

Redis キャッシュスペースを最適化する方法

シーン設定
1. POJOをキャッシュに保存する必要があります。クラスは次のように定義されています
public class TestPOJO implements Serializable {
private String testStatus;
private String userPin;
private String investor;
private Date testQueryTime;
private Date createTime;
private String bizInfo;
private Date otherTime;
private BigDecimal userAmount;
private BigDecimal userRate;
private BigDecimal applyAmount;
private String type;
private String checkTime;
private String preTestStatus;
public Object[] toValueArray(){
Object[] array = {testStatus, userPin, investor, testQueryTime,
createTime, bizInfo, otherTime, userAmount,
userRate, applyAmount, type, checkTime, preTestStatus};
return array;
}
public CreditRecord fromValueArray(Object[] valueArray){
//具体的数据类型会丢失,需要做处理
}
}2. 次の例をテストデータとして使用します
TestPOJO pojo = new TestPOJO();
pojo.setApplyAmount(new BigDecimal("200.11"));
pojo.setBizInfo("XX");
pojo.setUserAmount(new BigDecimal("1000.00"));
pojo.setTestStatus("SUCCESS");
pojo.setCheckTime("2023-02-02");
pojo.setInvestor("ABCD");
pojo.setUserRate(new BigDecimal("0.002"));
pojo.setTestQueryTime(new Date());
pojo.setOtherTime(new Date());
pojo.setPreTestStatus("PROCESSING");
pojo.setUserPin("ABCDEFGHIJ");
pojo.setType("Y");一般的な方法
System.out.println(JSON.toJSONString(pojo).length());
JSON を使用して直接シリアル化して出力する length=284**、**この方法は最も簡単な方法です。これは最も一般的に使用される方法でもあります。具体的なデータは次のとおりです:
{"applyAmount":200.11,"bizInfo":"XX","checkTime":"2023-02-02","投資家":"ABCD ","otherTime":"2023-04-10 17:45:17.717","preCheckStatus":"PROCESSING","testQueryTime":"2023-04-10 17:45:17.717"," testStatus":"SUCCESS ","type":"Y","userAmount":1000.00,"userPin":"ABCDEFGHIJ","userRate":0.002}
上記には多くのものが含まれていることがわかりました。属性名を含む無駄なデータは保存する必要はありません。
改善 1-属性名の削除
System.out.println(JSON.toJSONString(pojo.toValueArray()).length());
オブジェクト構造の代わりに配列構造を選択すると、属性名が削除され、length=144 が印刷されます。データサイズが 50% 削減されました。具体的なデータは次のとおりです:
["SUCCESS","ABCDEFGHIJ","ABCD","2023-04-10 17: 45:17.717",null,"XX"," 2023-04-10 17:45:17.717",1000.00,0.002,200.11,"Y","2023-02-02","処理中"]
null を格納する必要がないことがわかりました。時刻形式は文字列にシリアル化されます。不当なシリアル化の結果はデータの拡張につながるため、より適切なシリアル化ツールを選択する必要があります。
改善 2 - より優れたシリアル化ツールを使用する
//我们仍然选取JSON格式,但使用了第三方序列化工具 System.out.println(new ObjectMapper(new MessagePackFactory()).writeValueAsBytes(pojo.toValueArray()).length);
より優れたシリアル化ツールを選択して、フィールド圧縮と適切なデータ形式を実現します。print** length=92、スペースが削減されます。前のステップと比較して 40% 増加しました。
これはバイナリ データです。Redis はバイナリで操作する必要があります。バイナリを文字列に変換した後、次のように出力します:
��SUCCESS�ABCDEFGHIJ�ABCD� � j�6� �XX� �j�6� �?`bM����@i � �Q�Y�2023-02-02�PROCESSING
このアイデアに従ってさらに掘り下げて、データ型を手動で選択することで、より極端な最適化効果を達成できることがわかりました。より小さいデータ型を使用することを選択すると、さらに改善が得られます。
改善 3-データ型の最適化
上記の使用例では、testStatus、preCheckStatus、investor の 3 つのフィールドは実際には列挙文字列型です。文字列の代わりにデータ型 (byte や int など) を使用すると、スペースをさらに節約できます。 checkTime を表す文字列の代わりに Long 型を使用すると、シリアル化ツールが出力するバイト数が少なくなります。
