

Redis の基本的なデータ構造は何ですか?

整数セット
セットに少数の整数要素しか含まれていない場合、Redis は整数セット intset を使用します。まず intset のデータ構造を見てください:
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;実際、intset のデータ構造は比較的理解しやすいです。データを格納する要素であり、length にはコンテンツのサイズである要素数が格納され、encoding にはデータを格納する際の符号化方式が格納されます。
コードから、エンコードのエンコード タイプに次のものが含まれることがわかります。
#define INTSET_ENC_INT16 (sizeof(int16_t)) #define INTSET_ENC_INT32 (sizeof(int32_t)) #define INTSET_ENC_INT64 (sizeof(int64_t))
実際、それが確認できます。 Redis エンコーディングのタイプは、データのサイズを指します。インメモリデータベースとしてメモリを節約する設計を採用しています。
データ構造は小さいものから大きいものまで 3 つあるため、データを挿入する際はメモリを節約するために、できるだけ小さいデータ構造を使用してください。挿入されたデータが元のデータ構造よりも大きい場合は、拡張がトリガーされます。
拡張には 3 つの手順があります。
新しい要素の型に応じて、配列全体のデータ型を変更し、スペースを再割り当てします
元のデータを新しいデータ型に変換し、あるべき場所に再配置し、順序を保持します。
次に、新しい要素を挿入します
整数コレクションはダウングレード操作をサポートしていません。一度アップグレードすると、ダウングレードすることはできません。
ジャンプ リスト
スキップ リストはリンク リストの一種で、空間を使用して時間を交換するデータ構造です。スキップ リストは、O(logN) の平均検索と最悪の場合の O(N) の複雑さの検索をサポートします。
スキップ リストは、zskiplist と複数の zskiplistNode で構成されます。まず、その構造を見てみましょう:
/* ZSETs use a specialized version of Skiplists *//*
* 跳跃表节点
*/
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
/*
* 跳跃表
*/
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;したがって、このコードに基づいて、次の構造図を描くことができます:
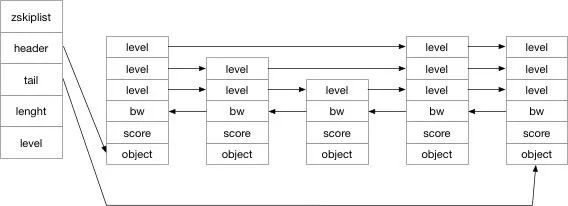
実際には、ジャンプ テーブルは使用空間です。時間変化データ構造では、レベルをリンク リストのインデックスとして使用します。
以前、誰かが Redis の作成者に、インデックスの構築にツリーではなくジャンプ テーブルを使用する理由を尋ねました。著者の答えは次のとおりです。
# メモリを節約します。
ZRANGE または ZREVRANGE を使用する場合、一般的なリンク リスト操作シナリオが含まれます。時間計算量のパフォーマンスは、バランスのとれたツリーのパフォーマンスと似ています。
最も重要な点は、ジャンプ テーブルの実装が非常に簡単で、O(logN) レベルに達する可能性があるということです。
圧縮リスト
圧縮リンク リスト Redis の作成者は、Redis を可能な限りメモリを節約するように設計された二重リンク リストとして紹介しています。
圧縮リストのコードのコメントに示されているデータ構造は次のとおりです。
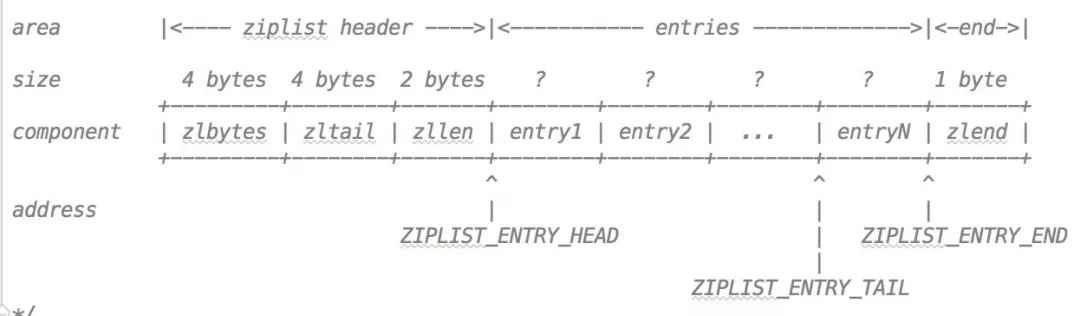
zlbytes はデータ構造を表します。圧縮リスト全体で使用されます。メモリバイト数
zltailは、圧縮リストの末尾ノードのオフセットを指定します。
zllenは、圧縮リスト内のエントリの数
entry は ziplist のノードです
zlend 圧縮リストの終わりをマークします
このリストには単一のポインタもあります:
ZIPLIST_ENTRY_HEAD リストの開始ノードの先頭オフセット
ZIPLIST_ENTRY_TAILリストの終了ノード
ZIPLIST_ENTRY_ENDリストの末尾ノードの終了オフセット
エントリの構造をもう一度見てください:
/*
* 保存 ziplist 节点信息的结构
*/
typedef struct zlentry {
// prevrawlen :前置节点的长度
// prevrawlensize :编码 prevrawlen 所需的字节大小
unsigned int prevrawlensize, prevrawlen;
// len :当前节点值的长度
// lensize :编码 len 所需的字节大小
unsigned int lensize, len;
// 当前节点 header 的大小
// 等于 prevrawlensize + lensize
unsigned int headersize;
// 当前节点值所使用的编码类型
unsigned char encoding;
// 指向当前节点的指针
unsigned char *p;
} zlentry;これらのパラメータを順番に説明します。
prevrawlen 前のノードの長さ。ここには追加のサイズがあり、実際には prevrawlen のサイズが記録されます。メモリを節約するために、Redis はデフォルトの int 長を直接使用せず、徐々にアップグレードします。
同様に、len は現在のノードの長さを記録し、lensize は len の長さを記録します。 headersize は、上記の 2 つのサイズの合計です。 encoding は、このノードのデータ型です。ここで、エンコード タイプには整数と文字列のみが含まれることに注意してください。 p ノード ポインタについては、あまり説明する必要はありません。
注意すべき点は、各ノードが前のノードの長さを保存することです。ノードが更新または削除された場合、このノードの後のデータも変更する必要があります。最悪のシナリオは、各ノードがすべてノードは拡張する必要があるゼロ点にあり、これにより、このノードの後のノードがサイズ パラメータを変更し、連鎖反応が引き起こされます。このとき、リンクリストを圧縮する最悪の時間計算量は O(n^2) です。ただし、すべてのノードが臨界値にあるため、確率は比較的小さいと言えます。
以上がRedis の基本的なデータ構造は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7563
7563
 15
1385
52
84
11
28
99
15
1385
52
84
11
28
99

