

Redis のマスター/スレーブ アーキテクチャを確立するにはどのような方法がありますか?

マスター/スレーブ環境の構築
Redis インスタンスはデフォルトではすべてマスター ノードであるため、マスター/スレーブ アーキテクチャを構築するにはいくつかの構成を変更する必要があります。Redis のマスター/スレーブ アーキテクチャは構築が比較的簡単ですRedis マスター スレーブ アーキテクチャを構築するには 3 つの方法が用意されています。後で紹介します。導入する前に、まずマスター スレーブ アーキテクチャの特徴を理解する必要があります。マスター スレーブ アーキテクチャには、マスター ノード (マスター) があります。 ) と少なくとも 1 つのスレーブ ノード (slave)。)、データ レプリケーションは一方向であり、マスター ノードからスレーブ ノードへのみコピーでき、スレーブ ノードからマスター ノードへはコピーできません。
マスター/スレーブ アーキテクチャを確立する方法
マスター/スレーブ アーキテクチャを確立するには 3 つの方法があります:
Redis の場合。slaveof {masterHost} {masterPort} コマンドを conf 構成ファイルに追加します。これは、Redis インスタンスの起動時に有効になります。
# --slaveof {masterHost を追加します。
redis-server 起動コマンドの後の {masterPort} パラメーター
slaveof 127.0.0.1 6379
 2 つの Redis インスタンスをそれぞれ起動します。起動後、自動的にマスターとスレーブの関係が確立されます。この原理については、後で詳しく説明します。まず、マスターとスレーブのアーキテクチャが適切であるかどうかを確認します。成功したら、まず 6379 マスター ノードに新しいデータを追加します:
マスター ノードは新しいデータ
2 つの Redis インスタンスをそれぞれ起動します。起動後、自動的にマスターとスレーブの関係が確立されます。この原理については、後で詳しく説明します。まず、マスターとスレーブのアーキテクチャが適切であるかどうかを確認します。成功したら、まず 6379 マスター ノードに新しいデータを追加します:
マスター ノードは新しいデータ 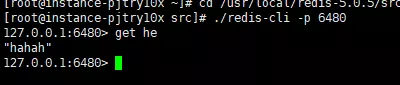 を追加し、次にデータを取得します。 6480 スレーブ ノード上:
を追加し、次にデータを取得します。 6480 スレーブ ノード上:
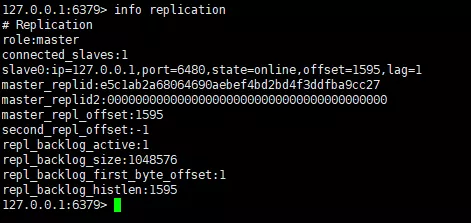 スレーブ上のマスター ノードで新しい値を正常に取得したことがわかります。マスター/スレーブ アーキテクチャを示すノード。正常にセットアップされました。info replication コマンドを使用して 2 つのノードの情報を表示します。最初にマスター ノードの情報を見てみましょう。
スレーブ上のマスター ノードで新しい値を正常に取得したことがわかります。マスター/スレーブ アーキテクチャを示すノード。正常にセットアップされました。info replication コマンドを使用して 2 つのノードの情報を表示します。最初にマスター ノードの情報を見てみましょう。
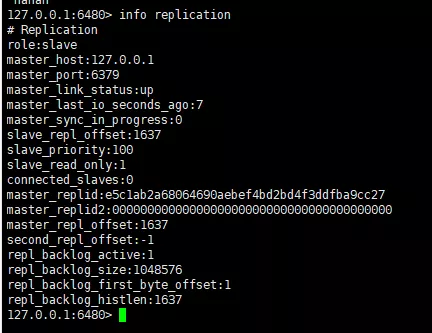 ポート 6379 のインスタンスの役割がマスターであり、接続中のインスタンスがあり、他に実行中のインスタンスがあることがわかります。ポート6480のredisインスタンス情報を見てみましょう。
ポート 6379 のインスタンスの役割がマスターであり、接続中のインスタンスがあり、他に実行中のインスタンスがあることがわかります。ポート6480のredisインスタンス情報を見てみましょう。
127.0.0.1:6480> set x 3 (error) READONLY You can't write against a read only replica. 127.0.0.1:6480>
ログイン後にコピー
プロンプトは読み取り専用であり、書き込み操作はサポートされていません。もちろん、設定を変更することもできます。設定ファイルでは、replica-read-only yes 設定項目が読み取りを制御するために使用されます。サーバーからのみです。なぜ読み取り専用にできるのでしょうか? レプリケーションは一方向であり、データはマスターからスレーブ ノードにのみ送信できることがわかっているためです。スレーブ ノードで書き込みが有効になっている場合、データはスレーブ ノードのデータが変更され、マスター ノードがそれを感知できない スレーブ ノード データをマスター ノードにコピーできず、データの不整合が発生するため、スレーブ ノードは読み取り専用にすることをお勧めします。