public Object[] toValueArray(){
Object[] array = {toInt(testStatus), userPin, toInt(investor), testQueryTime,
createTime, bizInfo, otherTime, userAmount,
userRate, applyAmount, type, toLong(checkTime), toInt(preTestStatus)};
return array;
}手動調整後、文字列型の代わりに小さなデータ型が使用され、印刷されますlength=69
改善点 4-ZIP 圧縮の検討
上記の点に加えて、より小さなボリュームを取得するために ZIP 圧縮の使用を検討することもできます。コンテンツが大きい場合や繰り返しが多い場合、ZIP 圧縮の効果は明らかです。ストレージがコンテンツの場合、コンテンツは配列ですおそらく ZIP 圧縮での使用に適しています。
30 バイト未満のファイルの場合、ZIP 圧縮によってファイル サイズが増加する可能性がありますが、必ずしもファイル サイズが減少するとは限りません。繰り返しの少ないコンテンツの場合、大幅な改善は得られません。そしてCPUのオーバーヘッドも発生します。
上記の最適化後、ZIP 圧縮は必須のオプションではなくなり、ZIP 圧縮の効果を判断するには実際のデータに基づくテストが必要になります。
ついに実装されました
上記の改善手順は最適化のアイデアを反映していますが、逆シリアル化プロセスにより型の損失が発生し、処理がさらに面倒になるため、逆シリアル化の問題も考慮する必要があります。
キャッシュ オブジェクトが事前に定義されている場合、各フィールドを手動で完全に処理できるため、実際の戦闘では、上記の目的を達成し、洗練された制御を実現し、最適な圧縮を実現するために、手動シリアル化を使用することをお勧めします。効果があり、パフォーマンスのオーバーヘッドが最小限に抑えられます。
次の msgpack 実装コードを参照できます。以下はテスト コードです。より優れた Packer および UnPacker ツールを自分でパッケージ化してください:
<dependency>
<groupId>org.msgpack</groupId>
<artifactId>msgpack-core</artifactId>
<version>0.9.3</version>
</dependency> public byte[] toByteArray() throws Exception {
MessageBufferPacker packer = MessagePack.newDefaultBufferPacker();
toByteArray(packer);
packer.close();
return packer.toByteArray();
}
public void toByteArray(MessageBufferPacker packer) throws Exception {
if (testStatus == null) {
packer.packNil();
}else{
packer.packString(testStatus);
}
if (userPin == null) {
packer.packNil();
}else{
packer.packString(userPin);
}
if (investor == null) {
packer.packNil();
}else{
packer.packString(investor);
}
if (testQueryTime == null) {
packer.packNil();
}else{
packer.packLong(testQueryTime.getTime());
}
if (createTime == null) {
packer.packNil();
}else{
packer.packLong(createTime.getTime());
}
if (bizInfo == null) {
packer.packNil();
}else{
packer.packString(bizInfo);
}
if (otherTime == null) {
packer.packNil();
}else{
packer.packLong(otherTime.getTime());
}
if (userAmount == null) {
packer.packNil();
}else{
packer.packString(userAmount.toString());
}
if (userRate == null) {
packer.packNil();
}else{
packer.packString(userRate.toString());
}
if (applyAmount == null) {
packer.packNil();
}else{
packer.packString(applyAmount.toString());
}
if (type == null) {
packer.packNil();
}else{
packer.packString(type);
}
if (checkTime == null) {
packer.packNil();
}else{
packer.packString(checkTime);
}
if (preTestStatus == null) {
packer.packNil();
}else{
packer.packString(preTestStatus);
}
}
public void fromByteArray(byte[] byteArray) throws Exception {
MessageUnpacker unpacker = MessagePack.newDefaultUnpacker(byteArray);
fromByteArray(unpacker);
unpacker.close();
}
