

Redis の基本原理は何ですか

Redis コア オブジェクト
Redis には 「コア オブジェクト」がありますこれは redisObject と呼ばれ、すべてのキーと値を表すために使用されます。redisObject 構造は String を表すために使用されます, データ型は Hash、List、Set、ZSet の 5 つです。
redisObject のソースコードは c 言語で書かれた redis.h にあります。興味のある方はご自身で確認してください。ここに redisObject についての図を描きました。 redisObject は次のとおりです。
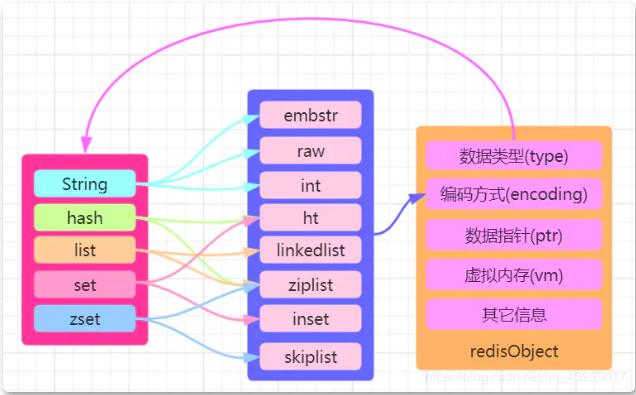
redisObject では、type はそれが属するデータ型を示し、エンコーディングはデータの格納方法を示します。データ型の基礎となる実装です。そこで、この記事ではエンコードの該当部分を具体的に紹介します。
それでは、エンコードにおけるストレージ タイプは何を意味するのでしょうか?特定のデータ型が表す意味は、次の図に示されているとおりです。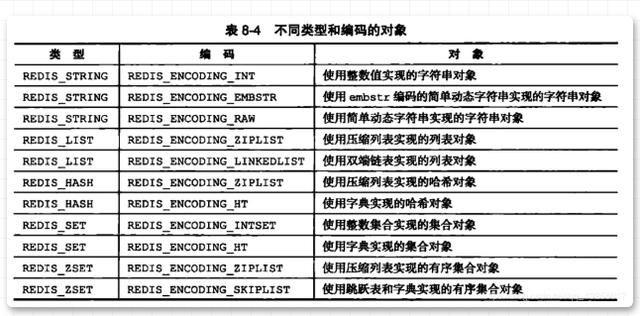
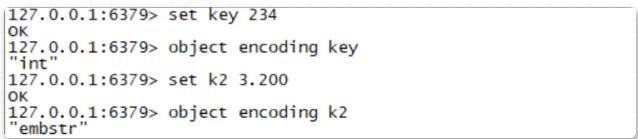
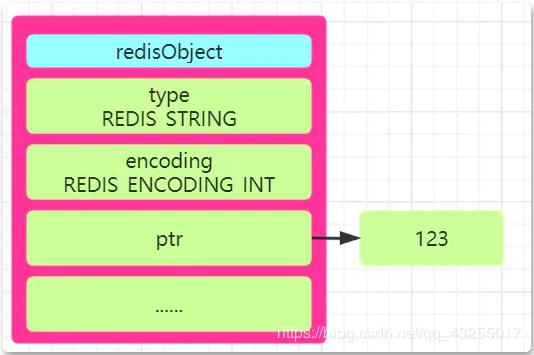
"整数値" (set num 123 など) の場合、int 格納メソッドを使用して格納されると規定されています。 redisObject の "ptr 属性" に保存されます。
「文字列は文字列値であり、長さが 32 バイトを超えている」 が使用されます。 SDS (シンプル ダイナミック ストリング) モードで、エンコーディングが raw に設定されている場合、「文字列の長さが 32 バイト以下である」 場合、エンコーディングは embstr に変更されて文字列が保存されます。
SDS は"Simple Dynamic String" と呼ばれます。Redis ソース コードの SDS には、int len、int free、char buf[] の 3 つの属性が定義されています。
len は文字列の長さを保存し、free は buf 配列内の未使用のバイト数を表し、buf 配列は文字列の各文字要素を保存します。 したがって、Redis ソース コードの説明に従って、文字列 Hello を Redsi に保存すると、以下に示すように SDS 形式で redisObject 構造図を描画できます。 #SDS と C 言語の文字列の比較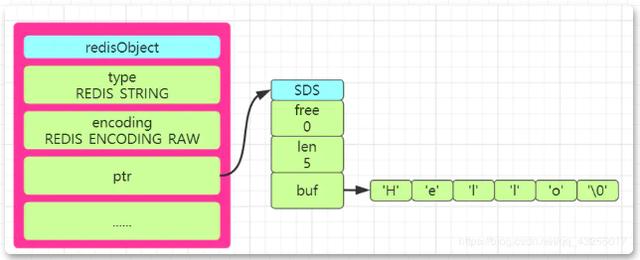 Redis には、SDS を文字列ストレージのタイプとして使用するという点で、明らかに独自の利点があります。C 言語の SDS 文字列と比較して、SDS には、文字列には独自の利点があります。
Redis には、SDS を文字列ストレージのタイプとして使用するという点で、明らかに独自の利点があります。C 言語の SDS 文字列と比較して、SDS には、文字列には独自の利点があります。
(1) C言語の文字列は自身の長さを記録しないため、
"毎回文字列を取得し、その長さを走査する、時間計算量は O(n)"です。Redis で文字列を取得するには、len の値を読み取るだけでよく、時間計算量は O(1) になります。
(2)"c言語" 2つの文字列の連結において、十分な長さのメモリ空間が確保されていない場合、
"バッファオーバーフローが発生します"; そして『SDS』は、まず len 属性に基づいて領域が要件を満たしているかどうかを判断します。領域が十分でない場合は、対応する領域が拡張されるため、 「バッファ オーバーフローは発生しません」 ###。 (3) SDS は、 「スペース事前割り当て」 および 「遅延スペース解放」
という 2 つの戦略も提供します。文字列にスペースを割り当てるときは、「文字列の増大の継続的な実行によって発生するメモリの再割り当ての数を減らす」 ように、実際よりも多くのスペースを割り当てます。 文字列が短縮された場合、SDS は未使用スペースをすぐに再利用するのではなく、free 属性を通じて未使用スペースを記録し、後で使用するときに解放します。 具体的なスペースの事前割り当ての原則は次のとおりです: "変更された文字列の長さ len が 1MB 未満の場合、len と同じ長さのスペースが事前に割り当てられます。つまり、len= free; len が 1MB より大きい場合、free によって割り当てられるスペースは 1MB"