127.0.0.1:6480> set x 3 (error) READONLY You can't write against a read only replica. 127.0.0.1:6480>
マスタ・スレーブ構成の切断
マスタ・スレーブ構成の切断もslaveofコマンドですので、スレーブノードでslaveof no oneコマンドを実行してください。次の関係を開くには、ノード 6480 で smileof no one コマンドを実行します。127.0.0.1:6480> slaveof no one OK 127.0.0.1:6480> info replication # Replication role:master connected_slaves:0 master_replid:a54f3ba841c67762d6c1e33456c97b94c62f6ac0 master_replid2:e5c1ab2a68064690aebef4bd2bd4f3ddfba9cc27 master_repl_offset:4367 second_repl_offset:4368 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:4367 127.0.0.1:6480>
127.0.0.1:6379> set y 3 OK
127.0.0.1:6480> get y (nil) 127.0.0.1:6480>
127.0.0.1:6379> info replication # Replication role:slave master_host:127.0.0.1 master_port:6480 master_link_status:up master_last_io_seconds_ago:2 master_sync_in_progress:0 slave_repl_offset:4367 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:99624d4b402b5091552b9cb3dd9a793a3005e2ea master_replid2:0000000000000000000000000000000000000000 master_repl_offset:4367 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:4368 repl_backlog_histlen:0 127.0.0.1:6379>
127.0.0.1:6480> info replication # Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6379,state=online,offset=4479,lag=1 master_replid:99624d4b402b5091552b9cb3dd9a793a3005e2ea master_replid2:a54f3ba841c67762d6c1e33456c97b94c62f6ac0 master_repl_offset:4479 second_repl_offset:4368 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:4479 127.0.0.1:6480>
复制技术的原理
redis 的主从架构好像很简单一样,我们就执行了一条命令就成功搭建了主从架构,并且数据复制也没有问题,使用起来确实简单,但是这背后 redis 还是帮我们做了很多的事情,比如主从服务器之间的数据同步、主从服务器的状态检测等,这背后 redis 是如何实现的呢?接下来我们就一起看看。
数据复制原理
我们执行完 slaveof 命令之后,我们的主从关系就建立好了,在这个过程中, master 服务器与 slave 服务器之间需要经历多个步骤,如下图所示:

redis 复制原理
slaveof 命令背后,主从服务器大致经历了七步,其中权限验证这一步不是必须的,为了能够更好的理解这些步骤,就以我们上面搭建的 redis 实例为例来详细聊一聊各步骤。
1、保存主节点信息
