

GPU より効率的な 7nm プロセス、Meta が第 1 世代 AI 推論アクセラレータをリリース

マシンハートレポート
ハートオブマシン編集部
最近、メタは人工知能における最新の進歩を明らかにしました。
Meta について考えるとき、人々は通常、Facebook、Instagram、WhatsApp、または今後登場する Metaverse などのアプリを思い浮かべます。しかし、多くの人が知らないのは、この会社がこれらのサービスを運用するための非常に洗練されたデータセンターを設計および構築しているということです。
AWS、GCP、Azure などのクラウド サービス プロバイダーとは異なり、Meta は、OCP が購入者に好印象を与えるように設計されている場合を除き、シリコンの選択、インフラストラクチャ、またはデータセンターの設計に関する詳細を開示する必要はありません。 Meta のユーザーは、その実現方法に関係なく、より優れた、より一貫したエクスペリエンスを望んでいます。
Meta では、AI ワークロードがあらゆる場所に存在し、コンテンツ理解、情報フロー、生成 AI、広告ランキングなど、幅広いユースケースの基礎を形成しています。これらのワークロードは、クラス最高の Python 統合、eager モード開発、シンプルな API を備えた PyTorch 上で実行されます。特に、ディープ ラーニング レコメンデーション モデル (DLRM) は、Meta のサービスとアプリケーション エクスペリエンスを向上させるために非常に重要です。しかし、これらのモデルのサイズと複雑さが増大するにつれて、基礎となるハードウェア システムは、効率を維持しながらメモリと計算能力を飛躍的に増加させる必要があります。
