


まず、関連する背景を共有しましょう。
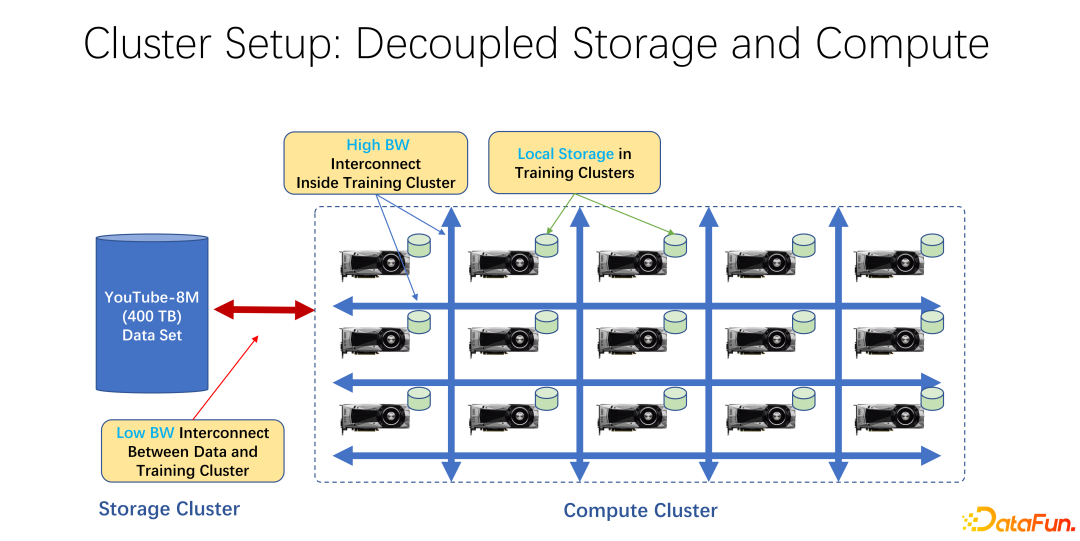
近年、AIトレーニングの活用が広がっています。インフラストラクチャの観点から見ると、ビッグ データであろうと AI トレーニング クラスターであろうと、そのほとんどはストレージとコンピューティングを分離したアーキテクチャを使用しています。たとえば、多くの GPU アレイが大規模なコンピューティング クラスターに配置され、もう 1 つのクラスターはストレージです。 Microsoft の Azure や Amazon の S3 などのクラウド ストレージを使用している場合もあります。
このようなインフラストラクチャの特徴は、まず、コンピューティング クラスター内に非常に高価な GPU が多数存在し、各 GPU が一定量の GPU を備えていることが多いことです。 SSD などのローカル ストレージ、数十テラバイトのストレージ。このようなマシン群では、リモートエンドとの接続に高速ネットワークが使用されることが多く、たとえば、Coco、image net、YouTube 8M などの非常に大規模な学習データがネットワーク経由で接続されます。
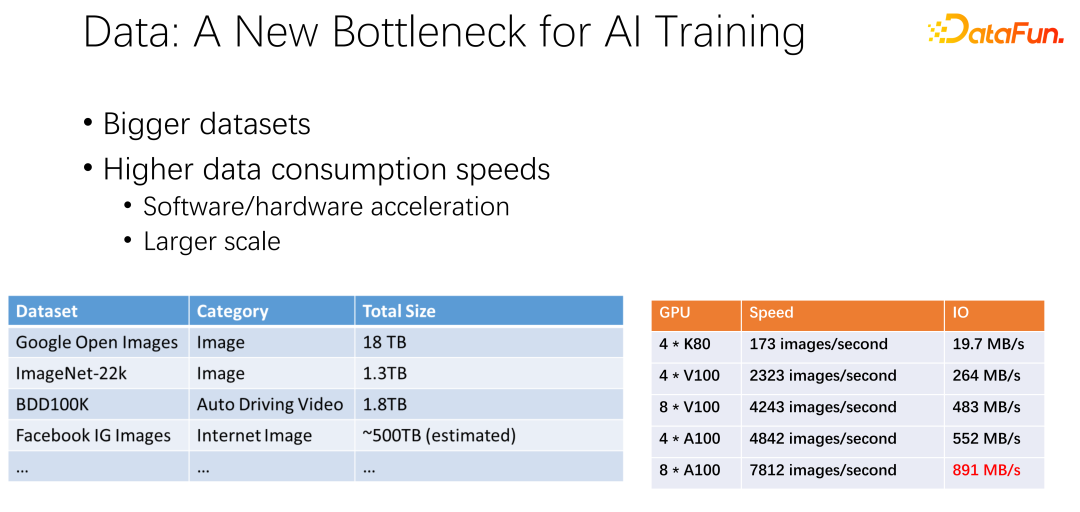
#上図に示すように、次の AI トレーニングではデータがボトルネックになる可能性があります。データセットがますます大きくなり、AI がより広く使用されるにつれて、より多くのトレーニング データが蓄積されていることが観察されています。同時に、GPU トラックのボリュームは非常に大きくなります。たとえば、AMD や TPU などのメーカーは、GPU や TPU などのアクセラレータをますます高速化するために、ハードウェアとソフトウェアの最適化に多大なエネルギーを費やしてきました。アクセラレータが社内で広く使用されるにつれて、クラスタの導入はますます大規模になっています。ここの 2 つの表は、データセットと GPU 速度間の変動を示しています。以前のK80からV100、P100、A100と速度が非常に速くなりました。ただし、GPU が高速になるにつれて、GPU はますます高価になります。 IO 速度などのデータが GPU の速度に追いつくことができるかどうかは大きな課題です。

