

マルチパス、マルチドメイン、すべてを網羅! Google AI がマルチドメイン学習一般モデル MDL をリリース

視覚タスク (画像分類など) の深層学習モデルは、通常、単一の視覚領域 (自然画像やコンピューター生成画像など) のデータを使用してエンドツーエンドでトレーニングされます。
一般に、複数のフィールドのビジュアル タスクを完了するアプリケーションは、異なるフィールド間でデータを共有せずに、個別のフィールドごとに複数のモデルを構築し、それらを独立してトレーニングする必要があります。推論時に、それぞれモデルはドメイン固有の入力データを処理します。
たとえ異なる分野を指向していても、これらのモデル間の初期層のいくつかの機能は類似しているため、これらのモデルの共同トレーニングはより効率的です。これにより、遅延と消費電力が削減され、各モデル パラメーターを保存するためのメモリ コストが削減されます。このアプローチはマルチドメイン学習 (MDL) と呼ばれます。
さらに、MDL モデルは単一ドメイン モデルより優れている場合もあります。1 つのドメインで追加のトレーニングを行うと、別のドメインのモデルのパフォーマンスが向上します。これは「前方知識」と呼ばれます。 「伝達」ですが、トレーニング方法と特定のドメインの組み合わせによっては、マイナスの知識伝達が生じる可能性もあります。 MDL に関するこれまでの研究では、クロスドメイン共同学習タスクの有効性が実証されていますが、手作業で作成されたモデル アーキテクチャが含まれているため、他のタスクに適用すると非効率的になります。

紙のリンク: https://arxiv.org/pdf/2010.04904.pdf
#この問題を解決するために、Google の研究者は、「オンデバイス マルチドメイン視覚分類のためのマルチパス ニューラル ネットワーク」という記事で、一般的な MDL モデルを提案しました。
この記事では、このモデルが効果的に高精度を達成し、否定的な知識伝達を削減し、肯定的な知識伝達を強化する方法を学習し、さまざまな特定分野の困難に対処できると述べています。モデルを効果的に最適化できます。
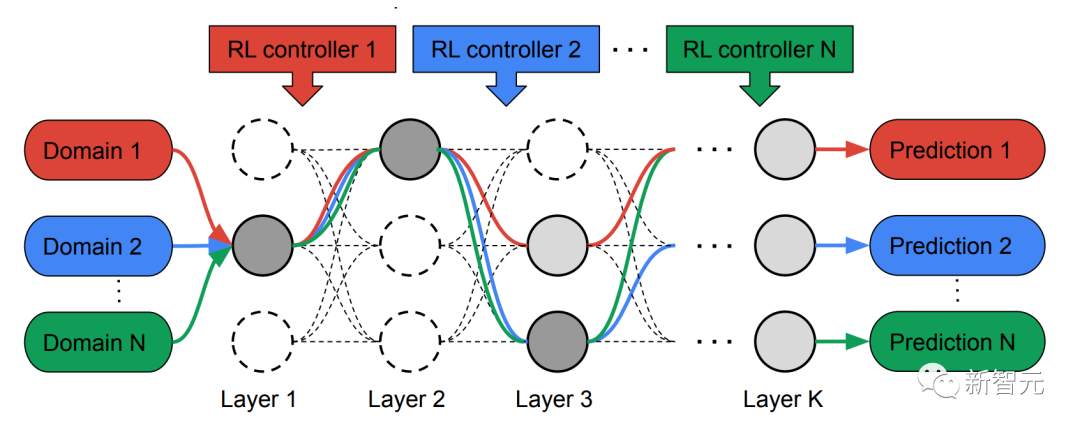
この目的を達成するために、研究者らは、統合モデルを確立するためのマルチパス ニューラル アーキテクチャ検索 (MPNAS) 手法を提案しました。異種ネットワーク アーキテクチャを使用します。
この方法は、効率的な神経構造検索 (NAS) 方法を単一パス検索からマルチパス検索に拡張して、各フィールドの最適なパスを共同で見つけます。また、Adaptive Balanced Domain Prioritization (ABDP) と呼ばれる新しい損失関数も導入されており、ドメイン固有の問題に適応してモデルを効率的にトレーニングできるようになります。結果として得られる MPNAS 方式は、効率的でスケーラブルです。
