

DockerとCanalをベースにしたMySQLのリアルタイム増分データ送信機能の実装方法

運河の紹介
運河の歴史的起源
当初、アリババ社は杭州と米国で設立されました。データベース インスタンスはすべてのコンピューター ルームにデプロイされますが、ビジネスではコンピューター ルーム間でデータを同期する必要があるため、主に増分変更を取得するトリガーに基づいた canal が誕生しました。 2010 年から、アリババは同期のために増分変更データを取得するデータベース ログ分析を徐々に試み始め、その結果、増分サブスクリプション ビジネスと消費ビジネスが生まれました。
canal でサポートされている現在のデータ ソースの mysql バージョンには、5.1.x、5.5.x、5.6.x、5.7.x、8.0.x が含まれます。
canal のアプリケーション シナリオ
現在、ログの増分サブスクリプションと消費に基づくビジネスには主に次のものがあります。
データベースの増分に基づくログ分析、増分データのサブスクリプションと消費を提供
データベース ミラーリング データベースのリアルタイム バックアップ
インデックス構築とリアルタイム メンテナンス (分割異種混合)インデックス、転置インデックスなど)
ビジネス キャッシュの更新
ビジネス ロジックによる増分データ処理
-
canal の動作原理
canal の原理を紹介する前に、まず mysql のマスター/スレーブ レプリケーションの原理を理解しましょう。
mysql マスター/スレーブ レプリケーションの原理
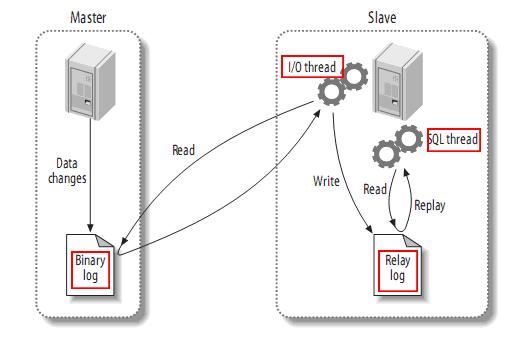
- ##mysql マスターはデータ変更操作をバイナリ ログに書き込みますバイナリ ログ記録されたコンテンツはバイナリ ログ イベントと呼ばれ、show binlog events コマンドで表示できます。
- mysql スレーブは、マスターのバイナリ ログ内のバイナリ ログ イベントをそのリレー ログ リレーにコピーします。 log
- mysql スレーブはリレー ログ内のイベントを再読み取りして実行し、データの変更を独自のデータベース テーブルにマッピングします
Canal の動作原理
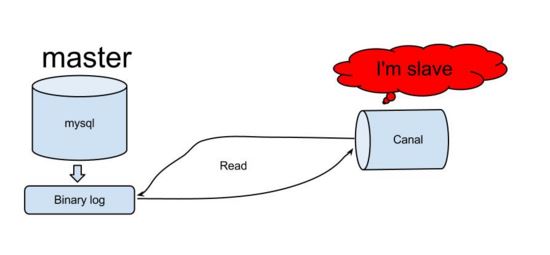
- ##canal は、mysql スレーブの対話プロトコルをシミュレートし、mysql スレーブを偽装します。ダンプ プロトコルを mysql マスターに送信します
- mysql マスターはダンプ リクエストを受信し、バイナリ ログをスレーブ (つまり canal) にプッシュし始めます
- canal分析バイナリ ログ オブジェクト (データはバイト ストリーム)
- この原理と方法に基づいて、データベース増分ログの取得と分析を完了し、増分データのサブスクリプションと消費を提供することができます。 mysql のリアルタイム増分データ転送機能を実現します。
canal はそのようなフレームワークであり、純粋な Java 言語で書かれているので、これから使い方を学び、実際の作業に適用していきます。
canal の docker 環境の準備最近コンテナ化技術が普及しているため、この記事では docker を使用して開発環境を迅速に構築しますが、従来の環境構築方法は問題ありません。 Docker コンテナ環境を構築する方法を学んだ後は、自分で環境を構築することもできます。この記事ではcanalを中心に解説しているのでdockerについてはあまり触れず、dockerの基本的な概念やコマンドの使い方を中心に紹介します。さらに多くのコンテナ技術の専門家とコミュニケーションを取りたい場合は、WeChat liyingjiese に私を追加して、「グループを追加」と発言してください。このグループには、世界中の主要企業のベスト プラクティスと最新の業界トレンドが毎週含まれています。
docker とは仮想マシン vmware を使ったことがある人は多いと思いますが、vmware を使って環境を構築する場合は、通常のシステムを用意するだけで済みます。イメージは正常にインストールされました。残りのソフトウェア環境とアプリケーション構成は、ローカル マシン上で動作するため、引き続き仮想マシン内で動作します。さらに、vmware はホスト マシンのリソースをより多く消費するため、ホスト マシンがフリーズしやすくなります。システムイメージ自体も多くのスペースを占有します。