在 6480 的客户端向 6480 节点服务器发送 slaveof 127.0.0.1 6379 命令时,我们会立马得到一个 OK。
127.0.0.1:6480> slaveof 127.0.0.1 6379 OK 127.0.0.1:6480>
这时候数据复制工作并没有开始,数据复制工作是在返回 OK 之后才开始执行的,这时候 6480 从节点做的事情是将给定的主服务器 IP 地址 127.0.0.1 以及端口 6379 保存到服务器状态的 masterhost 属性和 masterport 属性里面。
2、建立 socket 连接
在 slaveof 命令执行完之后,从服务器会根据命令设置的 IP 地址和端口,跟主服务器创建套接字连接, 如果从服务器能够跟主服务器成功的建立 socket 连接,那么从服务器将会为这个 socket 关联一个专门用于处理复制工作的文件事件处理器,这个处理器将负责后续的复制工作,比如接受全量复制的 RDB 文件以及服务器传来的写命令。同样主服务器在接受从服务器的 socket 连接之后,将为该 socket 创建一个客户端状态,这时候的从服务器同时具有服务器和客户端两个身份,从服务器可以向主服务器发送命令请求而主服务器则会向从服务器返回命令回复。
3、发送 ping 命令
从服务器与主服务器连接成功后,做的第一件事情就是向主服务器发送一个 ping 命令,发送 ping 命令主要有以下目的:
检测主从之间网络套接字是否可用
检测主节点当前是否可接受处理命令
在发送 ping 命令之后,正常情况下主服务器会返回 pong 命令,接受到主服务器返回的 pong 回复之后就会进行下一步工作,如果没有收到主节点的 pong 回复或者超时,比如网络超时或者主节点正在阻塞无法响应命令,从服务器会断开复制连接,等待下一次定时任务的调度。
4、身份验证
从服务器在接收到主服务器返回的 pong 回复之后,下一步要做的事情就是根据配置信息决定是否需要身份验证:
如果从服务器设置了 masterauth 参数,则进行身份验证
如果从服务器没有设置 masterauth 参数,则不进行身份验证
在需要身份验证的情况下,从服务器将就向主服务器发送一条 auth 命令,命令参数为从服务器 masterauth 选项的值,举个例子,如果从服务器的配置里将 masterauth 参数设置为:123456,那么从服务器将向主服务器发送 auth 123456 命令,身份验证的过程也不是一帆风顺的,可能会遇到以下几种情况:
从服务器通过 auth 命令发送的密码与主服务器的 requirepass 参数值一致,那么将继续进行后续操作,如果密码不一致,主服务将返回一个 invalid password 错误
如果主服务器没有设置 requirepass 参数,那么主服务器将返回一个 no password is set 错误
所有的错误情况都会令从服务器中止当前的复制工作,并且要从建立 socket 开始重新发起复制流程,直到身份验证通过或者从服务器放弃执行复制为止。
5. ポート情報の送信
認証に合格した後、スレーブ サーバーは REPLCONF リスニング コマンドを実行し、スレーブ サーバーのリスニング ポート番号をマスター サーバーに送信します。この例では、スレーブ サーバーのリスニング ポートは 6480 であり、スレーブ サーバーは REPLCONF リスニング 6480 コマンドをマスター サーバーに送信します。マスター サーバーはこのコマンドを受信した後、クライアントのslave_listening_port 属性にポート番号を記録します。スレーブ サーバーに対応するステータス。マスター サーバーの情報レプリケーションで確認されるポート値です。
6. データ レプリケーション
データ レプリケーションは最も複雑な部分です。これは psync コマンドによって完了します。スレーブ サーバーはマスター サーバーに psync コマンドを送信します。データを処理するための同期。Redis バージョン 2.8 より前では、sync コマンドが使用されていました。さまざまなコマンドに加えて、レプリケーション方法も大きく異なりました。Redis バージョン 2.8 より前では、完全なレプリケーションが使用されていましたが、これにより問題が発生します。マスターノードとネットワークのオーバーヘッドが大きい Redis バージョン 2.8 以降、データ同期は完全同期と部分同期に分割されます。
-
