

Python検索アルゴリズムの実装方法

検索アルゴリズムは、配列データ (母集団) の中に特定のデータ (キーワード) が存在するかどうかを取得するために使用されます。一般的に使用される検索アルゴリズムは次のとおりです。
線形検索: 線形検索これは順次検索とも呼ばれ、順序のない数値列を検索するために使用されます。
二分探索: 二分探索は半探索とも呼ばれ、そのアルゴリズムは順序付けされたシーケンスに使用されます。
内挿検索: 内挿検索は、二分探索アルゴリズムを改良したものです。
ブロック検索: インデックス順次検索とも呼ばれ、線形検索の改良版です。
ツリー テーブル検索: ツリー テーブル検索は、バイナリ サーチ ツリーとバランスド バイナリ ツリー検索に分類できます。
ハッシュ検索: ハッシュ検索では、キーワードから必要なデータを直接見つけることができます。
ツリーテーブル検索とハッシュ検索は多くのスペースを必要とするため、この記事では説明しません。この記事では、ツリーベースとハッシュベースのアプローチを超えた検索アルゴリズムの包括的な概要を提供し、各アルゴリズムの長所と短所を分析し、対応する最適化戦略を提案します。
1. 線形検索
線形検索とも呼ばれる逐次検索は、原始的、網羅的、総当たり検索に基づくアルゴリズムです。理解しやすく、コーディングの実装も簡単です。処理されるデータ量が多い場合、アルゴリズムの考え方が比較的単純であり、アルゴリズムの最適な設計がされていないため、パフォーマンスが低下する可能性があります。
線形検索のアイデア:
元のリストの各データを最初から最後まで 1 つずつスキャンし、指定されたキーワードと比較します。
比較が等しい場合、検索は成功します。
スキャンが完了しても、指定されたキーワードに等しいデータがまだ見つからない場合、検索失敗が宣言されます。
線形探索アルゴリズムの説明によると、コーディングと実装は簡単です。
'''
线性查找算法
参数:
nums: 序列
key:关键字
返回值:
关键字在序列中的位置
如果没有,则返回 -1
'''
def line_find(nums, key):
for i in range(len(nums)):
if nums[i] == key:
return i
return -1
'''
测试线性算法
'''
if __name__ == "__main__":
nums = [4, 1, 8, 10, 3, 5]
key = int(input("请输入要查找的关键字:"))
pos = line_find(nums, key)
print("关键字 {0} 在数列的第 {1} 位置".format(key, pos))
'''
输出结果:
请输入要查找的关键字:3
关键字 3 在数列的 4 位置
'''線形探索アルゴリズムの平均時間計算量分析。
1. 幸運な状況: 見つけたいキーワードがたまたまシーケンスの 1 番目の位置にあった場合、検索は 1 回だけで済みます。
たとえば、キーワード 4 を =[4,1,8,10,3,5] の順序で検索します。
検索は 1 回だけ必要です。
2. 最悪の状況: シーケンスの最後がスキャンされるまでキーワードが見つかりません。
キーワード 5 を =[4,1,8,10,3,5] の順序で検索するなど。
必要な検索回数はシーケンスの長さに等しく、ここでは 6 倍です。
3. 幸か不幸か: 見つかるキーワードがシーケンスの途中にある場合、それが見つかる確率は 1/n です。
n はシーケンスの長さです。