#上の図に示すように、多くの大企業のアプリケーションで次のような現象が観察されています。読み取り リモート データにアクセスするとき、GPU はアイドル状態になります。 GPU はリモート データの読み取りを待機しているため、IO がボトルネックになり、高価な GPU が無駄になります。このボトルネックを軽減するために多くの最適化作業が行われており、キャッシュは最も重要な最適化の方向性の 1 つです。ここでは 2 つの方法を説明します。
 最初のタイプは、多くのアプリケーション シナリオ、特に K8s と Docker などの基本的な AI トレーニング アーキテクチャで、大量のローカル ディスクが使用されることです。 。前述したように、GPU マシンには特定のローカル ストレージがあり、ローカル ディスクを使用してキャッシュを実行し、最初にデータをキャッシュすることができます。
最初のタイプは、多くのアプリケーション シナリオ、特に K8s と Docker などの基本的な AI トレーニング アーキテクチャで、大量のローカル ディスクが使用されることです。 。前述したように、GPU マシンには特定のローカル ストレージがあり、ローカル ディスクを使用してキャッシュを実行し、最初にデータをキャッシュすることができます。
GPU Docker を起動したら、すぐに GPU AI トレーニングを開始するのではなく、最初にデータをダウンロードしたり、リモート エンドから Docker にデータをダウンロードしたり、マウントしたりするなどの処理を行います。 Docker にダウンロードしたらトレーニングを開始します。このようにして、後続のトレーニング データの読み取りを可能な限りローカル データの読み取りに切り替えることができます。ローカル IO のパフォーマンスは、現時点では GPU トレーニングをサポートするのに十分です。 VLDB 2020 には、データ キャッシュ用の DALI に基づく CoorDL という論文があります。
