

Redis7.0 デプロイクラスターを実装する方法

Redis7.0 デプロイ クラスターの詳細バージョン
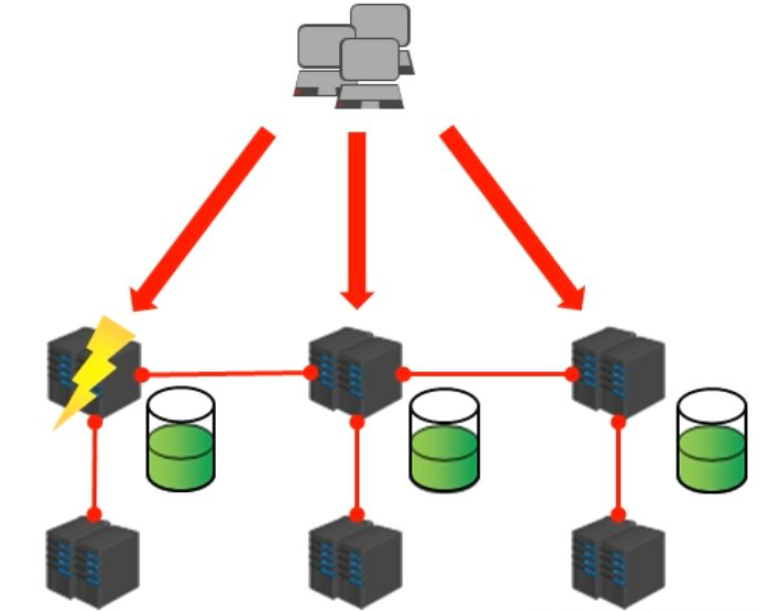
クラスター アーキテクチャは、ネットワーク経由で複数のコンピューターを接続し、統一された管理方法を使用して、外部からはサービスを提供する単一のコンピューターのように見える方法です
クラスターの役割:
単一サーバーのアクセス圧力を分散し、負荷分散を実現します
単一サーバーのストレージを分散します。スケーラビリティを実現します
単一サーバーのダウンタイムによって引き起こされるビジネス上の災害を軽減します
1、 Redis クラスターの内部構造の設計
データ ストレージ設計
アルゴリズム設計を通じて、キーの保存場所を計算します
すべてのストレージ スペースは 16384 個のパーツに分割される予定で、各ホストはパーツを保存します。各パーツは、キーのストレージ スペースではなく、ストレージ スペースを表します。
キーは次のように計算されます。結果は対応するストレージ スペースに配置されます
- #スケーラビリティの強化 (新しいストレージ スペースが追加され、正式には
slot
と呼ばれます)##クラスターの内部通信設計
- 各データベースは相互に通信し、スロットの番号付きデータを各ライブラリに保存します
- # #ヒットしたら直接リターン
- ミスしたら特定の場所を通知
-
##2. クラスターの内部構造の構築
メインコマンドは mainコマンドで実行されます。操作クライアント
mainコマンドで実行されます。操作クライアント
構成ファイル
変更redis.conf
次のコンテンツを追加します
cluster-enabled yes # 启动为节点 cluster-config-file nodes-6379.conf # cluster配置文件名,该文件属于自动生成,仅用于快速查找文件并查询文件内容 cluster-node-timeout 10000 # 节点服务响应超时时间,用于判定该节点是否下线或切换为从节点 cluster-migration-barrier <count> # master连接的slave最小数量
すぐに構成ファイルの 5 つのポイントをコピーし、内部のポートを置き換えますすべての実行後、[root@localhost conf]# sed "s/6379/6380/g" redis-6379.conf > redis-6380.conf [root@localhost conf]# sed "s/6379/6381/g" redis-6379.conf > redis-6381.conf [root@localhost conf]# sed "s/6379/6382/g" redis-6379.conf > redis-6382.conf [root@localhost conf]# sed "s/6379/6383/g" redis-6379.conf > redis-6383.conf [root@localhost conf]# sed "s/6379/6384/g" redis-6379.conf > redis-6384.conf [root@localhost conf]# sed "s/6379/6385/g" redis-6379.conf > redis-6385.confログイン後にコピー
cat
