

MySQL インデックスの役割とは何ですか

最初にデータベース テーブルを作成します:
create table single_table(
id int not auto_increment,
key1 varchar(100),
key2 int,
key3 varchar(100),
key_part1 varchar(100),
key_part2 varchar(100),
key_part3 varchar(100),
common_field varchar(100),
primary key(id), # 聚簇索引
key idx_key1(key1), # 二级索引
unique key uk_key2(key2), # 二级索引,而且该索引是唯一二级索引
key idx_key3(key3), # 二级索引
key idx_key_part(key_part1,key_part2,key_part3) # 二级索引,也是联合索引
)Engine=InnoDB CHARSET=utf8;1. インデックスは、スキャンする必要があるレコードの数を減らすために使用されます。
最も基本的なクエリ実行プランは、テーブル内のすべてのレコードをスキャンし、各検索レコードが検索条件を満たしているかどうかを確認することです。一致する場合はクライアントに送信し、一致しない場合はレコードをスキップします。この実行スキームはフルテーブルスキャンと呼ばれます。
InnoDB ストレージ エンジンの場合、テーブル全体のスキャンとは、クラスター化インデックスの最初のリーフ ノードの最初のレコードから開始し、レコードが存在する一方向リンク リストに沿って逆方向に移動することを意味します。最後のリーフ ノードの最後のレコードまでスキャンします。B ツリーを使用して、インデックス列の値が特定の値に等しいレコードを検索できれば、スキャンする必要があるレコードの数を減らすことができます。
B ツリー リーフ ノード内のレコードはインデックス列値の昇順に並べ替えられるため、特定の間隔でレコードをスキャンするだけで、スキャンする必要があるレコードの数を大幅に減らすことができます。 。
クエリ ステートメントの場合:
select * from single_table where id>=2 and id<=100;
このステートメントは、実際には [2,100] 内の id 値を検索する必要があります。すべてのクラスター化インデックス レコードについて、クラスター化インデックスに対応する B ツリーを通じて id=2 を持つクラスター化インデックス レコードをすばやく見つけ、レコードが見つかった一方向リンク リストに沿って逆方向にスキャンできます。特定のクラスター化インデックス レコードの id 値が [2,100] 間隔内になくなるまで、すべてのクラスター化インデックス レコードをスキャンする場合と比較して、この方法ではレコード数が大幅に削減されます。大量にスキャンする必要があるため、クエリの効率が向上します。
実際、B ツリーの場合、インデックス列と定数が =、<=>、in、not in、is null、is not null、>、< を使用している限り、 ;、> ;=、<=、between、!=、または like 演算子を接続してスキャン間隔を生成できるため、クエリの効率が向上します。
2. 並べ替えにはインデックスが使用されます
クエリ ステートメントを作成するとき、特定のルールに従ってクエリされたレコードを並べ替えるために、order by 句を使用する必要があることがよくあります。通常の状況では、レコードをメモリにロードし、いくつかの並べ替えアルゴリズムを使用してメモリ内でこれらのレコードを並べ替えることしかできません。クエリ結果セットが大きすぎてメモリ内で並べ替えられない場合があります。この場合、一時的にディスク領域を使用して中間結果を保存し、並べ替え操作の完了後に並べ替えられた結果をクライアントに返す必要があります。
MySQL では、メモリ内またはディスク上でソートするこの方法をファイル ソートと呼びますが、インデックス カラムが order by 句で使用されている場合は省略できます。メモリまたはディスク内にあります。
1. 次のクエリ ステートメントを分析します:
select * form single_table order by key_part1,key_part2,key_part3 limit 10;
このクエリ ステートメントの結果セットは、key_part1 値に従って並べ替える必要があります。 key_part1 値が同じ場合は、 key_part2 値で並べ替えます。 key_part1 値と key_part2 値が同じ場合、次に、key_part3 値で並べ替えます。私たちが確立した結合インデックス idx_key_part は、上記のルールに従って並べ替えられます。以下は、idx_key_part インデックスの簡略図です:
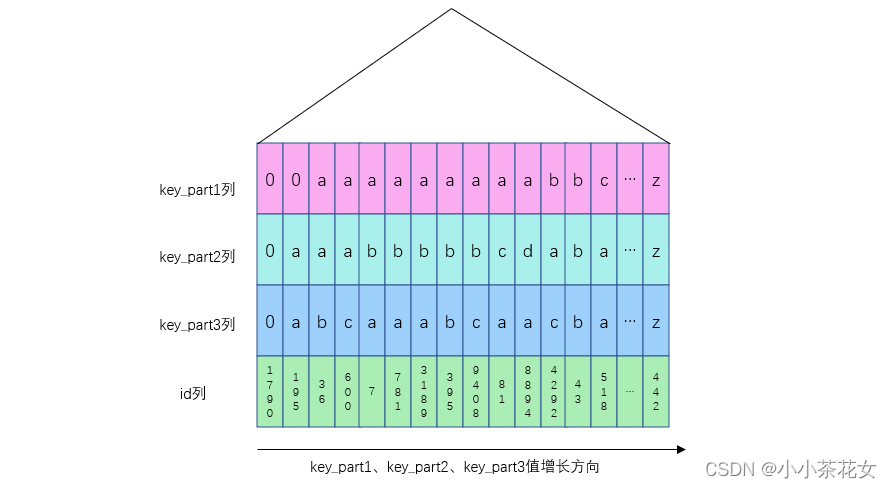
idx_key_part セカンダリ インデックス レコードから開始し、レコードが存在する一方向リンク リストに沿って逆方向にスキャンして、10 個のセカンダリ インデックス レコードを取得できます。クエリ リストは ## であるため、つまり完全なユーザー レコードを読み取る必要があるため、取得した各セカンダリ インデックス レコードに対してテーブルを返す操作を実行し、完全なユーザー レコードを顧客に送信します。これにより、10,000 件のレコードを並べ替える時間が節約されます。
order by後の列の順序この句は、インデックス列の順序も指定されている必要があります。order by key_part3、key_part2、key_part1 の順序が指定されている場合、B ツリー インデックスは使用できません。
key_part1## に従ってソートするためです。 # 値。レコードの key_part1 の値が同じ場合、key_part2 値に従って並べ替えます。記録された key_part1 値と key_part2# の場合## 値が同じ場合は、key_part3Value の並べ替えに従って並べ替えます。 order by 句の内容が order by key_part3, key_part2, key_part1 の場合、最初に key_part3 の値で並べ替える必要があります。 key_part3 値は同じであり、key_part2 値によって並べ替えられます。記録された key_part3 値と key_part2## の場合# 値が同じ場合、key_part1 値の順序で並べ替えます。これは明らかに競合です。 <h4 id="不可以使用索引进行排序的情况">3、不可以使用索引进行排序的情况:</h4><p><strong>(1)</strong><code> ASC、DESC混用;
对于使用联合索引进行排序的场景,我们要求各个排序列的排序规则是一致的,也就是要么各个列都是按照升序规则排序,要么都是按照降序规则排序。
(2) 排序列包含非一个索引的列;
有时用来排序的多个列不是同一个索引中的,这种情况也不能使用索引进行排序,比如下面的查询语句:
select * from single_table order by key1,,key2 limit 10;
对于idx_key1的二级索引记录来说,只按照key1列的值进行排序,而且在key1列相同的情况下是不按照
key2列的值进行排序的,所以不能使用idx_key1索引执行上述查询。
(3) 排序列是某个联合索引的索引列,但是这些排序列在联合索引中并不连续;
(4) 排序列不是以单独列名的形式出现在order by子句中;
3、索引用于分组
有时为了方便统计表中的一些信息,会把表中的记录按照某些列进行分组。比如下面的分组查询语句:
select key_part1,key_part2,key_part3,count(*) fron single_table group by key_part1,key_part2,key_part3;
这个查询语句相当于执行了3次分组操作:
先按照
key_part1值把记录进行分组,key_part1值相同的所有记录划分为一组;将
key_part1值相同的每个分组中的记录再按照key_part2的值进行分组,将key_part2值相同的记录放到一个小分组中,看起来像是在一个大分组中又细分了好多小分组。再将上一步中产生的小分组按照
key_part3的值分成更小的分组。所以整体上看起来就像是先把记录分成一个大分组,然后再把大分组分成若干个小分组,最后把若干个小分组再细分为更多的小分组。
上面这个查询语句就是统计每个小小分组包含的记录条数。
如果没有idx_key_part索引,就得建立一个用于统计的临时表,在扫描聚簇索引的记录时将统计的中间结果填入这个临时表。当扫描完记录后,再把临时表中的结果作为结果集发送给客户端。
如果有了idx_key_part索引,恰巧这个分组顺序又与idx_key_part的索引列的顺序一致,因此可以直接使用idx_key_part的二级索引进行分组,而不用建立临时表了。
与使用B+树索引进行排序差不多,分组列的顺序页需要与索引列的顺序一致,也可以值使用索引列中左边连续的列进行分组。
以上がMySQL インデックスの役割とは何ですかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7640
7640
 15
1391
52
90
11
32
150
15
1391
52
90
11
32
150