線形検索の平均検索数は = (1 n)/2 でなければなりません。この文は次のように書き直されます: その時間計算量は O(n) です。
ビッグ O 表記では定数は無視されます。
線形検索の最悪のシナリオは、配列全体をスキャンした後、キーワードが見つからないことです。
たとえば、キーワード 12 がシーケンス =[4,1,8,10,3,5] に存在するかどうかを調べます。
6 回スキャンしましたが、失敗しました。 !
改良された線形検索アルゴリズム
線形検索アルゴリズムは、それに応じて最適化できます。 「前哨基地」を設置するなど。いわゆる「前哨」とは、検索する キーワード をシーケンスの最後に挿入してから検索することです。
def line_find_(nums, key):
i = 0
while nums[i] != key:
i += 1
return -1 if i == len(nums)-1 else i
'''
测试线性算法
'''
if __name__ == "__main__":
nums = [4, 1, 8, 10, 3, 5]
key = int(input("请输入要查找的关键字:"))
# 查找之前,先把关键字存储到列到的尾部
nums.append(key)
pos = line_find_(nums, key)
print("关键字 {0} 在数列的第 {1} 位置".format(key, pos))「Outpost」で最適化された線形探索アルゴリズムの時間計算量は、O(n) のままです。つまり、2 コードから判断すると、大きな変更はありません。
しかし、コードを実際に実行する観点から見ると、2 オプションは if 命令の数を減らし、コンパイルされた命令の数も減らすため、 CPU命令の実行回数、この種の最適化は微細な最適化であり、アルゴリズムの本質の最適化ではありません。
コンピュータプログラミング言語を使用して記述されたコードは、疑似命令コードです。
コンパイルされた命令コードは、CPU 命令セットと呼ばれます。
最適化ソリューションの 1 つは、コンパイルされた命令セットを減らすことです。
2. 二分検索
順序付き検索とは、検索対象のデータが特定の順序で配置されている必要があることを意味し、二分検索は順序付き検索です。たとえば、シーケンス = [4,1,8,10,3,5,12] でキーワード 4 を検索する場合、因子シーケンスは順序付けされていないため、二分探索は使用できません。二分探索アルゴリズムを使用するには、まず一連の数値を並べ替える必要があります。
二分探索では、二分 (半分) アルゴリズムの考え方が使用されます。二分探索アルゴリズムには、常に取得する必要がある 2 つの重要な情報があります。 #One はシーケンス Mid_pos の中間位置です。
1 はシーケンスの中央の値 Mid_val です。
次に、nums=[1,3,4,5,8,10,12] のシーケンスでキーワード 8 を検索する、二分探索のアルゴリズム プロセスについて学習します。
バイナリ検索を実行する前に、まず 2 つの位置 (ポインター) 変数を定義します。
左ポインター l_idx は、最初はシーケンスの左端の番号を指します。
右ポインタ r_idx は、最初は配列の右端の番号を指します。
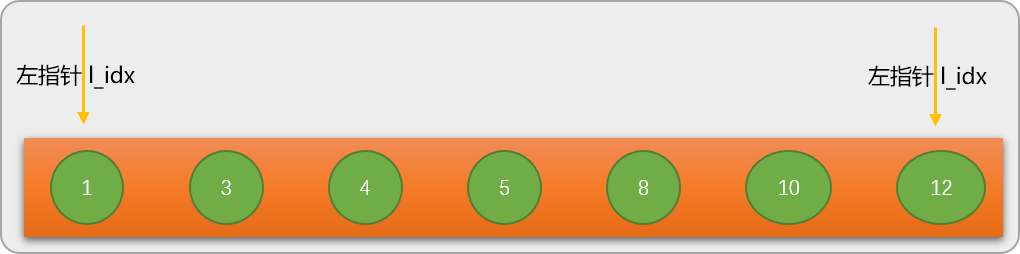
第 1 步:通过左、右指针的当前位置计算出数列的中间位置 mid_pos=3,并根据 mid_pos 的值找出数列中间位置所对应的值 mid_val=nums[mid_pos] 是 5。