この方法には多くの問題も伴います。まず、ローカル領域が限られているため、キャッシュされるデータも限られており、データセットがますます大きくなると、すべてのデータをキャッシュすることが困難になります。さらに、AI シナリオとビッグ データ シナリオの大きな違いは、AI シナリオのデータ セットが比較的限定されていることです。多数のテーブルとさまざまなビジネスが存在するビッグ データ シナリオとは異なり、各ビジネスのデータ テーブル間のコンテンツのギャップは非常に大きくなります。 AI シナリオでは、データ セットのサイズと数は、ビッグ データ シナリオよりもはるかに小さくなります。そのため、社内で提出された多くのタスクが同じデータを読み込むことがよくあります。全員がデータを自分のローカル マシンにダウンロードした場合、データを共有することはできず、データの多数のコピーがローカル マシンに繰り返し保存されることになります。このアプローチには明らかに多くの問題があり、十分に効率的ではありません。 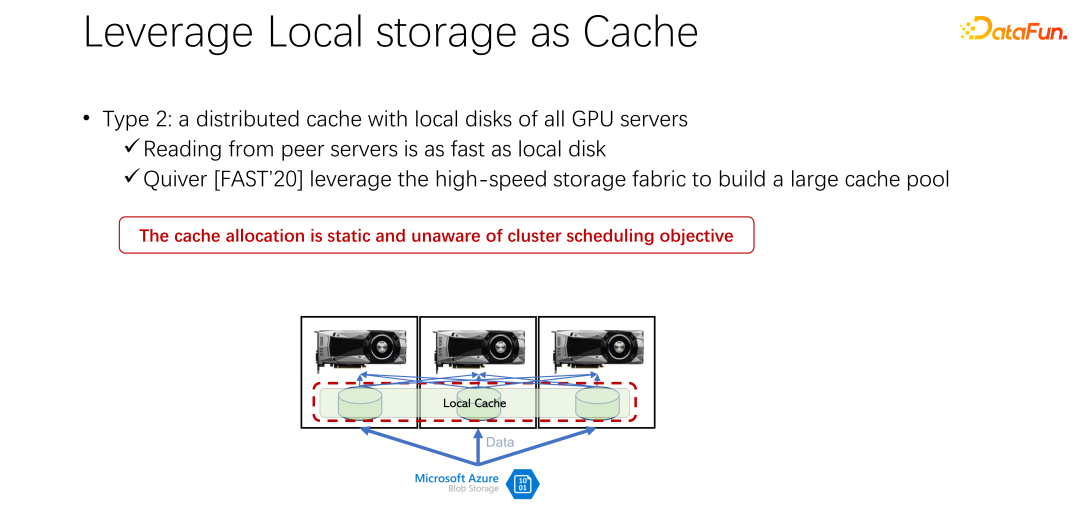
iver というタイトルの論文で、このソリューションについて言及されています。しかし、私たちの分析では、このような一見完璧に見える割り当て計画はまだ比較的静的であり、効率的ではないことがわかりました。同時に、どのようなキャッシュ削除アルゴリズムを使用するかについても議論に値する問題です。
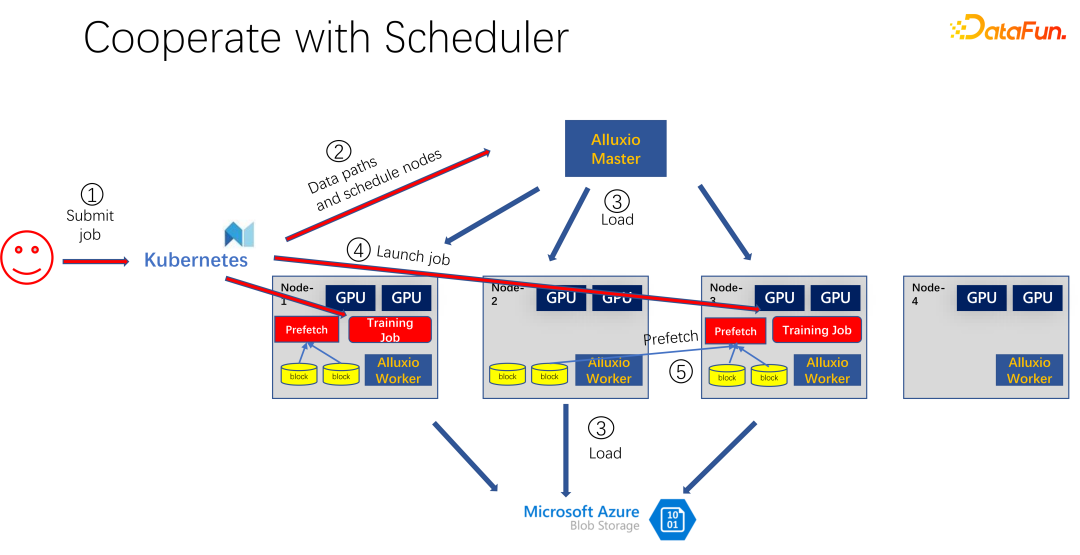
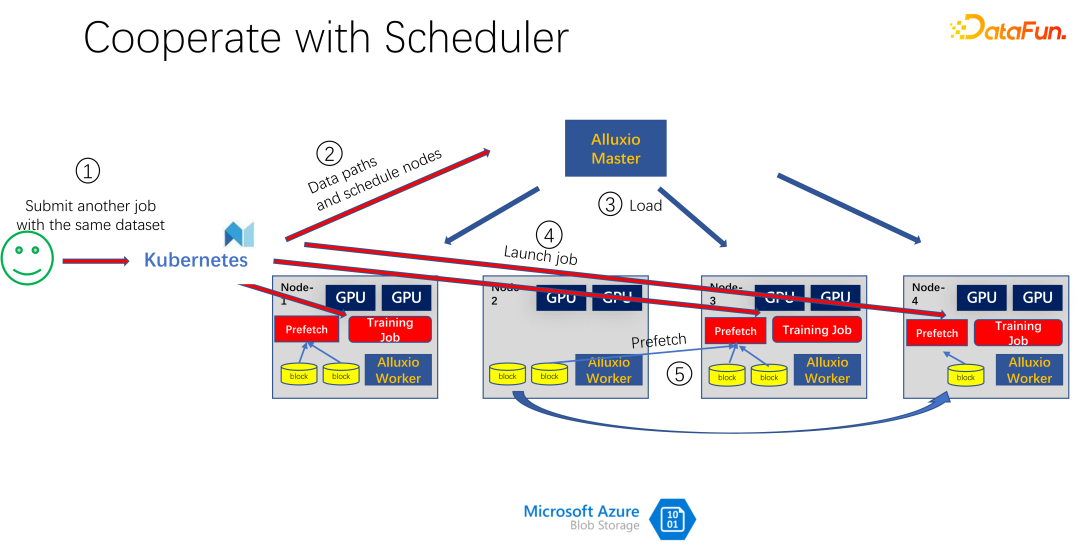
#上図にあるように、Alluxio をキャッシュとして使用するアプリケーションですAIトレーニング用。 K8s を使用して、クラスター タスク全体をスケジュールし、GPU、CPU、メモリなどのリソースを管理します。ユーザーが K8s にタスクを送信すると、K8s はまずプラグインを作成し、Alluxio マスターにデータのこの部分をダウンロードするように通知します。つまり、最初にウォームアップを行い、ジョブに必要なタスクをいくつかキャッシュしてみます。もちろん、Alluxio は持っているだけのデータを使用するため、完全にキャッシュする必要はありません。残りがまだキャッシュされていない場合は、リモート エンドから読み取られます。さらに、Alluxio マスターがそのようなコマンドを取得した後、ワーカーにリモート エンドに行くように要求できます。