

AI Morning Post | テキスト、画像、音声、ビデオ、そして 3D が相互に生成し合う体験とは何ですか?


現地時間の 5 月 9 日、Meta は、視覚 (画像およびビデオ形式)、温度 (赤外線画像)、テキスト、音声、深度情報、モーション読み取り値 (慣性測定ユニットまたは IMU によって生成)。現在、関連するソース コードは GitHub でホストされています。
6 つのモードにまたがるとはどういう意味ですか?
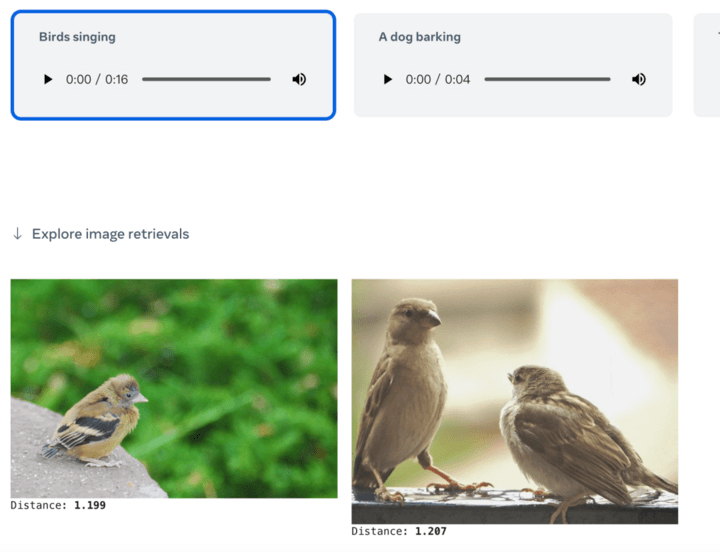
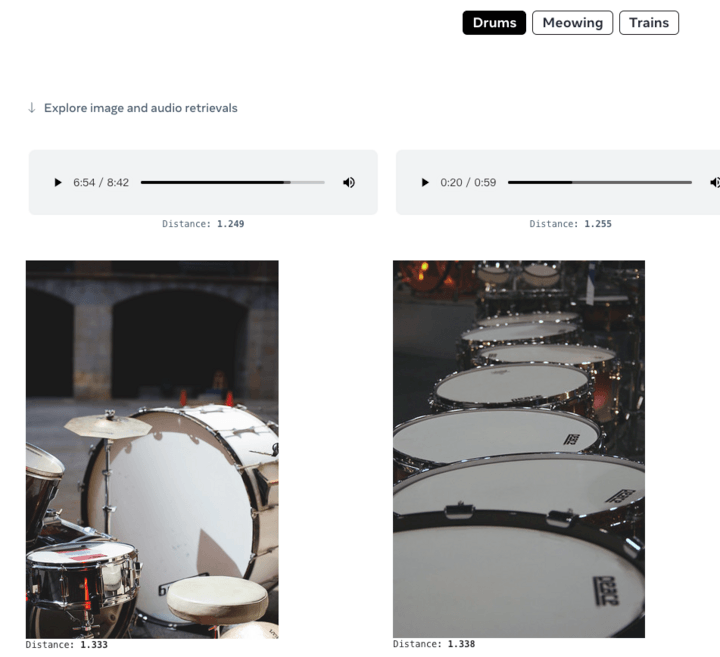
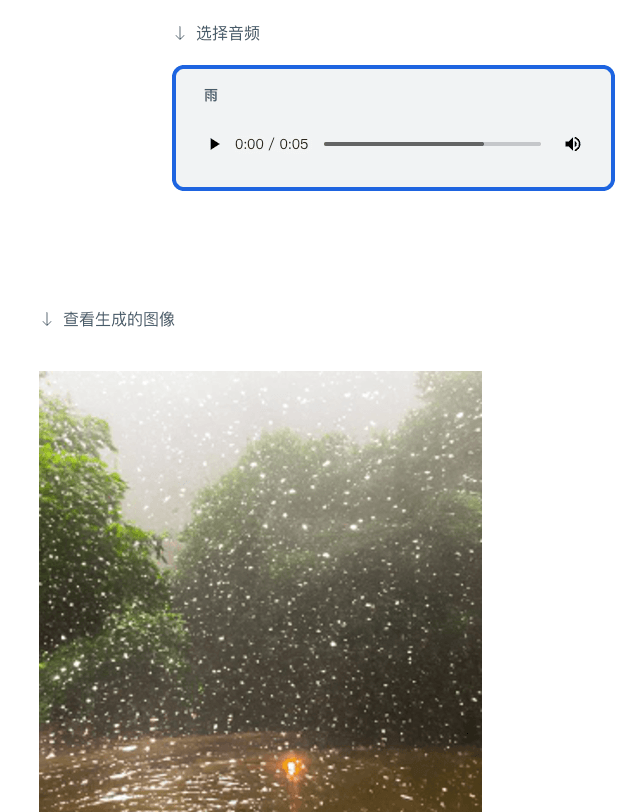
ImageBind はビジョンを核としており、6 つのモードを自由に理解して変換できます。 Meta は、犬の鳴き声を聞いて犬の絵を描き、対応する深度マップとテキストの説明を同時に与える、鳥の画像と海の波の音を入力して画像を取得するなどのいくつかのケースを示しました。浜辺の鳥。
Midjourney、Stable Diffusion、DALL-E 2 などのテキストと画像を組み合わせる画像ジェネレーターと比較すると、ImageBind はより広い網を張るようなもので、テキスト、画像/ビデオ、オーディオ、3D 測定値 (深度)、温度データを接続できます。 (熱) および運動データ (IMU から) を分析し、人間が環境を知覚または想像する方法と同様に、あらゆる可能性について最初にトレーニングすることなく、データ間のつながりを直接予測します。

研究者らは、ImageBind は大規模な視覚言語モデル (CLIP など) を使用して初期化できるため、これらのモデルの豊富な画像とテキスト表現を活用できると述べています。したがって、ImageBind は、ほとんどトレーニングすることなく、さまざまなモダリティやタスクに適応できます。
ImageBind は、関連するすべての種類のデータから学習するマルチモーダル AI システムを作成するという Meta の取り組みの一環です。モダリティの数が増えるにつれ、ImageBind は研究者が 3D センサーと IMU センサーを組み合わせて没入型の仮想世界を設計または体験するなど、新しい総合的なシステムの開発を試みるための水門を開きます。また、テキスト、ビデオ、画像を組み合わせて画像、ビデオ、オーディオ ファイル、またはテキスト情報を検索することで、記憶を探索する豊富な方法も提供します。
