

MySQL 最適化インデックスのマージによって発生するデッドロックを解決する方法

背景
本番環境でデッドロックが発生しました。デッドロックのログを確認すると、デッドロックの原因は 2 つの同一の更新ステートメント (where 条件の値のみが異なる) であることがわかりました。
は次のとおりです:
UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx1' AND `status` = 0; UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx2' AND `status` = 0;
最初は理解するのが難しかったですが、多くの調査と研究を経て、デッドロック形成の具体的な原理を分析しました。同じ問題を抱えている友人たちに役立つことを願って、この記事をみんなと共有したいと思います。
MySQL には多くの知識ポイントがあるため、多くの名詞はここではあまり紹介しません。興味のある友人は、特別に詳しく学習してフォローしてください。
*** (1) TRANSACTION:
TRANSACTION 791913819, ACTIVE 0 sec starting index read, thread declared inside InnoDB 4999
mysql tables in use 3, locked 3
LOCK WAIT 4 lock struct(s), heap size 1184, 3 row lock(s)
MySQL thread id 462005230, OS thread handle 0x7f55d5da3700, query id 2621313306 x.x.x.x test_user Searching rows for update
UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx1' AND `status` = 0;
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 110 page no 39167 n bits 1056 index `idx_status` of table `test`.`test_table` trx id 791913819 lock_mode X waiting
Record lock, heap no 495 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
*** (2) TRANSACTION:
TRANSACTION 791913818, ACTIVE 0 sec starting index read, thread declared inside InnoDB 4999
mysql tables in use 3, locked 3
5 lock struct(s), heap size 1184, 4 row lock(s)
MySQL thread id 462005231, OS thread handle 0x7f55cee63700, query id 2621313305 x.x.x.x test_user Searching rows for update
UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx2' AND `status` = 0;
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 110 page no 39167 n bits 1056 index `idx_status` of table `test`.`test_table` trx id 791913818 lock_mode X
Record lock, heap no 495 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 110 page no 41569 n bits 88 index `PRIMARY` of table `test`.`test_table` trx id 791913818 lock_mode X locks rec but not gap waiting
Record lock, heap no 14 PHYSICAL RECORD: n_fields 30; compact format; info bits 0
*** WE ROLL BACK TRANSACTION (1)
ログイン後にコピー
