

MySQL の制約は何ですか?

1. 概要
概念: 制約はテーブル内のフィールドに作用するルールであり、テーブル内のストレージを制限するために使用されます。テーブル データ。
目的: データベース内のデータの正確性、有効性、整合性を確認します。
カテゴリ:

注: 制約はテーブル内のフィールドに作用し、テーブルを作成できます。 /テーブルを変更するときに制約を追加します。
2. 制約のデモンストレーション
データベース内の一般的な制約と、その制約に関連するキーワードを紹介しました。では、テーブルの作成および変更時にこれらの制約をどのように指定すればよいでしょうか?次に、事例を通じてそれを実証していきます。
ケース要件: 要件に従ってテーブル構造の作成を完了します。要件は次のとおりです:
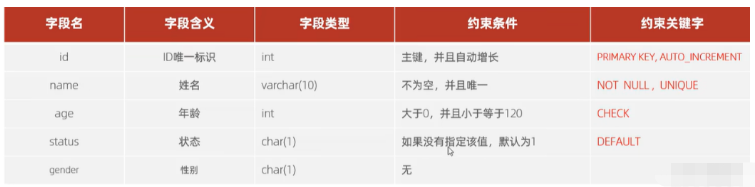
##対応するテーブル作成ステートメントは次のとおりです:
CREATE TABLE tb_user ( id INT AUTO_INCREMENT PRIMARY KEY COMMENT 'ID唯一标识', NAME VARCHAR ( 10 ) NOT NULL UNIQUE COMMENT '姓名', age INT CHECK ( age > 0 && age <= 120 ) COMMENT '年龄', STATUS CHAR ( 1 ) DEFAULT '1' COMMENT '状态', gender CHAR ( 1 ) COMMENT '性别' );
(1) まず、データを 3 つ追加しました。
insert into tb_user(name,age,status,gender) values ('Tom1',19,'1','男'),('Tom2',25,'0','男'); insert into tb_user(name,age,status,gender) values ('Tom3',19,'1','男');
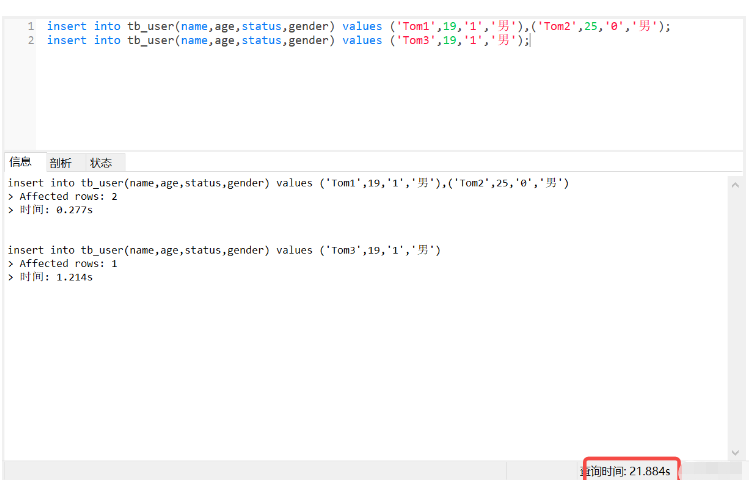
(2) テスト名 NOT NULL
insert into tb_user(name,age,status,gender) values (null,19,'1','男');