誰もが docker を簡単に理解できるように、vmware と比較して紹介しましょう Docker は、アプリ (アプリケーション) を基盤となるものから分離する、アプリの起動、パッケージ化、および実行のためのプラットフォームを提供します。インフラ(インフラ)。 Docker の 2 つの最も重要な概念は、イメージ (vmware のシステム イメージに似ています) とコンテナー (vmware にインストールされているシステムに似ています) です。
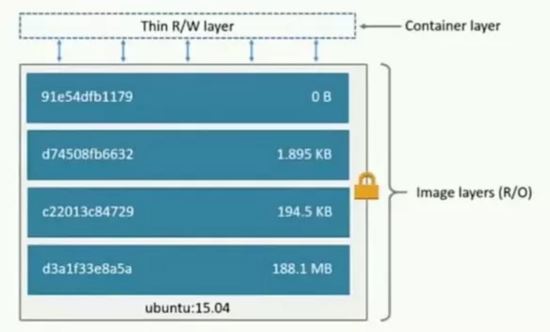
#画像 (ミラー) とは
#ファイルとメタデータのコレクション (ルート ファイルシステム)
- ##レイヤー化されており、各レイヤーはファイルを追加、変更、削除して新しい画像にすることができます 異なる画像が同じレイヤーを共有できます
- 画像自体は読み取り専用です
#コンテナとは
# #イメージから作成(コピー)
イメージ レイヤーの上にコンテナー レイヤー (読み取りおよび書き込み可能) を作成します
オブジェクト指向のアナロジー: クラスとインスタンス
イメージはアプリの保存と配布を担当し、コンテナはアプリの実行を担当します
## docker ネットワークの概要
Docker には 3 つのネットワーク タイプがあります。- bridge: ブリッジ ネットワーク。デフォルトでは、起動された docker コンテナは、docker のインストール中に作成されたブリッジ ネットワークである Bridge を使用します。docker コンテナが再起動されるたびに、対応する IP アドレスが順番に取得されます。これにより、再起動後に docker の IP アドレスが変更されます。 #none: ネットワークが指定されていません。 --network=none を使用すると、Docker コンテナは LAN IP を割り当てません。
- #host: ホスト ネットワーク。 --network=host を使用すると、Docker コンテナはネットワークをホストと共有し、両者は相互に通信できるようになります。コンテナ内のポート 8080 でリッスンする Web サービスを実行すると、コンテナはホストのポート 8080 に自動的にマッピングされます。
- カスタム ネットワークを作成します: (固定 IP を設定)
docker network create --subnet=172.18.0.0/16 mynetwork
 運河環境の構築
運河環境の構築
docker ==> docker download のダウンロードとインストールのアドレスを添付します。
運河イメージのダウンロードdocker pull canal/canal-server
:mysql イメージのダウンロード docker pull mysql
docker pull mysql
ダウンロードしたイメージの docker イメージを確認します: 
次のパス イメージmysql コンテナーと canal-server コンテナーを生成します: 
##生成mysql容器 docker run -d --name mysql --net mynetwork --ip 172.18.0.6 -p 3306:3306 -e mysql_root_password=root mysql ##生成canal-server容器 docker run -d --name canal-server --net mynetwork --ip 172.18.0.4 -p 11111:11111 canal/canal-server ## 命令介绍 --net mynetwork #使用自定义网络 --ip #指定分配ip
 mysql 構成の変更
mysql 構成の変更
以上は基本環境の下準備ですが、canalをsalveに偽装してmysqlでバイナリログを正しく取得するにはどうすればよいでしょうか?