です。(4) SDS はバイナリ セーフです。文字列の保存に加えて、バイナリ ファイル (画像、音声、ビデオなどのバイナリ データなど) も保存できますが、C 言語の文字列ではターミネータとして空の文字列が使用されます。一部の画像にはターミネータが含まれているため、バイナリ セーフではありません。
わかりやすくするために、以下に示すように、C 言語の文字列と SDS を比較する表を作成しました。
C 言語の文字列 SDS 長さを取得する時間計算量は O(n) 長さを取得する時間計算量は O(1) バイナリ セーフではありませんが、バイナリ セーフでは文字列のみを保存でき、バイナリ データも保存できます。 n 回、文字列は必然的に大きくなります。 n 回のメモリ割り当てを行う n 回、文字列メモリ割り当ての数を増やす
String type application
これについて言えば、多くの人がそう思います。人々はすでに Redis の String 型に習熟していると言えますが、純粋な理論を習得するには、理論を実際に適用する必要があります。上で述べたように、String は画像を保存するために使用できます。ここでは、画像ストレージを画像ストレージとして使用します。ケーススタディ。
(1) まず、アップロードした画像をエンコードする必要があります。画像を Base64 エンコードに処理するためのツール クラスです。具体的な実装コードは次のとおりです。
/** * 将图片内容处理成Base64编码格式 * @param file * @return */ public static String encodeImg(MultipartFile file) { byte[] imgBytes = null; try { imgBytes = file.getBytes(); } catch (IOException e) { e.printStackTrace(); } BASE64Encoder encoder = new BASE64Encoder(); return imgBytes==null?null:encoder.encode(imgBytes );コードをコピー
(2) 2 番目のステップは、処理された画像文字列形式を Redis に保存することです。実装されたコードは次のとおりです:
/** * Redis存储图片 * @param file * @return */ public void uploadImageServiceImpl(MultipartFile image) { String imgId = UUID.randomUUID().toString(); String imgStr= ImageUtils.encodeImg(image); redisUtils.set(imgId , imgStr); // 后续操作可以把imgId存进数据库对应的字段,如果需要从redis中取出,只要获取到这个字段后从redis中取出即可。 }これが画像の実装方法です。もちろん、バイナリ ストレージには String 型のデータ構造を適用して従来のカウント機能もあります: 「Weibo の数に関する統計、ファンの数に関する統計」 など。
ハッシュ型
ハッシュオブジェクトの実装にはziplistとhashtableの2つの方法があり、hashtableの格納方法はString型で、値もキー値の形式で格納されます。
辞書型の最下層は hashtable によって実装されます。辞書の最下層の実装原理を理解することは、ハッシュテーブルの実装原理を理解することを意味します。ハッシュテーブルの実装原理は、HashMap の最下層の原理と比較できます。
Dictionary
どちらも、追加時にキーを介して配列の添字を計算します。違いは、計算方法が異なることです。HashMap はハッシュ関数を使用し、hashtable は配列の添字を計算します。ハッシュ値を取得するには、sizemask 属性とハッシュ値を使用して配列添字を再度取得する必要があります。
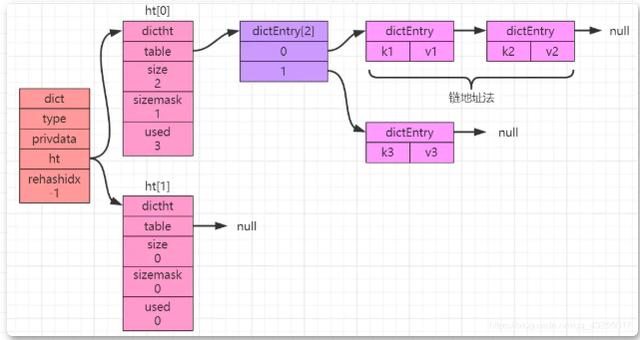
ハッシュ テーブルの最大の問題はハッシュの競合であることはわかっています。ハッシュの競合を解決するために、ハッシュ テーブル内の異なるキーが計算によって同じインデックスを取得すると、一方向のリンク リストが形成されます ("チェーン アドレス メソッド" )、以下の図に示すように:
rehash
ディクショナリの基礎となる実装では、 value オブジェクトは、各 dictEntry のオブジェクトとして格納されます。ハッシュ テーブルに格納されているキーと値のペアが増加または減少し続ける場合、ハッシュ テーブルを拡張または縮小する必要があります。
HashMapと同様に、ここでも再ハッシュ操作、つまり再ハッシュ配置が行われます。上の図からわかるように、ht[0] と ht[1] は 2 つのオブジェクトですが、以下ではそれらの属性の役割に焦点を当てます。
ハッシュ テーブル構造定義には 4 つの属性があります: dictEntry **table、unsigned long size、unsigned long sizemask、および unsigned long used であり、それぞれ "ハッシュ テーブル配列、ハッシュ テーブル サイズ" を意味します。インデックス値の計算に使用され、常に size-1、つまりハッシュ テーブルに既に存在するノードの数「」と等しくなります。
ht[0] は最初にデータを格納するために使用されます。拡張または縮小が必要な場合は、ht[0] のサイズによって ht[1] のサイズが決まります。ht[0] 内のすべてのデータ キー-value ペアは ht[1] に再ハッシュされます。
拡張操作: ht[1] の拡張サイズは、ht[0].used の現在の値の 2 倍である 2 の最初の整数乗です。縮小操作: ht[0] の最初の整数乗です。 .used 2 以上の 2 の整数乗。
ht[0] のすべてのキーと値のペアが ht[1] に再ハッシュされると、すべての配列添字値が再計算され、データ移行の完了後に ht[0] が解放されます。 , 次に、ht[1] を ht[0] に変更し、新しい ht[1] を作成して、次の伸縮に備えます。
プログレッシブ再ハッシュ
再ハッシュ プロセス中のデータ量が非常に大きい場合、Redis はすべてのデータを一度に正常に再ハッシュできず、Redis の外部サービスが停止します。この状況を内部的に処理します。Redis この状況では 「プログレッシブ リハッシュ」 が使用されます。
Redis は、すべての再ハッシュ操作が完了するまで、すべての再ハッシュ操作を複数のステップに分割します。特定の実装は、オブジェクトの rehashindex 属性に関連します。再ハッシュ操作はありません"。
再ハッシュ操作が開始されると、値は 0 に変更されます。プログレッシブ再ハッシュ プロセス中、"更新、削除、クエリは ht[0] と ht[1] の両方で実行されます。" たとえば、値を更新する場合、最初に ht[0] を更新し、次に ht[1] を更新します。
新しい操作は ht[1] テーブルに直接追加され、ht[0] はデータを追加しません。これにより、"ht[0] は減少するだけで、増加することはありません。最終的にある時点で、空のテーブル「」になり、再ハッシュ操作が完了します。
上記は、辞書の基礎となるハッシュテーブルの実装原理です。ハッシュテーブルの実装原理について説明した後、ハッシュデータ構造の 2 つの格納方法を見てみましょう"ziplist (圧縮リスト) )"
ziplist
压缩列表(ziplist)是一组连续内存块组成的顺序的数据结构,压缩列表能够节省空间,压缩列表中使用多个节点来存储数据。
压缩列表是列表键和哈希键底层实现的原理之一,「压缩列表并不是以某种压缩算法进行压缩存储数据,而是它表示一组连续的内存空间的使用,节省空间」,压缩列表的内存结构图如下:

压缩列表中每一个节点表示的含义如下所示:
zlbytes:4个字节的大小,记录压缩列表占用内存的字节数。
zltail:4个字节大小,记录表尾节点距离起始地址的偏移量,用于快速定位到尾节点的地址。
zllen:2个字节的大小,记录压缩列表中的节点数。
entry:表示列表中的每一个节点。
zlend:表示压缩列表的特殊结束符号'0xFF'。
再压缩列表中每一个entry节点又有三部分组成,包括previous_entry_ength、encoding、content。
previous_entry_ength表示前一个节点entry的长度,可用于计算前一个节点的其实地址,因为他们的地址是连续的。
encoding:这里保存的是content的内容类型和长度。
content:content保存的是每一个节点的内容。

说到这里相信大家已经都hash这种数据结构已经非常了解,若是第一次接触Redis五种基本数据结构的底层实现的话,建议多看几遍,下面来说一说hash的应用场景。