Meta は、現在の規模の AI 操作や特定のワークロードでは、GPU が非効率であり、最適な選択肢ではないことを発見しました。そこで同社は、AI システムのトレーニングを高速化するために推論アクセラレータ MTIA を提案しました。
MTIA V1
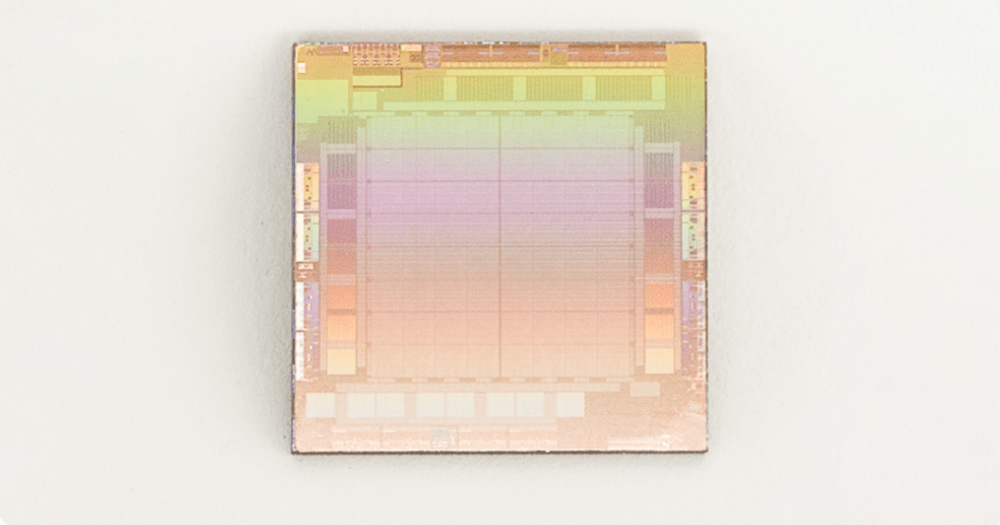
MTIA v1 (推論) チップ (ダイ)
2020 年に、Meta は社内ワークロード用に第 1 世代の MTIA ASIC 推論アクセラレータを設計しました。推論アクセラレータは、シリコン、PyTorch、推奨モデルを含むフルスタック ソリューションの一部です。
MTIA アクセラレータは TSMC 7nm プロセスで製造され、800 MHz で動作し、INT8 精度で 102.4 TOPS、FP16 精度で 51.2 TFLOPS を実現します。熱設計電力 (TDP) は 25 W です。
MTIA アクセラレータは、処理要素 (PE)、オンチップおよびオフチップのメモリ リソース、および相互接続で構成されます。アクセラレータには、システム ファームウェアを実行する専用の制御サブシステムが装備されています。ファームウェアは、利用可能なコンピューティング リソースとメモリ リソースを管理し、専用のホスト インターフェイスを介してホストと通信し、アクセラレータでのジョブの実行を調整します。
メモリ サブシステムは、オフチップ DRAM リソースとして LPDDR5 を使用し、128 GB まで拡張可能です。このチップには、すべての PE で共有される 128 MB のオンチップ SRAM も搭載されており、頻繁にアクセスされるデータと命令に対してより高い帯域幅とより低いレイテンシを提供します。
MTIA アクセラレータ グリッドは、8x8 構成で編成された 64 個の PE で構成され、メッシュ ネットワークを介して相互に接続され、メモリ ブロックにも接続されます。グリッド全体を全体として使用してジョブを実行することも、独立したジョブを実行できる複数のサブグリッドに分割することもできます。
