

Redis メモリが大きすぎる場合はどうなりますか?

1 メイン データベースのダウンタイム
まず、以下に示すように、メイン データベースのダウンタイムの災害復旧プロセスを見てみましょう。 #In メイン データベースがダウンした場合、最も一般的な災害復旧戦略は「メイン データベースを切断する」ことです。具体的には、クラスタに残っているスレーブ ライブラリからスレーブ ライブラリを選択してマスター ライブラリにアップグレードし、スレーブ ライブラリがマスター ライブラリにアップグレードされた後、残りのスレーブ ライブラリがその下にマウントされてスレーブ ライブラリになり、最終的にはスレーブ ライブラリがマスター ライブラリにアップグレードされます。マスター/スレーブ データベース全体が復元されます クラスター構造。
上記は完全な災害復旧プロセスであり、最もコストがかかるプロセスは、メイン ライブラリの切り替えではなく、スレーブ ライブラリの再マウントです。 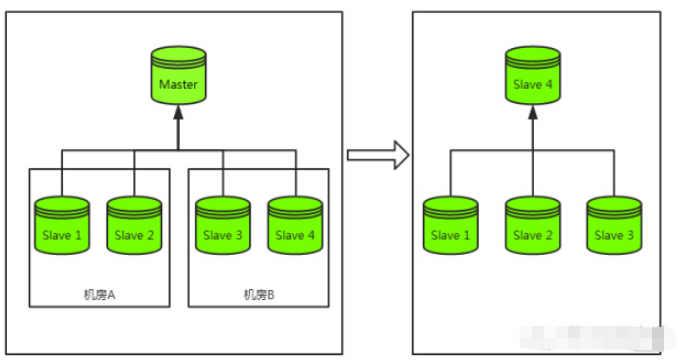
- メイン ライブラリは rdb ファイルをスレーブ ライブラリに送信します。
- ライブラリからロードを開始します。
- ロードが完了すると、アップロードが再開され、サービスは同時に開始されます
- 明らかに、このプロセス中の Redis のメモリ サイズが大きいほど、上記の各ステップの時間は長くなります。実際のテスト データは次のとおりです(マシンのパフォーマンスが向上していると信じています):
データが 20G に達すると、スレーブ データベースの回復時間が 20 近くまで延長されていることがわかります。分。10 個のスレーブ データベースがある場合、順番に回復するには合計 10 個のスレーブ データベースがかかります。200 分かかります。この時点でスレーブ ライブラリが大量の読み取りリクエストを処理している場合、このような長い回復を許容できますか?
これを見ると、必ず疑問に思うでしょう:なぜすべてのスレーブ ライブラリを同時にやり直すことができないのでしょうか?これは、すべてのスレーブ ライブラリが同時にメイン ライブラリから RDB ファイルを要求すると、そうすると、図書館本館のネットワークカードがすぐにいっぱいになってしまい、正常にサービスが提供できない状態になり、そのとき本館図書館はまた死んでしまいますし、追い打ちをかけるだけです。 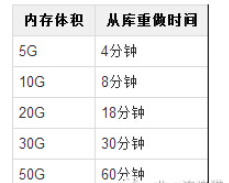
2 容量拡張の問題
トラフィックが突然増加することがよくありますが、通常、原因が判明する前に緊急対応として容量を拡張します。シナリオ 1 の表によると、20G Redis スレーブ データベースを拡張するには 20 分近くかかります。この重要な瞬間に 20 分のビジネスは耐えられますか? 拡張が完了する前に機能しなくなる可能性があります。
3 ネットワークが貧弱であると、スレーブ ライブラリがやり直しになり、最終的には雪崩が発生します。
このシナリオの最大の問題は、マスター ライブラリとスレーブ間の同期が確立されていないことです。スレーブ ライブラリはまだ書き込み要求を受け入れている可能性が高いため、中断時間が長すぎると同期バッファが上書きされる可能性があります。このとき、スレーブライブラリの最後の同期位置が失われており、ネットワーク復旧後、マスターライブラリは変更されていないものの、スレーブライブラリの同期位置が失われているため、スレーブライブラリをやり直す必要があります。問1の1、2、3の4ステップ。このとき、メイン ライブラリのメモリ サイズが大きすぎると、スレーブ ライブラリの REDO 速度が非常に遅くなり、スレーブ ライブラリに送信される読み取りリクエストに重大な影響を与えます。転送された rdb ファイルが大きすぎると、メインライブラリのネットワークカードが長期間にわたって深刻な影響を受けます。4 メモリが大きくなるほど、永続性をトリガーする操作がメイン スレッドをブロックする時間が長くなります。
Redis はシングルスレッドのメモリ内データベースです。redis では、時間のかかる操作を実行する必要があるため、操作中に bgsave や bgrewriteaof などの新しいプロセスがフォークされます。新しいプロセスをフォークするとき、共有可能なデータ コンテンツをコピーする必要はありませんが、前のプロセス領域のメモリ ページ テーブルがコピーされます。このコピーはメイン スレッドによって実行され、すべての読み取りおよび書き込み操作がブロックされます。メモリ使用量が増加するため、時間がかかります。たとえば、20G のメモリを備えた Redis の場合、bgsave はメモリ ページ テーブルをコピーするのに約 750 ミリ秒かかり、Redis メイン スレッドも 750 ミリ秒ブロックされます。#解決策
解決策は、もちろんメモリ使用量を削減することです。通常の状況では、これを実行します:
1 セット有効期限
時間に敏感なキーの有効期限を設定し、redis 独自の期限切れキーのクリーンアップ戦略を使用して、期限切れキーのメモリ使用量を削減します。また、ビジネス上の問題を軽減し、必要な作業を排除することもできます。定期的にクリーンアップする必要があります
2 redis にゴミを保存しないでください
これはまったくナンセンスですが、私たちと同じ問題を抱えている人はいますか?
3 不要なデータを適時にクリーンアップする
たとえば、次のようにします。 Redis には 3 つのビジネス データが含まれています。一定の時間が経過すると、2 つのビジネスがオフラインになった場合、これら 2 つのビジネスの関連データをクリーンアップする必要があります。
4 データをできるだけ圧縮してください。
たとえば、一部の長いテキスト データの場合、圧縮によってメモリ使用量が大幅に削減される可能性があります
#5 メモリの増加に注意し、大容量のキーを見つけてください
DBA であろうと開発者であろうと、Redis を使用するときはメモリに注意を払う必要があります。そうでないと、実際には無能です。ここでは、Redis インスタンス内のどのキーが比較的大きいかを分析して、ビジネスを迅速に支援できます。異常なキーを特定します (多くの場合、キーの予期せぬ増加が問題の原因です)6 pika
本当に疲れたくない場合は、移行してください。ビジネスを新しいオープンソース pika に移行することで、メモリにあまり注意を払う必要がなくなります。Redis メモリによって引き起こされる問題はもう問題ではありません。以上がRedis メモリが大きすぎる場合はどうなりますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7686
7686
 15
1639
14
1393
52
1287
25
1229
29
15
1639
14
1393
52
1287
25
1229
29

