

SpringBoot AOP Redis が遅延二重削除機能を実装する方法

1. ビジネス シナリオ
マルチスレッド同時実行の場合、データベース変更リクエストが 2 つあると仮定し、それらの間のデータの整合性を確保します。データベースと Redis、
変更リクエストの実装では、データベースを変更した後、Redis 内のデータをカスケード変更する必要があります。
リクエスト 1: A はデータベース データを変更します B は Redis データを変更します
リクエスト 2: C はデータベース データを変更します D は Redis データを変更します
同時状況では、A —> C &mdash が発生します;> D — > 状況 B
(スレッドによる複数のアトミック操作の同時実行の順序は重複する可能性があることを必ず理解してください)
1. 現時点での問題点
A データベースを変更する 最終的にデータは Redis に保存され、A の後に C もデータベースのデータを変更しました。
現時点では、Redis 内のデータとデータベースのデータの間に不整合が発生しています。その後のクエリ処理では、最初に Redis が長時間チェックされることになり、その結果、クエリされたデータは、データベースのデータと一致しません。データベース内の実際のデータについての質問です。
2. 解決策
Redis を使用する場合、Redis とデータベース データの一貫性を維持する必要があります。最も一般的な解決策の 1 つは、遅延二重削除戦略です。
注: 頻繁に変更されるデータ テーブルは Redis の使用には適していないことを知っておく必要があります。これは、二重削除戦略の結果、Redis に保存されているデータが削除され、後続のクエリでデータベースがクエリされるためです。したがって、Redis は、変更よりもはるかに読み取りの多いデータ キャッシュを使用します。
遅延二重削除スキームの実行手順
1> キャッシュの削除
2> データベースの更新
3> 500 ミリ秒の遅延 (特定のビジネスに応じて遅延実行時間を設定します)
4> キャッシュの削除
3. 500 ミリ秒の遅延があるのはなぜですか?
2 回目の Redis 削除の前に、データベースの更新操作を完了する必要があります。 3 番目のステップがない場合、Redis の 2 つの削除操作が完了した後、データベース内のデータが更新されていない可能性が高いと仮定します。この時点でデータへのアクセス要求がある場合、問題は発生します。冒頭で述べたような質問が表示されます。
4. キャッシュを 2 回削除する必要があるのはなぜですか?
2 回目の削除操作がなく、この時点でデータへのアクセス要求がある場合、それは以前に変更されていない Redis データである可能性があります。削除操作の実行後、Redis はリクエストが来るとデータベースにアクセスしますが、このときデータベース内のデータは更新されたデータとなり、データの整合性が保たれます。
2. コードの練習
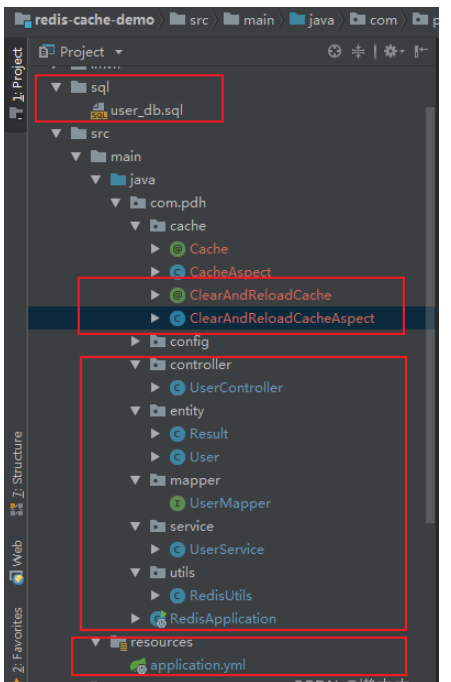
1. Redis と SpringBoot AOP の依存関係を導入する
<!-- redis使用 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- aop -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>2. カスタム AOP アノテーションとアスペクトを記述する
ClearAndReloadCache 遅延を倍増させるアノテーションを削除する
/**
*延时双删
**/
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Target(ElementType.METHOD)
public @interface ClearAndReloadCache {
String name() default "";
}ClearAndReloadCacheAspect によるアスペクトの二重削除の遅延
