

インデックスは書籍の目次に相当します。目次の主要なページ番号に基づいて、必要なコンテンツをすばやく見つけることができます。データベースはインデックスを使用して特定の値を検索し、その後、テーブルに対応する値を含む行を見つけるためのポインター。SQL ステートメントの実行が高速になり、データベース テーブル内の特定の情報にすばやくアクセスできるようになります。
一文の要約:
インデックスにより、データ検索の効率が向上し、データベースの IO コストが削減されます。
質問する: 私たちは時間とスペースを交換していますが、そのデータ構造、クエリ IO コスト、およびデータの保存方法についてはどうですか?
2 インデックス付きデータの進化構造 B ツリーのプロセスB ツリーの進化プロセスをPage の観点から見ていきます。
ページは、InnoDB がストレージ スペースを管理するための基本単位です。InnoDB は、データベース内のデータをページという基本ストレージ単位に保存します。ページは、メモリとディスク間の対話の基本単位でもあります。データベースはディスクから開始され、数ページのデータをメモリに読み取り、メモリ内の数ページのデータをディスクにリフレッシュします。1ページのメモリサイズは16KBです。
この SQL を実行して 10 個のレコードを取得するとします。
SELECT * FROM INNODB_USER LIMIT 0 , 10;
ページ内のすべてのデータには、record_typeというキー属性があります0 一般ユーザー レコード 1 ディレクトリ インデックス レコード 2 最小値 3 最大値
#Draw aページ上にデータがどのように配置されるかを示す図:

Store data主キーに従って順序
データの保存はシーケンシャル IO であり、保存に便利であることはわかっていますが、保存に便利な場合、クエリは不便になります。最後のものがチェックされている場合は、 、データのページ全体を走査する必要がありますか? 2.1 質問データの一部を確認したい場合はどうすればよいですか?データをすばやく見つけるにはどうすればよいですか?
リンク リスト
内のデータがどのように接続されているかです (データは同じページ内にあります):
MySQL は、一方向リンク リスト を介してページ内のデータを接続します。クエリが主キーに基づいている場合、バイナリ位置決め方法は非常に高速です。クエリがベースの場合、バイナリ位置決めメソッドは非常に高速です。非主キー インデックスでは、一方向のリンク リストを最小のものから順に走査することのみが可能です。
複数のページ間の接続を確立する方法 (データは別のページにあります):
MySQL は異なるページを双方向で渡します。リンクリスト 前のページから次のページ、次のページから次のページを見つけることができるようにリンクを設定します。ページ 二重リンク リストを最後まで検索し、同じページ上と同様に各ページで指定されたレコードを検索します。これも完全なテーブル スキャンです。
2.2 質問
リンク リストのレコードが増加すると、レコードを直接見つけることができないため、クエリが遅いという問題が発生します。よく考えてみると、いわゆるクエリが遅い とは、実際には次の 2 つの問題です。 :
チェック
ディレクトリ そうですか?ディレクトリとは何ですか?ただのインデックスじゃないの?
Baidu でディレクトリを見つけて写真を投稿してください:

非常に重要な情報が 2 つあることがわかりました。
データを迅速にクエリするという目的を達成するには、書籍のカタログのアイデアを参照してください。 データにカタログを追加し、データを確認します。最初に基づいたのは、カタログ ページは、クエリのパフォーマンスを向上させるためにデータがどのページのどこにあるかを見つけます。
しかし、2.3 質問: ディレクトリを作成するにはどうすればよいですか?各ページに目次を作成しますか?
ディレクトリを定期的に作成する必要がありますか?例えば、辞書のディレクトリはアルファベット順に設定されていますが、あなたは何を考えましたか?そうです、
主キーただし、ページごとにディレクトリを作成します。ディレクトリ ページ が複数回表示されるため、ディレクトリを 1 つずつたどる必要があります。
クエリのパフォーマンスも低下します
。 ディレクトリのディレクトリを 作成できますか? したがって、ディレクトリ ページのディレクトリを作成し、ルート ノードの 1 つの層を上に抽出することもできます。これにより、クエリが容易になります。
このツリーは主キーに従って
されているため、これを 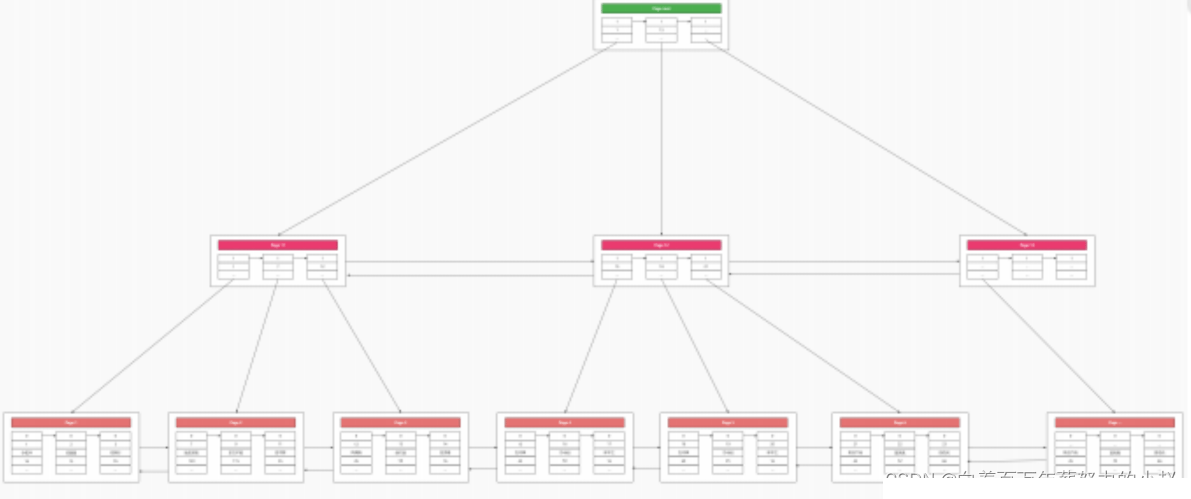 主キー インデックス ツリー
主キー インデックス ツリー
index は data であり、data は Index です。 これは、MysqlB ツリーの主キー インデックス ツリーのデータ構造です。どうですか? 直接暗記して得られる知識よりも優れていますか? 2.4 インデックス ツリー, ページの分割と結合
クエリのパフォーマンスを向上させる方法が見つかりました。では、ページを追加、変更、または削除すると、どのような問題が発生するでしょうか?
