

Redis でのクエリを高速化するためにパイプラインを使用する問題を解決する方法

Request/Response プロトコルと RTT
Redis は、クライアント/サーバー モードの TCP サービスであり、Request/Response プロトコルの実装としても知られています。

これは、通常、リクエストの完了は次の 2 つのステップに従って行われることを意味します。
クライアントは操作コマンドをサーバーに送信します。 , TCP ソケットからサーバーの応答値を読み取ります。一般的に、これはブロックメソッドです。
サーバーは運用コマンドを実行し、応答値をクライアントに返します
例
Client: INCR X Server: 1 Client: INCR X Server: 2 Client: INCR X Server: 3 Client: INCR X Server: 4
クライアントとサーバーはネットワーク経由で接続されます。ネットワーク接続は、非常に高速 (ローカル ループバック ネットワークなど) になる場合もあれば、非常に低速になる場合もあります (複数のホストにまたがるネットワークなど)。ネットワークがどのようなものであっても、データ パケットがクライアントからサーバーに送信されるまでには一定の時間がかかり、その後、対応する値がサーバーからクライアントに返されます。
この時間は RTT (ラウンド トリップ タイム) と呼ばれます。クライアントが複数の連続したリクエスト (リストに多数の要素を追加する、または Redis で多数のキーと値のペアをクリアするなど) を実行する必要がある場合、RTT はパフォーマンスにどのような影響を与えますか?これも計算するのにとても便利です。たとえば、RTT 時間が 250 ミリ秒の場合 (インターネット接続が非常に遅いと仮定して)、サーバーが 1 秒あたり 100,000 のリクエストを処理できるとしても、1 秒あたり最大 4 つのリクエストしか受け付けられません。
ループバック ネットワークの場合、RTT は特に短くなります (たとえば、著者の 127.0.0.1、RTT 応答時間は 44ms) が、複数の連続したネットワークを実行すると大量のコストを消費します。書き込み操作です。
実は、このシナリオでは消費量を削減する他の方法があります。満足していますか?驚き?
Redis パイプライン
Request/Response スタイル サービスには機能があります。クライアントが前の応答値を受信しなくても、新しい応答値を送信し続けることができます。リクエスト。 。この機能により、サーバーの応答を待つ必要がなく、最初に多数の操作コマンドをサーバーに送信し、その後サーバーの応答値をすべて一度に読み取ることができます。
この方法は パイプラインテクノロジーと呼ばれ、ここ数十年で広く使用されています。たとえば、複数の POP3 プロトコルの実装によりこの機能がサポートされ、サーバーから新しい電子メールをダウンロードする速度が大幅に向上します。
Redis はこのテクノロジーを非常に早くからサポートしているため、実行しているバージョンに関係なく、パイプラインテクノロジーを使用できます。たとえば、ここでは netcat ツールを使用したものを示します:
$ (printf "PING\r\nPING\r\nPING\r\n"; sleep 1) | nc localhost 6379 +PONG +PONG +PONG
これで、リクエストごとに RTT を支払う必要がなくなり、一度に 3 つの操作コマンドを送信できます。直感的な理解を容易にするために、前の手順に従って pipelining テクノロジを使用しましょう。実装シーケンスは次のとおりです:
Client: INCR X Client: INCR X Client: INCR X Client: INCR X Server: 1 Server: 2 Server: 3 Server: 4
ハイライト (黒板をノックする): クライアントが使用するときパイプライン操作コマンドを送信すると、サーバーは応答結果を整理するためにメモリを強制的に使用します。したがって、パイプラインを使用して大量の運用コマンドを送信する場合は、たとえば10kの運用コマンドを送信し、その応答を読み取るなど、適切なコマンド数を決定してバッチでサーバーに送信するのが最善です。さらに 10k 個の動作コマンドを送信し、... 消費時間はほぼ同じですが、追加メモリ消費量は、この 10k 個の動作コマンドの配置応答結果に必要な最大値となります。 (メモリの枯渇を防ぐために、適切な値を選択してください)
RTT だけの問題ではありません
パイプラインが RTT による消費を削減する唯一の方法ではありません, ただし、1 秒あたりに実行されるコマンドの数を大幅に増やすのに役立ちます。問題の真実は、対応するデータ構造にアクセスして応答結果を生成するという観点から見ると、パイプラインを使用しないことは確かに非常に安価ですが、ソケット I/O の観点から見ると、それは単に反対。 。これには read() および write() 呼び出しが含まれるため、ユーザー モードからカーネル モードに切り替える必要があります。この種のコンテキストの切り替えには特に時間がかかります。
パイプラインテクノロジが使用されると、多くの操作コマンドが同じ read() 呼び出しから読み取り操作を実行し、大量の応答結果が分散されます。書き込み操作は、同じ write() 呼び出しで実行されます。これに基づいて、以下に示すように、パイプラインの長さが増加するにつれて、1 秒あたりに実行されるクエリの数は、パイプラインテクノロジを使用しない場合、最初はベースラインの 10 倍になるまでほぼ直線的に増加します。
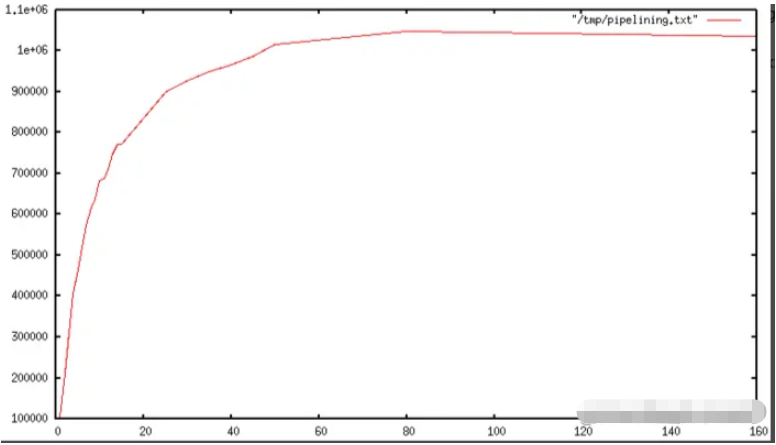 #実際のコード例
#実際のコード例
は翻訳されていません。基本的には、
パイプラインを使用してパフォーマンスを 5 倍向上させることを意味します。 <h4 id="Pipelining-VS-Scripting">Pipelining VS Scripting</h4><p><code>Redis Scripting(2.6+版本可用),通过使用在Server端完成大量工作的脚本Scripting,可以更加高效的解决大量pipelining用例。使用脚本Scripting的最大好处就是在读和写的时候消耗更少的性能,使得像读、写、计算这样的操作更加快速。(当client需要写操作之前获取读操作的响应结果时,pepelining就显得相形见拙。) 有时候,应用可能需要在使用pipelining时,发送 EVAL 或者 EVALSHA 命令,这是可行的,并且Redis明确支持这么这种SCRIPT LOAD命令。(它保证可可以调用 EVALSHA 而不会有失败的风险)。
Appendix: Why are busy loops slow even on the loopback interface?
读完全文,你可能还会感到疑问:为什么如下的Redis测试基准 benchmark 会执行这么慢,甚至在Client和Server在一个物理机上也是如此:
FOR-ONE-SECOND:
Redis.SET("foo","bar")
END毕竟Redis进程和测试基准benchmark在相同的机器上运行,并且这是没有任何实际的延迟和真实的网络参与,不就是消息通过内存从一个地方拷贝到另一个地方么? 原因是进程在操作系统中并不是一直运行。真实的情景是系统内核调度,调度到进程运行,它才会运行。比如测试基准benchmark被允许运行,从Redis Server中读取响应内容(与最后一次执行的命令相关),并且写了一个新的命令。这时命令将在回环网络的套接字中,但是为了被Redis Server读取,系统内核需要调度Redis Server进程(当前正在系统中挂起),周而复始。所以由于系统内核调度的机制,就算是在回环网络中,仍然会涉及到网络延迟。 简言之,在网络服务器中衡量性能时,使用回环网络测试并不是一个明智的方式。应该避免使用此种方式来测试基准。
以上がRedis でのクエリを高速化するためにパイプラインを使用する問題を解決する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7629
7629
 15
1389
52
89
11
31
141
15
1389
52
89
11
31
141