public void fromByteArray(MessageUnpacker unpacker) throws Exception {
if (!unpacker.tryUnpackNil()){
this.setTestStatus(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setUserPin(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setInvestor(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setTestQueryTime(new Date(unpacker.unpackLong()));
}
if (!unpacker.tryUnpackNil()){
this.setCreateTime(new Date(unpacker.unpackLong()));
}
if (!unpacker.tryUnpackNil()){
this.setBizInfo(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setOtherTime(new Date(unpacker.unpackLong()));
}
if (!unpacker.tryUnpackNil()){
this.setUserAmount(new BigDecimal(unpacker.unpackString()));
}
if (!unpacker.tryUnpackNil()){
this.setUserRate(new BigDecimal(unpacker.unpackString()));
}
if (!unpacker.tryUnpackNil()){
this.setApplyAmount(new BigDecimal(unpacker.unpackString()));
}
if (!unpacker.tryUnpackNil()){
this.setType(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setCheckTime(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setPreTestStatus(unpacker.unpackString());
}
}シナリオ拡張機能
2 億ユーザーのデータを保存すると仮定します。各ユーザーには 40 個のフィールドが含まれます。フィールド キーの長さは 6 バイトで、フィールドは個別に管理されます。
通常の状況では、ハッシュ構造を考えますが、ハッシュ構造にはキー情報が格納されるため、追加のリソースが占有されます。フィールドのキーは不要なデータです。上記の考え方によれば、代わりにリストを使用できます。ハッシュ構造の。
Redis 公式ツールのテストによると、リスト構造の使用には 144G のスペースが必要ですが、ハッシュ構造の使用には 245G のスペースが必要です** (属性の 50% 以上が空の場合は、これはまだ適用可能です)* *
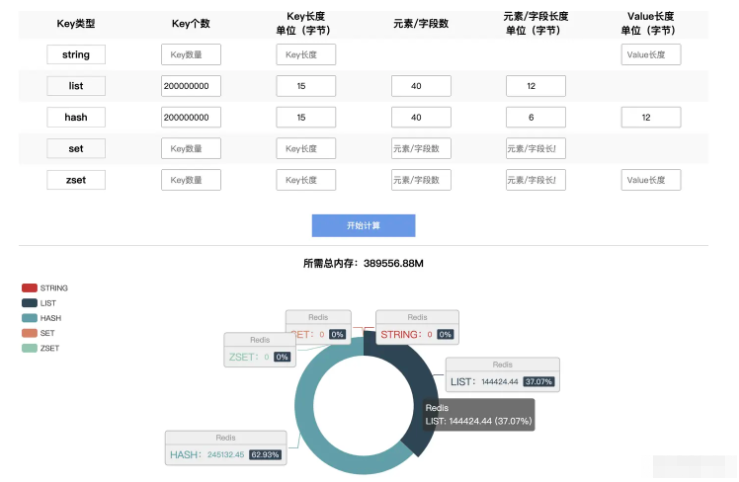
上記の例では、数行の簡単なコードで非常に簡単な措置をいくつか講じました。これにより、スペースをさらに削減できます。データ量が比較的大きい場合、大規模で高いパフォーマンス要件が必要なシナリオでは、これを強くお勧めします。 :
• オブジェクトの代わりに配列を使用します (多数のフィールドが空の場合は、シリアル化ツールを使用して null を圧縮する必要があります)
• より適切なシリアル化ツールを使用します
•より小さいデータ型を使用します
• ZIP 圧縮の使用を検討してください
• ハッシュ構造の代わりにリストを使用します (多数のフィールドが空の場合は、テストと比較が必要です)
以上がRedis キャッシュスペースを最適化する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7569
7569
 15
1386
52
87
11
28
107
15
1386
52
87
11
28
107

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisを使用して操作をロックするには、setnxコマンドを介してロックを取得し、有効期限を設定するために有効期限コマンドを使用する必要があります。特定の手順は次のとおりです。(1)SETNXコマンドを使用して、キー価値ペアを設定しようとします。 (2)expireコマンドを使用して、ロックの有効期限を設定します。 (3)Delコマンドを使用して、ロックが不要になったときにロックを削除します。
 基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
Redisはハッシュテーブルを使用してデータを保存し、文字列、リスト、ハッシュテーブル、コレクション、注文コレクションなどのデータ構造をサポートします。 Redisは、スナップショット(RDB)を介してデータを維持し、書き込み専用(AOF)メカニズムを追加します。 Redisは、マスタースレーブレプリケーションを使用して、データの可用性を向上させます。 Redisは、シングルスレッドイベントループを使用して接続とコマンドを処理して、データの原子性と一貫性を確保します。 Redisは、キーの有効期限を設定し、怠zyな削除メカニズムを使用して有効期限キーを削除します。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 Redis用のメッセージミドルウェアの作成方法
Apr 10, 2025 pm 07:51 PM
Redis用のメッセージミドルウェアの作成方法
Apr 10, 2025 pm 07:51 PM
Redisは、メッセージミドルウェアとして、生産消費モデルをサポートし、メッセージを持続し、信頼できる配信を確保できます。メッセージミドルウェアとしてRedisを使用すると、低遅延、信頼性の高いスケーラブルなメッセージングが可能になります。