コマンドを使用して内容をチェックし、変更されていることを確認できます
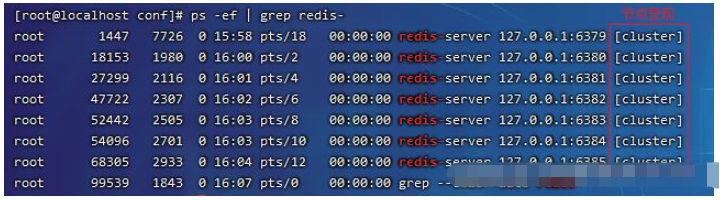
redis サービス クラスターを開始しますコマンドを実行して redis プロセスとポートを表示します# 在第一个窗口执行6379服务 redis-server redis-6379.conf # 在第二个窗口执行6380服务 redis-server redis-6380.conf # 在第三个窗口执行6381服务 redis-server redis-6381.conf # 下面的代码依次类推到6385ログイン後にコピー
ps -ef | grep redis-
##接続ノード
 src ディレクトリの表示
src ディレクトリの表示
上位バージョンでは、起動操作は構成情報の表示結果は以下のとおりですredis-cli
ruby## に移動されました#開始するには、と
gem という 2 つのファイルを 2 回ダウンロードする必要があります。# 下载命令也会将gem一起 yum -y install rubygemsログイン後にコピー
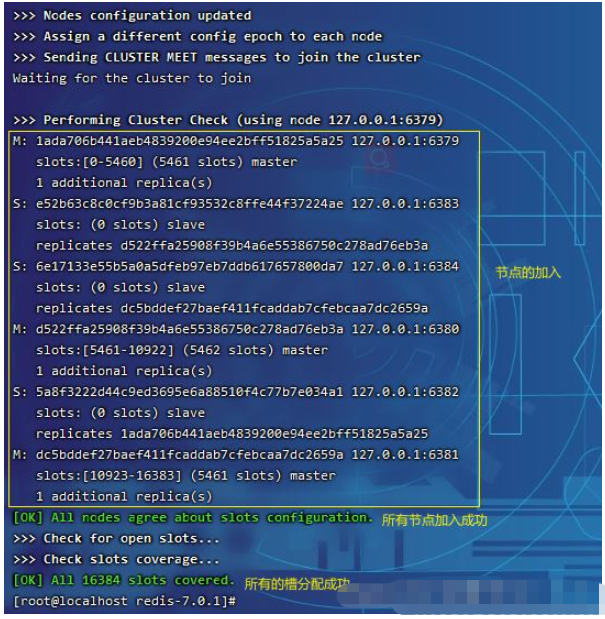
# --cluster create 创建集群 # --cluster-replicas 1 指定集群的内部结构(1代表一个master连接1个slave,2代表一个master连接两个save) # 后面的连接端口按数量实现master连接哪一个slave,1对1,1对2 redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 --cluster-replicas 1ログイン後にコピー実行結果は次のとおりです

yes
を実行した後の情報コマンドは次のとおりです。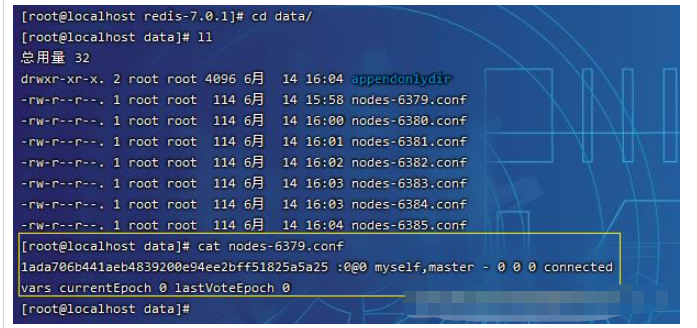
記録されている構成ファイル情報を再度確認します。すべてのクラスタ情報
 クライアントを起動してデータを保存します。
クライアントを起動してデータを保存します。
パラメーターを通じてクラスターを操作できます。さらに、redis コマンドを操作するときに、プロンプトクラスター デプロイメントが使用されるため、指定されていない場合は、
-c
( error) MOVED 5798 127.0.0.1:6380
注:
-c操作クラスタークライアントに接続するポートを指定してくださいredis-cli -c # 创建key,通过返回信息可以知道key存储到6380下了 127.0.0.1:6379> set name 123 -> Redirected to slot [5798] located at 127.0.0.1:6380 OKログイン後にコピー# 连接指定的集群客户端 [root@localhost data]# redis-cli -c -p 6382 # 获取key 127.0.0.1:6382> get name -> Redirected to slot [5798] located at 127.0.0.1:6380 "123" 127.0.0.1:6380>ログイン後にコピークラスターノード操作コマンド
クラスターノード情報の表示
cluster nodes
スレーブノードredisを入力し、マスターノードを切り替えるcluster replicate <master-id>
