

クラスター化インデックスは、各テーブルの主キーに基づいて B ツリーを構築し、テーブル全体の行レコード データがリーフ ノードに格納されます。
たとえば、クラスター化インデックスを直感的に感じてみましょう。
テーブル t を作成し、各ページに人為的に 2 行のレコードのみを保存できるようにします (ページごとに 2 行のレコードのみを人為的に制御する方法がわかりません):
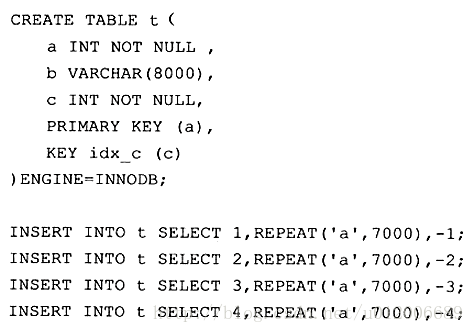
最後に、「MySQL Technology Insider」の著者は、次のような分析ツールを通じて、このクラスター化インデックス ツリーの大まかな構造を取得しました。インデックスはデータページと呼ばれ、各ページは二重リンクリストでリンクされており、データページは主キーの順に配置されています。
図に示すように、各データ ページには完全な行レコードが格納されますが、非データ ページのインデックス ページには、データ ページを指すキー値とオフセットのみが格納されます。完全なラインレコード。 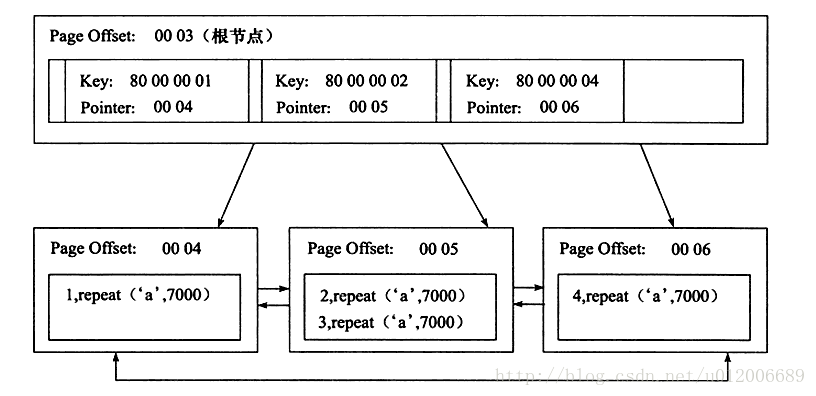
次に、作成者は補助インデックスとクラスター化インデックスを取得します。分析作業によるインデックス 関係図:
補助インデックス idx_c のリーフ ノードに、カラム c の値と主キーの値が含まれていることがわかります。
たとえば、Key の値が 0x7ffffffff であると仮定します。ここで、7 の 2 進表現は 0111 で、0 は負の数です。実際の整数値は反転して 1 を加える必要があるため、結果は -1 となり、これが列 c の値になります。主キー値は正の数 1 で、ポインター値 80000001 で表されます。8 ビットは 2 進数 1000 を表します。 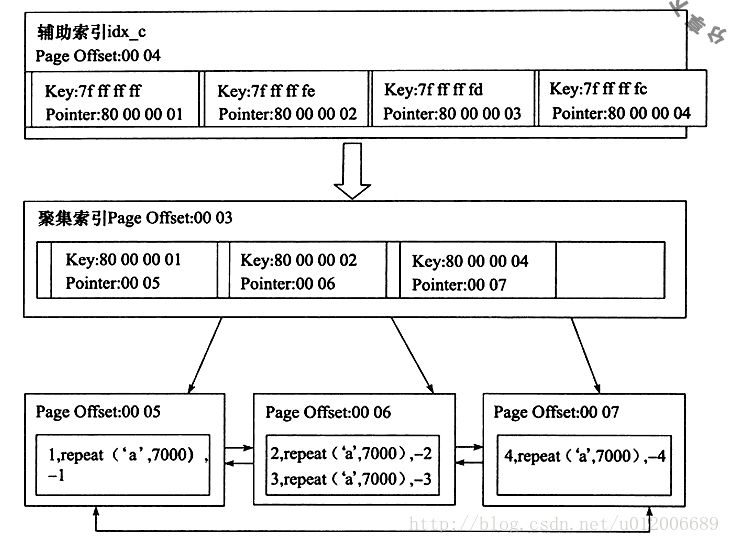
select a from where c = -2;
CREATE TABLE `student` ( `id` bigint(20) NOT NULL, `name` varchar(255) NOT NULL, `age` varchar(255) NOT NULL, `school` varchar(255) NOT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`), KEY `idx_school_age` (`school`,`age`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
このテーブルで実行した場合:
select count(*) from student
オプティマイザは統計用に補助インデックスを選択します。結果はクラスター化インデックスと補助インデックスの両方を走査することで取得できますが、補助インデックスのサイズはクラスター化インデックスよりもはるかに小さいためです。 Explain コマンドを実行します。
key と Extra は、補助インデックス idx_name が使用されていることを示します。 また、次の SQL が実行されるとします。select * from student where age > 10 and age < 15