应用场景
哈希表相对于String类型存储信息更加直观,擦欧总更加方便,经常会用来做用户数据的管理,存储用户的信息。
hash也可以用作高并发场景下使用Redis生成唯一的id。下面我们就以这两种场景用作案例编码实现。
存储用户数据
第一个场景比如我们要储存用户信息,一般使用用户的ID作为key值,保持唯一性,用户的其他信息(地址、年龄、生日、电话号码等)作为value值存储。
若是传统的实现就是将用户的信息封装成为一个对象,通过序列化存储数据,当需要获取用户信息的时候,就会通过反序列化得到用户信息。
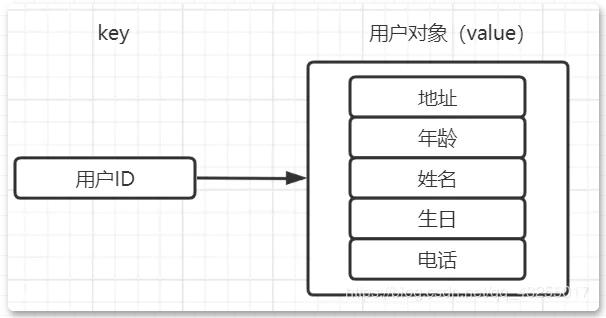
但是这样必然会造成序列化和反序列化的性能的开销,并且若是只修改其中的一个属性值,就需要把整个对象序列化出来,操作的动作太大,造成不必要的性能开销。
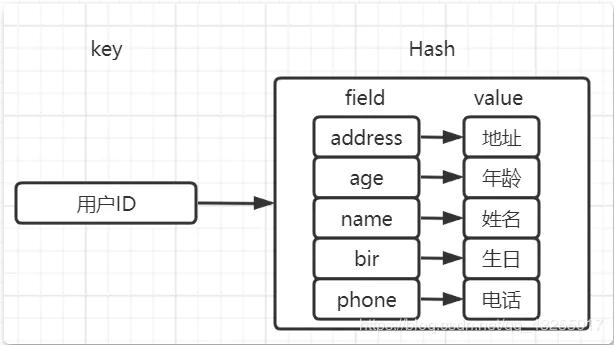
若是使用Redis的hash来存储用户数据,就会将原来的value值又看成了一个k v形式的存储容器,这样就不会带来序列化的性能开销的问题。
分布式生成唯一ID
第二个场景就是生成分布式的唯一ID,这个场景下就是把redis封装成了一个工具类进行实现,实现的代码如下:
// offset表示的是id的递增梯度值 public Long getId(String key,String hashKey,Long offset) throws BusinessException{ try { if (null == offset) { offset=1L; } // 生成唯一id return redisUtil.increment(key, hashKey, offset); } catch (Exception e) { //若是出现异常就是用uuid来生成唯一的id值 int randNo=UUID.randomUUID().toString().hashCode(); if (randNo <h3 id="List类型">List类型</h3><p>在 Redis 3.2 之前的版本,Redis 的列表是通过结合使用 ziplist 和 linkedlist 实现的。在3.2之后的版本就是引入了quicklist。</p><p>ziplist压缩列表上面已经讲过了,我们来看看linkedlist和quicklist的结构是怎么样的。</p><p>Linkedlist有双向链接,和普通的链表一样,都由指向前后节点的指针构成。时间复杂度为O(1)的操作包括插入、修改和更新,而时间复杂度为O(n)的操作是查询。</p><p>linkedlist和quicklist的底层实现是采用链表进行实现,在c语言中并没有内置的链表这种数据结构,Redis实现了自己的链表结构。</p><p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/887/227/168511087742882.jpg" class="lazy" alt="Redis の基本原理は何ですか"></p><p>Redis中链表的特性:</p><ol class=" list-paddingleft-2">
<li><p>每一个节点都有指向前一个节点和后一个节点的指针。</p></li>
<li><p>头节点和尾节点的prev和next指针指向为null,所以链表是无环的。</p></li>
<li><p>链表有自己长度的信息,获取长度的时间复杂度为O(1)。</p></li>
</ol><p>Redis中List的实现比较简单,下面我们就来看看它的应用场景。</p><h3 id="应用场景">应用场景</h3><p>Redis中的列表可以实现<strong>「阻塞队列」</strong>,结合lpush和brpop命令就可以实现。生产者使用lupsh从列表的左侧插入元素,消费者使用brpop命令从队列的右侧获取元素进行消费。</p><p>(1)首先配置redis的配置,为了方便我就直接放在application.yml配置文件中,实际中可以把redis的配置文件放在一个redis.properties文件单独放置,具体配置如下:</p><pre class="brush:php;toolbar:false">spring redis: host: 127.0.0.1 port: 6379 password: user timeout: 0 database: 2 pool: max-active: 100 max-idle: 10 min-idle: 0 max-wait: 100000(2)第二步创建redis的配置类,叫做RedisConfig,并标注上@Configuration注解,表明他是一个配置类。
