

xPath インジェクションの基本的な構文は何ですか?

まず第一に、xPath とは何ですか: xPath は、xml 内の情報を検索するための言語です。
Path には、要素、属性、テキスト、名前空間、処理命令、コメント、ドキュメントの 7 種類のノードが含まれています。ルートノード。 XML 文書は文書ツリーの構造に従って解析され、文書ツリーのルートは文書ノードまたはルート ノードと呼ばれます。

これは、基本的な XML ドキュメントのソース コードです。この XML ソース コードから、bookstore がドキュメント ノード (ルート ノード)、book であることがわかります。 、タイトル、著者、年、価格が要素ノードです。 book ノードには 4 つの子要素ノード (title、author、year、price) があり、title ノードには 3 つの兄弟要素 (author、year、price) があります。 title 要素ノードには属性とテキスト ノードがあり、属性ノードは lang で、その値は en、テキスト ノードの値は HarryPotter です。
以下に、XML ノードの関係の説明がいくつかあります (データ構造のツリーと同様):
親: book ノードの親は書店で、book ノードはタイトル、著者、年、価格 ノードの親。 (各ノードは親を 1 つだけ持つことができます)。
子: book は書店の子であり、book ノードの子はタイトル、著者、年、価格の子です。
(要素ノードは、0 個、1 個、または複数の子を持つことができます)。
タイトルの兄弟要素には、作成者、年、価格が含まれます。これらの要素は、ツリー構造の兄弟ノードと同様に、同じ親ノードを持ちます。 (ノードには兄弟が存在しない場合もあれば、1 つ以上の兄弟を持つこともできます)。
祖先: ノードの親、親の親、親の親の親 (無限ループ)、タイトル要素ノードの祖先は book と本屋です。
子孫: ノードの子、子の子、子の子 (無限ループ)、書店ドキュメント ノードの子孫は、book、タイトル、著者、年、価格、言語です。
xml のノード関係を知るだけでは十分ではありません。それがどのようにクエリされるのかも知る必要があります。xPath はパス式を使用してドキュメント内のノードまたはノード セットを選択します。ノードはパスまたはステップに沿って選択されます。
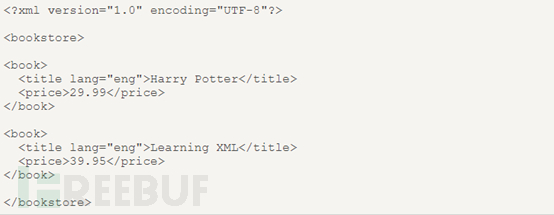
#XPath は、パス式を使用して XML ドキュメント内のノードを選択します。ノードはパスまたはステップをたどることによって選択されます。最も便利なパス式を以下に示します。
nodename: このノードのすべてのノードを選択します
/: ルート ノードから選択します
//: 一致するノードから選択します現在のノードは、その位置に関係なくドキュメント内のノードを選択します
.: 現在のノードを選択します
..: 現在のノードの親ノードを選択します
@: 属性を選択します
xpath クエリ構文を直接使用して js 経由でクエリを実行しましょう
まず、xpath 呼び出しに関する HTML ファイル テンプレートを記述し (呼び出しコードは js に記述されます)、次にクエリ用の XML ファイルを準備します。
js テンプレートのソース コードは次のとおりです。
https://www.runoob.com/try/try.php?filename=try_xpath_select_cdnodes
これを見てください。このHTMLを1つずつ ファイル内のjsコード(jsコードしかないので)
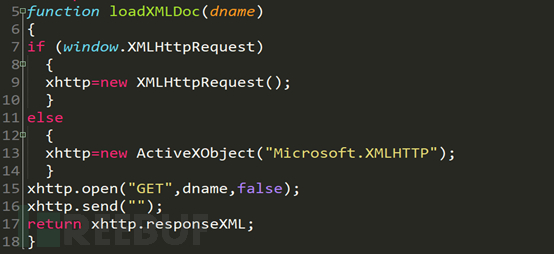
これはjsの非同期呼び出し関数です。重要なコードは次のとおりです。 15 行目と 17 行目で関数によって渡される dname 関数は xml のパスであり、取得された xml ファイルが 17 行目で返されます。
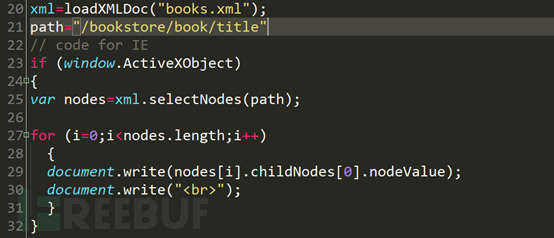
20行目を参照してください。変数xmlはloadXMLDOC関数実行後に取得されるXMLファイルを取得します。 21 行目の path 変数は、xpath のクエリ構文です。最初のif文でIE6以下のブラウザかどうかを判定し、IE6以下のブラウザであれば、対応するクエリのノード配列を取得した後、配列内の値を走査してページに出力します。
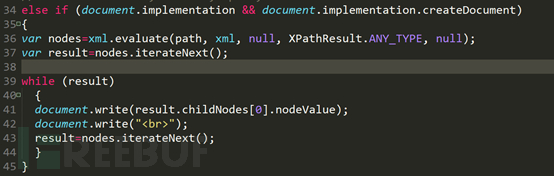
2 番目の if ステートメントは、IE6 以外のブラウザでも同じ実行プロセスを持ちますが、構文が若干異なります。IE6 以外のブラウザは評価を渡します。クエリには関数を使用し、基本的に形式は決まっているので、先ほどの構文を練習してみましょう。
クエリ構文の置換には、パスの値の変更のみが必要です。