自作の mysql の場合は、まず binlog 書き込み機能を有効にし、binlog-format
を行モードに設定し、mysql 設定ファイルを変更して bin_log を開き、find を使用する必要があります。 / -name my.cnfmy.cnf を見つけて、ファイルの内容を次のように変更します。
[mysqld] log-bin=mysql-bin # 开启binlog binlog-format=row # 选择row模式 server_id=1 # 配置mysql replaction需要定义,不要和canal的slaveid重复
mysql コンテナーを入力しますdocker exec -it mysql bash。 mysql にリンクされたアカウント canal を作成し、mysql スレーブとして権限を付与します。すでにアカウントをお持ちの場合は、直接付与できます:
mysql -uroot -proot # 创建账号 create user canal identified by 'canal'; # 授予权限 grant select, replication slave, replication client on *.* to 'canal'@'%'; -- grant all privileges on *.* to 'canal'@'%' ; # 刷新并应用 flush privileges;
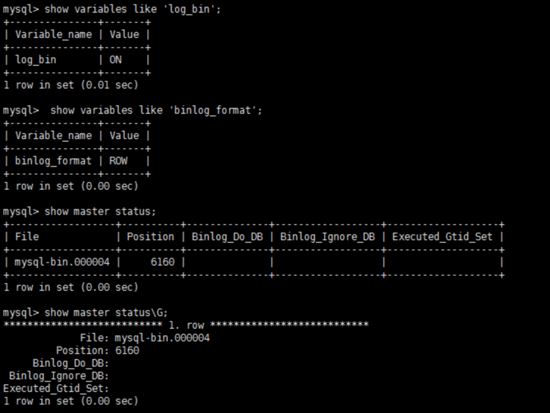
show variables like 'log_bin'; show variables like 'log_bin'; show master status;
 canal-server 構成の変更
canal-server 構成の変更
canal-server コンテナーを入力してくださいdocker exec -it canal-server bash
。canal-server 設定の編集vi canal-server/conf/example/instance.properties
詳細を設定してください。 ==>canal 設定手順。
設定手順。
canal-server コンテナを再起動docker restart canal-server
docker exec -it canal-server bash tail -100f canal-server/logs/example/example.log
この時点で、環境に関する取り組みは完了する準備が整いました。 
student.java
# 下载对镜像 docker pull elasticsearch:7.1.1 docker pull mobz/elasticsearch-head:5-alpine # 创建容器并运行 docker run -d --name elasticsearch --net mynetwork --ip 172.18.0.2 -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.1.1 docker run -d --name elasticsearch-head --net mynetwork --ip 172.18.0.5 -p 9100:9100 mobz/elasticsearch-head:5-alpine
canalconfig.java
package com.example.canal.study.pojo;
import lombok.data;
import java.io.serializable;
// @data 用户生产getter、setter方法
@data
public class student implements serializable {
private string id;
private string name;
private int age;
private string sex;
private string city;
}package com.example.canal.study.common;
import com.alibaba.otter.canal.client.canalconnector;
import com.alibaba.otter.canal.client.canalconnectors;
import org.apache.http.httphost;
import org.elasticsearch.client.restclient;
import org.elasticsearch.client.resthighlevelclient;
import org.springframework.beans.factory.annotation.value;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
import java.net.inetsocketaddress;
/**
* @author haha
*/
@configuration
public class canalconfig {
// @value 获取 application.properties配置中端内容
@value("${canal.server.ip}")
private string canalip;
@value("${canal.server.port}")
private integer canalport;
@value("${canal.destination}")
private string destination;
@value("${elasticsearch.server.ip}")
private string elasticsearchip;
@value("${elasticsearch.server.port}")
private integer elasticsearchport;
@value("${zookeeper.server.ip}")
private string zkserverip;
// 获取简单canal-server连接
@bean
public canalconnector canalsimpleconnector() {
canalconnector canalconnector = canalconnectors.newsingleconnector(new inetsocketaddress(canalip, canalport), destination, "", "");
return canalconnector;
}
// 通过连接zookeeper获取canal-server连接
@bean
public canalconnector canalhaconnector() {
canalconnector canalconnector = canalconnectors.newclusterconnector(zkserverip, destination, "", "");
return canalconnector;
}
// elasticsearch 7.x客户端
@bean
public resthighlevelclient resthighlevelclient() {
resthighlevelclient client = new resthighlevelclient(
restclient.builder(new httphost(elasticsearchip, elasticsearchport))
);
return client;
}
}public static class twotuple<a, b> {
public final a eventtype;
public final b columnmap;
public twotuple(a a, b b) {
eventtype = a;
columnmap = b;
}
}
public static list<twotuple<eventtype, map>> printentry(list<entry> entrys) {
list<twotuple<eventtype, map>> rows = new arraylist<>();
for (entry entry : entrys) {
// binlog event的事件事件
long executetime = entry.getheader().getexecutetime();
// 当前应用获取到该binlog锁延迟的时间