上で追加したデータには既に Tom3 が含まれているため、再度追加すると直接エラーが報告されます。
insert into tb_user(name,age,status,gender) values ('Tom3',19,'1','男');
 エラーが報告されていますが、この時点でデータを追加すると現象が見つかります。
エラーが報告されていますが、この時点でデータを追加すると現象が見つかります。
insert into tb_user(name,age,status,gender) values ('Tom4',80,'1','男');
明らかに自己増加IDですが、4がありません。理由は、自己増加ID申請後にUNIQUEをデータベースに登録できる状態になっているためです。は、最初にデータベースに値があるかどうかを確認します。同じ名前の値があります。存在する場合、新規追加は失敗します。新規追加は失敗しますが、自動インクリメント ID は適用されています。
逆に、null 名をテストしたばかりのときは、最初から空であると判断しており、まだ ID を申請する段階に達していなかったので、ID を申請しませんでした。 。
空かどうかを判断します ->> 自動インクリメント ID を適用します ->> 既存の値が存在するかどうかを判断します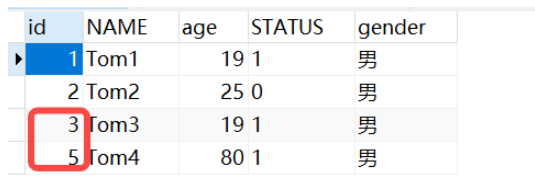 概要: 新規の場合 追加された名前が空ではなく、以前の既存のデータと同じである場合、この時点では新規追加は失敗しますが、主キー ID には適用されます。
概要: 新規の場合 追加された名前が空ではなく、以前の既存のデータと同じである場合、この時点では新規追加は失敗しますが、主キー ID には適用されます。
年齢は 0 より大きく 120 以下でなければならないと設定します。そうでない場合、保存は失敗します。
age int check (age > 0 && age <= 120) COMMENT '年龄' ,
insert into tb_user(name,age,status,gender) values ('Tom5',-1,'1','男'); insert into tb_user(name,age,status,gender) values ('Tom5',121,'1','男');
STATUS CHAR ( 1 ) DEFAULT '1' COMMENT '状态',
insert into tb_user(name,age,gender) values ('Tom5',120,'男');
主キーの自動インクリメント
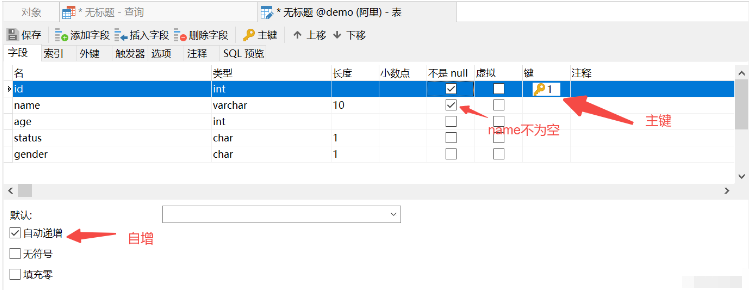 名前の一意性制約
名前の一意性制約
 ステータスのデフォルトは次のとおりです1
ステータスのデフォルトは次のとおりです1
#3. 外部キー制約
はデータの一貫性と整合性を確保するために、2 つのテーブル内のデータ間に接続が確立されます。
#例を見てみましょう:
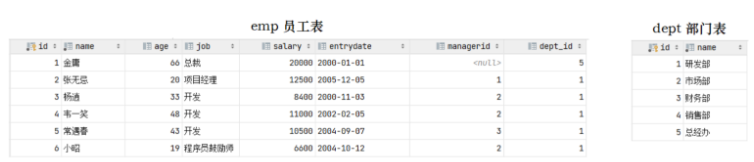
#左側の emp テーブルは、基本的なデータを格納する従業員テーブルです。従業員の ID、名前、年齢、役職、給与、入社日、上司 ID、部門 ID などの従業員に関する情報。従業員情報には部門の ID dept_id が格納され、部門の ID は関連する ID の主キー ID になります。部門テーブル dept. emp テーブルの dept_id は外部キーであり、別のテーブルの主キーに関連付けられています。
2、 不使用外键有什么影响
通过上面的示例,我们分别来演示 添加外键 和不添加外键的区别,首先来看不添加 外键 对数据有什么影响:
准备数据:
CREATE TABLE dept ( id INT auto_increment COMMENT 'ID' PRIMARY KEY, NAME VARCHAR ( 50 ) NOT NULL COMMENT '部门名称' ) COMMENT '部门表'; INSERT INTO dept (id, name) VALUES (1, '研发部'), (2, '市场部'),(3, '财务部'), (4, '销售部'), (5, '总经办'); CREATE TABLE emp ( id INT auto_increment COMMENT 'ID' PRIMARY KEY, NAME VARCHAR ( 50 ) NOT NULL COMMENT '姓名', age INT COMMENT '年龄', job VARCHAR ( 20 ) COMMENT '职位', salary INT COMMENT '薪资', entrydate date COMMENT '入职时间', managerid INT COMMENT '直属领导ID', dept_id INT COMMENT '部门ID' ) COMMENT '员工表'; INSERT INTO emp (id, name, age, job,salary, entrydate, managerid, dept_id) VALUES (1, '金庸', 66, '总裁',20000, '2000-01-01', null,5), (2, '张无忌', 20, '项目经理',12500, '2005-12-05', 1,1), (3, '杨逍', 33, '开发', 8400,'2000-11-03', 2,1), (4, '韦一笑', 48, '开 发',11000, '2002-02-05', 2,1), (5, '常遇春', 43, '开发',10500, '2004-09-07', 3,1), (6, '小昭', 19, '程 序员鼓励师',6600, '2004-10-12', 2,1);
接下来,我们可以做一个测试,删除id为1的部门信息。
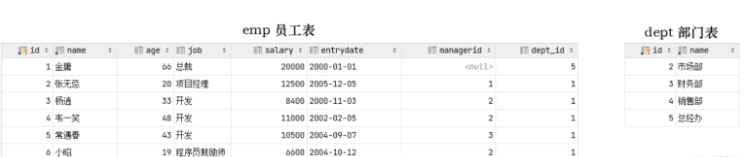
结果,我们看到删除成功,而删除成功之后,部门表不存在id为1的部门,而在emp表中还有很多的员工,关联的为id为1的部门,此时就出现了数据的不完整性。 而要想解决这个问题就得通过数据库的外键约束。
正常开发当中有时候会通过业务代码来控制数据的不完整性,例如删除部门的时候会先根据部门id去查看一下有没有对应的员工表,如果有则删除失败,没有则删除成功。
3、 添加外键的语法
可以在创建表的时候直接添加外键,也可以对现已存在的表添加外键。
(1)方式一
CREATE TABLE 表名( 字段名 数据类型, ... [CONSTRAINT] [外键名称] FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名) );
使用示例:
CREATE TABLE emp ( id INT auto_increment COMMENT 'ID' PRIMARY KEY, NAME VARCHAR ( 50 ) NOT NULL COMMENT '姓名', age INT COMMENT '年龄', job VARCHAR ( 20 ) COMMENT '职位', salary INT COMMENT '薪资', entrydate date COMMENT '入职时间', managerid INT COMMENT '直属领导ID', dept_id INT COMMENT '部门ID', CONSTRAINT fk_emp_dept_id FOREIGN KEY (dept_id) REFERENCES dept (id) ) COMMENT '员工表';
也可以省略掉CONSTRAINT fk_emp_dept_id 这样mysql就会自动给我们起外键名称。
方式二:对现存在的表添加外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名) ;
使用示例:
alter table emp add constraint fk_emp_dept_id FOREIGN KEY (dept_id) REFERENCES dept(id);
方式三:Navicat添加外键