二分查找算法的核心就是要找出数列中间位置的值。
第 2 步:把数列中间位置的值和给定的关键字相比较。这里关键字是 8,中间位置的值是 5,显然 8 是大于 5,因为数列是有序的,自然会想到没有必要再与数列中 5 之前的数字比较,而是专心和 5 之后的数字比较。
一次比较后再次查找的数列范围缩小了一半。这也是二分算法的由来。

第 3 步:根据比较结果,调整数列的大小,这里的大小调整不是物理结构上调整,而是逻辑上调整,调整后原数列没有变化。也就是通过修改左指针或右指针的位置,从逻辑上改变数列大小。调整后的数列如下图。
二分查找算法中数列的范围由左指针到右指针的长度决定。

第 4 步:重复上述步骤,至到找到或找不到为止。
编码实现二分查找算法
'''
二分查找算法
'''
def binary_find(nums, key):
# 初始左指针
l_idx = 0
# 初始在指针
r_ldx = len(nums) - 1
while l_idx <= r_ldx:
# 计算出中间位置
mid_pos = (r_ldx + l_idx) // 2
# 计算中间位置的值
mid_val = nums[mid_pos]
# 与关键字比较
if mid_val == key:
# 出口一:比较相等,有此关键字,返回关键字所在位置
return mid_pos
elif mid_val > key:
# 说明查找范围应该缩少在原数的左边
r_ldx = mid_pos - 1
else:
l_idx = mid_pos + 1
# 出口二:没有查找到给定关键字
return -1
'''
测试二分查找
'''
if __name__ == "__main__":
nums = [1, 3, 4, 5, 8, 10, 12]
key = 3
pos = binary_find(nums, key)
print(pos)通过前面对二分算法流程的分析,可知二分查找的子问题和原始问题是同一个逻辑,所以可以使用递归实现:
'''
递归实现二分查找
'''
def binary_find_dg(nums, key, l_idx, r_ldx):
if l_idx > r_ldx:
# 出口一:没有查找到给定关键字
return -1
# 计算出中间位置
mid_pos = (r_ldx + l_idx) // 2
# 计算中间位置的值
mid_val = nums[mid_pos]
# 与关键字比较
if mid_val == key:
# 出口二:比较相等,有此关键字,返回关键字所在位置
return mid_pos
elif mid_val > key:
# 说明查找范围应该缩少在原数的左边
r_ldx = mid_pos - 1
else:
l_idx = mid_pos + 1
return binary_find_dg(nums, key, l_idx, r_ldx)
'''
测试二分查找
'''
if __name__ == "__main__":
nums = [1, 3, 4, 5, 8, 10, 12]
key = 8
pos = binary_find_dg(nums, key,0,len(nums)-1)
print(pos)二分查找性能分析:
二分查找的过程用树形结构描述会更直观,当搜索完毕后,绘制出来树结构是一棵二叉树。
1.如上述代码执行过程中,先找到数列中的中间数字 5,然后以 5 为根节点构建唯一结点树。

2.5 和关键字 8 比较后,再在以数字 5 为分界线的右边数列中找到中间数字10,树形结构会变成下图所示。

3.10 和关键字 8比较后,再在10 的左边查找。

查找到8 后,意味着二分查找已经找到结果,只需要 3 次就能查找到最终结果。
从二叉树的结构上可以直观得到结论:二分查找关键字的次数由关键字在二叉树结构中的深度决定。
4.上述是查找给定的数字8,为了能查找到数列中的任意一个数字,最终完整的树结构应该如下图所示。

很明显,树结构是标准的二叉树。从树结构上可以看出,无论查找任何数字,最小是 1 次,如查找数字 5,最多也只需要 3 次,比线性查找要快很多。
根据二叉树的特性,结点个数为 n 的树的深度为 h=log2(n+1),所以二分查找算法的大 O 表示的时间复杂度为 O(logn),是对数级别的时间度。
当对长度为1000的数列进行二分查找时,所需次数最多只要 10 次,二分查找算法的效率显然是高效的。
然而,二分查找算法在实行之前需要对数列进行排序,因此前面所述的时间复杂度并未包含排序所需的时间。所以,二分查找一般适合数字变化稳定的有序数列。
3. 插值查找
插值查找本质是二分查找,插值查找对二分查找算法中查找中间位置的计算逻辑进行了改进。
原生二分查找算法中计算中间位置的逻辑:中间位置等于左指针位置加上右指针位置然后除以 2。
# 计算中间位置
mid_pos = (r_ldx + l_idx) // 2插值算法计算中间位置逻辑如下所示:
key 为要查找的关键字!!
# 插值算法中计算中间位置 mid_pos = l_idx + (key - nums[l_idx]) // (nums[r_idx] - nums[l_idx]) * (r_idx - l_idx)
编码实现插值查找:
# 插值查找基于二分法,只是mid计算方法不同
def binary_search(nums, key):
l_idx = 0
r_idx = len(nums) - 1
old_mid = -1
mid_pos = None
while l_idx < r_idx and nums[0] <= key and nums[r_idx] >= key and old_mid != mid_pos:
# 中间位置计算
mid_pos = l_idx + (key - nums[l_idx]) // (nums[r_idx] - nums[l_idx]) * (r_idx - l_idx)
old_mid = mid_pos
if nums[mid_pos] == key:
return "index is {}, target value is {}".format(mid_pos, nums[mid_pos])
# 此时目标值在中间值右边,更新左边界位置
elif nums[mid_pos] < key:
l_idx = mid_pos + 1
# 此时目标值在中间值左边,更新右边界位置
elif nums[mid_pos] > key:
r_idx = mid_pos - 1
return "Not find"
li =[1, 3, 4, 5, 8, 10, 12]
print(binary_search(li, 6))插值算法的中间位置计算时,对中间位置的计算有可能多次计算的结果是一样的,此时可以认为查找失败。
插值算法的性能介于线性查找和二分查找之间。
如果序列具有较大数量的均匀分布的数字,插值查找算法的平均执行效率要比二分查找好得多。如果数据在数列中分布不均匀,插值算法并不是最优选择。
4. 分块查找
分块查找类似于数据库中的索引查询,所以分块查找也称为索引查找。其算法的核心还是线性查找。
现有原始数列 nums=[5,1,9,11,23,16,12,18,24,32,29,25],需要查找关键字11 是否存在。
第 1 步:使用分块查找之前,先要对原始数列按区域分成多个块。至于分成多少块,可根据实际情况自行定义。分块时有一个要求,前一个块中的最大值必须小于后一个块的最小值。
块内部无序,但要保持整个数列按块有序。