このモデルは現在単なる研究プロジェクトであり、直接的な消費者向けまたは実用的なアプリケーションはありませんが、生成 AI が将来どのように没入型で多感覚のコンテンツを生成できるかを示し、またメタインが可能であることも示しています。 OpenAI や Google などの競合他社とは異なる方法で、大規模なオープンソース モデルへの道を切り開いています。
結局のところ、Meta は ImageBind テクノロジーが最終的には現在の 6 つの「感覚」を超えると信じており、ブログで次のように述べています。 —触覚、音声、嗅覚、脳の fMRI 信号など—により、より豊かな人間中心の人工知能モデルが可能になります。」
ImageBind の使用
ChatGPT が検索エンジンおよび質問と回答のコミュニティとして機能し、Midjourney が描画ツールとして使用できる場合、ImageBind で何ができるでしょうか?公式デモによると、画像から直接音声を生成できます:
音声から画像を生成することもできます:
マルチモーダル学習については、まだ発見されていないことがたくさんあります。現在、人工知能の分野では、より大きなモデルでのみ現れるスケーリング動作を効果的に定量化し、そのアプリケーションを理解していません。 ImageBind は、画像の生成と取得のための新しいアプリケーションを厳密な方法で評価および実証するためのステップです。
作者: バラッド
出典: First Electric Network (www.d1ev.com)
以上がAI Morning Post | テキスト、画像、音声、ビデオ、そして 3D が相互に生成し合う体験とは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7444
7444
 15
1371
52
76
11
9
6
15
1371
52
76
11
9
6

 カーソルAIでバイブコーディングを試してみましたが、驚くべきことです!