删除外键:
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
使用示例:
alter table emp drop foreign key fk_emp_dept_id;
4、 删除/更新行为
我们将在父表数据删除时发生的限制行为称为删除/更新行为,此行为是在添加外键之后发生的。具体的删除/更新行为有以下几种:

默认的MySQL 8.0.27版本中,RESTRICT是用于删除和更新行的行为!但是,不同的版本可能会有不同的行为

具体语法为:
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段) REFERENCES 主表名 (主表字段名) ON UPDATE CASCADE ON DELETE CASCADE;
就是比原先添加外键后面多了这些ON UPDATE CASCADE ON DELETE CASCADE,代表的是更新时采用CASCADE ,删除时也采用CASCADE
5、 演示删除/更新行为
(1)演示RESTRICT
在对父表中的记录进行删除或更新操作时,需要先检查该记录是否存在关联的外键,如果存在,则不允许执行删除或更新操作。 (与 NO ACTION 一致) 默认行为
首先要添加外键,默认是RESTRICT行为!
alter table emp add constraint fk_emp_dept_id FOREIGN KEY (dept_id) REFERENCES dept(id);
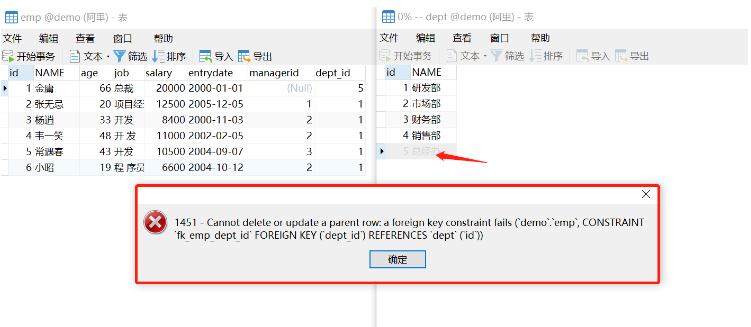
删除父表中id为5的记录时,会因为emp表中的dept_id存在5而报错。假如要更新id也同样会报错的!
(2)演示CASCADE
当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有,则
也删除/更新外键在子表中的记录。
删除外键的语法:
ALTER TABLE 表名 DROP FOREIGN KEY 外键约束名;
删除外键的示例:
alter table emp drop foreign key fk_emp_dept_id;
指定外键的删除更新行为为cascade
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update cascade on delete cascade ;
修改父表id为1的记录,将id修改为6

我们发现,原来在子表中dept_id值为1的记录,现在也变为6了,这就是cascade级联的效果。
在一般的业务系统中,不会修改一张表的主键值。
删除父表id为6的记录

我们发现,父表的数据删除成功了,但是子表中关联的记录也被级联删除了。
(3)演示SET NULL
当在父表中删除对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(这就要求该外键允许取null)。
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update set null on delete set null ;
在执行测试之前,我们需要先移除已创建的外键 fk_emp_dept_id。然后再通过数据脚本,将emp、dept表的数据恢复了。
接下来,我们删除id为1的数据,看看会发生什么样的现象。
我们发现父表的记录是可以正常的删除的,父表的数据删除之后,再打开子表 emp,我们发现子表emp的dept_id字段,原来dept_id为1的数据,现在都被置为NULL了。
これは、SET NULL の削除/更新動作の影響です。
4. 主キー ID として自動インクリメントまたは uuid を使用する方が良いですか?
mysql でテーブルを設計する場合、mysql は uuid または不連続で非繰り返しのスノーフレークを使用しないことを公式に推奨しています。 id (長い形で一意) ですが、主キー ID を継続的に増やすことをお勧めします。公式の推奨事項は auto_increment です。では、なぜ uuid の使用が推奨されないのですか? uuid を使用するデメリットは何ですか?
1. uuid、自動インクリメント ID、乱数挿入効率のテスト
最初に 3 つのテーブルを作成します、user_auto_key は自動インクリメント テーブルを表し、user_uuid はuuid には ID が保存され、random_key はスノーフレーク ID であるテーブル ID を表します。次に、jdbc に接続してバッチでデータを挿入します。テスト結果は次のとおりです:
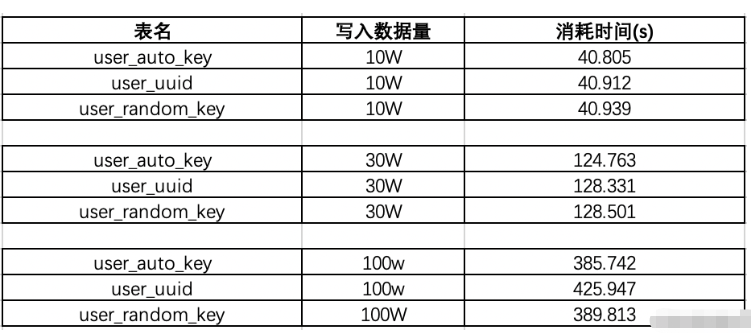
既存のデータ量が 130W の場合: もう一度 10w のデータを挿入して確認してみましょう。結果:

# データ量が100W程度の場合、uuidの挿入効率が最低となり、130Wのデータを追加した後であることがわかります。このシーケンスにより、uudi の時間が再び急落します。時間使用量の全体的な効率ランキングは次のとおりです: auto_key>random_key>uuid、uuid の効率が最も低くなります
2。自動インクリメント ID を使用するデメリット
1. 他の人があなたのデータベースをクロールすると、データベースの自動インクリメント ID に基づいてビジネスの成長情報を取得できるため、ビジネスの状況を簡単に分析できます
2. 同時実行負荷が高い場合、 InnoDB では、主キーに従って挿入するときに明らかなロック競合が発生します。主キーの上限は、すべての挿入がここで行われるため、競合のホット スポットになります。また、同時挿入によりギャップ ロックの競合が発生します。
3. Auto_Increment ロック メカニズムにより、自動インクリメント ロックの取得が発生し、特定のパフォーマンス損失が発生します。
4. 自動インクリメント ID にデータ移行が伴う場合は、非常に面倒です。
5. そして、サブデータベースやサブテーブルになると、自動的にIDを増やすのはかなり面倒です。
3. uuid を使用するデメリット
uuid には連続する自己増加 ID に関するルールがないため、新しい行の値が前の行の値より必ずしも大きくなるわけではありません。主キーの値が大きくなったため、InnoDB は常にインデックスの末尾に新しい行を挿入できるわけではなく、新しい行に適した新しい場所を見つけて新しい領域を割り当てる必要がありました。このプロセスでは複数の追加操作を実行する必要があり、データの乱れによりデータが分散し、次の問題が発生する可能性があります:
1. 書き込まれたターゲット ページはディスクにフラッシュされて移動された可能性があります。キャッシュからアップ さらに、innodb は挿入する前にターゲット ページをディスクから見つけてメモリに読み込む必要があるため、大量のランダムな IO
2 が発生します。書き込みがカオスであるため、innodb は新しい行にスペースを割り当てるためにページ分割操作を頻繁に実行する必要があります。ページ分割により大量のデータが移動します。一度に少なくとも 3 ページを変更する必要があります。
3. 頻繁なページ分割により、分割するとページがまばらになり、不規則に埋まり、最終的にはデータの断片化につながります。
ページの分割と断片化の問題、uuid が実際にこの問題の原因となります。 , しかし、Snowflake はこの問題を解決できます。Snowflake アルゴリズムは当然シーケンシャルであり、新しく挿入される ID は最大でなければなりません。そのため、Snowflake アルゴリズムを使用することは非常に良い選択だと思います。
5. 実際の開発では外部キーの使用をできる限り少なくする
主キーとインデックスは不可欠であり、データの取得速度を最適化するだけでなく、開発者が他のキーからデータを取得する手間を省くことができます。仕事。
競合の焦点: データベース設計に外部キーが必要かどうか。ここには 2 つの質問があります:
1 つはデータベース データの整合性と一貫性を確保する方法です;
2 つ目は、最初の質問がパフォーマンスに与える影響です。
ここではポジティブとネガティブの2つの観点に分けてご紹介しますので、ご参考までに!
1. 肯定的な視点
1. プログラムが 100% のデータ整合性を保証することは難しいため、データベース自体がデータの一貫性と整合性を保証し、より信頼性が高くなります。データベース サーバーがクラッシュしたり、その他の問題が発生したりした場合でも、キーによってデータの一貫性と完全性を最大限に確保できます。
2. 主キーと外部キーを使用してデータベースを設計すると、ER 図の読みやすさが向上しますが、これはデータベース設計において非常に重要です。
3. 外部キーによってビジネス ロジックがある程度説明されると、設計が思慮深く、具体的で包括的なものになります。