それはクラウド ストレージである場合もありますし、データをダウンロードしている Hadoop クラスターである場合もあります。この時点で、K8s は GPU クラスターへのジョブもスケジュールします。たとえば、上の図では、このようなクラスターでは、最初のノードと 3 番目のノードを選択してトレーニング タスクを開始します。トレーニング タスクを開始した後、データを読み取る必要があります。 PyTorch や Tensorflow などの現在の主流フレームワークには、データの事前読み取りを意味する Prefetch も組み込まれています。事前にキャッシュされた Alluxio のキャッシュ データを読み取り、トレーニング データの IO をサポートします。もちろん、読み込まれていないデータがあることが判明した場合、Alluxio はリモートから読み込むこともできます。 Alluxio は統合インターフェイスとして優れています。同時に、ジョブ間でデータを共有することもできます。
最初の問題は、AI シナリオではデータへのアクセス モードが過去とは大きく異なるため、キャッシュ削除アルゴリズムが非常に非効率であるということです。 2 番目の問題は、リソースとしてのキャッシュが帯域幅 (つまり、リモート ストレージの読み取り速度) と相反する関係にあることです。キャッシュが大きい場合、リモート エンドからデータを読み取る可能性は低くなります。キャッシュが小さい場合、リモート エンドから大量のデータを読み取る必要があります。これらのリソースをどのようにスケジュールして適切に割り当てるかも考慮する必要がある問題です。
#キャッシュ削除アルゴリズムについて説明する前に、まず AI トレーニングにおけるデータ アクセスのプロセスを見てみましょう。 AI のトレーニングでは、多くのエポックに分割され、反復的にトレーニングされます。各トレーニング エポックでは、各データが 1 回だけ読み取られます。トレーニングの過剰適合を防ぐために、各エポックが終了した後、次のエポックでは読み取り順序が変更され、シャッフルが実行されます。つまり、すべてのデータはエポックごとに 1 回読み取られますが、順序は異なります。 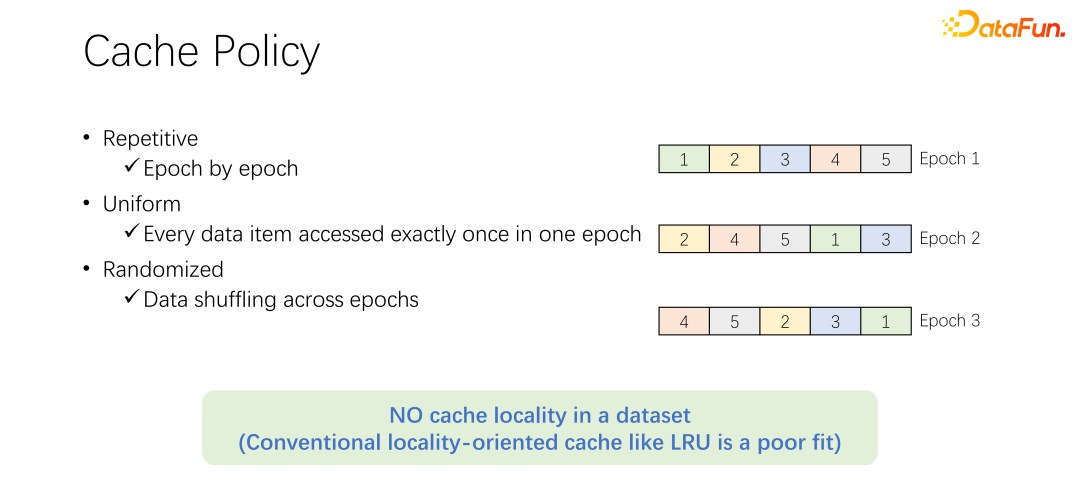

