命令とコンテキスト、および異なる大規模モデルによって生成された 2 つの応答で構成され、2 つの応答の品質は人間によって比較されます。
この調査では、アノテーター間で大きな差があるサンプルを排除して、最終的なテストセットにおける各アノテーターの IAA (アノテーター間合意) が 0.85 に近くなるようにしています。 PandaLM トレーニング セットと、この研究で作成された手動で注釈が付けられたテスト セットの間にはまったく重複がないことに注意してください。
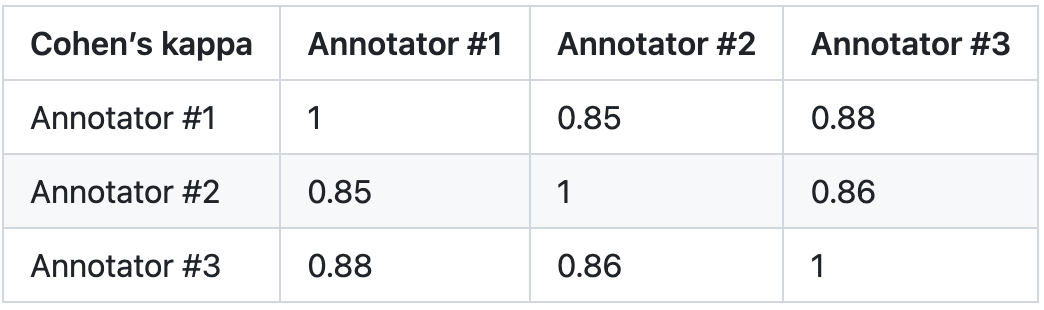
#これらのフィルタリングされたサンプルには、判断を支援するために追加の知識や入手困難な情報が必要であり、人間にとっては困難です正確にラベルを付けます。フィルタリングされたテスト セットには 1000 個のサンプルが含まれていますが、フィルタリングされていない元のテスト セットには 2500 個のサンプルが含まれています。テスト セットの分布は {0:105, 1:422, 2:472} で、0 は 2 つの応答が同様の品質であることを示し、1 は応答 1 の方が優れていることを示し、2 は応答 2 の方が優れていることを示します。
人間のテスト セットに基づく、PandaLM と gpt-3.5-turbo のパフォーマンスの比較は次のとおりです。
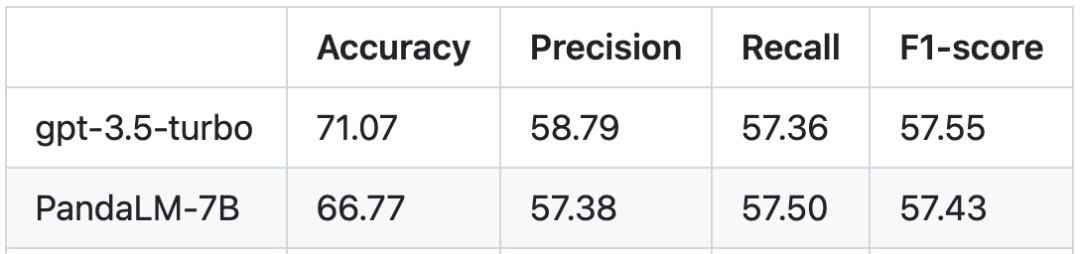
PandaLM-7B は精度において gpt-3.5-turbo のレベル 94% に達しており、適合率、再現率、F1 スコアの点で PandaLM-7B が達成されていることがわかります。 7B は gpt -3.5-turbo を上回りました。それほど遠くありません。 PandaLM-7B はすでに gpt-3.5-turbo と同等の大規模モデル評価能力を備えていると言えます。
この調査では、テスト セットの精度、適合率、再現率、F1 スコアに加えて、同様のサイズの 5 つの大規模なオープンソース モデル間の比較も提供されています。この研究では、まず同じトレーニング データを使用して 5 つのモデルを微調整し、次に人間、gpt-3.5-turbo、および PandaLM を使用して 5 つのモデルのペアごとの比較を実施しました。以下の表の最初の行の最初のタプル (72、28、11) は、Bloom-7B よりも優れた LLaMA-7B 応答が 72 個あり、Bloom-7B よりも悪い LLaMA-7B 応答が 28 個あることを示しています。モデルには同様の品質の 11 件の応答がありました。したがって、この例では、人間は LLaMA-7B が Bloom-7B よりも優れていると考えています。以下の 3 つの表の結果は、人間、gpt-3.5-turbo、PandaLM-7B の各モデルの優劣に関する判断が完全に一致していることを示しています。
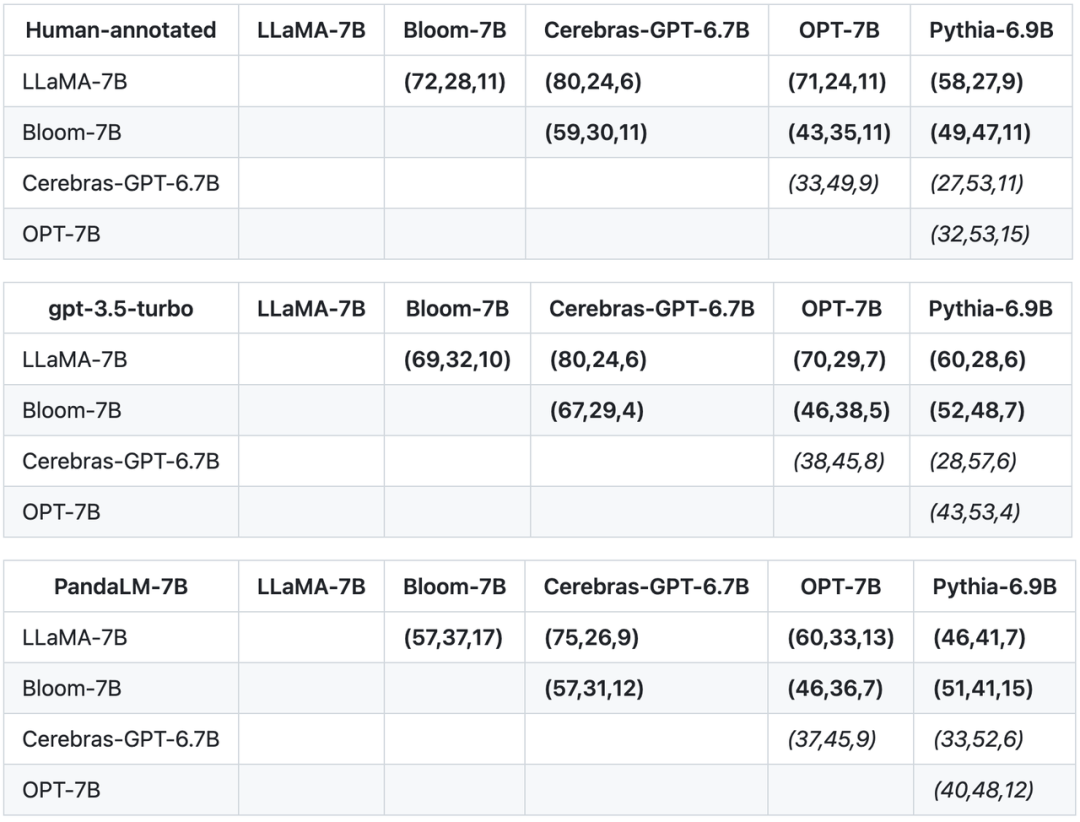
上記の 3 つの表に基づいて、この研究ではモデルの長所と短所の部分順序図を生成しました。この部分順序図は、LLaMA-7B > Bloom-7B > Pythia-6.9B > OPT-7B > Cerebras-GPT-6.7B として表現できる全順序関係が得られます。
要約すると、PandaLM は手動評価に加えて、サードパーティ API A を提供します。大規模モデルを評価するための 3 番目のオプション。 PandaLM の評価レベルは高いだけでなく、その結果は再現可能であり、評価プロセスは高度に自動化されており、プライバシーは保護され、コストは低くなっています。研究チームは、PandaLM が学術界や産業界における大規模モデルの研究を促進し、より多くの人々がこの研究分野の進歩の恩恵を受けることができるようになると信じています。どなたでも PandaLM プロジェクトにご注目ください。トレーニング、テストの詳細、関連記事、フォローアップ作業の詳細は、プロジェクト Web サイト (https://github.com/WeOpenML/PandaLM#) で発表されます。