@Aspect
@Component
public class ClearAndReloadCacheAspect {
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 切入点
*切入点,基于注解实现的切入点 加上该注解的都是Aop切面的切入点
*
*/
@Pointcut("@annotation(com.pdh.cache.ClearAndReloadCache)")
public void pointCut(){
}
/**
* 环绕通知
* 环绕通知非常强大,可以决定目标方法是否执行,什么时候执行,执行时是否需要替换方法参数,执行完毕是否需要替换返回值。
* 环绕通知第一个参数必须是org.aspectj.lang.ProceedingJoinPoint类型
* @param proceedingJoinPoint
*/
@Around("pointCut()")
public Object aroundAdvice(ProceedingJoinPoint proceedingJoinPoint){
System.out.println("----------- 环绕通知 -----------");
System.out.println("环绕通知的目标方法名:" + proceedingJoinPoint.getSignature().getName());
Signature signature1 = proceedingJoinPoint.getSignature();
MethodSignature methodSignature = (MethodSignature)signature1;
Method targetMethod = methodSignature.getMethod();//方法对象
ClearAndReloadCache annotation = targetMethod.getAnnotation(ClearAndReloadCache.class);//反射得到自定义注解的方法对象
String name = annotation.name();//获取自定义注解的方法对象的参数即name
Set<String> keys = stringRedisTemplate.keys("*" + name + "*");//模糊定义key
stringRedisTemplate.delete(keys);//模糊删除redis的key值
//执行加入双删注解的改动数据库的业务 即controller中的方法业务
Object proceed = null;
try {
proceed = proceedingJoinPoint.proceed();
} catch (Throwable throwable) {
throwable.printStackTrace();
}
//开一个线程 延迟1秒(此处是1秒举例,可以改成自己的业务)
// 在线程中延迟删除 同时将业务代码的结果返回 这样不影响业务代码的执行
new Thread(() -> {
try {
Thread.sleep(1000);
Set<String> keys1 = stringRedisTemplate.keys("*" + name + "*");//模糊删除
stringRedisTemplate.delete(keys1);
System.out.println("-----------1秒钟后,在线程中延迟删除完毕 -----------");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
return proceed;//返回业务代码的值
}
}3、application.yml
server:
port: 8082
spring:
# redis setting
redis:
host: localhost
port: 6379
# cache setting
cache:
redis:
time-to-live: 60000 # 60s
