初期値設定可能 |
| #import time
from itertools import accumulate
from functools import reduce
l_data = [1, 2, 3, 4]
data = accumulate(l_data, lambda x, y: x + y, initial=2)
print(list(data))
start = time.time()
for i in range(100000):
data = accumulate(l_data, lambda x, y: x + y, initial=2)
print(time.time() - start)
start = time.time()
for i in range(100000):
data = reduce(lambda x, y: x + y, l_data)
print(time.time() - start)
#输出
[2, 3, 5, 8, 12]
0.027924537658691406
0.03989362716674805ログイン後にコピー
上記の結果から、accumulate のほうが、reduce よりも若干パフォーマンスが良く、途中の処理過程も出力できることがわかります。
chain(*iterables)
iterables: 複数の反復可能オブジェクトを受け取る
複数の反復可能オブジェクトの要素を順番に返し、ディクショナリ出力要素の反復子を返します。デフォルトでは辞書のキーが出力されます
from itertools import chain
import time
list_data = [1, 2, 3]
dict_data = {"a": 1, "b": 2}
set_data = {4, 5, 6}
print(list(chain(list_data, dict_data, set_data)))
list_data = [1, 2, 3]
list_data2 = [4, 5, 6]
start = time.time()
for i in range(100000):
chain(list_data, list_data2)
print(time.time() - start)
start = time.time()
for i in range(100000):
list_data.extend(list_data2)
print(time.time() - start)
#输出
[1, 2, 3, 'a', 'b', 4, 5, 6]
0.012955427169799805
0.013965129852294922ログイン後にコピー
combinations(iterable: Iterable, r)
iterable: 操作する必要がある反復可能なオブジェクト
r: 抽出されたオブジェクトsubsequence 要素の数
は反復可能なオブジェクトを操作し、抽出されるサブシーケンスの数に従ってサブシーケンスを返します。サブシーケンス内の要素も順序付けされており、反復不可能であり、タプルの形式で表示されます。
from itertools import combinations
data = range(5)
print(tuple(combinations(data, 2)))
str_data = "asdfgh"
print(tuple(combinations(str_data, 2)))
#输出
((0, 1), (0, 2), (0, 3), (0, 4), (1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4))
(('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'g'), ('f', 'h'), ('g', 'h'))
ログイン後にコピー
combinations_with_replacement(iterable: Iterable, r)
は上記の組み合わせ(iterable: Iterable, r) に似ていますが、異なる点は、combinations_with_replacement のサブシーケンスの要素を繰り返すことができることです。詳細は次のとおりです。
from itertools import combinations_with_replacement
data = range(5)
print(tuple(combinations_with_replacement(data, 2)))
str_data = "asdfgh"
print(tuple(combinations_with_replacement(str_data, 2)))
#输出
((0, 0), (0, 1), (0, 2), (0, 3), (0, 4), (1, 1), (1, 2), (1, 3), (1, 4), (2, 2), (2, 3), (2, 4), (3, 3), (3, 4), (4, 4))
(('a', 'a'), ('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 's'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'd'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'f'), ('f', 'g'), ('f', 'h'), ('g', 'g'), ('g', 'h'), ('h', 'h'))
ログイン後にコピー
compress(data: Iterable, selectors: Iterable)
data: 操作する必要がある反復可能なオブジェクト