 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheはデータベースに接続するには、次の手順が必要です。データベースドライバーをインストールします。 web.xmlファイルを構成して、接続プールを作成します。 JDBCデータソースを作成し、接続設定を指定します。 JDBC APIを使用して、接続の取得、ステートメントの作成、バインディングパラメーター、クエリまたは更新の実行、結果の処理など、Javaコードのデータベースにアクセスします。
 Redis ExporterサービスでRedis Dropletを監視します
Apr 10, 2025 pm 01:36 PM
Redis ExporterサービスでRedis Dropletを監視します
Apr 10, 2025 pm 01:36 PM
Redisデータベースの効果的な監視は、最適なパフォーマンスを維持し、潜在的なボトルネックを特定し、システム全体の信頼性を確保するために重要です。 Redis Exporter Serviceは、Prometheusを使用してRedisデータベースを監視するために設計された強力なユーティリティです。 このチュートリアルでは、Redis Exporterサービスの完全なセットアップと構成をガイドし、監視ソリューションをシームレスに構築します。このチュートリアルを研究することにより、完全に動作する監視設定を実現します
 SQLデータベースエラーを表示する方法
Apr 10, 2025 pm 12:09 PM
SQLデータベースエラーを表示する方法
Apr 10, 2025 pm 12:09 PM
SQLデータベースエラーを表示する方法は次のとおりです。1。エラーメッセージを直接表示します。 2。エラーを表示し、警告コマンドを表示します。 3.エラーログにアクセスします。 4.エラーコードを使用して、エラーの原因を見つけます。 5.データベース接続とクエリ構文を確認します。 6.デバッグツールを使用します。