# #著者チームの紹介
著者チームの中で、Wang Yidong* は北京大学国立ソフトウェア工学センターの出身です (博士) .D.) および西湖大学 (研究助手)、Yu Zhuohao*、Zeng Zhengran 、Jiang Chaoya、Xie Rui、Ye Wei†、および Zhang Shikun† は、北京大学国立ソフトウェア工学センター出身、Yang Linyi、Wang Cunxiang と Zhang Yue† は西湖大学の出身で、Heng Qiang はノースカロライナ州立大学の出身で、Chen Hao はカーネギーメロン大学の出身で、Jindong Wang と Xie Xing は Microsoft Research Asia の出身です。 * は共同第一著者を示し、† は共同責任著者を示します。以上が再現可能、自動化、低コスト、高レベルの評価を実現する、大規模モデルを自動評価する初の大規模モデル PandaLM が登場の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7442
7442
 15
1371
52
76
11
9
6
15
1371
52
76
11
9
6

 vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのオブジェクトに文字列を変換する場合、標準のjson文字列にはjson.parse()が推奨されます。非標準のJSON文字列の場合、文字列は正規表現を使用して処理し、フォーマットまたはデコードされたURLエンコードに従ってメソッドを削減できます。文字列形式に従って適切な方法を選択し、バグを避けるためにセキュリティとエンコードの問題に注意してください。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
概要:Vue.js文字列配列をオブジェクト配列に変換するための次の方法があります。基本方法:定期的なフォーマットデータに合わせてマップ関数を使用します。高度なゲームプレイ:正規表現を使用すると、複雑な形式を処理できますが、慎重に記述して考慮する必要があります。パフォーマンスの最適化:大量のデータを考慮すると、非同期操作または効率的なデータ処理ライブラリを使用できます。ベストプラクティス:コードスタイルをクリアし、意味のある変数名とコメントを使用して、コードを簡潔に保ちます。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 VueおよびElement-UIカスケードドロップダウンボックスVモデルバインディング
Apr 07, 2025 pm 08:06 PM
VueおよびElement-UIカスケードドロップダウンボックスVモデルバインディング
Apr 07, 2025 pm 08:06 PM
VueとElement-UIカスケードドロップダウンボックスv-Modelバインディング共通ピットポイント:V-Modelは、文字列ではなく、カスケード選択ボックスの各レベルで選択した値を表す配列をバインドします。 SelectedOptionsの初期値は、nullまたは未定義ではなく、空の配列でなければなりません。データの動的読み込みには、非同期でデータの更新を処理するために非同期プログラミングスキルを使用する必要があります。膨大なデータセットの場合、仮想スクロールや怠zyな読み込みなどのパフォーマンス最適化手法を考慮する必要があります。
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