データベースとアプリケーションの間には 1 対多の関係があります。アプリケーション A はデータの一部の整合性を維持します。システムが大きくなると、アプリケーション B が追加されます。2 つのアプリケーション A と B開発方法が異なる場合があります。チームがそれを行います。データの整合性を確保するためにどのように調整するか、1 年後に新しい C アプリケーションが追加された場合はどう対処するか?
2. 反対の見方
1. データの整合性を確保するためにトリガーまたはアプリケーションを使用できる
2. 主キー/外部キーの過度の強調または使用により、開発時間が増加します。テーブルが多すぎるなどの問題が発生する
3. 外部キーを使用しない場合、データ管理はシンプルで操作が簡単で、パフォーマンスが高くなります (挿入、更新、インポート時のインポートやエクスポートなどの操作が高速になります)。データの削除)
大規模なデータベースでは外部キーについてさえ考えないでください。想像してみてください。プログラムは毎日何百万ものレコードを挿入する必要があります。外部キー制約がある場合、レコードが修飾されているかどうかを毎回スキャンする必要があります。通常は、フィールドに外部キーがあるだけではないため、スキャンの数は指数関数的に増加します。私のプログラムの 1 つは 3 時間で完了しましたが、外部キーを追加すると 28 時間かかります。
3. 結論
1. 大規模システム (パフォーマンス要件が低く、セキュリティ要件が高い) では外部キーを使用し、大規模システム (パフォーマンス要件が高く、セキュリティ要件は自分で制御する) では、外部キーを使用します。外部キーは必要ありません。小規模なシステムの場合は、外部キーを使用することをお勧めします。
2. 外部キーは適切に使用し、過度に追求しないようにしましょう
データの一貫性と完全性を確保するために、外部キーを使用せずにプログラムで制御することができます。この時点で、データ保護を実装するためのレイヤーを作成する必要があります。その後、このレイヤーを通じてデータベースのさまざまなアプリケーションにアクセスできるようになります。
次の点に注意してください:
MySQL では外部キーの使用が許可されていますが、整合性チェックの目的で、この機能は InnoDB テーブル タイプを除くすべてのテーブル タイプで無視されます。これは奇妙に思えるかもしれませんが、実際にはごく普通のことです。データベース内のすべての外部キーの挿入、更新、削除のたびに整合性チェックを実行することは、時間とリソースを消費するプロセスであり、特に、または複合キーを処理する場合にはパフォーマンスに影響を及ぼす可能性があります。巻線接続の数。したがって、ユーザーは表に基づいて特定のニーズに合ったものを選択できます。
したがって、より良いパフォーマンスが必要で整合性チェックが必要ない場合は、MyISAM テーブル タイプの使用を選択できます。MySQL で参照整合性に基づいてテーブルを構築し、良好なパフォーマンスを維持したい場合は、パフォーマンスを向上させるには、テーブル構造を innoDB タイプ
として選択するのが最善です。以上がMySQL の制約は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7569
7569
 15
1386
52
87
11
28
107
15
1386
52
87
11
28
107

 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 Redis ExporterサービスでRedis Dropletを監視します
Apr 10, 2025 pm 01:36 PM
Redis ExporterサービスでRedis Dropletを監視します
Apr 10, 2025 pm 01:36 PM
Redisデータベースの効果的な監視は、最適なパフォーマンスを維持し、潜在的なボトルネックを特定し、システム全体の信頼性を確保するために重要です。 Redis Exporter Serviceは、Prometheusを使用してRedisデータベースを監視するために設計された強力なユーティリティです。 このチュートリアルでは、Redis Exporterサービスの完全なセットアップと構成をガイドし、監視ソリューションをシームレスに構築します。このチュートリアルを研究することにより、完全に動作する監視設定を実現します