#上記の例に示すように。上が LRU アルゴリズム、下が等化方法です。最初にキャッシュできるデータは 2 つだけです。問題を単純化してみると、キャッシュ D と B の 2 つの容量しかなく、真ん中がアクセス順序です。たとえば、最初にアクセスされたのは B です。LRU の場合、B がキャッシュにヒットします。次のアクセスは C です。C は D と B のキャッシュにありません。したがって、LRU ポリシーに基づいて、D が置き換えられ、C は保持されます。つまり、この時のキャッシュはCとBです。次に訪れるのはAですが、これもCとBにはありません。したがって、B は削除され、C と A に置き換えられます。次は D ですが、D はキャッシュにないため、D と A に置き換えられます。類推すると、後続のアクセスはすべてキャッシュにヒットしないことがわかります。その理由は、LRU キャッシュが実行されると、LRU キャッシュが置き換えられるためですが、実際には、エポック内で一度アクセスされており、このエポック内で再度アクセスされることはありません。代わりに LRU がキャッシュしますが、LRU は役に立たないだけでなく、実際には状況を悪化させます。以下のような方法で統一した方が良いでしょう。
#次の統一メソッドでは、D と B が常にキャッシュにキャッシュされ、置換は行われません。この場合、少なくとも 50% のヒット率が得られます。したがって、キャッシュ アルゴリズムは複雑である必要はなく、LRU や LFU などのアルゴリズムを使用せず、均一なアルゴリズムを使用するだけであることがわかります。
2 番目の質問については、キャッシュとリモート帯域幅の関係についてです。データの先読みは、GPU がデータを待つのを防ぐために、すべての主流の AI フレームワークに組み込まれています。したがって、GPU がトレーニングしているとき、実際には CPU が次のラウンドで使用される可能性のあるデータを事前に準備するようにトリガーされます。これにより、GPU の計算能力を最大限に活用できます。しかし、リモート ストレージの IO がボトルネックになると、GPU が CPU を待たなければならないことになります。したがって、GPU のアイドル時間が長くなり、リソースが無駄になります。 IO の問題を軽減するための、より良いスケジュール管理方法が存在することを願っています。