@Configuration public class RedisConfiguration { @Value("{spring.redis.port}") private int port; @Value("{spring.redis.pool.max-active}") private int maxActive; @Value("{spring.redis.pool.min-idle}") private int minIdle; @Value("{spring.redis.database}") private int database; @Value("${spring.redis.timeout}") private int timeout; @Bean public JedisPoolConfig getRedisConfiguration(){ JedisPoolConfig jedisPoolConfig= new JedisPoolConfig(); jedisPoolConfig.setMaxTotal(maxActive); jedisPoolConfig.setMaxIdle(maxIdle); jedisPoolConfig.setMinIdle(minIdle); jedisPoolConfig.setMaxWaitMillis(maxWait); return jedisPoolConfig; } @Bean public JedisConnectionFactory getConnectionFactory() { JedisConnectionFactory factory = new JedisConnectionFactory(); factory.setHostName(host); factory.setPort(port); factory.setPassword(password); factory.setDatabase(database); JedisPoolConfig jedisPoolConfig= getRedisConfiguration(); factory.setPoolConfig(jedisPoolConfig); return factory; } @Bean public RedisTemplate, ?> getRedisTemplate() { JedisConnectionFactory factory = getConnectionFactory(); RedisTemplate, ?> redisTemplate = new StringRedisTemplate(factory); return redisTemplate; } }(3)第三步就是创建Redis的工具类RedisUtil,自从学了面向对象后,就喜欢把一些通用的东西拆成工具类,好像一个一个零件,需要的时候,就把它组装起来。
@Component public class RedisUtil { @Autowired private RedisTemplate<string> redisTemplate; /** 存消息到消息队列中 @param key 键 @param value 值 @return */ public boolean lPushMessage(String key, Object value) { try { redisTemplate.opsForList().leftPush(key, value); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** 从消息队列中弹出消息 - <rpop> @param key 键 @return */ public Object rPopMessage(String key) { try { return redisTemplate.opsForList().rightPop(key); } catch (Exception e) { e.printStackTrace(); return null; } } /** 查看消息 @param key 键 @param start 开始 @param end 结束 0 到 -1代表所有值 复制代码@return */ public List<object> getMessage(String key, long start, long end) { try { return redisTemplate.opsForList().range(key, start, end); } catch (Exception e) { e.printStackTrace(); return null; } }</object></rpop></string>这样就完成了Redis消息队列工具类的创建,在后面的代码中就可以直接使用。