新しいモデルは、パフォーマンスを低下させることなく維持しながら、単一ドメイン手法と比較して、モデル サイズと FLOPS をそれぞれ 78% と 32% 削減します。
マルチパス神経構造検索肯定的な知識の伝達を促進し、否定的な知識の伝達を回避するために、従来の解決策は、すべてのドメインが共有する ほとんどのレイヤーは、各ドメインの共有特徴を学習し (特徴抽出と呼ばれます)、その上にドメイン固有のレイヤーをいくつか構築します。ただし、この特徴抽出方法では、特性が大きく異なる領域(自然画像と芸術的な絵画のオブジェクトなど)を扱うことができません。一方、各 MDL モデルに対して統一された異種構造を構築するには時間がかかり、ドメイン固有の知識が必要です。
マルチパス ニューラル検索アーキテクチャ フレームワーク NAS はディープ ラーニングを自動的に設計するための強力なパラダイムですアーキテクチャ 。これは、最終モデルの一部となる可能性のあるさまざまな潜在的な構成要素で構成される検索空間を定義します。
検索アルゴリズムは、分類精度などのモデル目標を最適化するために、検索空間から最適な候補アーキテクチャを見つけます。 TuNAS などの最近の NAS 方式は、エンドツーエンドのパス サンプリングを使用することで検索効率を向上させます。
TuNAS からインスピレーションを受け、MPNAS は、検索とトレーニングの 2 つの段階で MDL モデル アーキテクチャを確立しました。
検索フェーズでは、各ドメインの最適なパスを共同で見つけるために、MPNAS は各ドメインに個別の強化学習 (RL) コントローラーを作成します。これは、スーパー ネットワーク (つまり、検索によって定義されたもの) から始まります。 space 候補ノード間のすべての可能なサブネットワークのスーパーセットからのエンドツーエンド パス (入力層から出力層まで) をサンプルします。
複数の反復にわたって、すべての RL コントローラーはパスを更新して、すべての領域で RL 報酬を最適化します。検索フェーズの最後に、各ドメインのサブネットワークを取得します。最後に、次の図に示すように、すべてのサブネットワークが結合されて、MDL モデルの異種構造が作成されます。
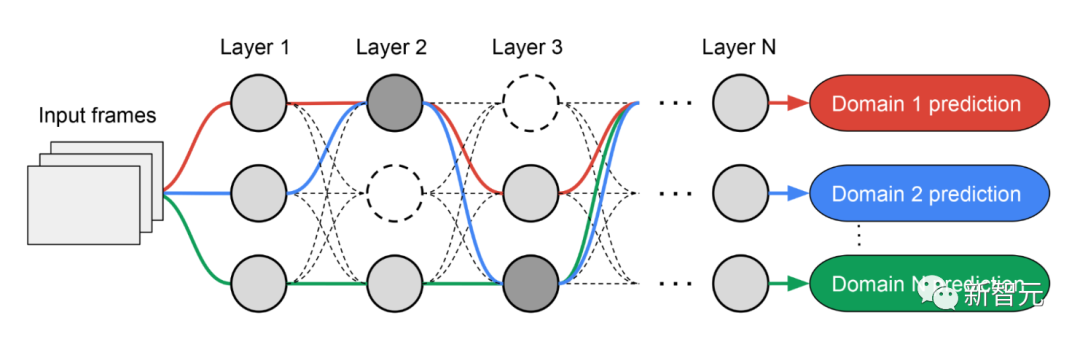
各ドメインのサブネットワークは独立して検索されるため、コンポーネントは複数で共有できます。ドメイン (つまり、濃い灰色のノード)、単一のドメインで使用されている (つまり、明るい灰色のノード)、またはどのサブネットワークでも使用されていない (つまり、ポイント ノード)。
各ドメインのパスは、検索プロセス中に任意のレイヤーをスキップすることもできます。サブネットワークはパフォーマンスを最適化する方法で途中でどのブロックを使用するかを自由に選択できるため、出力ネットワークは異種混合で効率的です。
次の図は、Visual Domain Decathlon の 2 つの領域の検索アーキテクチャを示しています。