各 PE には 2 つのプロセッサ コア (そのうちの 1 つはベクトル拡張機能を搭載) と、行列の乗算、累算、データ移動、非線形関数の計算などの重要な演算を実行するように最適化された多数の固定関数ユニットが装備されています。 。プロセッサ コアは、RISC-V オープン命令セット アーキテクチャ (ISA) に基づいており、必要なコンピューティングおよび制御タスクを実行するために大幅にカスタマイズされています。
各 PE には、データの高速な保存と操作のために 128 KB のローカル SRAM メモリもあります。このアーキテクチャは、ワークロードを効率的に実行するための基礎となる並列処理とデータの再利用を最大限に高めます。
このチップは、スレッド レベルとデータ レベルの並列処理 (TLP および DLP) の両方を提供し、命令レベルの並列処理 (ILP) を活用し、大量のメモリ リクエストを同時に処理できるようにすることで大規模なメモリ レベルの並列処理 (MLP) を可能にします。 。
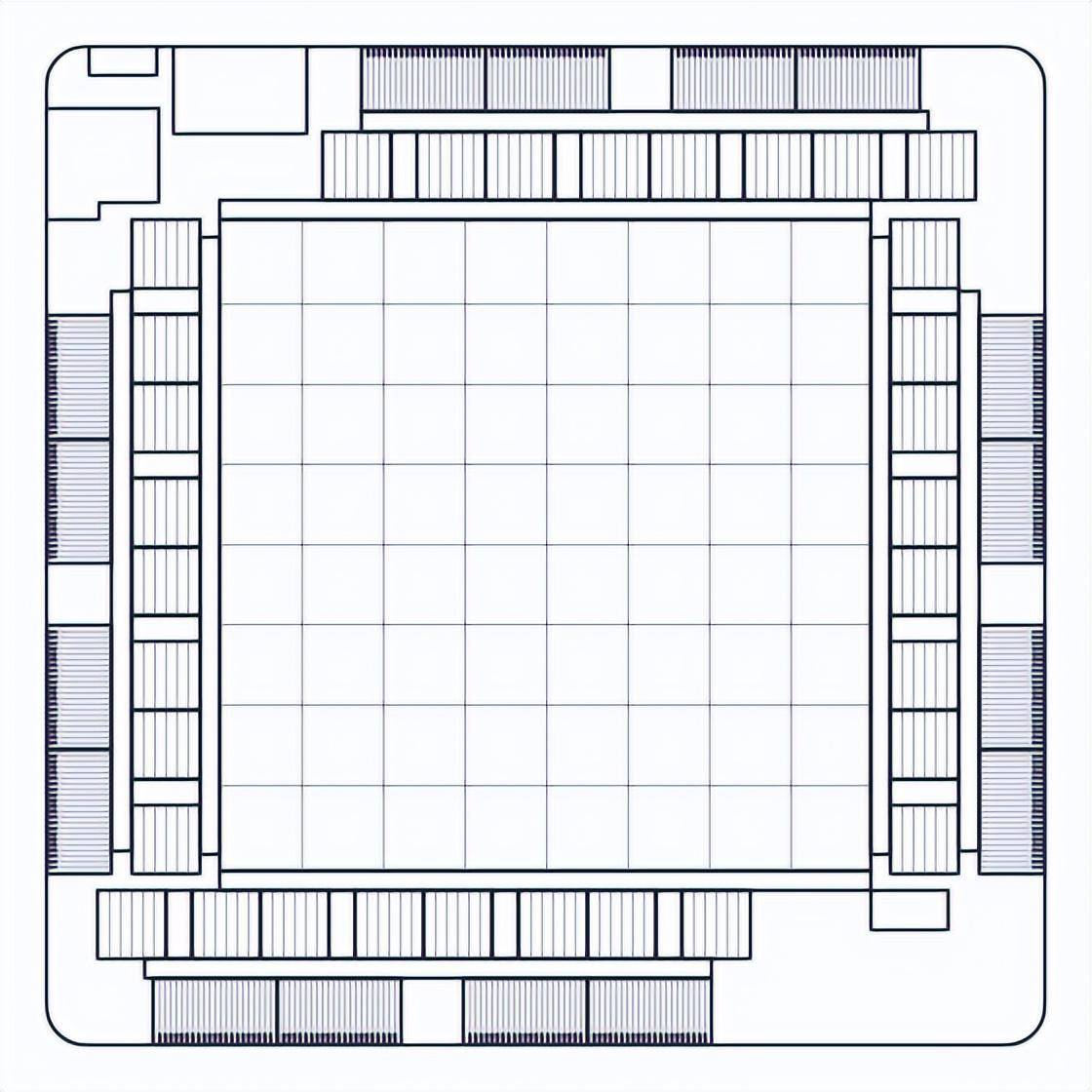
MTIA v1 システム設計
MTIA アクセラレータは、サーバーへの統合を容易にするために、小型のデュアル M.2 ボードにマウントされています。このボードは PCIe Gen4 x8 リンクを使用してサーバー上のホスト CPU に接続し、消費電力はわずか 35 W です。

MTIAを備えたサンプルテストボード
