

一般的な統計合計、タイ値の計算、およびその他の操作は、次を使用して実装できます。集約関数 、一般的な集約関数は次のとおりです:
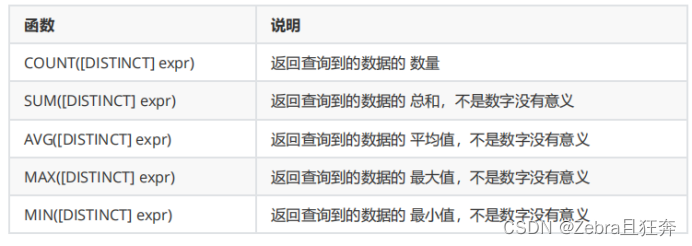

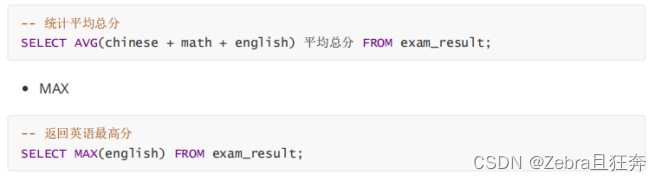


注:
1. カウント: count (*)、count (0)、count (1) を使用できます。平たく言えば、テーブル全体から 1 を選択するのと同じです。この count の 0 と 1 がパラメーターとして渡されるだけです。 、最初に 1 を選択し、次に count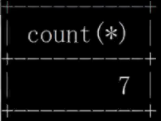
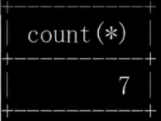
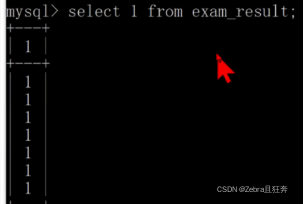

 #Select で指定されたフィールドgroup by の後にある必要があります。 Yes と no は集計関数でのみ使用できます。そうでない場合は、問題が発生します。
#Select で指定されたフィールドgroup by の後にある必要があります。 Yes と no は集計関数でのみ使用できます。そうでない場合は、問題が発生します。
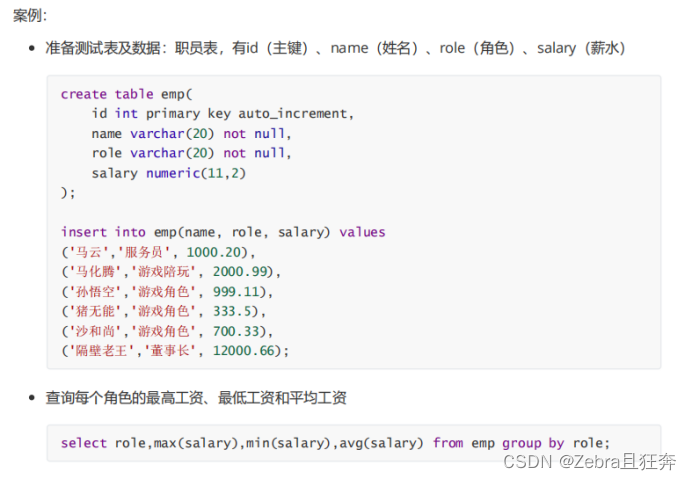
1. Group by ステートメントの本質は次のとおりです。グループ化、多くの場合、集計クエリと一緒に使用します
2。集計関数がある限り、グループ化できます
3。グループ化操作では、クエリによりフィールドと集計関数をグループ化できます。 、および他の非グループ化フィールドを保証する必要があります。 グループ化後に複数の行が存在することはありません (学生 ID のグループ化など、学生 ID のグループ化後は行が 1 つしかないため、クエリ フィールドに学生名を含めることができます)
4. グループ化する前に where を使用して条件をフィルターし、グループ化した後に had を使用します (コードは実行の順序です)
実行順序: from > on> join > where > group by > with > getting >select > Distinct > order by > limit
まずスコア > 60 の行を検索し、クラス ID に従ってグループ化します。得られた結果からクラス
6.group by は、繰り返しの行を 1 つの行にマージすることです
7。 group by フィールド数が多い場合はマージできない場合がありますが、グループ化の効果は得られ、集計関数も使用できます。
3.HAVING

構文:

2 番目の方法では、接続条件とフィルタリング結果セット条件の違いが区別できない場合があります。どちらを使用しても構いませんが、後続の外部結合に対応するために、最初のものを優先してください。内部結合は、取得したデカルト積に接続条件を与えるのと等価です。
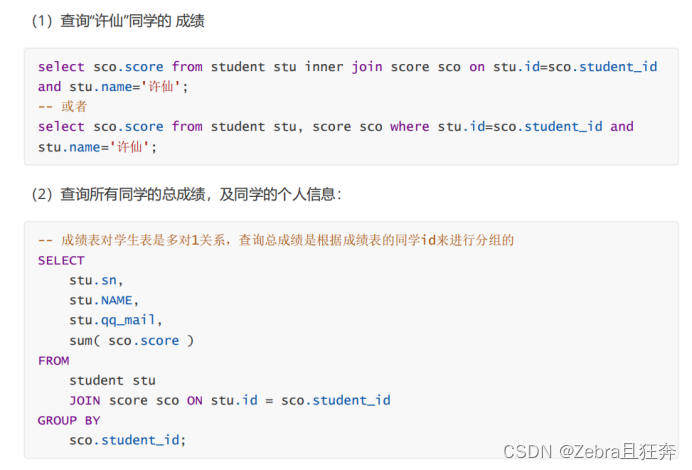
ここで group by を使用しない場合は、次のような 1 行だけになります。これは等価です。すべての生徒の得点を合計します。必要なのは各学生の合計スコアなので、最初に学生 ID に従ってグループ化する必要があります。