*** (1) TRANSACTION: TRANSACTION 791913819, ACTIVE 0 sec starting index read, thread declared inside InnoDB 4999 mysql tables in use 3, locked 3 LOCK WAIT 4 lock struct(s), heap size 1184, 3 row lock(s) MySQL thread id 462005230, OS thread handle 0x7f55d5da3700, query id 2621313306 x.x.x.x test_user Searching rows for update UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx1' AND `status` = 0; *** (1) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 110 page no 39167 n bits 1056 index `idx_status` of table `test`.`test_table` trx id 791913819 lock_mode X waiting Record lock, heap no 495 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 *** (2) TRANSACTION: TRANSACTION 791913818, ACTIVE 0 sec starting index read, thread declared inside InnoDB 4999 mysql tables in use 3, locked 3 5 lock struct(s), heap size 1184, 4 row lock(s) MySQL thread id 462005231, OS thread handle 0x7f55cee63700, query id 2621313305 x.x.x.x test_user Searching rows for update UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx2' AND `status` = 0; *** (2) HOLDS THE LOCK(S): RECORD LOCKS space id 110 page no 39167 n bits 1056 index `idx_status` of table `test`.`test_table` trx id 791913818 lock_mode X Record lock, heap no 495 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 *** (2) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 110 page no 41569 n bits 88 index `PRIMARY` of table `test`.`test_table` trx id 791913818 lock_mode X locks rec but not gap waiting Record lock, heap no 14 PHYSICAL RECORD: n_fields 30; compact format; info bits 0 *** WE ROLL BACK TRANSACTION (1)
上記のデッドロック ログを簡単に分析します:
- 1. 最初の内容 (行 1 ~ 9) )、行 6 はトランザクション (1) によって実行される SQL ステートメントで、行 7 と 8 はトランザクション (1) が idx_status インデックスの X ロックを待機していることを意味します;
- 2。コンテンツの 2 番目のブロック (11 行目から 19 行目) では、16 行目はトランザクション (2) によって実行される SQL ステートメントであり、17 行目と 18 行目は、トランザクション (2) が idx_status インデックス X ロック オンを保持していることを意味します。 意味: トランザクション (2) は、PRIMARY インデックスの X ロックの取得を待機しています。 (ただし、ギャップではないということは、ギャップ ロックではないことを意味します)
- 4. 最後の文は、MySQL がトランザクション (1) をロールバックしたことを意味します。
- テーブル構造
CREATE TABLE `test_table` ( `id` int(11) NOT NULL AUTO_INCREMENT, `trans_id` varchar(21) NOT NULL, `status` int(11) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `uniq_trans_id` (`trans_id`) USING BTREE, KEY `idx_status` (`status`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
テーブル構造からわかるように、
trans_id columnuniq_trans_id # に一意のインデックスがあります。 ##,status 列 idx_status には通常のインデックスがあり、id 列は主キー インデックス PRIMARY です。 InnoDB エンジンには 2 種類のインデックスがあります:
- クラスター化インデックス:
- データ ストレージとインデックスを配置します。インデックス構造のリーフ ノードは一緒に行データを格納します。