フル コピー: 通常、初期コピー シナリオで使用されます。Redis の新旧バージョンに関係なく、スレーブ サーバーがマスター サービスに接続するときにフル コピーが実行されます。初回はマスターをコピーします ノードのすべてのデータが一度にスレーブノードに送信されます データが大きい場合、マスターノードとネットワークに多くのオーバーヘッドが発生します 初期バージョンの Redis はのみサポートしています完全レプリケーションは、効率的なデータ レプリケーション方法ではありません
-
部分レプリケーション: マスター/スレーブ レプリケーションにおけるネットワーク中断やその他の理由によって引き起こされるデータ損失シナリオを処理するために使用されます。状況が許せばマスターノードが損失を補い、欠落したデータをスレーブノードに送信します。再発行されるデータはデータの全量よりもはるかに小さいため、完全コピーの過度のオーバーヘッドを効果的に回避できます。部分コピーは古いバージョンのコピーを大幅に最適化し、不必要な完全コピー操作を効果的に回避します。
redis がフル コピーと部分コピーをサポートできる理由は、主に sync コマンドを最適化するためです。redis バージョン 2.8 以降では、新しい psync コマンドが使用されます。コマンドの形式は、psync {runId} {offset} です。これら 2 つの各パラメータの意味:
- runId: 実行中のマスター ノードの ID
- offset: コピー元のデータのオフセット現在のスレーブ ノード
- 上記の runid とオフセットについてよく知らないかもしれませんが、問題ありません。最初に次の 3 つの概念を見てみましょう:
1. オフセットのコピー
レプリケーションに参加しているマスター ノードとスレーブ ノードは、それぞれ独自のレプリケーション オフセットを維持します: マスター サーバーが N バイトのデータをスレーブ サーバーに送信するたびに、N バイトが追加されます。スレーブ サーバーは、マスター サーバーから送信された N バイトのデータを受信するたびに、自身のオフセット値に N を加算します。マスター サーバーとスレーブ サーバーのレプリケーション オフセットを比較することで、マスター サーバーとスレーブ サーバーのデータが一貫しているかどうかを知ることができます。マスター サーバーとスレーブ サーバーのオフセットが常に同じであれば、マスターとスレーブのデータは一貫しています。逆に、マスターサーバーとスレーブサーバーのオフセットが一致していても、転送量が同じでない場合は、マスターサーバーとスレーブサーバーのデータ状態が一致していないことを意味します。の場合、次の図に示すように、特定のサーバーが送信プロセス中にオフラインになります。
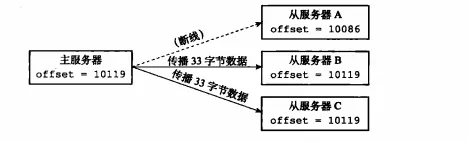 offset is inconsistent
offset is inconsistent
スレーブ サーバー A は次の理由によりオフラインですデータ送信中にネットワーク上の理由により、オフセットがマスター サーバーと不一致になり、スレーブ サーバー A が再起動して一致すると、マスター サーバーが正常に接続された後、psync コマンドをマスター サーバーに再送信します。データ レプリケーションは完全に実行されるべきですか? 部分的に実行されるべきですか? 部分レプリケーションが実行される場合、マスターは切断期間中にスレーブ A によって失われたデータをどのように補償できますか? これらの質問に対する答えは、レプリケーション バックログ バッファーにあります。
2. レプリケーション バックログ バッファレプリケーション バックログ バッファは、プライマリ ノードに保存される固定長のキューです。デフォルトのサイズは 1MB です。プライマリ ノードがスレーブ ノード (slave) が作成されます。このとき、マスター ノード (master) が書き込みコマンドに応答すると、コマンドがスレーブ ノードに送信されるだけでなく、レプリケーション バックログ バッファーにも書き込まれます。
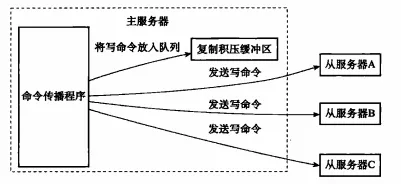 レプリケーション バックログ バッファ
レプリケーション バックログ バッファ
したがって、メイン サーバーのレプリケーション バックログ バッファには、最近伝播された書き込みコマンドの一部が格納されます。 、レプリケーション バックログ バッファーは、各バイトに対応するレプリケーション オフセットを記録します。したがって、スレーブ サーバーがマスター サーバーに再接続すると、スレーブ サーバーは、psync コマンドを介して、独自のレプリケーション オフセット offset をマスター サーバーに送信します。マスター サーバーは、このレプリケーション オフセットを使用して、スレーブ サーバー上で実行するデータ同期操作を決定します。