最初に、クエリする必要がある構文をリストします。
注: パスがスラッシュ (/) で始まる場合、このパスはwill は常に要素への絶対パスを表します。
bookstore: 書店要素のすべての子ノードを選択します。
/bookstore: ルート要素のbookstoreを選択します。
bookstore/book:bookstore の子要素であるすべての book 要素を選択します。
//book: ドキュメント内の位置に関係なく、すべての book 子要素を選択します。
bookstore//book:bookstore: の下の位置に関係なく、bookstore 要素の子孫であるすべての book 要素を選択します。
//@lang: lang という名前の属性をすべて選択します。
これらの単一クエリのみを使用すると、期待した結果が得られない可能性があるため、他のクエリ ステートメントと組み合わせる必要があります。以下は、一致する必要がある構文の一部です:
Predicate (より正確なクエリ結果を取得するには、角括弧を使用します):
Select the path of the first sub-element book of書店要素を /bookstore /book[1] に追加します。
/bookstore/book[last()]:bookstore の子要素である最後の book 要素を選択します。
/bookstore/book[last()-1]:bookstore の子要素である最後から 2 番目の book 要素を選択します。
/bookstore/book[position()
//title[@lang]: lang という名前の属性を持つすべての title 要素を選択します。
//title[@lang='eng']: eng の値を持つ lang 属性を持つすべての title 要素を選択します。
/bookstore/book[price>35.00]: 本屋要素のすべての book 要素を選択します。price 要素の値は 35.00 より大きくなければなりません。
/bookstore/book[price>35.00]/title:bookstore 要素内の book 要素のすべての title 要素を選択します。price 要素の値は 35.00 より大きくなければなりません。
不明なノードを選択:
*: 任意の要素ノードと一致します。
##@*: 任意の属性ノードと一致します。 node(): 任意のタイプのノードに一致します。 例: /bookstore/*:bookstore 要素のすべての子要素を選択します。 //*: ドキュメント内のすべての要素を選択します。 //title[@*]: 属性を持つすべてのタイトル要素を選択します。 いくつかのパスを選択します: //book/title | //book/price: book 要素のすべての title 要素とprice 要素を選択します。 //title | //price: ドキュメント内のすべてのタイトル要素と価格要素を選択します。 /bookstore/book/title | //price: 書店要素の book 要素に属するすべての title 要素と、ドキュメント内のすべてのprice 要素を選択します クエリの例をいくつか見てみましょう:2 番目の本のタイトル値をクエリ:/bookstore/book[1]/title


以上がxPath インジェクションの基本的な構文は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7510
7510
 15
1378
52
78
11
19
64
15
1378
52
78
11
19
64