long delaytime = system.currenttimemillis() - executetime;
date date = new date(entry.getheader().getexecutetime());
simpledateformat simpledateformat = new simpledateformat("yyyy-mm-dd hh:mm:ss");
// 当前的entry(binary log event)的条目类型属于事务
if (entry.getentrytype() == entrytype.transactionbegin || entry.getentrytype() == entrytype.transactionend) {
if (entry.getentrytype() == entrytype.transactionbegin) {
transactionbegin begin = null;
try {
begin = transactionbegin.parsefrom(entry.getstorevalue());
} catch (invalidprotocolbufferexception e) {
throw new runtimeexception("parse event has an error , data:" + entry.tostring(), e);
}
// 打印事务头信息,执行的线程id,事务耗时
logger.info(transaction_format,
new object[]{entry.getheader().getlogfilename(),
string.valueof(entry.getheader().getlogfileoffset()),
string.valueof(entry.getheader().getexecutetime()),
simpledateformat.format(date),
entry.getheader().getgtid(),
string.valueof(delaytime)});
logger.info(" begin ----> thread id: {}", begin.getthreadid());
printxainfo(begin.getpropslist());
} else if (entry.getentrytype() == entrytype.transactionend) {
transactionend end = null;
try {
end = transactionend.parsefrom(entry.getstorevalue());
} catch (invalidprotocolbufferexception e) {
throw new runtimeexception("parse event has an error , data:" + entry.tostring(), e);
}
// 打印事务提交信息,事务id
logger.info("----------------\n");
logger.info(" end ----> transaction id: {}", end.gettransactionid());
printxainfo(end.getpropslist());
logger.info(transaction_format,
new object[]{entry.getheader().getlogfilename(),
string.valueof(entry.getheader().getlogfileoffset()),
string.valueof(entry.getheader().getexecutetime()), simpledateformat.format(date),
entry.getheader().getgtid(), string.valueof(delaytime)});
}
continue;
}
// 当前entry(binary log event)的条目类型属于原始数据
if (entry.getentrytype() == entrytype.rowdata) {
rowchange rowchage = null;
try {
// 获取储存的内容
rowchage = rowchange.parsefrom(entry.getstorevalue());
} catch (exception e) {
throw new runtimeexception("parse event has an error , data:" + entry.tostring(), e);
}
// 获取当前内容的事件类型
eventtype eventtype = rowchage.geteventtype();
logger.info(row_format,
new object[]{entry.getheader().getlogfilename(),
string.valueof(entry.getheader().getlogfileoffset()), entry.getheader().getschemaname(),
entry.getheader().gettablename(), eventtype,
string.valueof(entry.getheader().getexecutetime()), simpledateformat.format(date),
entry.getheader().getgtid(), string.valueof(delaytime)});
// 事件类型是query或数据定义语言ddl直接打印sql语句,跳出继续下一次循环
if (eventtype == eventtype.query || rowchage.getisddl()) {
logger.info(" sql ----> " + rowchage.getsql() + sep);
continue;
}
printxainfo(rowchage.getpropslist());
// 循环当前内容条目的具体数据
for (rowdata rowdata : rowchage.getrowdataslist()) {
list<canalentry.column> columns;
// 事件类型是delete返回删除前的列内容,否则返回改变后列的内容
if (eventtype == canalentry.eventtype.delete) {
columns = rowdata.getbeforecolumnslist();
} else {
columns = rowdata.getaftercolumnslist();
}
hashmap<string, object> map = new hashmap<>(16);
// 循环把列的name与value放入map中
for (column column: columns){
map.put(column.getname(), column.getvalue());
}
rows.add(new twotuple<>(eventtype, map));
}
}
}
return rows;
}package com.example.canal.study.action;
import com.alibaba.otter.canal.client.canalconnector;
import com.alibaba.otter.canal.protocol.canalentry;
import com.alibaba.otter.canal.protocol.message;
import com.example.canal.study.common.canaldataparser;
import com.example.canal.study.common.elasticutils;
import com.example.canal.study.pojo.student;
import lombok.extern.slf4j.slf4j;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.beans.factory.annotation.qualifier;
import org.springframework.stereotype.component;
import java.io.ioexception;
import java.util.list;
import java.util.map;
/**
* @author haha
*/