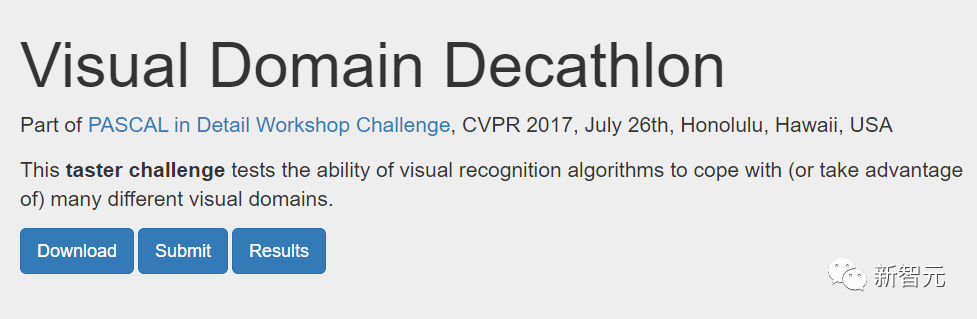
Visual Domain Decathlon は、CVPR 2017 の PASCAL in Detail Workshop Challenge の一部としてテストされました。多くの異なる視覚領域を処理 (または活用) する視覚認識アルゴリズムの能力を向上させます。見てわかるように、これら 2 つの関連性の高いドメイン (1 つは赤、もう 1 つは緑) のサブネットワークは、重複するパスから構成要素の大部分を共有していますが、それらの間にはまだ違いがあります。
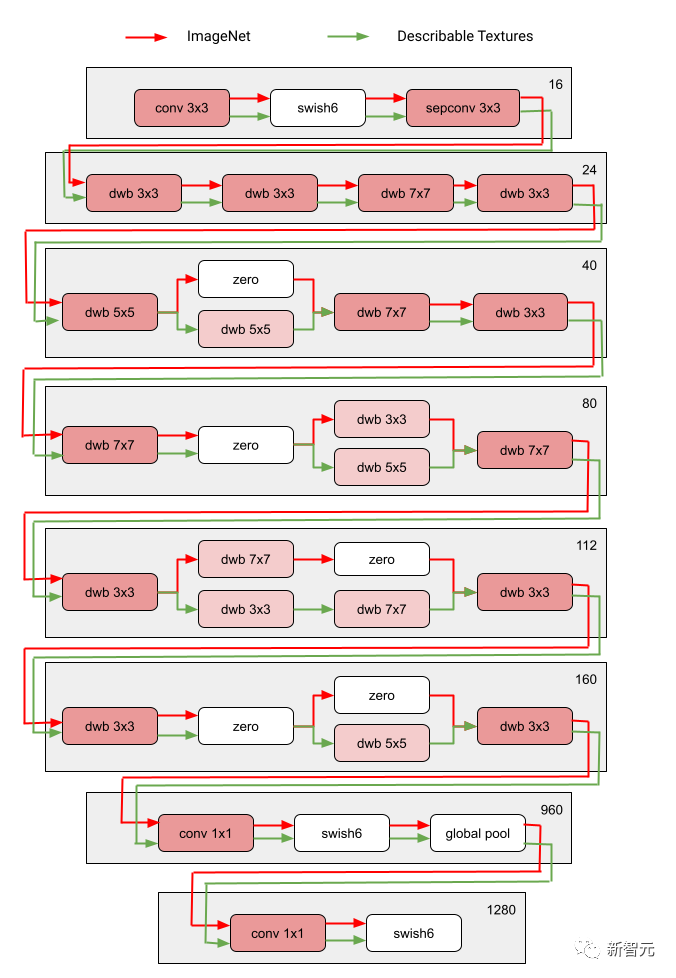
#図の赤と緑のパスは、それぞれ ImageNet と記述可能なテクスチャのサブネットワークを表し、濃いピンクのノードは共有ブロックを表します複数のドメインによる。薄ピンクのノードは、各パスで使用されるブロックを表します。図中の「dwb」ブロックは、dwbottleneck ブロックを表します。図のゼロ ブロックは、サブネットがブロックをスキップすることを示します。 次の図は、上記の 2 つの領域におけるパスの類似性を示しています。類似性は、各ドメインのサブネット間の Jaccard 類似性スコアによって測定されます。値が高いほど、パスがより類似していることを意味します。

図は、10 個のドメインのパス間の Jaccard 類似性スコアの混同行列を示しています。スコアの範囲は 0 ~ 1 です。スコアが大きいほど、2 つのパスが共有するノードの数が多くなります。
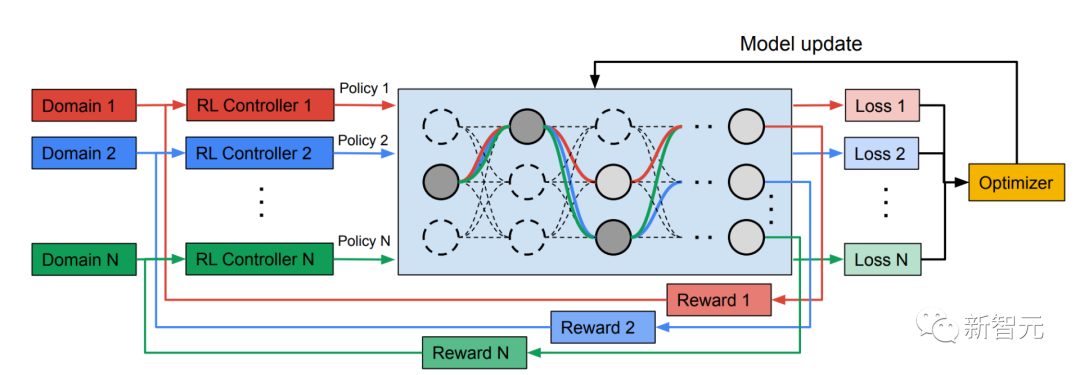
異種マルチドメイン モデルのトレーニング第 2 フェーズでは、MPNAS によって生成されたモデルがすべてのドメインに対して最初からトレーニングされます。これを行うには、すべてのドメインに対して統一された目的関数を定義する必要があります。さまざまなドメインを適切に処理するために、研究者らは、学習プロセス全体を調整してドメイン間の損失のバランスをとる、適応型バランスドメイン優先順位付け (ABDP) と呼ばれるアルゴリズムを設計しました。以下に、さまざまな設定でトレーニングされたモデルの精度、モデル サイズ、FLOPS を示します。 MPNAS を他の 3 つの方法と比較します。
ドメイン非依存の NAS: モデルはドメインごとに個別に検索され、トレーニングされます。
単一パス マルチヘッド: 事前トレーニングされたモデルをすべてのドメインの共有バックボーンとして使用し、ドメインごとに個別の分類ヘッドを使用します。
マルチヘッド NAS: ドメインごとに個別の分類ヘッドを使用して、すべてのドメインの統合バックボーン アーキテクチャを検索します。