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisを使用して操作をロックするには、setnxコマンドを介してロックを取得し、有効期限を設定するために有効期限コマンドを使用する必要があります。特定の手順は次のとおりです。(1)SETNXコマンドを使用して、キー価値ペアを設定しようとします。 (2)expireコマンドを使用して、ロックの有効期限を設定します。 (3)Delコマンドを使用して、ロックが不要になったときにロックを削除します。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
Redisはハッシュテーブルを使用してデータを保存し、文字列、リスト、ハッシュテーブル、コレクション、注文コレクションなどのデータ構造をサポートします。 Redisは、スナップショット(RDB)を介してデータを維持し、書き込み専用(AOF)メカニズムを追加します。 Redisは、マスタースレーブレプリケーションを使用して、データの可用性を向上させます。 Redisは、シングルスレッドイベントループを使用して接続とコマンドを処理して、データの原子性と一貫性を確保します。 Redisは、キーの有効期限を設定し、怠zyな削除メカニズムを使用して有効期限キーを削除します。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 Redis用のメッセージミドルウェアの作成方法
Apr 10, 2025 pm 07:51 PM
Redis用のメッセージミドルウェアの作成方法
Apr 10, 2025 pm 07:51 PM
Redisは、メッセージミドルウェアとして、生産消費モデルをサポートし、メッセージを持続し、信頼できる配信を確保できます。メッセージミドルウェアとしてRedisを使用すると、低遅延、信頼性の高いスケーラブルなメッセージングが可能になります。