が規則的に増加し、新しいデータが追加された場合はどうなるでしょうか?次のデータ ページのユーザー レコードの主キー値は、前のページのユーザー レコードの主キー値より大きくなければなりません
これは規則的に増加しているため、二重リンクされたページのリストの最後にページを直接追加できます。 が順序どおりに増加せず、新しいデータが追加された場合はどうなりますか?
新しいページを開いて、データの場所を見つけます。 古いデータを新しいページに移動し、新しいデータを順序付けられた位置に配置します。
概要:
ページの追加、変更、削除時に発生する問題:順序のない増加が発生すると、次のように言えます。主キー ID の更新やインデックス ページの削除などの更新操作中に、多数のツリー ノードの調整が行われ、子リーフ ノード ページ ページと上位リーフ ノード ページおよびルート ノード ページのページングとマージがトリガーされ、結果として大量のディスクの断片化とデータベース容量の損失
頻繁に更新および変更される列にインデックスを構築すべきではない、または主キー要約しましょう:
主キー インデックス ツリーは次のとおりです。クラスター化インデックスまたはクラスター化インデックスとも呼ばれます。InnoDB では、テーブルにはクラスター化インデックス ツリーが 1 つだけあります。テーブルが主キー インデックスを作成する場合、この主キー インデックスはクラスター化インデックスです。キーに基づいてデータを決定します。クラスター化インデックス ツリーの値。行の物理的な保存順序で、クラスター化インデックスはテーブル内のすべての列を並べ替えて保存します。インデックスはデータであり、データはインデックスであり、主キー インデックス ツリーを参照します。クラスター化インデックス (クラスター化インデックス):
2.5 先ほどの結論に基づいて、面接での質問をいくつか紹介します。
主キー ID が増加傾向にあることが最適なのはなぜですか?
你刚刚看完啊,不会没记住吧,有序递增,下一个数据页中用户记录的主键值必须大于上一个页中用户的主键值,假如我是趋势递增,存入的数据肯定是在最末尾链表或者新增一个链表,就不会触发页的分裂与合并,导致添加的速度变慢。
三层B+数能存多少数据?
考察点:Page页的大小,B+树的定义
1GB = 1024 M, 1mb = 1024k,1k= 1024 bytes
答:
已知:索引逻辑单元 16bytes 字节,16KB=16* 1024*1024,肯定比一千万多,在InnoDB中B+树的深度为3层就能满足千万级别的数据存储。
mysql 大字段为什么要拆分?
一个Page页可存放16K的数据,大字段占用大量的存储空间,意味着一个Page页可存储的数据条数变少,那么就需要更多的页来存储,需要更多的Page,意味着树的深度会变高。那么磁盘IO的次数会增加,性能下降,查询更慢。大字段不管是否被使用都会存放在索引上,占据大量内存空间压缩Page数据条数。
为什么用B+树?