selector:真の値を決定するために反復可能 オブジェクト。str にできない場合は、リスト、タプルなどにするのが最適です。
セレクター内の要素かどうかに応じて、データ内の対応するインデックスの要素を出力します。いずれか短い方が true である場合は、 iterator を返します。
from itertools import compress
data = "asdfg"
list_data = [1, 0, 0, 0, 1, 4]
print(list(compress(data, list_data)))
#输出
['a', 'g']
ログイン後にコピー
count(start, step)
start: 開始要素
step: 開始以降の成長要素のステップ サイズ
反復の増加 開始点は start で、増分ステップは指定された値です。すべての要素がすぐに生成されるわけではありません。要素を再帰的に取得するには、next() メソッドを使用することをお勧めします。
from itertools import count
c = count(start=10, step=20)
print(next(c))
print(next(c))
print(next(c))
print(next(c))
print(c)
#输出
10
30
50
70
count(90, 20)
ログイン後にコピー
cycle(iterable)
iterable: ループによって出力する必要がある反復可能オブジェクト
反復子を返し、反復可能オブジェクトの要素をループアウトします。 count と同様に、結果を反復可能なオブジェクトに変換しないことが最善ですが、ループであるため、要素を取得するには next() または for ループを使用することをお勧めします。
from itertools import cycle
a = "asdfg"
data = cycle(a)
print(next(data))
print(next(data))
print(next(data))
print(next(data))
#输出
a
s
d
f
ログイン後にコピー
dropwhile(predicate, iterable)
predicate: 要素を削除するかどうかの基準
iterable: iterable object
述語フィルターの結果を計算することによりTrue と評価される要素が破棄される反復子を返します。後続の要素がTrueかFalseかに関わらず、述語がFalseの場合に出力されます。
from itertools import dropwhile
list_data = [1, 2, 3, 4, 5]
print(list(dropwhile(lambda i: i < 3, list_data)))
print(list(dropwhile(lambda x: x < 5, [1, 4, 6, 4, 1])))
#输出
[3, 4, 5]
[6, 4, 1]
ログイン後にコピー
filterfalse(predicate, iterable)
predicate: 要素を破棄するかどうかの基準
iterable: iterable object
反復子を生成します。要素が演算を実行し、それが述語条件を満たすかどうかを判定します。 filter メソッドに似ていますが、filter の逆です。
import time
from itertools import filterfalse
print(list(filterfalse(lambda i: i % 2 == 0, range(10))))
start = time.time()
for i in range(100000):
filterfalse(lambda i: i % 2 == 0, range(10))
print(time.time() - start)
start = time.time()
for i in range(100000):
filter(lambda i: i % 2 == 0, range(10))
print(time.time() - start)
#输出
[1, 3, 5, 7, 9]
0.276653528213501
0.2768676280975342ログイン後にコピー
上記の結果から、filterfalse と filter のパフォーマンスに大きな違いがないことがわかります。
groupby(iterable, key=なし)
iterable: 反復可能なオブジェクト
key: オプション。要素に関して判断する必要がある条件。デフォルトは x == x です。
反復子を返し、連続するキーとキーに応じたグループ (キーの条件を満たす連続した要素) を返します。
groupby を使用してグループ化する前に並べ替える必要があることに注意してください。
from itertools import groupby
str_data = "babada"
for k, v in groupby(str_data):
print(k, list(v))
str_data = "aaabbbcd"
for k, v in groupby(str_data):
print(k, list(v))
def func(x: str):
print(x)
return x.isdigit()
str_data = "12a34d5"
for k, v in groupby(str_data, key=func):
print(k, list(v))
#输出
b ['b']
a ['a']
b ['b']
a ['a']
d ['d']
a ['a']
a ['a', 'a', 'a']
b ['b', 'b', 'b']
c ['c']
d ['d']
1
2
a
True ['1', '2']
3
False ['a']
4
d
True ['3', '4']
5