 PHP の動作: XPath を使用した XML ドキュメントからのデータの抽出
Jun 13, 2023 pm 10:03 PM
PHP の動作: XPath を使用した XML ドキュメントからのデータの抽出
Jun 13, 2023 pm 10:03 PM
XPath は、PHP を使用して XML データを操作する場合に非常に便利なツールです。 XPath は、XML ドキュメント内の要素を検索するための言語です。これは、開発者が XML ドキュメントから必要なデータを迅速かつ簡単に抽出するのに役立ちます。この記事では、XPath の基本概念を紹介し、PHP で XPath を使用する方法を詳しく説明します。 XPath を使用して XML ドキュメントからデータを抽出し、単純なドキュメントを構築する方法を示します。
 PHP と XPath を使用して HTML コンテンツを解析する方法
Jun 17, 2023 am 11:17 AM
PHP と XPath を使用して HTML コンテンツを解析する方法
Jun 17, 2023 am 11:17 AM
Web テクノロジーが発展し続けるにつれて、Web ページのコンテンツはますます複雑になってきています。クローラーやデータマイニングなど、さらなる処理や分析のために HTML ページから情報を抽出する必要があることがよくあります。この記事では、PHP と XPath を使用して HTML コンテンツを解析し、必要な情報を迅速かつ簡単に取得する方法を紹介します。 PHPSimpleHTMLDOMParserPHPSimpleHTMLDOMParser はオープンソースです
 PHP XPath 関数の使用法の詳細な説明: XPath は XML および HTML ファイルの検索およびクエリ関数を提供します
Jun 27, 2023 pm 01:04 PM
PHP XPath 関数の使用法の詳細な説明: XPath は XML および HTML ファイルの検索およびクエリ関数を提供します
Jun 27, 2023 pm 01:04 PM
XPath は、XML および HTML ドキュメント内の特定のノードをクエリして検索するための言語です。 XPath はパス表現言語として、PHP を含む多くのプログラミング言語で広く使用されています。この記事では、プロジェクトで XPath を簡単に使用して XML および HTML ファイルの検索とクエリを実行できるように、PHPXPath 関数の使用方法を詳しく説明します。 XPathとは何ですか? XPath は、XML および HTML ドキュメント内の特定のノードをクエリして検索するための言語です。
 xPath インジェクションの基本的な構文は何ですか?
May 26, 2023 pm 12:01 PM
xPath インジェクションの基本的な構文は何ですか?
May 26, 2023 pm 12:01 PM
まず、xPath とは: xPath は、xml 内の情報を検索するための言語です。xPath には、要素、属性、テキスト、名前空間、処理命令、コメント、ドキュメント (ルート ノード) の 7 つのノード要素があります。 XML ドキュメントはドキュメント ツリーとして解析され、ツリーのルートはドキュメント ノードまたはルート ノードと呼ばれます。これは基本的なXML文書のソースコードであり、このXMLソースコードからわかるように、bookstoreが文書ノード(ルートノード)であり、book、タイトル、著者、年、価格が要素ノードとなっています。 book ノードには 4 つの子要素ノード (タイトル、著者、年、価格) があり、タイトル ノードには 3 つの兄弟ノード (au) があります。
 PHP の DOM および XPath テクノロジー
May 11, 2023 pm 04:04 PM
PHP の DOM および XPath テクノロジー
May 11, 2023 pm 04:04 PM
近年、インターネットの継続的な発展に伴い、Web 開発技術も継続的に更新され、反復されています。その中でも、PHP 言語は、学習と使用が簡単で、実行速度が速く、クロスプラットフォームの特性があるため、Web 開発の分野で広く使用されています。 PHPでは、Webアプリケーションを開発する際によく使われる技術としてDOMとXPathの技術がありますが、この記事ではこれら2つの技術の基礎知識と応用シナリオについて詳しく紹介します。 1. DOM テクノロジー DOM (Document Object Model、DocumentObjectModel) は、XML または HTM を処理する方法です
 xpath、JsonPath、bs4 に Python を使用するにはどうすればよいですか?
May 09, 2023 pm 09:04 PM
xpath、JsonPath、bs4 に Python を使用するにはどうすればよいですか?
May 09, 2023 pm 09:04 PM
1.xpath1.1xpath Google を使用して、事前に xpath プラグインをインストールします。ctrl+shift+x を押すと、小さな黒いボックスが表示され、lxml ライブラリ pipinstalllxml-ihttps://pypi.douban.com/simple をインストールします。 lxml.etreefromlxmlimportetreeetree.parse() ローカル ファイルを解析します html_tree =etree.parse('XX.html')etree.HTML() サーバー応答ファイル html_tree=etree.HTML(respon
 XPATH を使用して を含むテキストを検索する
Sep 10, 2023 am 11:33 AM
XPATH を使用して を含むテキストを検索する
Sep 10, 2023 am 11:33 AM
ロケーター xpath を使用して、検索テキストに または スペースが含まれる要素を識別できます。まず、Web 要素の HTML コードの末尾と先頭のスペースを確認してみましょう。下の画像では、HTML コード (タグ名 Strong) に反映されているように、テキスト JAVABASICS にスペースが含まれています。要素のテキストまたは属性の値にスペースが含まれている場合、そのような要素の xpath を作成するには、正規化されたスペース関数を使用する必要があります。文字列から末尾と先頭のスペースをすべて削除します。また、文字列内のすべての新しいタグまたは既存の行も削除されます。構文//タグ名[normalize-space(@attribute/functiono
 JavaScript セレクターの種類と使用法の詳細な説明
Dec 26, 2023 pm 12:38 PM
JavaScript セレクターの種類と使用法の詳細な説明
Dec 26, 2023 pm 12:38 PM
JavaScript セレクターのさまざまなタイプと使用法についての詳細な説明 はじめに: JavaScript は、Web 開発で広く使用されている強力なスクリプト言語です。開発プロセス中、多くの場合、セレクターを介して HTML 要素を取得または操作する必要があります。 JavaScript は、さまざまなニーズを満たすためにさまざまなタイプのセレクターを提供します。この記事では、JavaScript セレクターのさまざまな種類と使用法を詳しく説明し、具体的なコード例を示します。 1. getElementById の選択
