

クラスター化インデックスは、デフォルトで innodb によって作成される主キーベースのインデックス構造であり、テーブル内のデータは、リーフ ノードのデータ ページとしてクラスター化インデックスに直接配置されます。
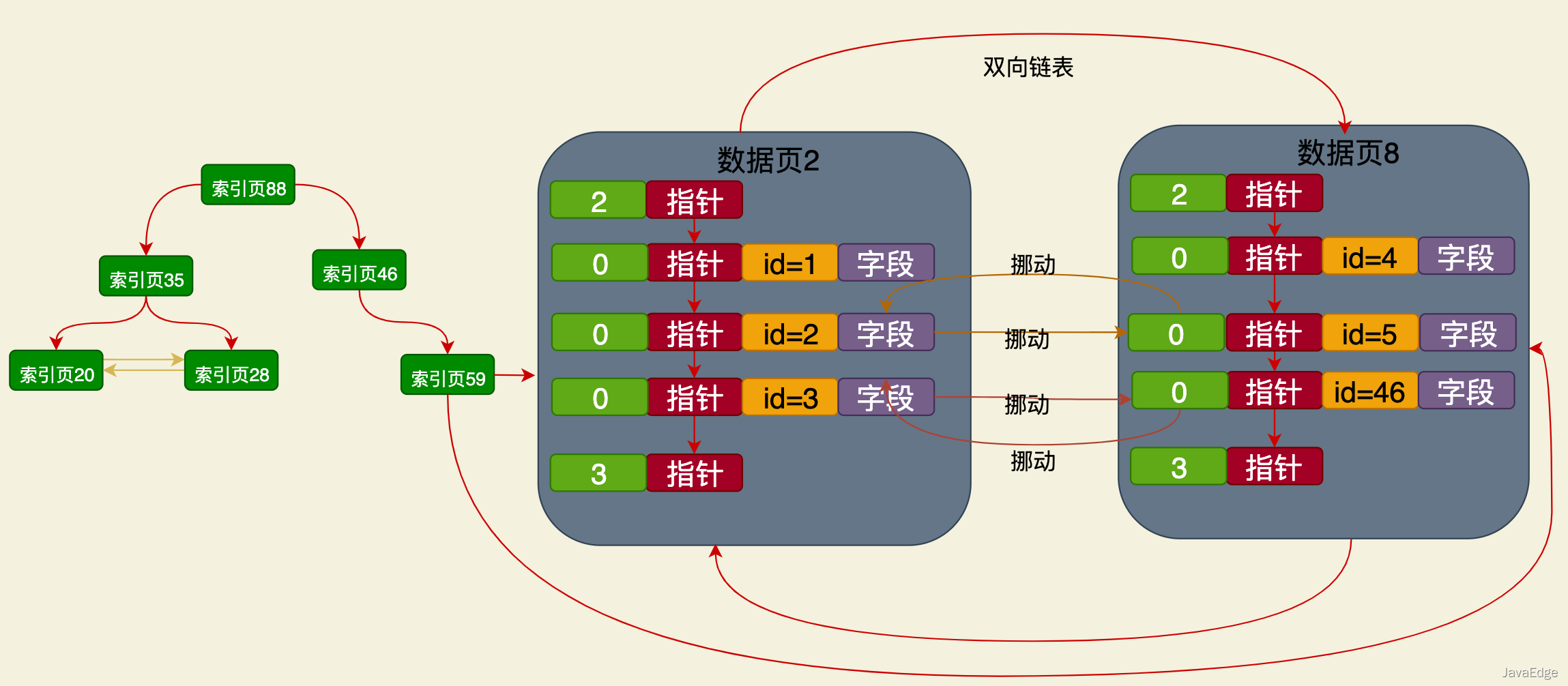
これは、クラスターから独立した B ツリーに基づく名前フィールドです。クラスター インデックスのインデックス構造。そのリーフ ノードに格納されるデータには値のみが含まれます。主キーと名前フィールドの。 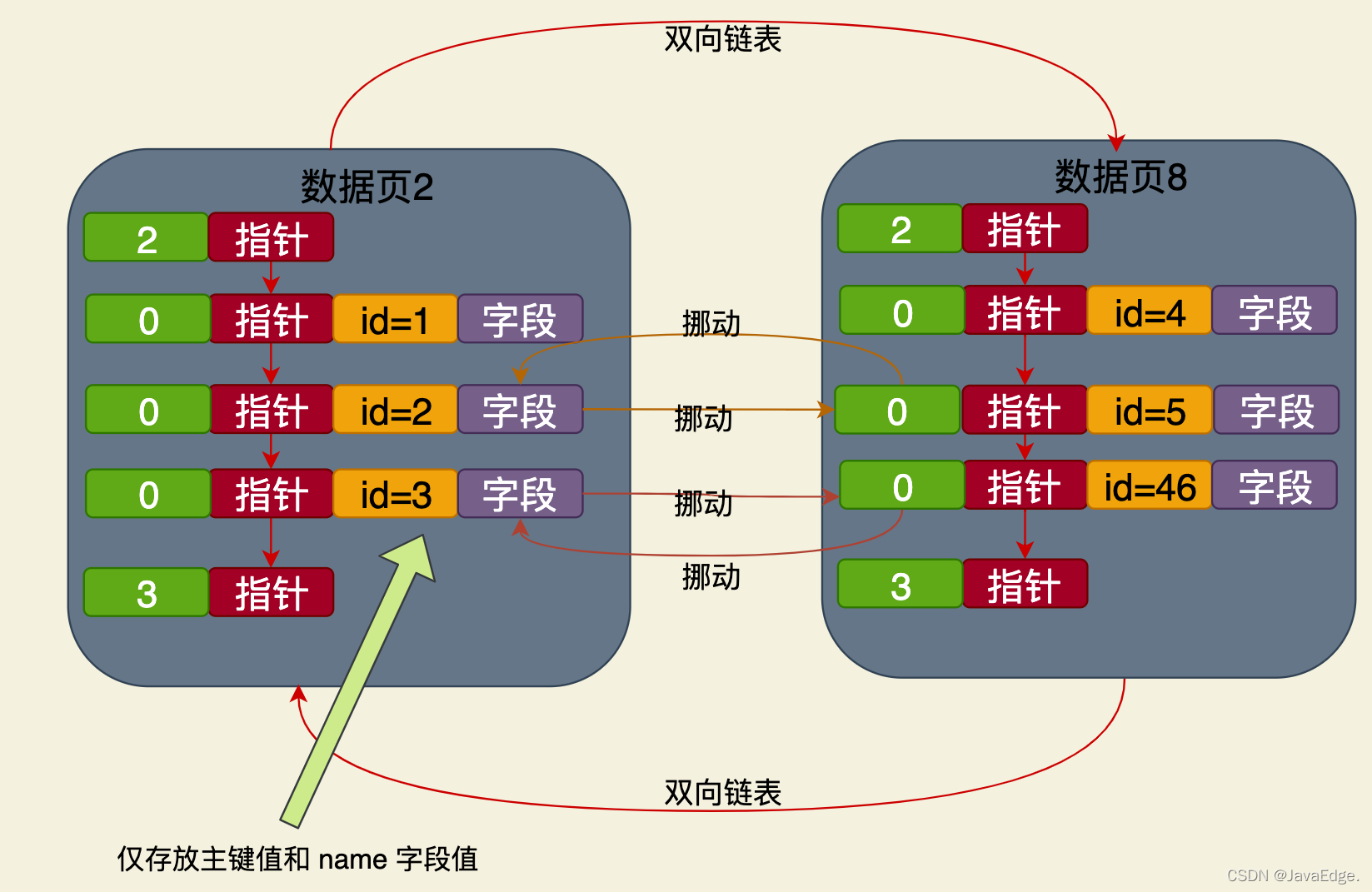
#次のレベルのページ番号
名前フィールド値の並べ替えに従った、名前フィールドの最小値。
したがって、名前フィールドに基づいてデータをクエリする場合も、プロセスは同じです。名前インデックス ツリーのルート ノードから開始して、データが見つかるまでレイヤーごとに検索します。リーフ ノードのページで、name フィールド値に対応する主キー値を見つけます。
select * from t where name='xx'
のようなステートメントの場合、最初に名前の値に基づいて名前インデックス ツリーを検索し、リーフ ノードを見つけます。対応する主キー値のみが見つかりますが、この行は見つかりません。のデータが見つかりません。すべてのフィールド。
したがって、まだテーブルに戻る必要があります。主キー値に従ってルート ノードから開始してクラスター化インデックスに移動し、リーフ ノードのデータ ページを見つけて、完全なデータを見つける必要があります。主キー値に対応する行 この時点でのみ、
select *で必要なすべてのフィールド値を取り出すことができます。
ジョイントインデックスたとえば、名前age、実行プロセスは同じで、独立したBツリーが確立され、リーフノードのデータページにID名ageが格納された後、デフォルトでは名前順に並べ替えられます。同じ名前の場合は名前順に並べ替えられます。年齢ランキングは、異なるデータ ページ間での名前の年齢値の並べ替えにも同じことが当てはまります。
次の層ノードのページ番号
名前年齢の最小値
したがって、名前年齢に基づいて検索する場合は、名前年齢ジョイント インデックス ツリーをたどって、主キーを検索します。をクリックし、主キーに基づいてクラスター化インデックスに移動し、検索します。
以上がMySQL セカンダリ インデックス クエリ プロセスとは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