Mar 20, 2025 pm 03:34 PM
カーソルAIでバイブコーディングを試してみましたが、驚くべきことです!
Mar 20, 2025 pm 03:34 PM
バイブコーディングは、無限のコード行の代わりに自然言語を使用してアプリケーションを作成できるようにすることにより、ソフトウェア開発の世界を再構築しています。 Andrej Karpathyのような先見の明に触発されて、この革新的なアプローチは開発を許可します
 2025年2月のトップ5 Genai発売:GPT-4.5、Grok-3など!
Mar 22, 2025 am 10:58 AM
2025年2月のトップ5 Genai発売:GPT-4.5、Grok-3など!
Mar 22, 2025 am 10:58 AM
2025年2月は、生成AIにとってさらにゲームを変える月であり、最も期待されるモデルのアップグレードと画期的な新機能のいくつかをもたらしました。 Xai’s Grok 3とAnthropic's Claude 3.7 SonnetからOpenaiのGまで
 オブジェクト検出にYolo V12を使用する方法は?
Mar 22, 2025 am 11:07 AM
オブジェクト検出にYolo V12を使用する方法は?
Mar 22, 2025 am 11:07 AM
Yolo(あなたは一度だけ見ています)は、前のバージョンで各反復が改善され、主要なリアルタイムオブジェクト検出フレームワークでした。最新バージョンYolo V12は、精度を大幅に向上させる進歩を紹介します
 SORA vs VEO 2:よりリアルなビデオを作成するのはどれですか?
Mar 10, 2025 pm 12:22 PM
SORA vs VEO 2:よりリアルなビデオを作成するのはどれですか?
Mar 10, 2025 pm 12:22 PM
GoogleのVEO 2とOpenaiのSORA:どのAIビデオジェネレーターが最高でしたか? どちらのプラットフォームも印象的なAIビデオを生成しますが、その強みはさまざまな領域にあります。 この比較は、さまざまなプロンプトを使用して、どのツールがニーズに最適かを明らかにします。 t
 Google' s Gencast:Gencast Mini Demoを使用した天気予報
Mar 16, 2025 pm 01:46 PM
Google' s Gencast:Gencast Mini Demoを使用した天気予報
Mar 16, 2025 pm 01:46 PM
Google Deepmind's Gencast:天気予報のための革新的なAI 天気予報は、初歩的な観察から洗練されたAI駆動の予測に移行する劇的な変化を受けました。 Google DeepmindのGencast、グラウンドブレイク
 ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4は現在利用可能で広く使用されており、CHATGPT 3.5のような前任者と比較して、コンテキストを理解し、一貫した応答を生成することに大幅な改善を示しています。将来の開発には、よりパーソナライズされたインターが含まれる場合があります
 chatgptよりも優れたAIはどれですか?
Mar 18, 2025 pm 06:05 PM
chatgptよりも優れたAIはどれですか?
Mar 18, 2025 pm 06:05 PM
この記事では、Lamda、Llama、GrokのようなChatGptを超えるAIモデルについて説明し、正確性、理解、業界への影響における利点を強調しています(159文字)
 O1対GPT-4O:OpenAIの新しいモデルはGPT-4Oよりも優れていますか?
Mar 16, 2025 am 11:47 AM
O1対GPT-4O:OpenAIの新しいモデルはGPT-4Oよりも優れていますか?
Mar 16, 2025 am 11:47 AM
OpenaiのO1:12日間の贈り物は、これまでで最も強力なモデルから始まります 12月の到着は、世界の一部の地域で雪片が世界的に減速し、雪片がもたらされますが、Openaiは始まったばかりです。 サム・アルトマンと彼のチームは12日間のギフトを立ち上げています