- 補助インデックスのリーフ ノードには、クラスター化インデックスのキー値である主キー値が格納されます。
主キー インデックス
PRIMARY
uniq_trans_id インデックスと idx_status インデックスは補助インデックスであり、リーフ ノードには主キー値 (id 列の値) が格納されます。 補助インデックスを通じて行データを検索する場合、最初に補助インデックスを通じて主キー ID を見つけ、次に主キー インデックスを通じて二次検索 (これもテーブルに呼び出されます) を実行し、最後に行データを見つけます。
実行計画を見ると、update ステートメントでインデックスのマージが使用されていることがわかります。つまり、このステートメントでは ## の両方が使用されています。 #uniq_trans_id 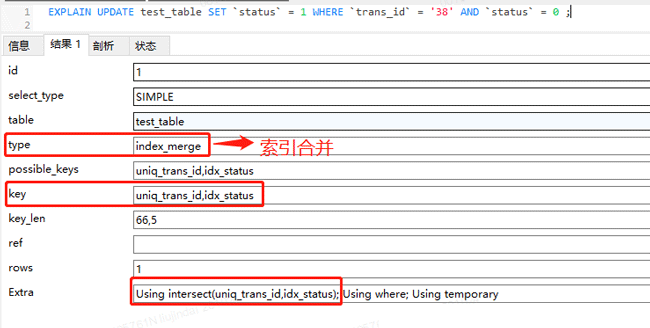 インデックスが再度使用されます
インデックスが再度使用されます
インデックス、 intersect(uniq_trans_id,idx_status) を使用することは、2 つのインデックスを通じて交差を取得することを意味します。 index_merge が使用される理由 MySQL5.0 より前は、テーブルは一度に 1 つのインデックスしか使用できず、条件付きスキャンで複数のインデックスを同時に使用することはできませんでした。ただし、5.1 からは、
最適化テクノロジが導入され、複数のインデックスを使用して同じテーブルで条件付きスキャンを実行できるようになりました。
たとえば、実行プラン内のステートメント:
UPDATE test_table SET `status` = 1 WHERE `trans_id` = '38' AND `status` = 0 ;
MySQL は、条件 trans_id = ‘38’ に基づいて uniq_trans_id# を使用します。
## インデックスはリーフ ノードに保存されている ID 値を検索します。同時に、条件status = 0 に従って、idx_status インデックスを使用して、リーフ ノードに保存された ID 値; その後、2 つのグループ ID 値が交差され、最終的に交差 ID がテーブルに返されます、つまり、リーフ ノードに保存された行データが PRIMARY インデックスを通じて検出されます。 多くの人がここで疑問を抱くかもしれません。uniq_trans_id はすでに一意のインデックスです。このインデックスを通じて見つかるのは最大でも 1 つのデータだけです。では、なぜ MySQL オプティマイザーは 2 つのインデックスを使用するのでしょうか。 2 つのインデックスの共通部分を検索し、クエリのためにテーブルに戻ります。これにより、別の idx_status
最初の例では、uniq_trans_id インデックスのみを使用します。
##クエリ条件 trans_id = ‘38’ によると、 use
uniq_trans_id- インデックスはリーフ ノードに保存されている ID 値を検索します;
PRIMARY インデックスを使用して、見つかった ID 値を通じてリーフ ノードに保存されている行データを検索します;次に、見つかった行データを - status = 0
条件でフィルター処理します。
2 番目のタイプはインデックスのマージを使用します。
Using intersect(uniq_trans_id,idx_status):
trans_id によると= ‘38’ クエリ条件、
- インデックスを使用して、リーフ ノードに保存されている ID 値を検索します;
-
idx_statusstatus によると = 0クエリ条件。 インデックスを使用して、リーフ ノードに保存されている ID 値を検索します。 1/2 で見つかった ID 値の共通部分を取得し、PRIMARY インデックスを使用してリーフ ノードに保存されている行データを見つけます
上記の 2 つのケースの主な違いは、1 つ目の方法では最初にインデックスを通じてデータを検索し、次に他のクエリ条件を使用してフィルタリングすること、2 つ目の方法では最初に ID 値の共通部分を取得することです。 2 つのインデックスを通じて見つかりました。交差部分の後に ID 値がまだある場合は、テーブルに戻ってデータを取得します。
オプティマイザが 2 番目のケースの実行コストが最初のケースの実行コストより小さいと判断した場合、インデックスのマージが発生します。 (運用環境のフロー テーブルには status = 0 のデータがほとんどありません。これが、オプティマイザが 2 番目のケースを考慮する理由の 1 つです)。
index_merge
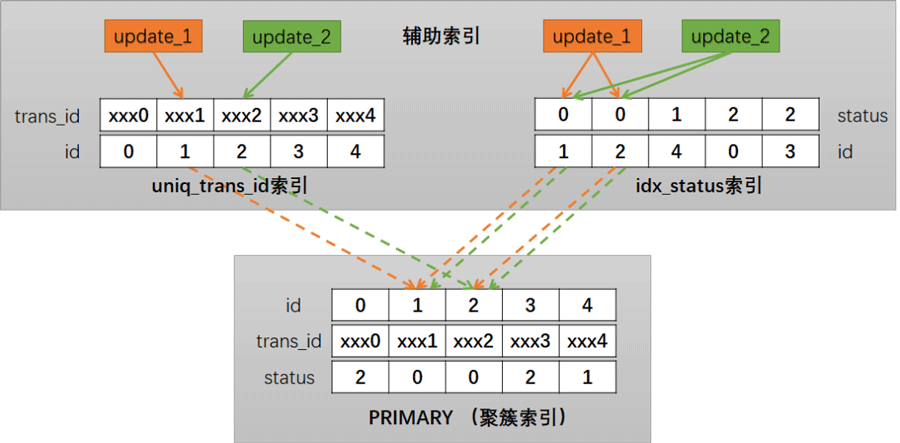
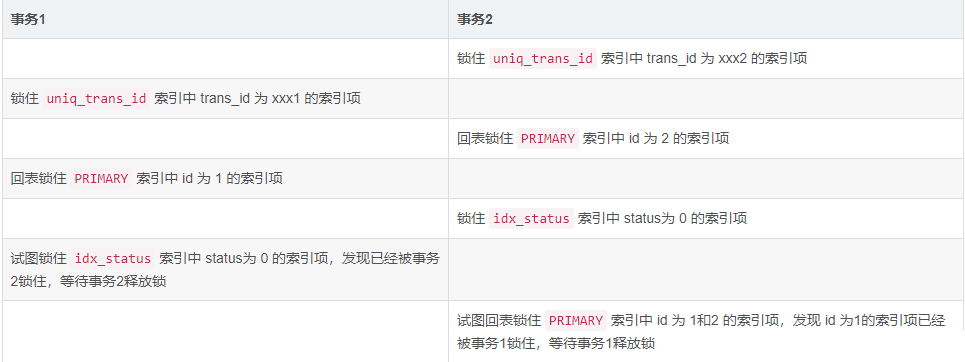
index_merge を使用した後にデッドロックが発生する理由 上記は、2 つの更新トランザクションをロックするプロセスを簡単に示しています。図では、idx_status
たとえば、次のようなタイミングでデッドロックが発生します。
-