cluster meet ip:port
ソルトなしのノードを無視します
cluster forget <id>
手動フェールオーバー
cluster failover
ノードの追加
redis-trib.rb add-node
ノードの削除redis-trib.rb del-node
redis-trib.rb reshard
3. マスター/スレーブのオフラインとマスター/スレーブの切り替え
1. スレーブのオフライン操作をシミュレートする
スレーブ サーバーで実行Ctrl C
サービスをダウンロード接続されているホストのステータスを観察します。ホストは、スレーブ サーバーに障害が発生した場合にそのスレーブを失敗としてマークします。 10 秒以内にスレーブに接続できません。他のクラスタ サービスは接続に失敗し、他のサービスはメッセージ#スレーブを再起動し、ホストが再接続します。スレーブ マシン上
マスター マシンがオフラインになると、スレーブ マシンは特定のスロットに切り替わります。マスター マシンがオンラインに戻ると、元のマスター マシンがスレーブ マシンになります。
以上がRedis7.0 デプロイクラスターを実装する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7554
7554
 15
1382
52
83
11
24
96
15
1382
52
83
11
24
96

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisを使用して操作をロックするには、setnxコマンドを介してロックを取得し、有効期限を設定するために有効期限コマンドを使用する必要があります。特定の手順は次のとおりです。(1)SETNXコマンドを使用して、キー価値ペアを設定しようとします。 (2)expireコマンドを使用して、ロックの有効期限を設定します。 (3)Delコマンドを使用して、ロックが不要になったときにロックを削除します。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
Redisはハッシュテーブルを使用してデータを保存し、文字列、リスト、ハッシュテーブル、コレクション、注文コレクションなどのデータ構造をサポートします。 Redisは、スナップショット(RDB)を介してデータを維持し、書き込み専用(AOF)メカニズムを追加します。 Redisは、マスタースレーブレプリケーションを使用して、データの可用性を向上させます。 Redisは、シングルスレッドイベントループを使用して接続とコマンドを処理して、データの原子性と一貫性を確保します。 Redisは、キーの有効期限を設定し、怠zyな削除メカニズムを使用して有効期限キーを削除します。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 Redis用のメッセージミドルウェアの作成方法
Apr 10, 2025 pm 07:51 PM
Redis用のメッセージミドルウェアの作成方法
Apr 10, 2025 pm 07:51 PM
Redisは、メッセージミドルウェアとして、生産消費モデルをサポートし、メッセージを持続し、信頼できる配信を確保できます。メッセージミドルウェアとしてRedisを使用すると、低遅延、信頼性の高いスケーラブルなメッセージングが可能になります。