@slf4j
@component
public class binlogelasticsearch {
@autowired
private canalconnector canalsimpleconnector;
@autowired
private elasticutils elasticutils;
//@qualifier("canalhaconnector")使用名为canalhaconnector的bean
@autowired
@qualifier("canalhaconnector")
private canalconnector canalhaconnector;
public void binlogtoelasticsearch() throws ioexception {
opencanalconnector(canalhaconnector);
// 轮询拉取数据
integer batchsize = 5 * 1024;
while (true) {
message message = canalhaconnector.getwithoutack(batchsize);
// message message = canalsimpleconnector.getwithoutack(batchsize);
long id = message.getid();
int size = message.getentries().size();
log.info("当前监控到binlog消息数量{}", size);
if (id == -1 || size == 0) {
try {
// 等待2秒
thread.sleep(2000);
} catch (interruptedexception e) {
e.printstacktrace();
}
} else {
//1. 解析message对象
list<canalentry.entry> entries = message.getentries();
list<canaldataparser.twotuple<canalentry.eventtype, map>> rows = canaldataparser.printentry(entries);
for (canaldataparser.twotuple<canalentry.eventtype, map> tuple : rows) {
if(tuple.eventtype == canalentry.eventtype.insert) {
student student = createstudent(tuple);
// 2。将解析出的对象同步到elasticsearch中
elasticutils.savees(student, "student_index");
// 3.消息确认已处理
// canalsimpleconnector.ack(id);
canalhaconnector.ack(id);
}
if(tuple.eventtype == canalentry.eventtype.update){
student student = createstudent(tuple);
elasticutils.updatees(student, "student_index");
// 3.消息确认已处理
// canalsimpleconnector.ack(id);
canalhaconnector.ack(id);
}
if(tuple.eventtype == canalentry.eventtype.delete){
elasticutils.deletees("student_index", tuple.columnmap.get("id").tostring());
canalhaconnector.ack(id);
}
}
}
}
}
/**
* 封装数据至student
* @param tuple
* @return
*/
private student createstudent(canaldataparser.twotuple<canalentry.eventtype, map> tuple){
student student = new student();
student.setid(tuple.columnmap.get("id").tostring());
student.setage(integer.parseint(tuple.columnmap.get("age").tostring()));
student.setname(tuple.columnmap.get("name").tostring());
student.setsex(tuple.columnmap.get("sex").tostring());
student.setcity(tuple.columnmap.get("city").tostring());
return student;
}
/**
* 打开canal连接
*
* @param canalconnector
*/
private void opencanalconnector(canalconnector canalconnector) {
//连接canalserver
canalconnector.connect();
// 订阅destination
canalconnector.subscribe();
}
/**
* 关闭canal连接
*
* @param canalconnector
*/
private void closecanalconnector(canalconnector canalconnector) {
//关闭连接canalserver
canalconnector.disconnect();
// 注销订阅destination
canalconnector.unsubscribe();
}
}canaldemoapplication.java(spring boot启动类)
package com.example.canal.study;
import com.example.canal.study.action.binlogelasticsearch;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.boot.applicationarguments;
import org.springframework.boot.applicationrunner;
import org.springframework.boot.springapplication;
import org.springframework.boot.autoconfigure.springbootapplication;
/**
* @author haha
*/
@springbootapplication
public class canaldemoapplication implements applicationrunner {
@autowired
private binlogelasticsearch binlogelasticsearch;
public static void main(string[] args) {
springapplication.run(canaldemoapplication.class, args);
}
// 程序启动则执行run方法
@override
public void run(applicationarguments args) throws exception {
binlogelasticsearch.binlogtoelasticsearch();
}
}application.properties
server.port=8081 spring.application.name = canal-demo canal.server.ip = 192.168.124.5 canal.server.port = 11111 canal.destination = example zookeeper.server.ip = 192.168.124.5:2181 zookeeper.sasl.client = false elasticsearch.server.ip = 192.168.124.5 elasticsearch.server.port = 9200
canal集群高可用的搭建
通过上面的学习,我们知道了单机直连方式的canala应用。在当今互联网时代,单实例模式逐渐被集群高可用模式取代,那么canala的多实例集群方式如何搭建呢!