False ['d']
True ['5']ログイン後にコピー
islice(iterable, stop)\islice(iterable, start, stop[, step])
iterable: 操作する必要がある反復可能オブジェクト
start:操作の開始
stop: 終了操作のインデックス位置
step: ステップ サイズ
反復子を返します。スライスと似ていますが、そのインデックスは負の数をサポートしません。
from itertools import islice
import time
list_data = [1, 5, 4, 2, 7]
#学习中遇到问题没人解答?小编创建了一个Python学习交流群:725638078
start = time.time()
for i in range(100000):
data = list_data[:2:]
print(time.time() - start)
start = time.time()
for i in range(100000):
data = islice(list_data, 2)
print(time.time() - start)
print(list(islice(list_data, 1, 3)))
print(list(islice(list_data, 1, 4, 2)))
#输出
0.010963201522827148
0.01595783233642578
[5, 4]
[5, 2]
0.010963201522827148
0.01595783233642578
[5, 4]
[5, 2]ログイン後にコピー
上記の結果から、スライスのパフォーマンスが islice のパフォーマンスよりわずかに優れていることがわかります。
pairwise(iterable)
操作する必要がある反復可能オブジェクト
反復可能オブジェクト内の連続する重複するペアを返す反復子を返します。 、空を返します。
from itertools import pairwise
str_data = "asdfweffva"
list_data = [1, 2, 5, 76, 8]
print(list(pairwise(str_data)))
print(list(pairwise(list_data)))
#输出
[('a', 's'), ('s', 'd'), ('d', 'f'), ('f', 'w'), ('w', 'e'), ('e', 'f'), ('f', 'f'), ('f', 'v'), ('v', 'a')]
[(1, 2), (2, 5), (5, 76), (76, 8)]
ログイン後にコピー
permutations(iterable, r=None)
iterable: 操作する必要がある反復可能なオブジェクト
r: 抽出されたサブシーケンス
は類似していますと組み合わせた場合、どちらも反復可能なオブジェクトのサブシーケンスを抽出しますが、順列は繰り返し不可能で順序付けされておらず、まさに combions_with_replacement の逆です。
from itertools import permutations
data = range(5)
print(tuple(permutations(data, 2)))
str_data = "asdfgh"
print(tuple(permutations(str_data, 2)))
#输出
((0, 1), (0, 2), (0, 3), (0, 4), (1, 0), (1, 2), (1, 3), (1, 4), (2, 0), (2, 1), (2, 3), (2, 4), (3, 0), (3, 1), (3, 2), (3, 4), (4, 0), (4, 1), (4, 2), (4, 3))
(('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 'a'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'a'), ('d', 's'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'a'), ('f', 's'), ('f', 'd'), ('f', 'g'), ('f', 'h'), ('g', 'a'), ('g', 's'), ('g', 'd'), ('g', 'f'), ('g', 'h'), ('h', 'a'), ('h', 's'), ('h', 'd'), ('h', 'f'), ('h', 'g'))
ログイン後にコピー
product(*iterables,repeat=1)
iterables: 複数の反復可能なオブジェクト
repeat: 反復可能なオブジェクトの繰り返しの数、つまり、コピー回数
イテレータを返します。類似の順列と組み合わせにより、デカルト積の反復可能なオブジェクトが生成されます。 product 関数は zip 関数に似ていますが、zip は要素と 1 対 1 で一致するのに対し、product は 1 対多の関係を作成します。
from itertools import product
list_data = [1, 2, 3]
list_data2 = [4, 5, 6]
print(list(product(list_data, list_data2)))
print(list(zip(list_data, list_data2)))
# 如下两个含义是一样的,都是将可迭代对象复制一份, 很方便的进行同列表的操作
print(list(product(list_data, repeat=2)))
print(list(product(list_data, list_data)))