 共同インデックス idx_school_age のフィールド順序は、最初に学校、次に年齢であるため、条件付きクエリは年齢に基づき、通常はインデックス付けされません。 : ただし、条件が変更されない場合、すべてのフィールドのクエリはエントリ数のクエリに変更されます:
共同インデックス idx_school_age のフィールド順序は、最初に学校、次に年齢であるため、条件付きクエリは年齢に基づき、通常はインデックス付けされません。 : ただし、条件が変更されない場合、すべてのフィールドのクエリはエントリ数のクエリに変更されます: select count(*) from student where age > 10 and age < 15

 以下は、ジョイント インデックス idx_a_b の作成例です。
以下は、ジョイント インデックス idx_a_b の作成例です。
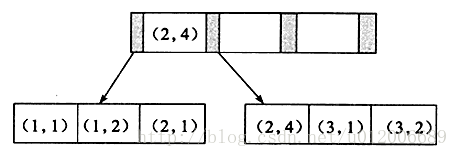
联合索引也是一棵B+树,其键值数量大于等于2。键值都是排序的,通过叶子节点可以逻辑上顺序的读出所有数据。数据(1,1)(1,2)(2,1)(2,4)(3,1)(3,2)是按照(a,b)先比较a再比较b的顺序排列。
基于上面的结构,对于以下查询显然是可以使用(a,b)这个联合索引的:
select * from table where a=xxx and b=xxx ; select * from table where a=xxx;
但是对于下面的sql是不能使用这个联合索引的,因为叶子节点的b值,1,2,1,4,1,2显然不是排序的。
select * from table where b=xxx
联合索引的第二个好处是对第二个键值已经做了排序。举个例子:
create table buy_log(
userid int not null,
buy_date DATE
)ENGINE=InnoDB;
insert into buy_log values(1, '2009-01-01');
insert into buy_log values(2, '2009-02-01');
alter table buy_log add key(userid);
alter table buy_log add key(userid, buy_date);当执行
select * from buy_log where user_id = 2;
时,优化器会选择key(userid);但是当执行以下sql:
select * from buy_log where user_id = 2 order by buy_date desc;
时,优化器会选择key(userid, buy_date),因为buy_date是在userid排序的基础上做的排序。
如果把key(userid,buy_date)删除掉,再执行:
select * from buy_log where user_id = 2 order by buy_date desc;
优化器会选择key(userid),但是对查询出来的结果会进行一次filesort,即按照buy_date重新排下序。所以联合索引的好处在于可以避免filesort排序。
以上がmysqlでクラスター化インデックス、補助インデックス、カバリングインデックス、ジョイントインデックスを使用する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