基于zookeeper获取canal实例
准备zookeeper的docker镜像与容器:
docker pull zookeeper docker run -d --name zookeeper --net mynetwork --ip 172.18.0.3 -p 2181:2181 zookeeper docker run -d --name canal-server2 --net mynetwork --ip 172.18.0.8 -p 11113:11113 canal/canal-server
1、机器准备:
运行canal的容器ip: 172.18.0.4 , 172.18.0.8
zookeeper容器ip:172.18.0.3:2181
mysql容器ip:172.18.0.6:3306
2、按照部署和配置,在单台机器上各自完成配置,演示时instance name为example。
3、修改canal.properties,加上zookeeper配置并修改canal端口:
canal.port=11113 canal.zkservers=172.18.0.3:2181 canal.instance.global.spring.xml = classpath:spring/default-instance.xml
4、创建example目录,并修改instance.properties:
canal.instance.mysql.slaveid = 1235 #之前的canal slaveid是1234,保证slaveid不重复即可 canal.instance.master.address = 172.18.0.6:3306
注意: 两台机器上的instance目录的名字需要保证完全一致,ha模式是依赖于instance name进行管理,同时必须都选择default-instance.xml配置。
启动两个不同容器的canal,启动后,可以通过tail -100f logs/example/example.log查看启动日志,只会看到一台机器上出现了启动成功的日志。
比如我这里启动成功的是 172.18.0.4:
查看一下zookeeper中的节点信息,也可以知道当前工作的节点为172.18.0.4:11111:
[zk: localhost:2181(connected) 15] get /otter/canal/destinations/example/running
{"active":true,"address":"172.18.0.4:11111","cid":1}客户端链接, 消费数据
可以通过指定zookeeper地址和canal的instance name,canal client会自动从zookeeper中的running节点获取当前服务的工作节点,然后与其建立链接:
[zk: localhost:2181(connected) 0] get /otter/canal/destinations/example/running
{"active":true,"address":"172.18.0.4:11111","cid":1}对应的客户端编码可以使用如下形式,上文中的canalconfig.java中的canalhaconnector就是一个ha连接:
canalconnector connector = canalconnectors.newclusterconnector("172.18.0.3:2181", "example", "", "");链接成功后,canal server会记录当前正在工作的canal client信息,比如客户端ip,链接的端口信息等(聪明的你,应该也可以发现,canal client也可以支持ha功能):
[zk: localhost:2181(connected) 4] get /otter/canal/destinations/example/1001/running
{"active":true,"address":"192.168.124.5:59887","clientid":1001}数据消费成功后,canal server会在zookeeper中记录下当前最后一次消费成功的binlog位点(下次你重启client时,会从这最后一个位点继续进行消费):
[zk: localhost:2181(connected) 5] get /otter/canal/destinations/example/1001/cursor
{"@type":"com.alibaba.otter.canal.protocol.position.logposition","identity":{"slaveid":-1,"sourceaddress":{"address":"mysql.mynetwork","port":3306}},"postion":{"included":false,"journalname":"binlog.000004","position":2169,"timestamp":1562672817000}}停止正在工作的172.18.0.4的canal server:
docker exec -it canal-server bash cd canal-server/bin sh stop.sh
这时172.18.0.8会立马启动example instance,提供新的数据服务:
[zk: localhost:2181(connected) 19] get /otter/canal/destinations/example/running
{"active":true,"address":"172.18.0.8:11111","cid":1}与此同时,客户端也会随着canal server的切换,通过获取zookeeper中的最新地址,与新的canal server建立链接,继续消费数据,整个过程自动完成。