この結果から、NAS ではドメインごとに一連のモデルを構築する必要があり、その結果、大規模なモデルが必要になることがわかります。シングルパス マルチヘッドおよびマルチヘッド NAS はモデルのサイズと FLOPS を大幅に削減できますが、ドメインに同じバックボーンの共有を強制すると、負の知識伝達が発生し、全体的な精度が低下します。

対照的に、MPNAS は、高い全体精度を維持しながら、小規模で効率的なモデルを構築できます。 MPNAS の平均精度は、このモデルがアクティブな知識の伝達を実現できるため、ドメインに依存しない NAS 手法よりも 1.9% も高くなっています。以下の図は、これらの手法のドメインごとのトップ 1 の精度を比較しています。
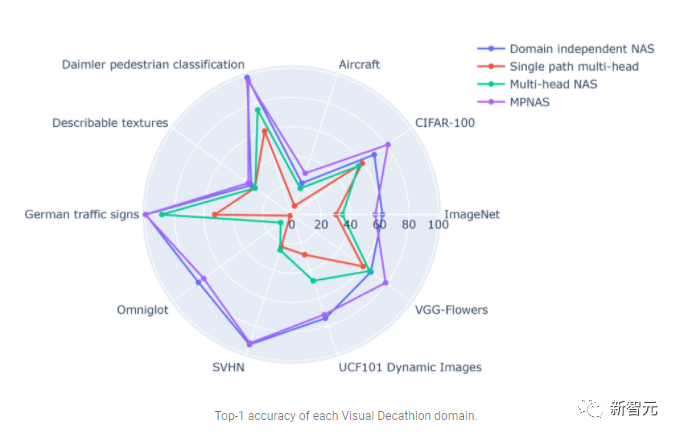
評価では、検索およびトレーニング段階の一部として ABDP を使用することで、トップ- 1 精度は 69.96% から 71.78% に増加しました (増分: 1.81%)。
将来の方向
MPNAS は、データの不均衡、ドメインの多様性、ネガティブな移行、MDL で可能なパラメータ共有戦略のドメインの可用性を解決するための異種ネットワークを構築することです。効率的なソリューションです。スケーラビリティと広い検索スペースを実現します。 MobileNet のような検索スペースを使用することにより、生成されたモデルもモバイル対応になります。既存の検索アルゴリズムと互換性のないタスクについては、研究者らはマルチタスク学習用に MPNAS の拡張を続けており、MPNAS を使用して統合マルチドメイン モデルを構築したいと考えています。
以上がマルチパス、マルチドメイン、すべてを網羅! Google AI がマルチドメイン学習一般モデル MDL をリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7489
7489
 15
1377
52
77
11
19
41
15
1377
52
77
11
19
41

 YOLOは不滅です! YOLOv9 がリリースされました: パフォーマンスとスピード SOTA~
Feb 26, 2024 am 11:31 AM
YOLOは不滅です! YOLOv9 がリリースされました: パフォーマンスとスピード SOTA~
Feb 26, 2024 am 11:31 AM
現在の深層学習手法は、モデルの予測結果が実際の状況に最も近くなるように、最適な目的関数を設計することに重点を置いています。同時に、予測に十分な情報を取得するには、適切なアーキテクチャを設計する必要があります。既存の方法は、入力データがレイヤーごとの特徴抽出と空間変換を受けると、大量の情報が失われるという事実を無視しています。この記事では、ディープネットワークを介してデータを送信する際の重要な問題、つまり情報のボトルネックと可逆機能について詳しく説明します。これに基づいて、深層ネットワークが複数の目的を達成するために必要なさまざまな変化に対処するために、プログラマブル勾配情報 (PGI) の概念が提案されています。 PGI は、目的関数を計算するためのターゲット タスクに完全な入力情報を提供することで、ネットワークの重みを更新するための信頼できる勾配情報を取得できます。さらに、新しい軽量ネットワーク フレームワークが設計されています。