のみを渡します。 、コード レベルでステータスが 0 であるかどうかを判断します。# クエリ条件から、データをクエリするためにtrans_id -
を使用するように強制します。 index;Useforce Index(uniq_trans_id)クエリ ステートメントでuniq_trans_id - ここで、クエリ条件の直後に id フィールドを使用し、主キーを介して更新します。
- idx_status
- インデックスを MySQL レベルから削除するか、これら 2 つの列を含む結合インデックスを作成します。
index merge##MySQL オプティマイザーの 最適化をオフにします。
以上がMySQL 最適化インデックスのマージによって発生するデッドロックを解決する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7460
7460
 15
1376
52
77
11
17
17
15
1376
52
77
11
17
17

 MySQLユーザーとデータベースの関係
Apr 08, 2025 pm 07:15 PM
MySQLユーザーとデータベースの関係
Apr 08, 2025 pm 07:15 PM
MySQLデータベースでは、ユーザーとデータベースの関係は、アクセス許可と表によって定義されます。ユーザーには、データベースにアクセスするためのユーザー名とパスワードがあります。許可は助成金コマンドを通じて付与され、テーブルはCreate Tableコマンドによって作成されます。ユーザーとデータベースの関係を確立するには、データベースを作成し、ユーザーを作成してから許可を付与する必要があります。
 mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
MySQLには、無料のコミュニティバージョンと有料エンタープライズバージョンがあります。コミュニティバージョンは無料で使用および変更できますが、サポートは制限されており、安定性要件が低く、技術的な能力が強いアプリケーションに適しています。 Enterprise Editionは、安定した信頼性の高い高性能データベースを必要とするアプリケーションに対する包括的な商業サポートを提供し、サポートの支払いを喜んでいます。バージョンを選択する際に考慮される要因には、アプリケーションの重要性、予算編成、技術スキルが含まれます。完璧なオプションはなく、最も適切なオプションのみであり、特定の状況に応じて慎重に選択する必要があります。
 RDS MySQL Redshift Zero ETLとの統合
Apr 08, 2025 pm 07:06 PM
RDS MySQL Redshift Zero ETLとの統合
Apr 08, 2025 pm 07:06 PM
データ統合の簡素化:AmazonrdsmysqlとRedshiftのゼロETL統合効率的なデータ統合は、データ駆動型組織の中心にあります。従来のETL(抽出、変換、負荷)プロセスは、特にデータベース(AmazonrdsmysQlなど)をデータウェアハウス(Redshiftなど)と統合する場合、複雑で時間がかかります。ただし、AWSは、この状況を完全に変えたゼロETL統合ソリューションを提供し、RDSMYSQLからRedshiftへのデータ移行のための簡略化されたほぼリアルタイムソリューションを提供します。この記事では、RDSMysQl Zero ETLのRedshiftとの統合に飛び込み、それがどのように機能するか、それがデータエンジニアと開発者にもたらす利点を説明します。
 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 MySQLのユーザー名とパスワードを入力する方法
Apr 08, 2025 pm 07:09 PM
MySQLのユーザー名とパスワードを入力する方法
Apr 08, 2025 pm 07:09 PM
MySQLのユーザー名とパスワードを入力するには:1。ユーザー名とパスワードを決定します。 2。データベースに接続します。 3.ユーザー名とパスワードを使用して、クエリとコマンドを実行します。
 MySQLのクエリ最適化は、特に大規模なデータセットを扱う場合、データベースのパフォーマンスを改善するために不可欠です
Apr 08, 2025 pm 07:12 PM
MySQLのクエリ最適化は、特に大規模なデータセットを扱う場合、データベースのパフォーマンスを改善するために不可欠です
Apr 08, 2025 pm 07:12 PM
1.正しいインデックスを使用して、データの量を削減してデータ検索をスピードアップしました。テーブルの列を複数回検索する場合は、その列のインデックスを作成します。あなたまたはあなたのアプリが基準に従って複数の列からのデータが必要な場合、複合インデックス2を作成します2。選択した列のみを避けます。必要な列のすべてを選択すると、より多くのサーバーメモリを使用する場合にのみサーバーが遅くなり、たとえばテーブルにはcreated_atやupdated_atやupdated_atなどの列が含まれます。
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
