

前提:デフォルトでは、全員がmysqlをインストールしています。
Mysql は、大規模なデータベースをサポートし、数千万のレコードを持つ大規模なデータベースを処理できるリレーショナル データベースです。クローラーによって収集されたデータセットが mysql に保存された後、mysql の関連クエリを使用して関連データを 1 ステップで取得できます。 具体的な機能についてはここでは詳しく説明しませんので、実際の操作から始めましょう。
次のコマンドを使用してインストールします
pip install pymysql
pymysql ライブラリ: Python3 リンク mysql
備考:
ps: MYSQLdb は python2 にのみ適用されます。xx
python3 は MYSQLdb をサポートしていません。代わりに、pymysql
が実行時にレポートします: ImportError: No module names 'MYSQLdb'
import pymysql as pmq
localhost はローカル IP です。ここで Localhost は現在のローカル コンピュータを示すために使用されます。それ以外の場合は、localhost を対応するデータベース IP に変更します。
root はデータベース ユーザー名、123456 はデータベース パスワード、python_chenge はデータベース名です。

画像のデータベース python_chenge が作成されました (構築後、上記のコードを使用して接続できます)。構築後、現在テーブルはありません。 Python を使い始めます テーブルの作成、挿入、クエリ、変更、削除などの操作を実行します (クローラと組み合わせて説明します)
保存する前に、 Python でテーブルを作成します。フィールドは 4 つあります (主キー 映画名、リンク、評価 )
# 创建 movie 表
テーブル映画を作成します。フィールドは (id、タイトル、URL、レート) です。 )、CHARACTER SET utf8 COLLATE utf8_general_ci は文字列エンコーディングが utf8 形式に設定されます
id は主キー、int 型、AUTO_INCREMENT 自動インクリメント、空ではない null ではありません
title、url文字列型 varchar(100) で、これも null ではありません。 空です。
評価率は小数点以下の数値であるため、浮動小数点数であり、空でもありません。

クローラーがデータを収集しました データについては、Python がすでにテーブルを構築しているため、収集したデータをデータベースに挿入できます。導入してください
### 插入数据
for i in json_data['subjects']:

# 查询
 #2. 指定されたデータをクエリします
#2. 指定されたデータをクエリします
これ データのすべてのフィールド #查询单条
##05 更新と変更
### 更新
データベースも確認してください
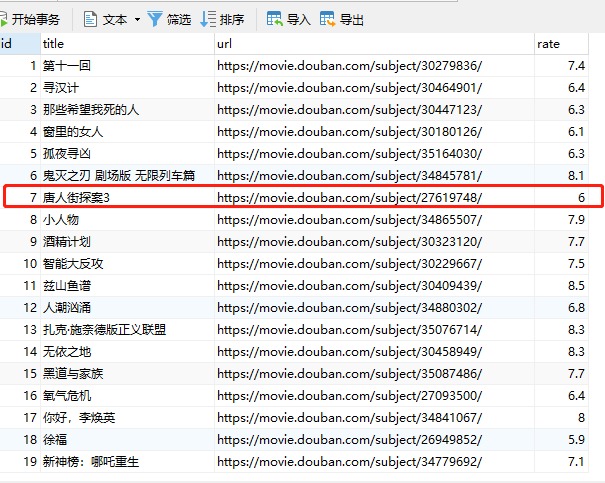 もう一度、チャイナタウンを例に挙げます。その ID は 7 です。削除する場合は、ID を更新して削除できます。
もう一度、チャイナタウンを例に挙げます。その ID は 7 です。削除する場合は、ID を更新して削除できます。
def delete(Id):
以上がPython を使用して Mysql を操作する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