 この「間違い」は実際には間違いではありません。Transformer アーキテクチャ図の何が「間違っている」のかを理解するには、4 つの古典的な論文から始めてください。
Jun 14, 2023 pm 01:43 PM
この「間違い」は実際には間違いではありません。Transformer アーキテクチャ図の何が「間違っている」のかを理解するには、4 つの古典的な論文から始めてください。
Jun 14, 2023 pm 01:43 PM
少し前に、Transformer のアーキテクチャ図と Google Brain チームの論文「Attending IsAllYouNeed」のコードとの間の矛盾を指摘したツイートが多くの議論を引き起こしました。セバスチャンの発見は意図せぬ間違いだったのではないかと考える人もいるが、これもまた驚くべきことである。結局のところ、Transformer 論文の人気を考慮すると、この矛盾については何千回も言及されるべきでした。 Sebastian Raschka氏はネチズンのコメントに答えて、「最もオリジナルな」コードは確かにアーキテクチャ図と一致していたが、2017年に提出されたコードバージョンは修正されたものの、アーキテクチャ図は同時に更新されていなかったと述べた。これが議論の「齟齬」の根本原因でもある。
 マルチパス、マルチドメイン、すべてを網羅! Google AI がマルチドメイン学習一般モデル MDL をリリース
May 28, 2023 pm 02:12 PM
マルチパス、マルチドメイン、すべてを網羅! Google AI がマルチドメイン学習一般モデル MDL をリリース
May 28, 2023 pm 02:12 PM
視覚タスク (画像分類など) の深層学習モデルは、通常、単一の視覚領域 (自然画像やコンピューター生成画像など) からのデータを使用してエンドツーエンドでトレーニングされます。一般に、複数のドメインのビジョン タスクを完了するアプリケーションは、個別のドメインごとに複数のモデルを構築し、それらを個別にトレーニングする必要があります。データは異なるドメイン間で共有されません。推論中、各モデルは特定のドメインの入力データを処理します。たとえそれらが異なる分野を指向しているとしても、これらのモデル間の初期層のいくつかの機能は類似しているため、これらのモデルの共同トレーニングはより効率的です。これにより、遅延と消費電力が削減され、各モデル パラメーターを保存するためのメモリ コストが削減されます。このアプローチはマルチドメイン学習 (MDL) と呼ばれます。さらに、MDL モデルは単一モデルよりも優れたパフォーマンスを発揮します。
 Spring Data JPA のアーキテクチャと動作原理は何ですか?