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test
username: root
password: 1234
# mp setting
mybatis-plus:
mapper-locations: classpath*:com/pdh/mapper/*.xml
global-config:
db-config:
table-prefix:
configuration:
# log of sql
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# hump
map-underscore-to-camel-case: true4、user_db.sql script
は運用テスト データに使用されます
DROP TABLE IF EXISTS `user_db`; CREATE TABLE `user_db` ( `id` int(4) NOT NULL AUTO_INCREMENT, `username` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of user_db -- ---------------------------- INSERT INTO `user_db` VALUES (1, '张三'); INSERT INTO `user_db` VALUES (2, '李四'); INSERT INTO `user_db` VALUES (3, '王二'); INSERT INTO `user_db` VALUES (4, '麻子'); INSERT INTO `user_db` VALUES (5, '王三'); INSERT INTO `user_db` VALUES (6, '李三');
5、UserController
/**
* 用户控制层
*/
@RequestMapping("/user")
@RestController
public class UserController {
@Autowired
private UserService userService;
@GetMapping("/get/{id}")
@Cache(name = "get method")
//@Cacheable(cacheNames = {"get"})
public Result get(@PathVariable("id") Integer id){
return userService.get(id);
}
@PostMapping("/updateData")
@ClearAndReloadCache(name = "get method")
public Result updateData(@RequestBody User user){
return userService.update(user);
}
@PostMapping("/insert")
public Result insert(@RequestBody User user){
return userService.insert(user);
}
@DeleteMapping("/delete/{id}")
public Result delete(@PathVariable("id") Integer id){
return userService.delete(id);
}
}6、UserService
/**
* service层
*/
@Service
public class UserService {
@Resource
private UserMapper userMapper;
public Result get(Integer id){
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(User::getId,id);
User user = userMapper.selectOne(wrapper);
return Result.success(user);