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisを使用して操作をロックするには、setnxコマンドを介してロックを取得し、有効期限を設定するために有効期限コマンドを使用する必要があります。特定の手順は次のとおりです。(1)SETNXコマンドを使用して、キー価値ペアを設定しようとします。 (2)expireコマンドを使用して、ロックの有効期限を設定します。 (3)Delコマンドを使用して、ロックが不要になったときにロックを削除します。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 Redisでデータ損失を解決する方法
Apr 10, 2025 pm 08:24 PM
Redisでデータ損失を解決する方法
Apr 10, 2025 pm 08:24 PM
Redisデータ損失の原因には、メモリの障害、停電、人的エラー、ハードウェアの障害が含まれます。ソリューションは次のとおりです。1。RDBまたはAOF持続性を使用してデータをディスクに保存します。 2。高可用性のために複数のサーバーにコピーします。 3。Hawith redis sentinelまたはredisクラスター。 4.データをバックアップするスナップショットを作成します。 5.永続性、複製、スナップショット、監視、セキュリティ対策などのベストプラクティスを実装します。
 Redisコマンドラインの使用方法
Apr 10, 2025 pm 10:18 PM
Redisコマンドラインの使用方法
Apr 10, 2025 pm 10:18 PM
Redisコマンドラインツール(Redis-Cli)を使用して、次の手順を使用してRedisを管理および操作します。サーバーに接続し、アドレスとポートを指定します。コマンド名とパラメーターを使用して、コマンドをサーバーに送信します。ヘルプコマンドを使用して、特定のコマンドのヘルプ情報を表示します。 QUITコマンドを使用して、コマンドラインツールを終了します。