# 同上述含义
print(list(product(list_data, list_data2, repeat=2)))
print(list(product(list_data, list_data2, list_data, list_data2)))
#输出
[(1, 4), (1, 5), (1, 6), (2, 4), (2, 5), (2, 6), (3, 4), (3, 5), (3, 6)]
[(1, 4), (2, 5), (3, 6)]
[(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)]
[(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)]
[(1, 4, 1, 4), (1, 4, 1, 5), (1, 4, 1, 6), (1, 4, 2, 4), (1, 4, 2, 5), (1, 4, 2, 6), (1, 4, 3, 4), (1, 4, 3, 5), (1, 4, 3, 6), (1, 5, 1, 4), (1, 5, 1, 5), (1, 5, 1, 6), (1, 5, 2, 4), (1, 5, 2, 5), (1, 5, 2, 6), (1, 5, 3, 4), (1, 5, 3, 5), (1, 5, 3, 6), (1, 6, 1, 4), (1, 6, 1, 5), (1, 6, 1, 6), (1, 6, 2, 4), (1, 6, 2, 5), (1, 6, 2, 6), (1, 6, 3, 4), (1, 6, 3, 5), (1, 6, 3, 6), (2, 4, 1, 4), (2, 4, 1, 5), (2, 4, 1, 6), (2, 4, 2, 4), (2, 4, 2, 5), (2, 4, 2, 6), (2, 4, 3, 4), (2, 4, 3, 5), (2, 4, 3, 6), (2, 5, 1, 4), (2, 5, 1, 5), (2, 5, 1, 6), (2, 5, 2, 4), (2, 5, 2, 5), (2, 5, 2, 6), (2, 5, 3, 4), (2, 5, 3, 5), (2, 5, 3, 6), (2, 6, 1, 4), (2, 6, 1, 5), (2, 6, 1, 6), (2, 6, 2, 4), (2, 6, 2, 5), (2, 6, 2, 6), (2, 6, 3, 4), (2, 6, 3, 5), (2, 6, 3, 6), (3, 4, 1, 4), (3, 4, 1, 5), (3, 4, 1, 6), (3, 4, 2, 4), (3, 4, 2, 5), (3, 4, 2, 6), (3, 4, 3, 4), (3, 4, 3, 5), (3, 4, 3, 6), (3, 5, 1, 4), (3, 5, 1, 5), (3, 5, 1, 6), (3, 5, 2, 4), (3, 5, 2, 5), (3, 5, 2, 6), (3, 5, 3, 4), (3, 5, 3, 5), (3, 5, 3, 6), (3, 6, 1, 4), (3, 6, 1, 5), (3, 6, 1, 6), (3, 6, 2, 4), (3, 6, 2, 5), (3, 6, 2, 6), (3, 6, 3, 4), (3, 6, 3, 5), (3, 6, 3, 6)]
[(1, 4, 1, 4), (1, 4, 1, 5), (1, 4, 1, 6), (1, 4, 2, 4), (1, 4, 2, 5), (1, 4, 2, 6), (1, 4, 3, 4), (1, 4, 3, 5), (1, 4, 3, 6), (1, 5, 1, 4), (1, 5, 1, 5), (1, 5, 1, 6), (1, 5, 2, 4), (1, 5, 2, 5), (1, 5, 2, 6), (1, 5, 3, 4), (1, 5, 3, 5), (1, 5, 3, 6), (1, 6, 1, 4), (1, 6, 1, 5), (1, 6, 1, 6), (1, 6, 2, 4), (1, 6, 2, 5), (1, 6, 2, 6), (1, 6, 3, 4), (1, 6, 3, 5), (1, 6, 3, 6), (2, 4, 1, 4), (2, 4, 1, 5), (2, 4, 1, 6), (2, 4, 2, 4), (2, 4, 2, 5), (2, 4, 2, 6), (2, 4, 3, 4), (2, 4, 3, 5), (2, 4, 3, 6), (2, 5, 1, 4), (2, 5, 1, 5), (2, 5, 1, 6), (2, 5, 2, 4), (2, 5, 2, 5), (2, 5, 2, 6), (2, 5, 3, 4), (2, 5, 3, 5), (2, 5, 3, 6), (2, 6, 1, 4), (2, 6, 1, 5), (2, 6, 1, 6), (2, 6, 2, 4), (2, 6, 2, 5), (2, 6, 2, 6), (2, 6, 3, 4), (2, 6, 3, 5), (2, 6, 3, 6), (3, 4, 1, 4), (3, 4, 1, 5), (3, 4, 1, 6), (3, 4, 2, 4), (3, 4, 2, 5), (3, 4, 2, 6), (3, 4, 3, 4), (3, 4, 3, 5), (3, 4, 3, 6), (3, 5, 1, 4), (3, 5, 1, 5), (3, 5, 1, 6), (3, 5, 2, 4), (3, 5, 2, 5), (3, 5, 2, 6), (3, 5, 3, 4), (3, 5, 3, 5), (3, 5, 3, 6), (3, 6, 1, 4), (3, 6, 1, 5), (3, 6, 1, 6), (3, 6, 2, 4), (3, 6, 2, 5), (3, 6, 2, 6), (3, 6, 3, 4), (3, 6, 3, 5), (3, 6, 3, 6)]