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisを使用して操作をロックするには、setnxコマンドを介してロックを取得し、有効期限を設定するために有効期限コマンドを使用する必要があります。特定の手順は次のとおりです。(1)SETNXコマンドを使用して、キー価値ペアを設定しようとします。 (2)expireコマンドを使用して、ロックの有効期限を設定します。 (3)Delコマンドを使用して、ロックが不要になったときにロックを削除します。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 Redisコマンドラインの使用方法
Apr 10, 2025 pm 10:18 PM
Redisコマンドラインの使用方法
Apr 10, 2025 pm 10:18 PM
Redisコマンドラインツール(Redis-Cli)を使用して、次の手順を使用してRedisを管理および操作します。サーバーに接続し、アドレスとポートを指定します。コマンド名とパラメーターを使用して、コマンドをサーバーに送信します。ヘルプコマンドを使用して、特定のコマンドのヘルプ情報を表示します。 QUITコマンドを使用して、コマンドラインツールを終了します。
 Centos RedisでLUAスクリプト実行時間を構成する方法
Apr 14, 2025 pm 02:12 PM
Centos RedisでLUAスクリプト実行時間を構成する方法
Apr 14, 2025 pm 02:12 PM
Centosシステムでは、Redis構成ファイルを変更するか、Redisコマンドを使用して悪意のあるスクリプトがあまりにも多くのリソースを消費しないようにすることにより、LUAスクリプトの実行時間を制限できます。方法1:Redis構成ファイルを変更し、Redis構成ファイルを見つけます:Redis構成ファイルは通常/etc/redis/redis.confにあります。構成ファイルの編集:テキストエディター(VIやNANOなど)を使用して構成ファイルを開きます:sudovi/etc/redis/redis.conf luaスクリプト実行時間制限を設定します。