#キャッシュとリモート IO は、ジョブ全体のスループットに大きな影響を与えます。したがって、GPU、CPU、メモリに加えて、キャッシュとネットワークもスケジュールする必要があります。 Hadoop、yarn、マイソース、K8s などのこれまでのビッグデータの開発プロセスでは、主に CPU、メモリ、GPU がスケジュールされていました。ネットワーク、特にキャッシュの制御があまり良くありません。したがって、AI シナリオでは、クラスター全体の最適化を達成するために、AI を適切にスケジュールして割り当てる必要があると考えています。

EuroSys 2023 で公開された記事、これは、コンピューティング リソースとストレージ リソースをスケジュールするための統合フレームワークです。
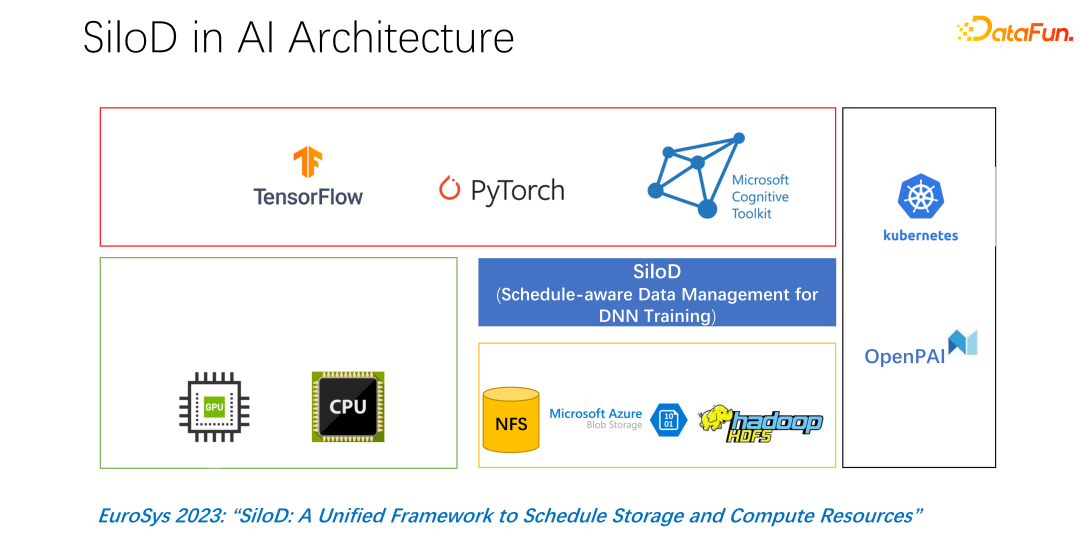 #全体的なアーキテクチャを上の図に示します。左下隅は、クラスター内の CPU および GPU ハードウェア コンピューティング リソースと、NFS、クラウド ストレージ HDFS などのストレージ リソースです。上位レベルには、TensorFlow、PyTorch などの AI トレーニング フレームワークがいくつかあります。私たちは、コンピューティング リソースとストレージ リソースを一元的に管理し、割り当てるプラグインを追加する必要があると考えており、これが SiloD を提案したものです。
#全体的なアーキテクチャを上の図に示します。左下隅は、クラスター内の CPU および GPU ハードウェア コンピューティング リソースと、NFS、クラウド ストレージ HDFS などのストレージ リソースです。上位レベルには、TensorFlow、PyTorch などの AI トレーニング フレームワークがいくつかあります。私たちは、コンピューティング リソースとストレージ リソースを一元的に管理し、割り当てるプラグインを追加する必要があると考えており、これが SiloD を提案したものです。
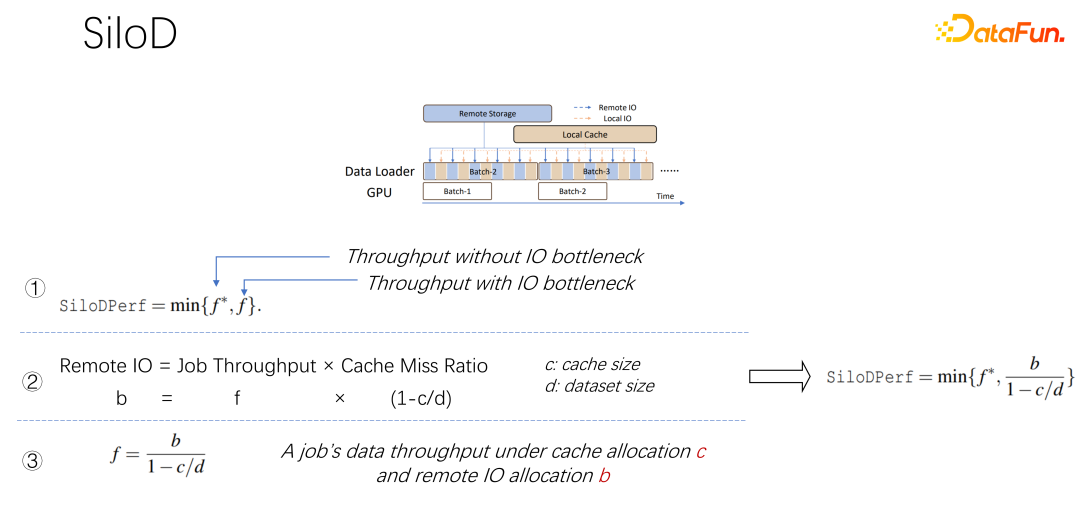
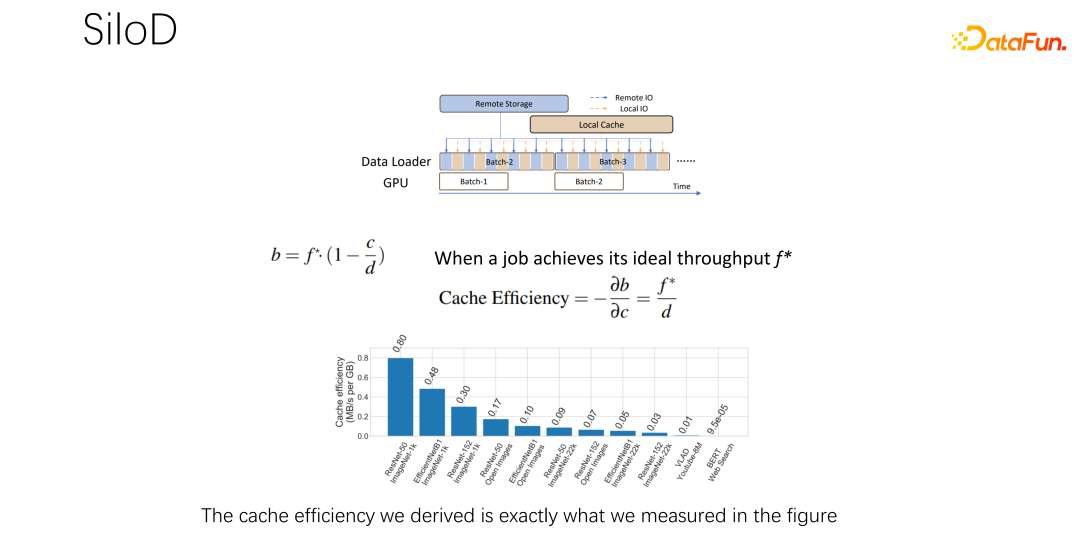