B+树的底层是多路平衡查找树,对于每一次的查询的都是从根节点触发,到子叶结点才存放数据,根节点和非叶子结点都是存放的索引指针,查找叶子结点互,可以根据键值数据查询。具备更强的扫库、扫表能力、排序能力以及查询效率和性能的稳定性,存储能力也更强,仅使用三层B+树就能存储千万级别的数据。
刚才看的是根据主键得来的索引,我们如果不查主键,或者说表里压根就没有主键,怎么办?我们还可以根据几个字段来创建联合索引(组合索引聚合索引。。哎呀名字而已怎么叫都行)。
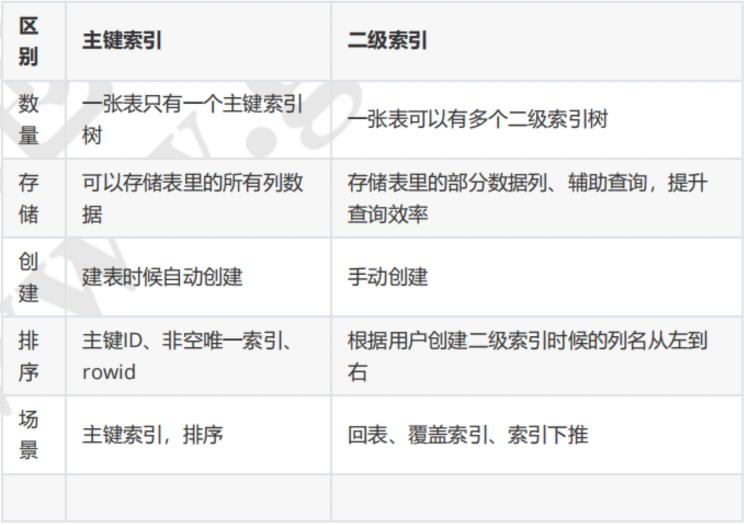
根据主键得到的索引树叫主键索引树,根据别的字段得到的索引树叫二级索引树。
通过下面的SQL 可以建立一个组合索引
ALTER TABLE INNODB_USER ADD INDEX SECOND_INDEX_AGE_USERNAME_PHONE('age','user_name','phone');
其实,看似建立了1个索引,但是你使用 age 查询 age,user_name 查询 age,user_name,phone 都能生效
您也可以认为建立了三个这样的索引:
ALTER TABLE INNODB__USER ADD INDEX SECOND_INDEX_AGE__USERNAME_PHONE('age'); ALTER TABLE INNODB_USER ADD INDEX SECOND_INDEX_AGE_USERNAME_PHONE('age','user_name'); ALTER TABLE `INNODB_USER`ADD INDEX SECOND_INDEX_AGE_USERNAME_PHONE('age','user_name','phone');
首先需要知道参与排序的字段类型是否有有序?
如果是有序字段,就按照有序字段排序比如(int) 1 2 3 4。
如果是无序字段,按照这个列的字符集的排序规则来排序,这点不去深入,知道就好。
我现在有一个组合索引(A-B-C)他会按照你建立字段的顺序来进行排序:
如果A相同按照B排序,如果B相同按照C排序,如果ABC全部相同,会按照聚集索引进行排序。
我们的Page会根据组合索引的字段建立顺序来存储数据,年龄 用户名 手机号。
它的数据结构其实是一样的
还是上面那个索引,年龄用户名手机号,age,username,phone
那么可以看到我们第一个字段是AGE,如果需要这个索引生效,是不是在查询的时候需要先使用Age查询,然后如果还需要user_name,就使用user_name。
只使用了user_name 能使用到索引吗?
其实是不行的,因为我是先使用age进行排序的,你必须先命中age,再命中user_name,再命中phone,这个其实
就是我们所说的最左匹配原则。
最左其实就是因为我们是按照组合索引的顺序来存储的。大家常说的"索引桥"也是这个原因。在命中组合索引中,必须像过桥一样,先跨过第一块木板,再到第二块木板,最后到第三块木板。
二级索引树有三个重要的概念,分别是回表、覆盖索引、索引下推。.
回表就是:我们查询的数据不在二级索引树中需要拿到ID去主键索引树找的过程。
覆盖索引就是:我们需要查询的数据都在二级索引树中,直接返回这种情况就叫做覆盖索引。
索引下推(index condition pushdown )简称ICP:在Mysql5.6以后的版本上推出,用于优化回表查询;
为什么离散度低的列不走索引?
分散の概念とは何ですか?同一のデータが多いほど分散は低くなり、同一のデータが少ないほど分散は高くなります。
データはすべて同じです。どのように並べ替えますか?並べ替えられないんですか?
B ツリーに重複する値が多すぎます。MySQL オプティマイザがインデックス作成がテーブル全体スキャンを使用するのとほぼ同じであると判断すると、インデックスが作成されても実行されません。インデックスを使用するかどうかは、MySQL オプティマイザーによって決定されます。
インデックスは多ければ多いほど良いのでしょうか?
スペースの観点: スペースを時間と交換すると、インデックスがディスクスペースを占有する必要があります。
時間: インデックスをヒットしてクエリの効率を向上させます。更新と削除の場合、ページの分割とマージが発生し、挿入および更新ステートメントの応答時間に影響しますが、パフォーマンスが低下します。
頻繁に更新する必要がある列の場合、ページの分割と結合が頻繁に発生するため、インデックスを作成することはお勧めできません。
結合インデックス (複合インデックス) とも呼ばれるセカンダリ インデックス ツリーは、インデックス作成時に列名の順序を保存します。セカンダリ インデックスの列名の作成に使用されるデータです。セカンダリ インデックス ツリーは、クエリを支援し、クエリの効率を向上させるために生まれました。セカンダリ インデックス ツリーには、テーブル リターン、カバリング インデックス、インデックス プッシュダウンの 3 つのアクションがあります。その中で最もパフォーマンスが高いのはカバリングインデックスです。
インターネットで違いの画像を見つけました
以上がMySQL インデックスのナレッジ ポイント分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



