

MySQL で重複したクエリを削除する方法は何ですか?

1. テスト データの挿入
下図のテスト データでは、user_name が lilei と zhaofeng であるユーザーが重複データです。
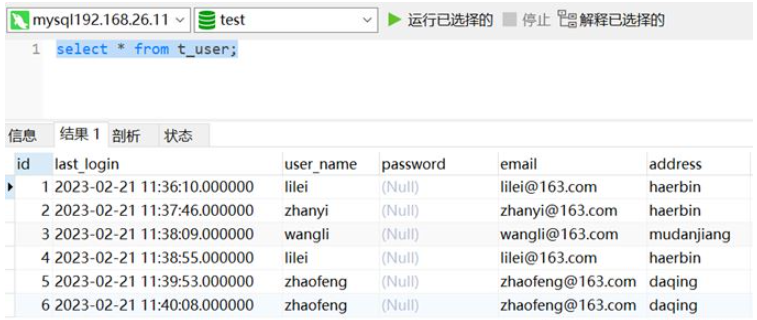
2. 重複データを削除する方法
1. 方法 1: unique を使用する
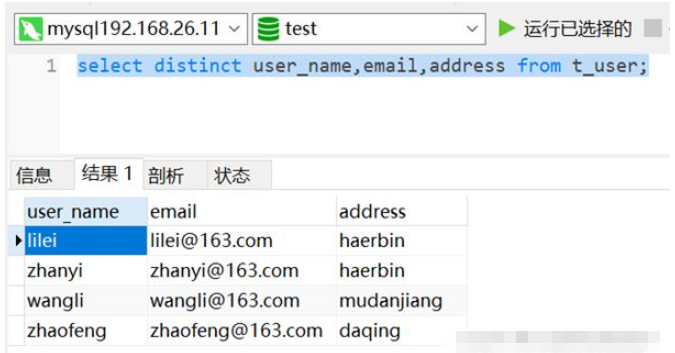
コードは次のとおりです ( example):
select distinct user_name,email,address from t_user;
以下に示すように、データは重複排除されており、重複データは 1 つだけ保持されています。
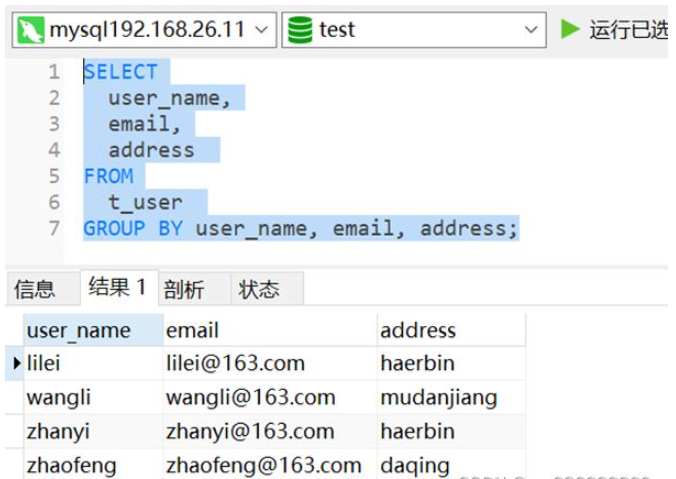
2. 方法 2: 以下に示すように、group by
SELECT user_name,email,address FROM t_user GROUP BY user_name, email, address;
を使用します。データは重複排除されており、重複データ 1 つだけが保持されます。
3. 方法 3: ウィンドウ関数を使用する
(1) データベースが MySQL8 以降の場合は、ウィンドウ関数 row_number( )
SELECT *
FROM(
SELECT t.*,
ROW_NUMBER() OVER(PARTITION BY user_name
ORDER BY last_login DESC) rn
FROM table AS t
) AS t_user
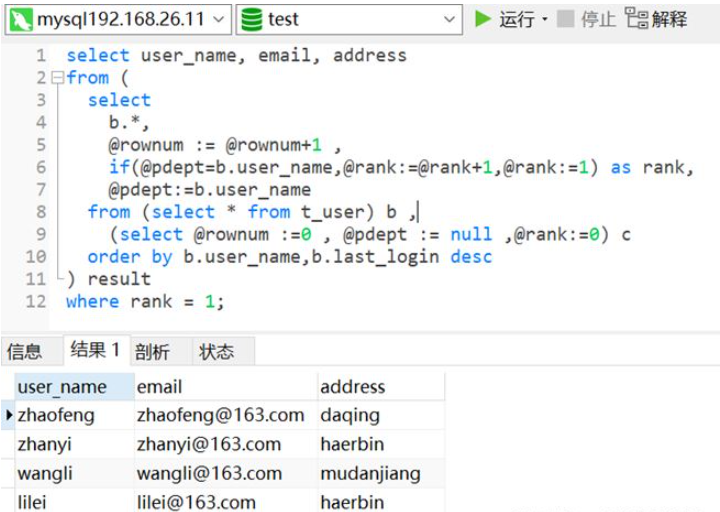
WHERE rn = 1;(2) データベースのバージョンが MySQL8 より低い場合は、以下に示すようにクラス row_number() メソッド
select user_name, email, address from ( select b.*, @rownum := @rownum+1 ,-- 定义用户变量@rownum来记录数据的行号 if(@pdept=b.user_name,@rank:=@rank+1,@rank:=1) as rank,-- 如果当前分组user_name和上一次分组user_name相同,则@rank(对每一组的数据进行编号)值加1,否则表示为新的分组,从1开始 @pdept:=b.user_name -- 定义变量@pdept用来保存上一次的分组id from (select * from t_user) b , (select @rownum :=0 , @pdept := null ,@rank:=0) c -- 初始化自定义变量值 order by b.user_name,b.last_login desc -- 该排序必须,否则结果会不对 ) result where rank = 1;
を使用します。データは重複排除されており、重複データは 1 つだけ保持されます。 。
以上がMySQL で重複したクエリを削除する方法は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7476
7476
 15
1377
52
77
11
19
32
15
1377
52
77
11
19
32