Set集合
Redis中列表和集合都可以用来存储字符串,但是「Set是不可重复的集合,而List列表可以存储相同的字符串」,Set集合是无序的这个和后面讲的ZSet有序集合相对。
Set的底层实现是「ht和intset」,ht(哈希表)前面已经详细了解过,下面我们来看看inset类型的存储结构。
inset也叫做整数集合,用于保存整数值的数据结构类型,它可以保存int16_t、int32_t 或者int64_t 的整数值。
在整数集合中,有三个属性值encoding、length、contents[],分别表示编码方式、整数集合的长度、以及元素内容,length就是记录contents里面的大小。
在整数集合新增元素的时候,若是超出了原集合的长度大小,就会对集合进行升级,具体的升级过程如下:
首先扩展底层数组的大小,并且数组的类型为新元素的类型。
然后将原来的数组中的元素转为新元素的类型,并放到扩展后数组对应的位置。
整数集合升级后就不会再降级,编码会一直保持升级后的状态。
应用场景
Set集合的应用场景可以用来「去重、抽奖、共同好友、二度好友」等业务类型。接下来模拟一个添加好友的案例实现:
@RequestMapping(value = "/addFriend", method = RequestMethod.POST) public Long addFriend(User user, String friend) { String currentKey = null; // 判断是否是当前用户的好友 if (AppContext.getCurrentUser().getId().equals(user.getId)) { currentKey = user.getId.toString(); } //若是返回0则表示不是该用户好友 return currentKey==null?0l:setOperations.add(currentKey, friend); }
假如两个用户A和B都是用上上面的这个接口添加了很多的自己的好友,那么有一个需求就是要实现获取A和B的共同好友,那么可以进行如下操作:
public Set intersectFriend(User userA, User userB) { return setOperations.intersect(userA.getId.toString(), userB.getId.toString()); }举一反三,还可以实现A用户自己的好友,或者B用户自己的好友等,都可以进行实现。
ZSet集合
ZSet是有序集合,从上面的图中可以看到ZSet的底层实现是ziplist和skiplist实现的,ziplist上面已经详细讲过,这里来讲解skiplist的结构实现。
skiplist也叫做「跳跃表」,跳跃表是一种有序的数据结构,它通过每一个节点维持多个指向其它节点的指针,从而达到快速访问的目的。
skiplist由如下几个特点:
有很多层组成,由上到下节点数逐渐密集,最上层的节点最稀疏,跨度也最大。
每一层都是一个有序链表,只扫包含两个节点,头节点和尾节点。
每一层的每一个每一个节点都含有指向同一层下一个节点和下一层同一个位置节点的指针。
如果一个节点在某一层出现,那么该以下的所有链表同一个位置都会出现该节点。
具体实现的结构图如下所示:
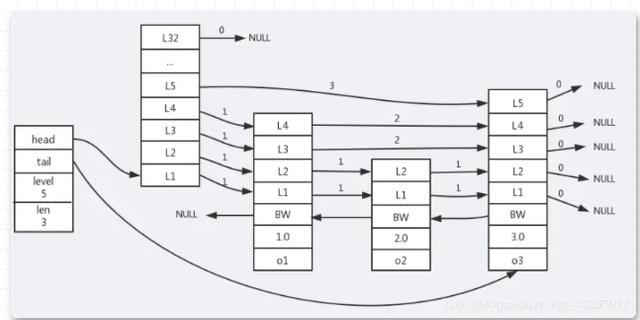
跳跃表的结构中包含指向头节点和尾节点的指针head和tail,能够快速进行定位。当在跳跃表中从尾向前遍历时,层数用 level 表示,跳跃表长度用 len 表示,同时也会使用后退指针 BW。
BW下面还有两个值分别表示分值(score)和成员对象(各个节点保存的成员对象)。
跳跃表的实现中,除了最底层的一层保存的是原始链表的完整数据,上层的节点数会越来越少,并且跨度会越来越大。
跳跃表的上面层就相当于索引层,都是为了找到最后的数据而服务的,数据量越大,条表所体现的查询的效率就越高,和平衡树的查询效率相差无几。
应用场景
因为ZSet是有序的集合,因此ZSet在实现排序类型的业务是比较常见的,比如在首页推荐10个最热门的帖子,也就是阅读量由高到低,排行榜的实现等业务。