上記の観察に基づくと、SiloD はキャッシュとネットワーク割り当てに使用できます。さらに、キャッシュのサイズは、各ジョブの速度とデータセット全体のサイズに基づいて割り当てられます。ウェブについても同様です。全体のアーキテクチャは次のようになります。K8 のような主流のジョブ スケジューリングに加えて、データ管理もあります。たとえば、図の左側では、キャッシュ管理には、クラスター全体に割り当てられたキャッシュ サイズ、各ジョブのキャッシュ サイズ、および各ジョブが使用するリモート IO のサイズの統計または監視が必要です。次の操作は Alluxio メソッドと非常に似ており、どちらもデータ トレーニングに API を使用できます。各ワーカーでキャッシュを使用して、ローカル ジョブのキャッシュ サポートを提供します。もちろん、クラスター内のノードにまたがることもでき、共有することもできます。
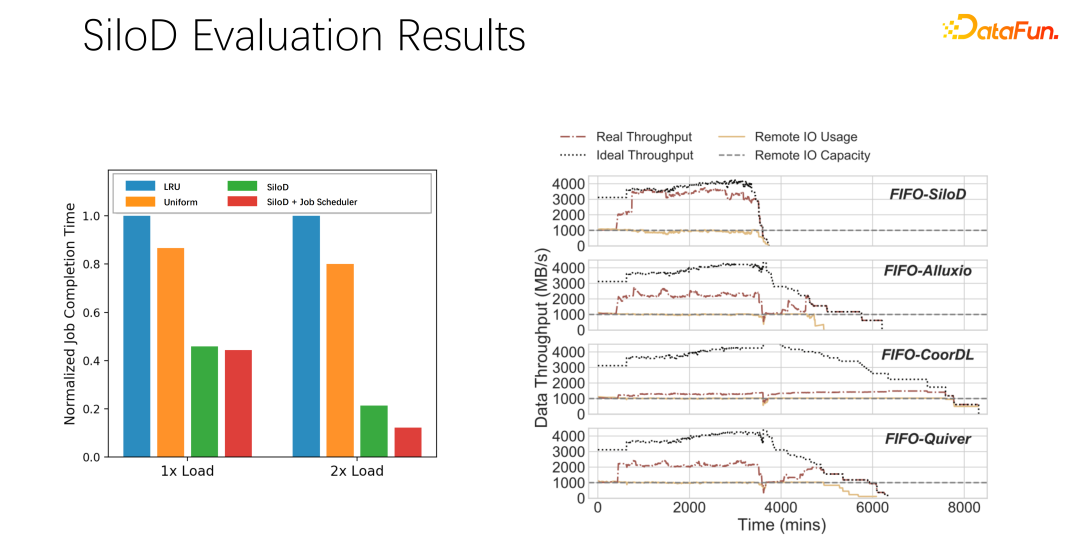
予備的なテストと実験の結果、このような割り当て方法により、システム全体の使用率とスループットが向上することがわかりました。クラスター。非常に明らかな改善であり、最大 8 倍のパフォーマンス向上に達する可能性があります。これにより、ジョブの待機状態や GPU のアイドル状態が明らかに軽減されます。

上記の紹介を要約しましょう:
まず、AI やディープ ラーニングのトレーニング シナリオでは、LRU や LFU などの従来のキャッシュ戦略は適していません。uniform を直接使用することをお勧めします。
#第 2 に、#キャッシュとリモート帯域幅はペアのパートナーであり、全体的に大きな役割を果たします。パフォーマンスの役割。
3 番目、K8 や Yarn などの主要なスケジューリング フレームワークは、SiloD から簡単に継承できます。
最後に、論文ではいくつかの実験を行いました。さまざまなスケジューリング戦略により、スループットが明らかに向上しました。 。
#3. 分散キャッシュ戦略とコピー管理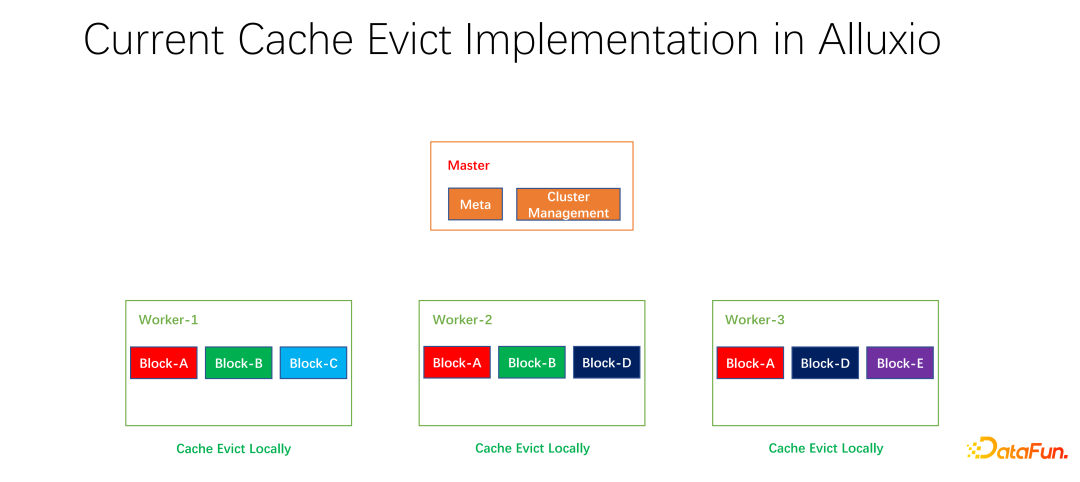