外部結合は、左外部結合と右外部結合に分けられます。左外部結合は、結合クエリを実行したときに左側のテーブルが完全に表示される場合の接続方法であり、右外部結合は、結合クエリが実行された場合に右側のテーブルが完全に表示される場合の接続方法です。
注:
左結合: 左のテーブルのデータは、結合条件 (以降の部分を含む) に基づきません。 the and) フィルタリングしてすべてを表示します。後で where や他の条件を追加するなど、他の条件もフィルタリングできます。
右のテーブルに接続条件を満たさない値のデータがある場合、右のテーブルのデータはnull、左のテーブルはすべて表示されます
構文: (注: on の後に where を続けることもできます)


同じクエリこの方法では、今回は 8 位の結果が表示されます。 空の学生情報の場合、左のテーブル、つまり学生テーブルのすべてのデータが表示され、接続条件 stu.id = sco の影響を受けません。 Student_id. 前の 以内の場合 接続時、 は学生「中国語学習外国人」 の情報を表示できません。は、sco テーブルにある学生「中国語を学習する外国人」の ID ではありません。
自己結合とは、同じテーブル内で自分自身を接続してクエリを実行することを指します。
使用シナリオ: 同じテーブル内の複数の行を比較します。
注: 自己結合クエリは、join on ステートメントを使用してクエリすることもできます。
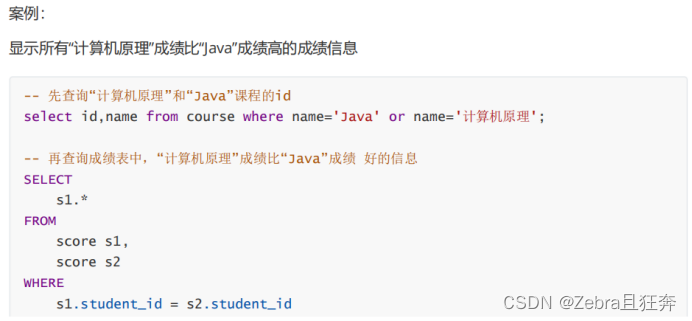
サブクエリは、他の SQL ステートメントに埋め込まれた選択ステートメントを指し、ネストされたクエリとも呼ばれます
クエリとクラスメート「卒業したくない」学生の数: (自己結合)

複数行サブクエリ: 複数行のレコードを返すサブクエリ (頻繁に使用されます)
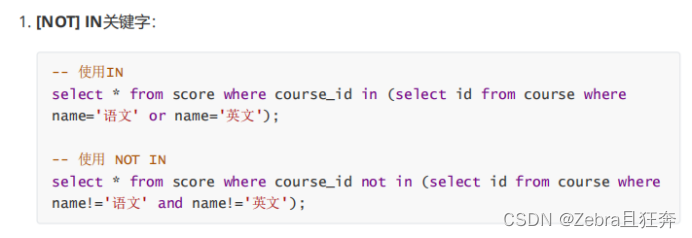
ケース: 「中国語」または「英語」コースのスコア情報をクエリする: (内部接続)
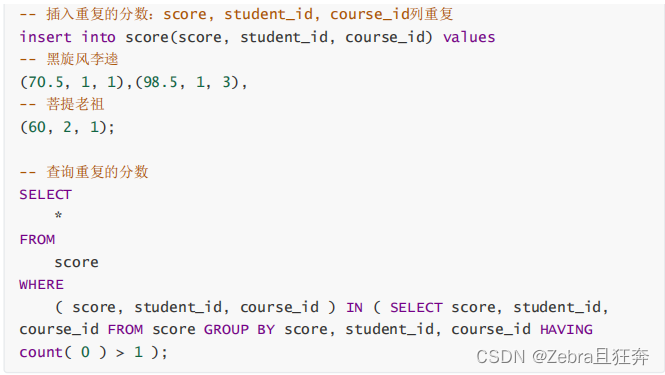
ここでグループ化します。マージには役割を果たしませんが、グループ化には役割を果たします
実際のアプリケーションでは、実行をマージするために、結果として、集合演算子 Union、Union all を使用できるようになります。 UNION および UNION ALL を使用する場合、クエリの前後の 結果セット内のフィールドは 一貫している必要があります。
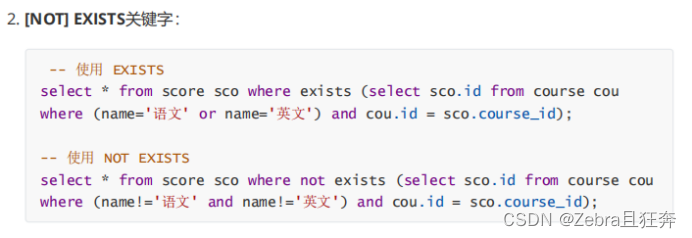
#**場合によっては、複数のテーブルを関連付けることはできませんが、同じフィールド内のデータをクエリする必要があります。**ユニオンは or より効率的ですケース: ID が 3 未満、または名前が「English」のコースをクエリする:
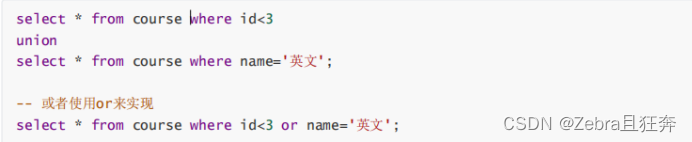
この演算子は、2 つの結果セットの和集合を取得するために使用されます。この演算子を使用すると、結果セット内の重複行は削除されません。 (取得したデータが全く同じ場合は重複せず表示されます)
#ケース: ID が 3 未満または名前が「Java」のコースをクエリする 
以上がMySQL の集計クエリとユニオン クエリの操作の分析例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