Apr 17, 2024 pm 02:48 PM
Spring Data JPA のアーキテクチャと動作原理は何ですか?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA は JPA アーキテクチャに基づいており、マッピング、ORM、トランザクション管理を通じてデータベースと対話します。そのリポジトリは CRUD 操作を提供し、派生クエリによりデータベース アクセスが簡素化されます。さらに、遅延読み込みを使用して必要な場合にのみデータを取得するため、パフォーマンスが向上します。
 1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
論文のアドレス: https://arxiv.org/abs/2307.09283 コードのアドレス: https://github.com/THU-MIG/RepViTRepViT は、モバイル ViT アーキテクチャで優れたパフォーマンスを発揮し、大きな利点を示します。次に、この研究の貢献を検討します。記事では、主にモデルがグローバル表現を学習できるようにするマルチヘッド セルフ アテンション モジュール (MSHA) のおかげで、軽量 ViT は一般的に視覚タスクにおいて軽量 CNN よりも優れたパフォーマンスを発揮すると述べられています。ただし、軽量 ViT と軽量 CNN のアーキテクチャの違いは十分に研究されていません。この研究では、著者らは軽量の ViT を効果的なシステムに統合しました。
 Golang フレームワーク アーキテクチャの学習曲線はどれくらい急ですか?
Jun 05, 2024 pm 06:59 PM
Golang フレームワーク アーキテクチャの学習曲線はどれくらい急ですか?
Jun 05, 2024 pm 06:59 PM
Go フレームワーク アーキテクチャの学習曲線は、Go 言語とバックエンド開発への慣れ、選択したフレームワークの複雑さ、つまり Go 言語の基本の十分な理解によって決まります。バックエンドの開発経験があると役立ちます。フレームワークの複雑さが異なると、学習曲線も異なります。
 数年後にはプログラマーが減少するということをご存知ですか?
Nov 08, 2023 am 11:17 AM
数年後にはプログラマーが減少するということをご存知ですか?
Nov 08, 2023 am 11:17 AM
「ComputerWorld」誌はかつて、IBM がエンジニアが必要な数式を書いて提出できる新しい言語 FORTRAN を開発したため、「プログラミングは 1960 年までに消滅するだろう」という記事を書きました。コンピューターを実行すればプログラミングは終了します。画像 数年後、私たちは新しいことわざを聞きました: ビジネスマンは誰でもビジネス用語を使って問題を説明し、コンピュータに何をすべきかを伝えることができます。COBOL と呼ばれるこのプログラミング言語を使用することで、企業はもはやプログラマーを必要としません。その後、IBM は従業員がフォームに記入してレポートを作成できるようにする RPG と呼ばれる新しいプログラミング言語を開発したと言われており、会社のプログラミング ニーズのほとんどはこれで完了できます。
 画像の類似性比較にコントラスト損失を使用してシャム ネットワークを探索する
Apr 02, 2024 am 11:37 AM
画像の類似性比較にコントラスト損失を使用してシャム ネットワークを探索する
Apr 02, 2024 am 11:37 AM
はじめに コンピュータ ビジョンの分野では、画像の類似性を正確に測定することは、幅広い実用化を伴う重要なタスクです。画像検索エンジンから顔認識システム、コンテンツベースの推奨システムに至るまで、類似した画像を効果的に比較して見つける機能が重要です。シャム ネットワークとコントラスト損失を組み合わせることで、データ駆動型の方法で画像の類似性を学習するための強力なフレームワークが提供されます。このブログ投稿では、シャム ネットワークの詳細を掘り下げ、コントラスト損失の概念を探り、これら 2 つのコンポーネントがどのように連携して効果的な画像類似性モデルを作成するかを探っていきます。まず、Siamese ネットワークは、同じ重みとパラメータを共有する 2 つの同一のサブネットワークで構成されています。各サブネットワークは入力画像を特徴ベクトルにエンコードします。