异常与总结
elasticsearch-head无法访问elasticsearch
es与es-head是两个独立的进程,当es-head访问es服务时,会存在一个跨域问题。所以我们需要修改es的配置文件,增加一些配置项来解决这个问题,如下:
[root@localhost /usr/local/elasticsearch-head-master]# cd ../elasticsearch-5.5.2/config/ [root@localhost /usr/local/elasticsearch-5.5.2/config]# vim elasticsearch.yml # 文件末尾加上如下配置 http.cors.enabled: true http.cors.allow-origin: "*"
修改完配置文件后需重启es服务。
elasticsearch-head查询报406 not acceptable
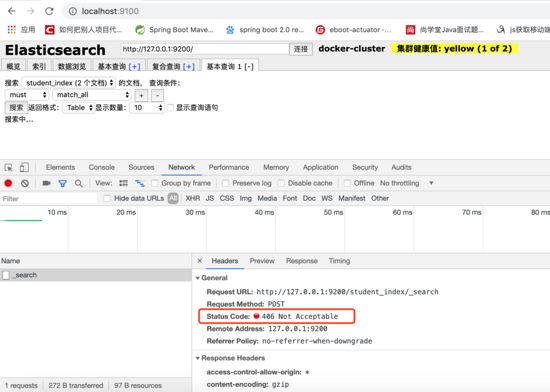
解决方法:
1、进入head安装目录;
2、cd _site/
3、编辑vendor.js 共有两处
#6886行 contenttype: "application/x-www-form-urlencoded 改成 contenttype: "application/json;charset=utf-8" #7574行 var inspectdata = s.contenttype === "application/x-www-form-urlencoded" && 改成 var inspectdata = s.contenttype === "application/json;charset=utf-8" &&
使用elasticsearch-rest-high-level-client报org.elasticsearch.action.index.indexrequest.ifseqno
#pom中除了加入依赖 <dependency> <groupid>org.elasticsearch.client</groupid> <artifactid>elasticsearch-rest-high-level-client</artifactid> <version>7.1.1</version> </dependency> #还需加入 <dependency> <groupid>org.elasticsearch</groupid> <artifactid>elasticsearch</artifactid> <version>7.1.1</version> </dependency>
相关参考: 。
为什么elasticsearch要在7.x版本不能使用type?
参考: 为什么elasticsearch要在7.x版本去掉type?
使用spring-data-elasticsearch.jar报org.elasticsearch.client.transport.nonodeavailableexception
由于本文使用的是elasticsearch7.x以上的版本,目前spring-data-elasticsearch底层采用es官方transportclient,而es官方计划放弃transportclient,工具以es官方推荐的resthighlevelclient进行调用请求。 可参考 resthighlevelclient api 。
设置docker容器开启启动
如果创建时未指定 --restart=always ,可通过update 命令 docker update --restart=always [containerid]
docker for mac network host模式不生效
host模式是为了性能,但是这却对docker的隔离性造成了破坏,导致安全性降低。 在性能场景下,可以用--netwokr host开启host模式,但需要注意的是,如果你用windows或mac本地启动容器的话,会遇到host模式失效的问题。原因是host模式只支持linux宿主机。
参见官方文档: 。
客户端连接zookeeper报authenticate using sasl(unknow error)

zookeeper.jar は dokcer の Zookeeper のバージョンと一致しません
zookeeper.jar は 3.4 より前のバージョンを使用します。 6 バージョン
このエラーは、Zookeeper が外部アプリケーションとして、システムからリソースを申請する必要があることを意味します。リソースを申請するとき、認証に合格する必要があり、sasl は認証です。 SASL 認証に合格しました。待ち時間を避けて効率を向上させます。
system.setproperty("zookeeper.sasl.client", "false"); をプロジェクト コードに追加します。 Spring Boot プロジェクトの場合は、application を追加できます。 .propertiesAddzookeeper.sasl.client=false。
mvn によって生成されたパッケージに置き換えます。インストール###: ##### #######
以上がDockerとCanalをベースにしたMySQLのリアルタイム増分データ送信機能の実装方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7442
7442
 15
1371
52
76
11
9
6
15
1371
52
76
11
9
6

 rootとしてmysqlにログインできません
Apr 08, 2025 pm 04:54 PM
rootとしてmysqlにログインできません
