

Redis でホット データとコールド データの識別と交換を実現する方法

背景
Redis ハイブリッド ストレージ製品は、Alibaba Cloud が独自に開発したハイブリッド ストレージ製品であり、Redis プロトコルおよび機能と完全な互換性があります。
コールド データの一部をディスクに保存することで、ほとんどのアクセス パフォーマンスが低下しないようにしながら、ユーザー コストが大幅に削減され、Redis 単一インスタンスのデータ量のメモリ制限を超えます。
その中でも、ホット データとコールド データの識別と交換は、ハイブリッド ストレージ製品のパフォーマンスの重要な要素です。
ホット データとコールド データの定義
Redis ハイブリッド ストレージでは、ディスクに対するメモリの比率はユーザーが自由に選択できます:
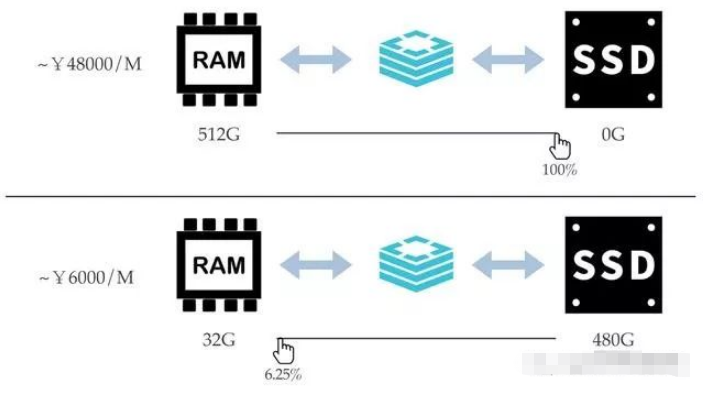
- キー アクセス頻度は、価値。
- KV データベースとして、通常のアクセス要求では、まずキーを検索して、キーが存在するかどうかを確認する必要があります。キーが存在しないことを確認するには、次のセットを確認する必要があります。すべてのキーを何らかの形式で。メモリ内データ構造のすべてのキー値を保持すると、検索速度が純粋なメモリ データ構造の場合とまったく同じであることが保証されます。
- キーのサイズ比率は非常に低いです。
- 一般的なビジネスモデルでは、通常の文字列型であっても、そのValueはKeyの数倍となるのが一般的です。 Set、List、Hash などのコレクション オブジェクトの場合、すべてのメンバーを合計して構成される値はキーよりも数桁大きくなります。
- 不均一なデータ アクセスとホットスポット データの存在。
- メモリがすべてのデータを保存するには十分ではなく、値が大きい (キーに比べて)

ホット データ ->コールド データ
非同期メソッド:- メインスレッドはメモリが近くなったときにデータを生成します一連のデータ交換タスク;
- バックグラウンド スレッドはこれらのデータ交換タスクを実行し、完了後にメイン スレッドに通知します;
- メイン スレッドの更新 メモリ内の値を解放し、メモリ内のデータ ディクショナリの値を単純なメタ情報に更新します;
- 同期方法:
コールド データ -> ホット データ
非同期メソッド:- メインスレッドは、コマンドを実行する前にまずコマンドを判断します。関係するすべての値がメモリ内にあるかどうか;
- そうでない場合は、データ読み込みタスクを生成し、クライアントを一時停止し、メインスレッドは他のクライアント要求の処理を続行します。
- メイン スレッドはメモリ内のデータ ディクショナリの値を更新し、以前に一時停止されたクライアントをウェイクアップし、そのリクエストを処理します。
- 同期方法:
- Lua スクリプトでは、特定のコマンドの実行フェーズ中に、値がディスクに保存されていることが判明した場合、 、メインスレッドがそれを直接実行します。データ読み込みタスクにより、Lua スクリプトとコマンドのセマンティクスが変更されないことが保証されます。
以上がRedis でホット データとコールド データの識別と交換を実現する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7513
7513
 15
1378
52
79
11
19
64
15
1378
52
79
11
19
64

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示するには、3つの方法があります。キーコマンドを使用して、指定されたパターンに一致するすべてのキーを返します。スキャンコマンドを使用してキーを繰り返し、キーのセットを返します。情報コマンドを使用して、キーの総数を取得します。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 Redisでサーバーを開始する方法
Apr 10, 2025 pm 08:12 PM
Redisでサーバーを開始する方法
Apr 10, 2025 pm 08:12 PM
Redisサーバーを起動する手順には、以下が含まれます。オペレーティングシステムに従ってRedisをインストールします。 Redis-Server(Linux/Macos)またはRedis-Server.exe(Windows)を介してRedisサービスを開始します。 Redis-Cli ping(Linux/macos)またはRedis-Cli.exePing(Windows)コマンドを使用して、サービスステータスを確認します。 Redis-Cli、Python、node.jsなどのRedisクライアントを使用して、サーバーにアクセスします。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