下面就选用获取排行榜前前10名的选手作为案例实现,实现的代码如下所示:
@Autowired private RedisTemplate redisTemplate; /** * 获取前10排名 * @return */ public static List<levelvo> getZset(String key, long baseNum, LevelService levelService){ ZSetOperations<serializable> operations = redisTemplate.opsForZSet(); // 根据score分数值获取前10名的数据 Set<zsetoperations.typedtuple>> set = operations.reverseRangeWithScores(key,0,9); List<levelvo> list= new ArrayList<levelvo>(); int i=1; for (ZSetOperations.TypedTuple<object> o:set){ int uid = (int) o.getValue(); LevelCache levelCache = levelService.getLevelCache(uid); LevelVO levelVO = levelCache.getLevelVO(); long score = (o.getScore().longValue() - baseNum + levelVO .getCtime())/CommonUtil.multiplier; levelVO .setScore(score); levelVO .setRank(i); list.add( levelVO ); i++; } return list; }</object></levelvo></levelvo></zsetoperations.typedtuple></serializable></levelvo>以上的代码实现大致逻辑就是根据score分数值获取前10名的数据,然后封装成lawyerVO对象的列表进行返回。
以上がRedis の基本原理は何ですかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7648
7648
 15
1392
52
91
11
36
110
15
1392
52
91
11
36
110

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisを使用して操作をロックするには、setnxコマンドを介してロックを取得し、有効期限を設定するために有効期限コマンドを使用する必要があります。特定の手順は次のとおりです。(1)SETNXコマンドを使用して、キー価値ペアを設定しようとします。 (2)expireコマンドを使用して、ロックの有効期限を設定します。 (3)Delコマンドを使用して、ロックが不要になったときにロックを削除します。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 Redisでデータ損失を解決する方法
Apr 10, 2025 pm 08:24 PM
Redisでデータ損失を解決する方法
Apr 10, 2025 pm 08:24 PM
Redisデータ損失の原因には、メモリの障害、停電、人的エラー、ハードウェアの障害が含まれます。ソリューションは次のとおりです。1。RDBまたはAOF持続性を使用してデータをディスクに保存します。 2。高可用性のために複数のサーバーにコピーします。 3。Hawith redis sentinelまたはredisクラスター。 4.データをバックアップするスナップショットを作成します。 5.永続性、複製、スナップショット、監視、セキュリティ対策などのベストプラクティスを実装します。
 Redisコマンドラインの使用方法
Apr 10, 2025 pm 10:18 PM
Redisコマンドラインの使用方法
Apr 10, 2025 pm 10:18 PM
Redisコマンドラインツール(Redis-Cli)を使用して、次の手順を使用してRedisを管理および操作します。サーバーに接続し、アドレスとポートを指定します。コマンド名とパラメーターを使用して、コマンドをサーバーに送信します。ヘルプコマンドを使用して、特定のコマンドのヘルプ情報を表示します。 QUITコマンドを使用して、コマンドラインツールを終了します。