Apr 08, 2025 pm 04:54 PM
ルートとしてMySQLにログインできない主な理由は、許可の問題、構成ファイルエラー、一貫性のないパスワード、ソケットファイルの問題、またはファイアウォール傍受です。解決策には、構成ファイルのBind-Addressパラメーターが正しく構成されているかどうかを確認します。ルートユーザー許可が変更されているか削除されてリセットされているかを確認します。ケースや特殊文字を含むパスワードが正確であることを確認します。ソケットファイルの許可設定とパスを確認します。ファイアウォールがMySQLサーバーへの接続をブロックすることを確認します。
 MySQLユーザーとデータベースの関係
Apr 08, 2025 pm 07:15 PM
MySQLユーザーとデータベースの関係
Apr 08, 2025 pm 07:15 PM
MySQLデータベースでは、ユーザーとデータベースの関係は、アクセス許可と表によって定義されます。ユーザーには、データベースにアクセスするためのユーザー名とパスワードがあります。許可は助成金コマンドを通じて付与され、テーブルはCreate Tableコマンドによって作成されます。ユーザーとデータベースの関係を確立するには、データベースを作成し、ユーザーを作成してから許可を付与する必要があります。
 RDS MySQL Redshift Zero ETLとの統合
Apr 08, 2025 pm 07:06 PM
RDS MySQL Redshift Zero ETLとの統合
Apr 08, 2025 pm 07:06 PM
データ統合の簡素化:AmazonrdsmysqlとRedshiftのゼロETL統合効率的なデータ統合は、データ駆動型組織の中心にあります。従来のETL(抽出、変換、負荷)プロセスは、特にデータベース(AmazonrdsmysQlなど)をデータウェアハウス(Redshiftなど)と統合する場合、複雑で時間がかかります。ただし、AWSは、この状況を完全に変えたゼロETL統合ソリューションを提供し、RDSMYSQLからRedshiftへのデータ移行のための簡略化されたほぼリアルタイムソリューションを提供します。この記事では、RDSMysQl Zero ETLのRedshiftとの統合に飛び込み、それがどのように機能するか、それがデータエンジニアと開発者にもたらす利点を説明します。
 MySQLのクエリ最適化は、特に大規模なデータセットを扱う場合、データベースのパフォーマンスを改善するために不可欠です
Apr 08, 2025 pm 07:12 PM
MySQLのクエリ最適化は、特に大規模なデータセットを扱う場合、データベースのパフォーマンスを改善するために不可欠です
Apr 08, 2025 pm 07:12 PM
1.正しいインデックスを使用して、データの量を削減してデータ検索をスピードアップしました。テーブルの列を複数回検索する場合は、その列のインデックスを作成します。あなたまたはあなたのアプリが基準に従って複数の列からのデータが必要な場合、複合インデックス2を作成します2。選択した列のみを避けます。必要な列のすべてを選択すると、より多くのサーバーメモリを使用する場合にのみサーバーが遅くなり、たとえばテーブルにはcreated_atやupdated_atやupdated_atなどの列が含まれます。
 MySQLテーブルロックテーブルを変更するかどうか
Apr 08, 2025 pm 05:06 PM
MySQLテーブルロックテーブルを変更するかどうか
Apr 08, 2025 pm 05:06 PM
MySQLがテーブル構造を変更すると、メタデータロックが通常使用され、テーブルがロックされる可能性があります。ロックの影響を減らすために、次の測定値をとることができます。1。オンラインDDLでテーブルを使用できます。 2。バッチで複雑な変更を実行します。 3.小規模またはオフピーク期間中に操作します。 4. PT-OSCツールを使用して、より細かい制御を実現します。
 mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
MySQLには、無料のコミュニティバージョンと有料エンタープライズバージョンがあります。コミュニティバージョンは無料で使用および変更できますが、サポートは制限されており、安定性要件が低く、技術的な能力が強いアプリケーションに適しています。 Enterprise Editionは、安定した信頼性の高い高性能データベースを必要とするアプリケーションに対する包括的な商業サポートを提供し、サポートの支払いを喜んでいます。バージョンを選択する際に考慮される要因には、アプリケーションの重要性、予算編成、技術スキルが含まれます。完璧なオプションはなく、最も適切なオプションのみであり、特定の状況に応じて慎重に選択する必要があります。
 MySQLはAndroidで実行できますか
Apr 08, 2025 pm 05:03 PM
MySQLはAndroidで実行できますか
Apr 08, 2025 pm 05:03 PM
MySQLはAndroidで直接実行できませんが、次の方法を使用して間接的に実装できます。Androidシステムに構築されたLightWeight Database SQLiteを使用して、別のサーバーを必要とせず、モバイルデバイスアプリケーションに非常に適したリソース使用量が少ない。 MySQLサーバーにリモートで接続し、データの読み取りと書き込みのためにネットワークを介してリモートサーバー上のMySQLデータベースに接続しますが、強力なネットワーク依存関係、セキュリティの問題、サーバーコストなどの短所があります。
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