- スレーブ サーバーのレプリケーション オフセット後のデータがレプリケーション バックログ バッファーにまだ存在する場合、マスター サーバーはスレーブ サーバー上で部分的なレプリケーション操作を実行します。
如果从服务器的复制偏移量之后的数据不存在于复制积压缓冲区里面,那么主服务器将对从服务器执行全量复制操作
3、服务器运行ID
每个 Redis 节点启动后都会动态分配一个 40 位的十六进制字符串作为运行 ID,运行 ID 的主要作用是用来唯一识别 Redis 节点,我们可以使用 info server 命令来查看
127.0.0.1:6379> info server # Server redis_version:5.0.5 redis_git_sha1:00000000 redis_git_dirty:0 redis_build_id:2ef1d58592147923 redis_mode:standalone os:Linux 3.10.0-957.27.2.el7.x86_64 x86_64 arch_bits:64 multiplexing_api:epoll atomicvar_api:atomic-builtin gcc_version:4.8.5 process_id:25214 run_id:7b987673dfb4dfc10dd8d65b9a198e239d20d2b1 tcp_port:6379 uptime_in_seconds:14382 uptime_in_days:0 hz:10 configured_hz:10 lru_clock:14554933 executable:/usr/local/redis-5.0.5/src/./redis-server config_file:/usr/local/redis-5.0.5/redis.conf 127.0.0.1:6379>
这里面有一个run_id 字段就是服务器运行的ID
在熟悉这几个概念之后,我们可以一起探讨 psync 命令的运行流程,具体如下图所示:
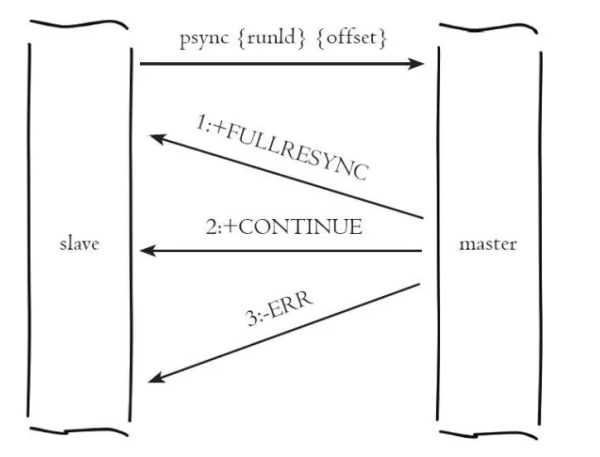
psync 运行流程
psync 命令的逻辑比较简单,整个流程分为两步:
1、从节点发送 psync 命令给主节点,参数 runId 是当前从节点保存的主节点运行ID,参数offset是当前从节点保存的复制偏移量,如果是第一次参与复制则默认值为 -1。
2、主节点接收到 psync 命令之后,会向从服务器返回以下三种回复中的一种:
回复 +FULLRESYNC {runId} {offset}:表示主服务器将与从服务器执行一次全量复制操作,其中 runid 是这个主服务器的运行 id,从服务器会保存这个id,在下一次发送 psync 命令时使用,而 offset 则是主服务器当前的复制偏移量,从服务器会将这个值作为自己的初始化偏移量
回复 +CONTINUE:那么表示主服务器与从服务器将执行部分复制操作,从服务器只要等着主服务器将自己缺少的那部分数据发送过来就可以了
回复 +ERR:那么表示主服务器的版本低于 redis 2.8,它识别不了 psync 命令,从服务器将向主服务器发送 sync 命令,并与主服务器执行全量复制
7、命令持续复制
当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。主从服务器之间的连接不会中断,因为主节点会持续发送写命令到从节点,以确保主从数据的一致性。
经过上面 7 步就完成了主从服务器之间的数据同步,由于这篇文章的篇幅比较长,关于全量复制和部分复制的细节就不介绍了,全量复制就是将主节点的当前的数据生产 RDB 文件,发送给从服务器,从服务器再从本地磁盘加载,这样当文件过大时就需要特别大的网络开销,不然由于数据传输比较慢会导致主从数据延时较大,部分复制就是主服务器将复制积压缓冲区的写命令直接发送给从服务器。
心跳检测
心跳检测是发生在主从节点在建立复制后,它们之间维护着长连接并彼此发送心跳命令,便以后续持续发送写命令,主从心跳检测如下图所示:
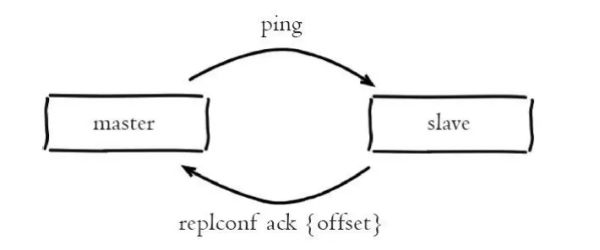
主从心跳检测
主从节点彼此都有心跳检测机制,各自模拟成对方的客户端进行通信,主从心跳检测的规则如下:
默认情况下,主节点会每隔 10 秒向从节点发送 ping 命令,以检测从节点的连接状态和是否存活。可通过修改 redis.conf 配置文件里面的 repl-ping-replica-period 参数来控制发送频率
从节点在主线程中每隔 1 秒发送 replconf ack {offset} 命令,给主节点 上报自身当前的复制偏移量,这条命令除了检测主从节点网络之外,还通过发送复制偏移量来保证主从的数据一致
主节点根据 replconf 命令判断从节点超时时间,体现在 info replication 统 计中的 lag 信息中,我们在主服务器上执行 info replication 命令:
127.0.0.1:6379> info replication # Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6480,state=online,offset=25774,lag=0 master_replid:c62b6621e3acac55d122556a94f92d8679d93ea0 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:25774 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:25774 127.0.0.1:6379>
可以看出 slave0 字段的值最后面有一个 lag,lag 表示与从节点最后一次通信延迟的秒数,正常延迟应该在 0 和 1 之间。如果超过 repl-timeout 配置的值(默认60秒),则判定从节点下线并断开复制客户端连接,如果从节点重新恢复,心跳检测会继续进行。
主从拓扑架构
Redis 的主从拓扑结构可以支持单层或多层复制关系,根据拓扑复杂性可以分为以下三种:一主一从、一主多从、树状主从架构。
一主一从结构
一主一从结构是最简单的复制拓扑结构,我们前面搭建的就是一主一从的架构,架构如图所示:
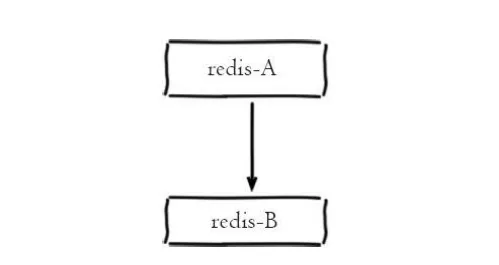
一主一从架构
1 つのマスターと 1 つのスレーブ アーキテクチャ
は、マスター ノードがダウンしたときにスレーブ ノードからのフェイルオーバー サポートを提供するために使用されます。アプリケーションの書き込みコマンドの同時実行性が高く、永続性が必要な場合に使用されます。を使用すると、スレーブ ノードでのみ AOF を有効にすることができます。これにより、データのセキュリティが確保されるだけでなく、マスター ノードでの永続性によるパフォーマンスの干渉も回避されます。ただし、ここには注意が必要な落とし穴があります。つまり、マスター ノードが永続化機能をオフにする場合、マスター ノードがオフラインになった場合に自動再起動を回避する必要があります。マスターノードは以前に永続化機能をオンにしていないため、自動再起動後はデータセットは空になりますが、このときスレーブノードがマスターノードのコピーを継続すると、スレーブノードのデータもクリアされます。持続力が失われます。安全なアプローチは、スレーブ ノードで smileof no one を実行してマスター ノードとのレプリケーション関係を切断し、その後マスター ノードを再起動してこの問題を回避することです。
1 つのマスターと複数のスレーブのアーキテクチャ 1 つのマスターと複数のスレーブのアーキテクチャは、スター トポロジとも呼ばれます。1 つのマスターと複数のスレーブのアーキテクチャを次の図に示します。
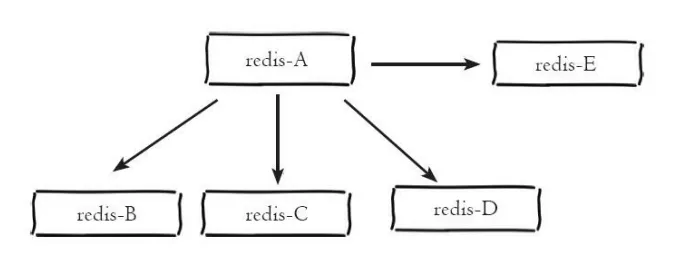
一マスター-複数スレーブ アーキテクチャ
1 マスター-複数スレーブ アーキテクチャでは、読み取りと書き込みを分離して、マスター サーバーへの負荷を軽減できます。読み取りの割合が大きいシナリオの場合は、読み取りコマンドを使用します。をスレーブ ノードに送信して、マスター ノードへの圧力を共有することができます。同時に、日々の開発中にキーやソートなどの時間のかかる読み取りコマンドを実行する必要がある場合は、それらをスレーブ ノードの 1 つで実行することで、遅いクエリがマスター ノードをブロックして影響を与えるのを防ぐことができます。オンラインサービスの安定性。書き込みの同時実行性が高いシナリオでは、複数のスレーブ ノードによりマスター ノードが書き込みコマンドを複数回送信することになり、ネットワーク帯域幅が過剰に消費され、マスター ノードの負荷も増加してサービスの安定性に影響します。
ツリー マスター/スレーブ アーキテクチャ