分块查找要求原始数列从整体上具有升序或降序趋势,如果数列的分布不具有趋向性,如果仍然想使用分块查找,则需要进行分块有序调整。
第 2 步:根据分块信息,建立索引表。索引表至少应该有 2 个字段,每一块中的最大值数字以及每一块的起始地址。显然索引表中的数字是有序的。

第 3 步:查找给定关键字时,先查找索引表,查询关键字应该在那个块中。如查询关键字 29,可知应该在第三块中,然后根据索引表中所提供的第三块的地址信息,再进入第三块数列,按线性匹配算法查找29 具体位置。

编码实现分块查找:
先编码实现根据分块数量、创建索引表,这里使用二维列表保存储索引表中的信息。
'''
分块:建立索引表
参数:
nums 原始数列
blocks 块大小
'''
def create_index_table(nums, blocks):
# 索引表使用列表保存
index_table = []
# 每一块的数量
n = len(nums) // blocks
for i in range(0, len(nums), n):
# 索引表中的每一行记录
tmp_lst = []
# 最大值
tmp_lst.append(max(nums[i:i + n-1]))
# 起始地址
tmp_lst.append(i)
# 终止地址
tmp_lst.append(i + n - 1)
# 添加到索引表中
index_table.append(tmp_lst)
return index_table
'''
测试分块
'''
nums = [5, 1, 9, 11, 23, 16, 12, 18, 24, 32, 29, 25]
it = create_index_table(nums, 3)
print(it)
'''
输出结果:
[[11, 0, 3], [23, 4, 7], [32, 8, 11]]
'''代码执行后,输出结果和分析的结果一样。
以上代码仅对整体趋势有序的数列进行分块。如果整体没有向有序趋势发展,则需要提供适当的块排序计划,有兴趣的人可以自行完成。
如上代码仅为说明分块查找算法。
分块查找的完整代码:
'''
分块:建立索引表
参数:
nums 原始数列
blocks 块大小
'''
def create_index_table(nums, blocks):
# 索引表使用列表保存
index_table = []
# 每一块的数量
n = len(nums) // blocks
for i in range(0, len(nums), n):
tmp_lst = []
tmp_lst.append(max(nums[i:i + n - 1]))
tmp_lst.append(i)
tmp_lst.append(i + n - 1)
index_table.append(tmp_lst)
return index_table
'''
使用线性查找算法在对应的块中查找
'''
def lind_find(nums, start, end):
for i in range(start, end):
if key == nums[i]:
return i
break
return -1
'''
测试分块
'''
nums = [5, 1, 9, 11, 23, 16, 12, 18, 24, 32, 29, 25]
key = 16
# 索引表
it = create_index_table(nums, 3)
# 索引表的记录编号
pos = -1
# 在索引表中查询
for n in range(len(it) - 1):
# 是不是在第一块中
if key <= it[0][0]:
pos = 0
# 其它块中
if it[n][0] < key <= it[n + 1][0]:
pos = n + 1
break
if pos == -1:
print("{0} 在 {1} 数列中不存在".format(key, nums))
else:
idx = lind_find(nums, it[pos][1], it[pos][2] + 1)
if idx != -1:
print("{0} 在 {1} 数列的 {2} 位置".format(key, nums, idx))
else:
print("{0} 在 {1} 数列中不存在".format(key, nums))
'''
输出结果
16 在 [5, 1, 9, 11, 23, 16, 12, 18, 24, 32, 29, 25] 数列的第 5 位置
'''分块查找对于整体趋向有序的数列,其查找性能较好。如果原始数列没有整体有序性,就需要使用块排序算法,其时间复杂度没有二分查找算法好。
建立索引表是分块查找所必需的,但这会增加额外的存储空间,因此其空间复杂度较高。其优于二分的地方在于只需要对原始数列进行部分排序。本质还是以线性查找为主。
以上がPython検索アルゴリズムの実装方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1421
52
1315
25
1266
29
1239
24
14
1421
52
1315
25
1266
29
1239
24

 PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPは主に手順プログラミングですが、オブジェクト指向プログラミング(OOP)もサポートしています。 Pythonは、OOP、機能、手続き上のプログラミングなど、さまざまなパラダイムをサポートしています。 PHPはWeb開発に適しており、Pythonはデータ分析や機械学習などのさまざまなアプリケーションに適しています。
 PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPはWeb開発と迅速なプロトタイピングに適しており、Pythonはデータサイエンスと機械学習に適しています。 1.PHPは、単純な構文と迅速な開発に適した動的なWeb開発に使用されます。 2。Pythonには簡潔な構文があり、複数のフィールドに適しており、強力なライブラリエコシステムがあります。
 PHPとPython:彼らの歴史を深く掘り下げます
Apr 18, 2025 am 12:25 AM
PHPとPython:彼らの歴史を深く掘り下げます
Apr 18, 2025 am 12:25 AM
PHPは1994年に発信され、Rasmuslerdorfによって開発されました。もともとはウェブサイトの訪問者を追跡するために使用され、サーバー側のスクリプト言語に徐々に進化し、Web開発で広く使用されていました。 Pythonは、1980年代後半にGuidovan Rossumによって開発され、1991年に最初にリリースされました。コードの読みやすさとシンプルさを強調し、科学的コンピューティング、データ分析、その他の分野に適しています。
 Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Pythonは、スムーズな学習曲線と簡潔な構文を備えた初心者により適しています。 JavaScriptは、急な学習曲線と柔軟な構文を備えたフロントエンド開発に適しています。 1。Python構文は直感的で、データサイエンスやバックエンド開発に適しています。 2。JavaScriptは柔軟で、フロントエンドおよびサーバー側のプログラミングで広く使用されています。
 Sublime Code Pythonを実行する方法
Apr 16, 2025 am 08:48 AM
Sublime Code Pythonを実行する方法
Apr 16, 2025 am 08:48 AM
PythonコードをSublimeテキストで実行するには、最初にPythonプラグインをインストールし、次に.pyファイルを作成してコードを書き込み、Ctrl Bを押してコードを実行する必要があります。コードを実行すると、出力がコンソールに表示されます。
 vscodeでコードを書く場所
Apr 15, 2025 pm 09:54 PM
vscodeでコードを書く場所
Apr 15, 2025 pm 09:54 PM
Visual Studioコード(VSCODE)でコードを作成するのはシンプルで使いやすいです。 VSCODEをインストールし、プロジェクトの作成、言語の選択、ファイルの作成、コードの書き込み、保存して実行します。 VSCODEの利点には、クロスプラットフォーム、フリーおよびオープンソース、強力な機能、リッチエクステンション、軽量で高速が含まれます。
 Golang vs. Python:パフォーマンスとスケーラビリティ
Apr 19, 2025 am 12:18 AM
Golang vs. Python:パフォーマンスとスケーラビリティ
Apr 19, 2025 am 12:18 AM
Golangは、パフォーマンスとスケーラビリティの点でPythonよりも優れています。 1)Golangのコンピレーションタイプの特性と効率的な並行性モデルにより、高い並行性シナリオでうまく機能します。 2)Pythonは解釈された言語として、ゆっくりと実行されますが、Cythonなどのツールを介してパフォーマンスを最適化できます。
 メモ帳でPythonを実行する方法
Apr 16, 2025 pm 07:33 PM
メモ帳でPythonを実行する方法
Apr 16, 2025 pm 07:33 PM
メモ帳でPythonコードを実行するには、Python実行可能ファイルとNPPEXECプラグインをインストールする必要があります。 Pythonをインストールしてパスを追加した後、nppexecプラグインでコマンド「python」とパラメーター "{current_directory} {file_name}"を構成して、メモ帳のショートカットキー「F6」を介してPythonコードを実行します。