}
public Result insert(User user){
int line = userMapper.insert(user);
if(line > 0)
return Result.success(line);
return Result.fail(888,"操作数据库失败");
}
public Result delete(Integer id) {
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(User::getId, id);
int line = userMapper.delete(wrapper);
if (line > 0)
return Result.success(line);
return Result.fail(888, "操作数据库失败");
}
public Result update(User user){
int i = userMapper.updateById(user);
if(i > 0)
return Result.success(i);
return Result.fail(888,"操作数据库失败");
}
}3. テスト検証
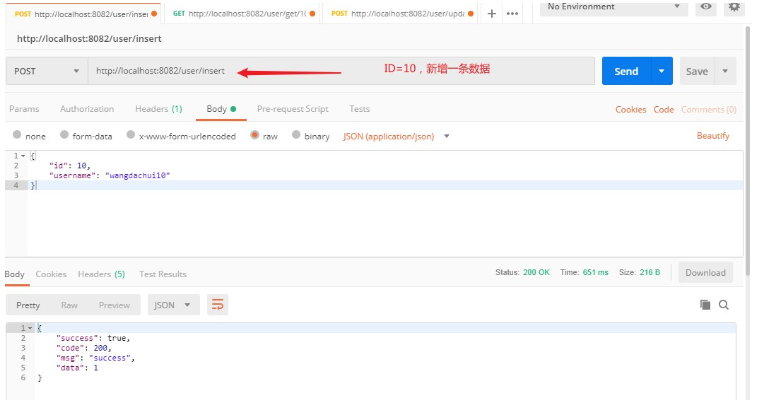
1、ID=10、新しいデータを追加
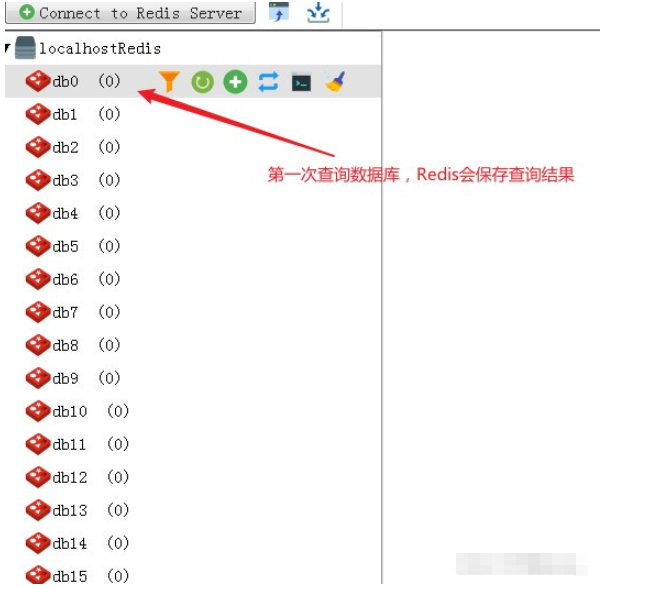
2. 初めてデータベースにクエリを実行するとき、Redis はクエリ結果を保存します
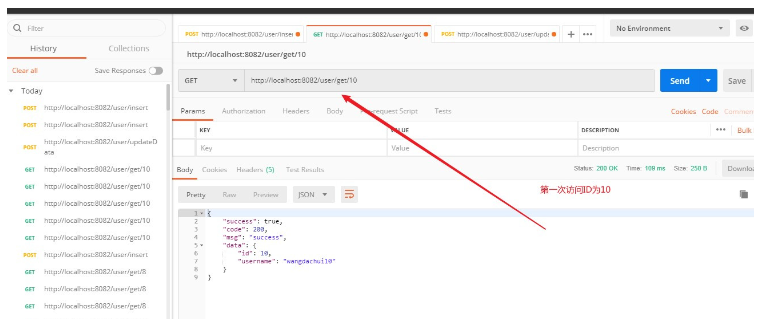
3. 最初のアクセス ID is 10
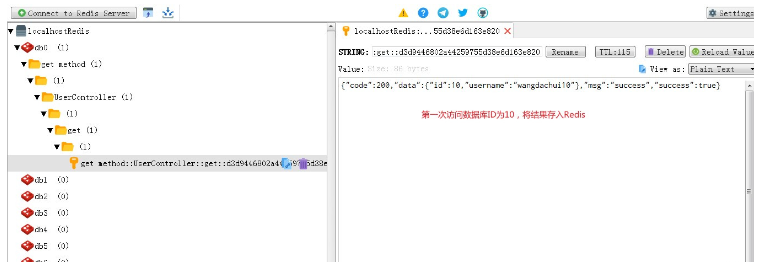
5 に保存します。更新 ID 10 に対応するユーザー名の場合 (データベースとキャッシュの不整合検証スキーム) 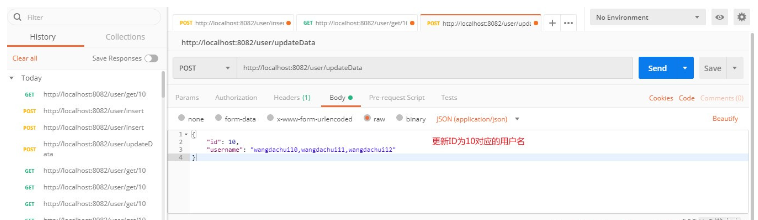
データベースとキャッシュの不整合検証スキーム:
ブレークポイントを作成してシミュレーションA スレッド 最初の削除が実行された後、A がデータベースの更新を完了する前に、別のスレッド B が ID=10 にアクセスし、古いデータを読み取ります。 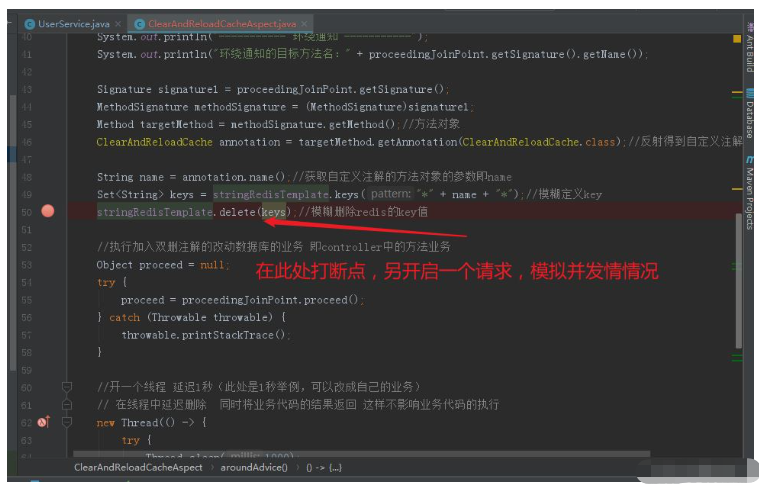
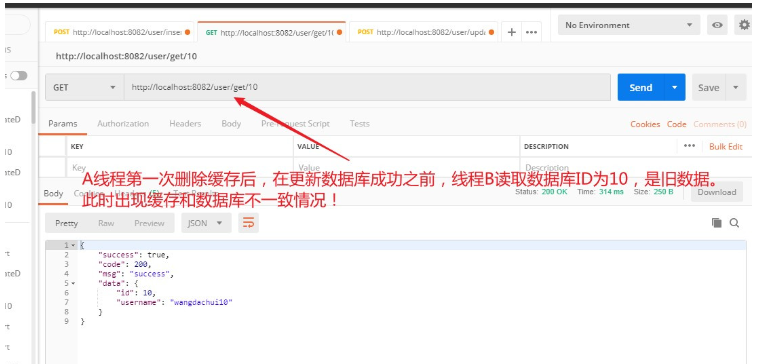
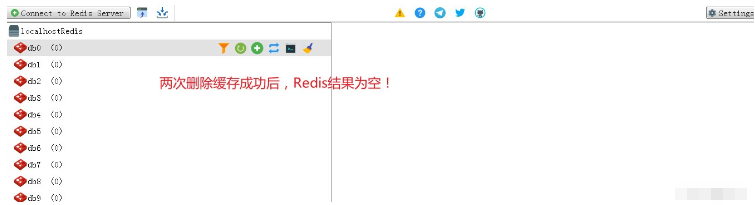
以上がSpringBoot AOP Redis が遅延二重削除機能を実装する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7530
7530
 15
1379
52
82
11
21
76
15
1379
52
82
11
21
76

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
Redisはハッシュテーブルを使用してデータを保存し、文字列、リスト、ハッシュテーブル、コレクション、注文コレクションなどのデータ構造をサポートします。 Redisは、スナップショット(RDB)を介してデータを維持し、書き込み専用(AOF)メカニズムを追加します。 Redisは、マスタースレーブレプリケーションを使用して、データの可用性を向上させます。 Redisは、シングルスレッドイベントループを使用して接続とコマンドを処理して、データの原子性と一貫性を確保します。 Redisは、キーの有効期限を設定し、怠zyな削除メカニズムを使用して有効期限キーを削除します。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示するには、3つの方法があります。キーコマンドを使用して、指定されたパターンに一致するすべてのキーを返します。スキャンコマンドを使用してキーを繰り返し、キーのセットを返します。情報コマンドを使用して、キーの総数を取得します。