 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICAT自体はデータベースパスワードを保存せず、暗号化されたパスワードのみを取得できます。解決策:1。パスワードマネージャーを確認します。 2。NAVICATの「パスワードを記憶する」機能を確認します。 3.データベースパスワードをリセットします。 4.データベース管理者に連絡してください。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 MySQLでテーブルをコピーする方法
Apr 08, 2025 pm 07:24 PM
MySQLでテーブルをコピーする方法
Apr 08, 2025 pm 07:24 PM
MySQLでテーブルをコピーするには、新しいテーブルの作成、データの挿入、外部キーの設定、インデックスのコピー、トリガー、ストアドプロシージャ、および機能が必要です。特定の手順には、同じ構造を持つ新しいテーブルの作成が含まれます。元のテーブルからデータを新しいテーブルに挿入します。同じ外部キーの制約を設定します(元のテーブルに1つがある場合)。同じインデックスを作成します。同じトリガーを作成します(元のテーブルに1つがある場合)。同じストアドプロシージャまたは関数を作成します(元のテーブルが使用されている場合)。
 mysqlを表示する方法
Apr 08, 2025 pm 07:21 PM
mysqlを表示する方法
Apr 08, 2025 pm 07:21 PM
次のコマンドでmysqlデータベースを表示します。サーバーに接続します:mysql -u username -pパスワードrun showデータベース。すべての既存のデータベースを取得するコマンド[データベース]を選択します。データベース名を使用します。テーブルを表示:表を表示します。テーブル構造を表示:テーブル名を説明してください。データを表示:[テーブル名]から[ *]を選択します。
 MariadBのNAVICATでデータベースパスワードを表示する方法は?
Apr 08, 2025 pm 09:18 PM
MariadBのNAVICATでデータベースパスワードを表示する方法は?
Apr 08, 2025 pm 09:18 PM
Passwordが暗号化された形式で保存されているため、MariadbのNavicatはデータベースパスワードを直接表示できません。データベースのセキュリティを確保するには、パスワードをリセットするには3つの方法があります。NAVICATを介してパスワードをリセットし、複雑なパスワードを設定します。構成ファイルを表示します(推奨されていない、高リスク)。システムコマンドラインツールを使用します(推奨されません。コマンドラインツールに習熟する必要があります)。
 NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する手順:データベースに接続します。 SQLエディターウィンドウを作成します。 SQLクエリまたはスクリプトを書きます。 [実行]ボタンをクリックして、クエリまたはスクリプトを実行します。結果を表示します(クエリが実行された場合)。
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