ログイン後にコピー
repeat(object[,times])
object: 任意の正当なオブジェクト
times: オプション、オブジェクトが生成される回数 (times が生成されない場合)渡されると、無限ループ
反復子を返し、時間に基づいてオブジェクト オブジェクトを繰り返し生成します。
from itertools import repeat
str_data = "assd"
print(repeat(str_data))
print(list(repeat(str_data, 4)))
list_data = [1, 2, 4]
print(repeat(list_data))
print(list(repeat(list_data, 4)))
dict_data = {"a": 1, "b": 2}
print(repeat(dict_data))
print(list(repeat(dict_data, 4)))
#输出
repeat('assd')
['assd', 'assd', 'assd', 'assd']
repeat([1, 2, 4])
[[1, 2, 4], [1, 2, 4], [1, 2, 4], [1, 2, 4]]
repeat({'a': 1, 'b': 2})
[{'a': 1, 'b': 2}, {'a': 1, 'b': 2}, {'a': 1, 'b': 2}, {'a': 1, 'b': 2}]ログイン後にコピー
starmap(function, iterable)
function: スコープ反復子オブジェクト要素の関数
iterable: iterable object
反復子を返し、関数を適用しますMap 関数と同様に、反復可能オブジェクトのすべての要素 (すべての要素は反復可能オブジェクトでなければなりません。値が 1 つしかない場合でも、タプル (1, ) などの反復可能オブジェクトでラップする必要があります)。パラメーターが反復可能オブジェクトの要素と一致している場合は、要素の代わりにタプルを使用します ([(2,3), (3,3)] に対応する pow(a, b) など)。
map と starmap の違いは、map は通常、関数にパラメータが 1 つしかない場合に動作するのに対し、starmap は関数に複数のパラメータがある場合に動作できることです。
from itertools import starmap
list_data = [1, 2, 3, 4, 5]
list_data2 = [(1, 1), (2, 2), (3, 3), (4, 4), (5, 5)]
list_data3 = [(1,), (2,), (3,), (4,), (5,)]
print(list(starmap(lambda x, y: x + y, list_data2)))
print(list(map(lambda x: x * x, list_data)))
print(list(starmap(lambda x: x * x, list_data)))
print(list(starmap(lambda x: x * x, list_data3)))
#输出
[2, 4, 6, 8, 10]
[1, 4, 9, 16, 25]
Traceback (most recent call last):
File "c:\Users\ts\Desktop\2022.7\2022.7.22\test.py", line 65, in <module>
print(list(starmap(lambda x: x * x, list_data)))
TypeError: 'int' object is not iterableログイン後にコピー
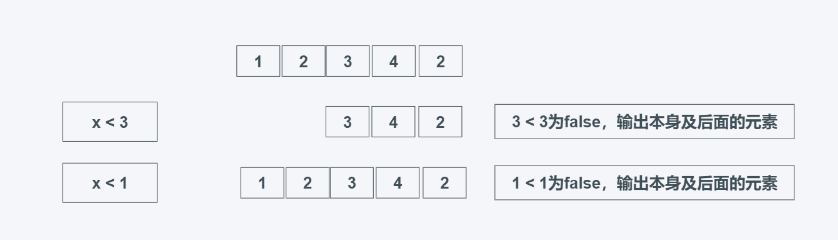
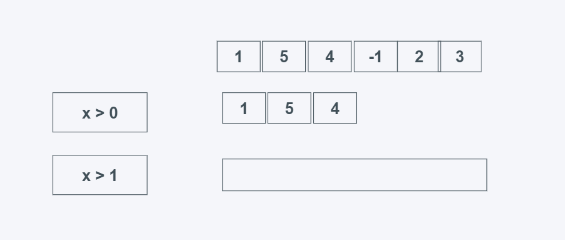
takewhile(predicate, iterable)
predicate:判断条件,为真就返回
iterable: 可迭代对象
当predicate为真时返回元素,需要注意的是,当第一个元素不为True时,则后面的无论结果如何都不会返回,找的前多少个为True的元素。
from itertools import takewhile
#学习中遇到问题没人解答?小编创建了一个Python学习交流群:725638078
list_data = [1, 5, 4, 6, 2, 3]
print(list(takewhile(lambda x: x > 0, list_data)))
print(list(takewhile(lambda x: x > 1, list_data)))
ログイン後にコピー
zip_longest(*iterables, fillvalue=None)
iterables:可迭代对象
fillvalue:当长度超过时,缺省值、默认值, 默认为None
返回迭代器, 可迭代对象元素一一对应生成元组,当两个可迭代对象长度不一致时,会按照最长的有元素输出并使用fillvalue补充,是zip的反向扩展,zip为最小长度输出。
from itertools import zip_longest
list_data = [1, 2, 3]
list_data2 = ["a", "b", "c", "d"]
print(list(zip_longest(list_data, list_data2, fillvalue="-")))
print(list(zip_longest(list_data, list_data2)))
print(list(zip(list_data, list_data2)))