私たちはオープンソースの取り組みも行ってきました。分散キャッシュ戦略とレプリカ管理に関するこの取り組みはコミュニティに提出され、現在 PR 段階にあります。 Alluxio マスターは主に、メタの管理とワーカー クラスター全体の管理を担当します。実際にデータをキャッシュするのはワーカーです。データをキャッシュするブロック単位には多数のブロックが存在します。 1 つの問題は、現在のキャッシュ戦略が 1 つのワーカーを対象としているため、ワーカー内の各データを削除するかどうかを計算する場合、1 つのワーカーでのみ計算する必要があり、ローカライズされているということです。
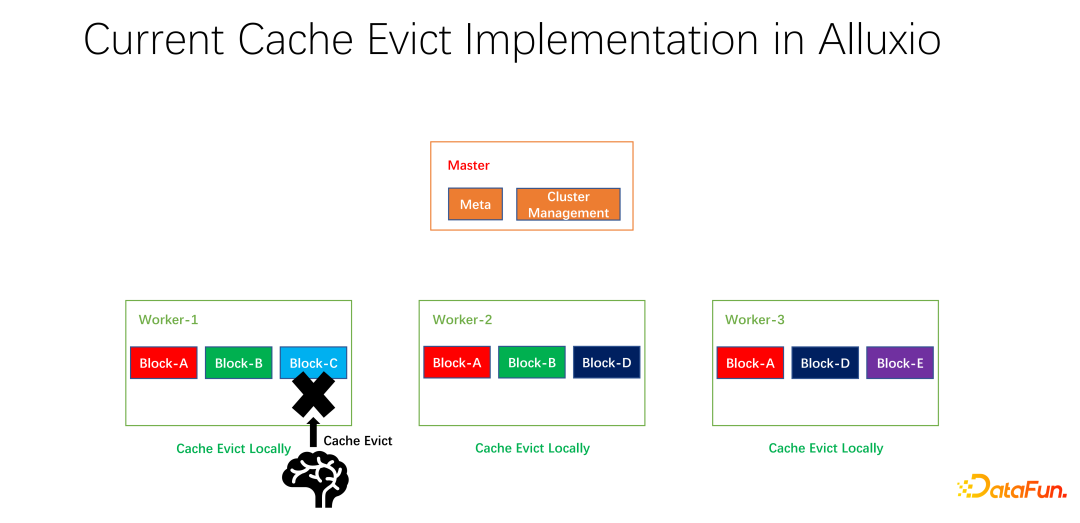
#
上の図に示すように、私たちが行うことは、各ワーカーのレプリカ情報を維持することです。たとえば、ワーカーがコピーを追加したり、コピーを削除したりすると、最初にマスターに報告され、マスターはこの情報をハートビートの戻り値として使用し、関連する他のワーカーに返します。他のワーカーは、グローバル コピー全体のリアルタイムの変更を知ることができます。同時にコピー情報も更新されます。したがって、内部ワーカーを削除する場合、各ワーカーが全世界に何個のコピーを持っているかを知ることができ、いくつかの重みを設計できます。たとえば、LRU は引き続き使用されますが、どのデータを削除して置き換えるかを総合的に検討するために、レプリカの数の重みが追加されます。
#予備テストの後、ビッグデータであれ AI トレーニングであれ、多くの分野で大きな改善がもたらされる可能性があります。つまり、1 台のマシン上の 1 人のワーカーのキャッシュ ヒットを最適化するだけではありません。私たちの目標は、クラスター全体のキャッシュ ヒット率を向上させることです。

最後に全文を要約してみます。まず、AI トレーニング シナリオでは、均一なキャッシュ削除アルゴリズムが従来の LRU や LFU よりも優れています。次に、キャッシュとリモート ネットワーキングも、割り当てとスケジュール設定が必要なリソースです。第三に、キャッシュを最適化するときは、1 つのジョブや 1 つのワーカーに限定するのではなく、エンドツーエンドのグローバル パラメーター全体を考慮して、クラスター全体の効率とパフォーマンスを向上させる必要があります。
以上が大規模な深層学習トレーニングのためのキャッシュ最適化の実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