ツリー マスター/スレーブ アーキテクチャは、ツリー トポロジ アーキテクチャとも呼ばれます。ツリー マスター/スレーブ アーキテクチャを次の図に示します。
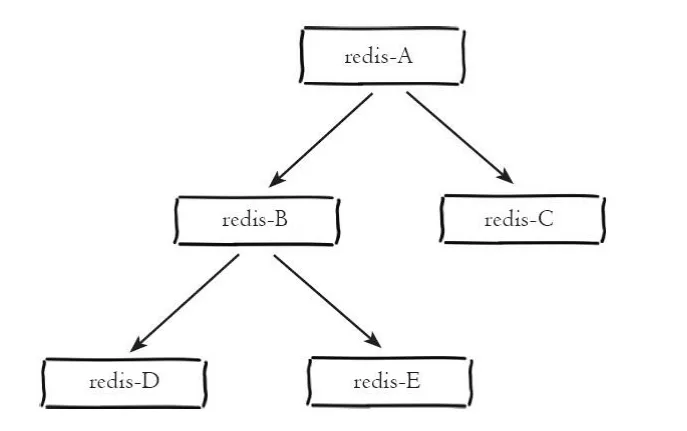
ツリー状のマスター/スレーブ アーキテクチャ
ツリー状のマスター/スレーブ アーキテクチャにより、スレーブ ノードはマスター セクションのデータをコピーするだけでなく、他のスレーブ ノードのマスター ノードとしても機能し、下位レベルへのコピーを続行します。ワンマスターマルチスレーブアーキテクチャの欠点を解決し、マスターノードの負荷とスレーブノードに送信する必要があるデータ量を効果的に削減できるレプリケーション中間層を導入します。アーキテクチャ図に示すように、データはノード A に書き込まれた後、ノード B および C に同期されます。その後、ノード B はデータをノード D および E に同期します。データはレイヤーごとに複製されます。マスター ノードのパフォーマンスへの干渉を避けるために、負荷圧力を軽減するために複数のスレーブ ノードを搭載する必要がある場合、マスター ノードはツリー マスター/スレーブ構造を採用できます。
以上がRedis のマスター/スレーブ アーキテクチャを確立するにはどのような方法がありますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7471
7471
 15
1377
52
77
11
19
30
15
1377
52
77
11
19
30

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
Redisはハッシュテーブルを使用してデータを保存し、文字列、リスト、ハッシュテーブル、コレクション、注文コレクションなどのデータ構造をサポートします。 Redisは、スナップショット(RDB)を介してデータを維持し、書き込み専用(AOF)メカニズムを追加します。 Redisは、マスタースレーブレプリケーションを使用して、データの可用性を向上させます。 Redisは、シングルスレッドイベントループを使用して接続とコマンドを処理して、データの原子性と一貫性を確保します。 Redisは、キーの有効期限を設定し、怠zyな削除メカニズムを使用して有効期限キーを削除します。
 Redis-Serverが見つからない場合はどうすればよいですか
Apr 10, 2025 pm 06:54 PM
Redis-Serverが見つからない場合はどうすればよいですか
Apr 10, 2025 pm 06:54 PM
Redis-Serverが見つからない問題を解決するための手順:インストールを確認して、Redisが正しくインストールされていることを確認します。環境変数Redis_hostとredis_portを設定します。 Redis Server Redis-Serverを起動します。サーバーがRedis-Cli pingを実行しているかどうかを確認します。
 Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示するには、3つの方法があります。キーコマンドを使用して、指定されたパターンに一致するすべてのキーを返します。スキャンコマンドを使用してキーを繰り返し、キーのセットを返します。情報コマンドを使用して、キーの総数を取得します。
 Redisのバージョン番号を表示する方法
Apr 10, 2025 pm 05:57 PM
Redisのバージョン番号を表示する方法
Apr 10, 2025 pm 05:57 PM
Redisバージョン番号を表示するには、次の3つの方法を使用できます。(1)情報コマンドを入力し、(2) - versionオプションでサーバーを起動し、(3)構成ファイルを表示します。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redis Zsetの使用方法
Apr 10, 2025 pm 07:27 PM
Redis Zsetの使用方法
Apr 10, 2025 pm 07:27 PM
Redis Orderedセット(ZSET)は、並べ替えられた要素を保存し、関連するスコアでソートするために使用されます。 zsetを使用する手順には次のものがあります。1。zsetを作成します。 2。メンバーを追加します。 3.メンバースコアを取得します。 4。ランキングを取得します。 5.ランキング範囲のメンバーを取得します。 6.メンバーを削除します。 7.要素の数を取得します。 8。スコア範囲のメンバーの数を取得します。