[(1, 'a'), (2, 'b'), (3, 'c'), ('-', 'd')]
[(1, 'a'), (2, 'b'), (3, 'c'), (None, 'd')]
[(1, 'a'), (2, 'b'), (3, 'c')]
ログイン後にコピー
总结
accumulate(iterable: Iterable, func: None, initial:None):
进行可迭代对象元素的累计运算,可以设置初始值,类似于reduce,相比较reduce,accumulate可以输出中间过程的值,reduce只能输出最后结果,且accumulate性能略好于reduce。
chain(*iterables)
依次输出迭代器中的元素,不会循环输出,有多少输出多少。当输出字典元素时,默认会输出字典的键;而对于列表,则相当于使用extend函数。
combinations(iterable: Iterable, r):
抽取可迭代对象的子序列,其实就是排列组合,不过只返回有序、不重复的子序列,以元组形式呈现。
combinations_with_replacement(iterable: Iterable, r)
类似于combinations,从可迭代对象中提取子序列,但是返回的子序列是无序且不重复的,以元组的形式呈现。
compress(data: Iterable, selectors: Iterable)
根据selectors中的元素是否为True或者False返回可迭代对象的合法元素,selectors为str时,都为True,并且只会决定长度。
count(start, step):
从start开始安装step不断生成元素,是无限循环的,最好控制输出个数或者使用next(),send()等获取、设置结果
cycle(iterable)
循环输出可迭代对象的元素,相当于对chain函数进行无限循环。建议控制输出数据的数量,或使用next()、send()等函数获取或设置返回结果。
dropwhile(predicate, iterable)
根据predicate是否为False来返回可迭代器元素,predicate可以为函数, 返回的是第一个False及之后的所有元素,不管后面的元素是否为True或者False。这个函数适用于舍弃迭代器或可迭代对象的开头部分,比如在写入文件时忽略文档注释

filterfalse(predicate, iterable)
类似于filter方法,返回所有满足predicate条件的元素,作为一个可迭代对象。
groupby(iterable, key=None)
输出连续符合key要求的键值对,默认为x == x。
islice(iterable, stop)\islice(iterable, start, stop[, step])
对可迭代对象进行切片,和普通切片类似,但是这个不支持负数。这种方法适用于迭代对象的切片,比如你需要获取文件中的某几行内容
pairwise(iterable)
返回连续的重叠对象(两个元素), 少于两个元素返回空,不返回。
permutations(iterable, r=None)
从可迭代对象中抽取子序列,与combinations类似,不过抽取的子序列是无序、可重复。
product(*iterables, repeat=1)
输出可迭代对象的笛卡尔积,类似于排序组合,不可重复,是两个或者多个可迭代对象进行操作,当是一个可迭代对象时,则返回元素,以元组形式返回。
repeat(object[, times])
重复返回object对象,默认时无限循环
starmap(function, iterable)
批量操作可迭代对象中的元素,操作的可迭代对象中的元素必须也要是可迭代对象,与map类似,但是可以对类似于多元素的元组进行操作。
takewhile(predicate, iterable)
返回前多少个predicate为True的元素,如果第一个为False,则直接输出一个空。
zip_longest(*iterables, fillvalue=None)
将可迭代对象中的元素一一对应,组成元组形式存储,与zip方法类似,不过zip是取最短的,而zip_longest是取最长的,缺少的使用缺省值。















 7529
7529
 15
15

 PHPとPython:2つの一般的なプログラミング言語を比較します
Apr 14, 2025 am 12:13 AM
PHPとPython:2つの一般的なプログラミング言語を比較します
Apr 14, 2025 am 12:13 AM
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
 debian opensslでHTTPSサーバーを構成する方法
Apr 13, 2025 am 11:03 AM
debian opensslでHTTPSサーバーを構成する方法
Apr 13, 2025 am 11:03 AM
 Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
 DebianのGitlabのプラグイン開発ガイド
Apr 13, 2025 am 08:24 AM
DebianのGitlabのプラグイン開発ガイド
Apr 13, 2025 am 08:24 AM
 Apacheとは何ですか
Apr 13, 2025 pm 12:06 PM
Apacheとは何ですか
Apr 13, 2025 pm 12:06 PM
 PHPおよびPython:コードの例と比較
Apr 15, 2025 am 12:07 AM
PHPおよびPython:コードの例と比較
Apr 15, 2025 am 12:07 AM
 Apacheはどの言語に書かれていますか?
Apr 13, 2025 pm 12:42 PM
Apacheはどの言語に書かれていますか?
Apr 13, 2025 pm 12:42 PM