これらのアクセラレータをホストするサーバーは、Open Compute Project の Yosemite V3 サーバー仕様を使用します。各サーバーには 12 個のアクセラレータが含まれており、これらのアクセラレータはホスト CPU に接続され、PCIe スイッチ階層を使用して相互に接続されます。したがって、異なるアクセラレータ間の通信にホスト CPU が関与する必要はありません。このトポロジにより、ワークロードを複数のアクセラレータに分散して並列実行できます。アクセラレータの数とサーバー構成パラメータは、現在および将来のワークロードを最適に実行できるように慎重に選択されています。
MTIA ソフトウェア スタック
MTIA ソフトウェア (SW) スタックは、開発者に優れた開発効率と高性能エクスペリエンスを提供するように設計されています。 PyTorch と完全に統合されているため、ユーザーは使い慣れた開発エクスペリエンスを得ることができます。 MTIA で PyTorch を使用するのは、CPU または GPU で PyTorch を使用するのと同じくらい簡単です。また、活発な PyTorch 開発者エコシステムとツールのおかげで、MTIA SW スタックは、MTIA アクセラレータ カスタム アーキテクチャと ISA もサポートしながら、PyTorch FX IR を使用してモデルレベルの変換と最適化を実行し、LLVM IR を使用して低レベルの最適化を実行できるようになりました。
次の図は、MTIA ソフトウェア スタック フレームワークの図です:
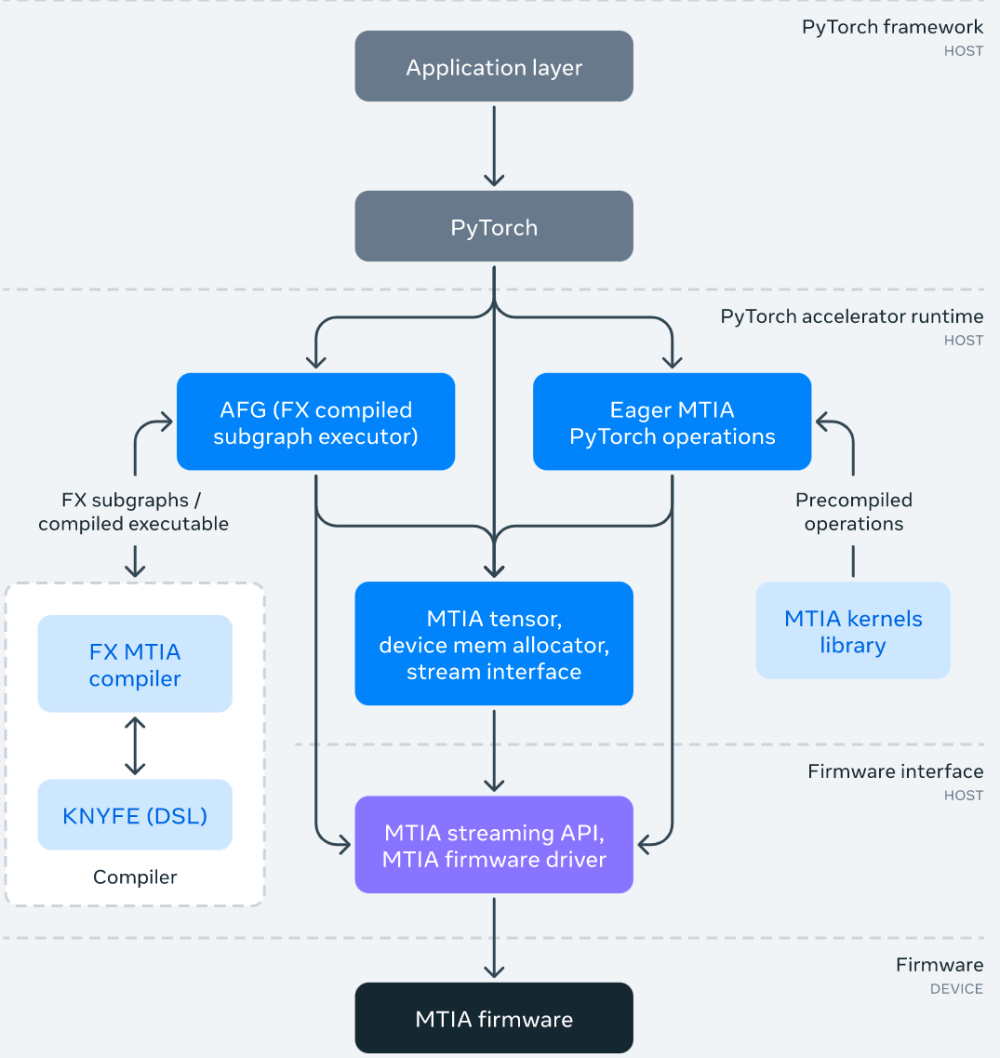
SW スタックの一部として、Meta は、完全に接続された組み込みパッケージ オペレーターなど、パフォーマンスが重要な ML カーネル用に手動で調整され、高度に最適化されたカーネル ライブラリも開発しました。 SW スタックの上位レベルには、コンパイルおよびコード生成中にこれらの高度に最適化されたカーネルをインスタンス化して使用するオプションがあります。
さらに、MTIA SW スタックは PyTorch 2.0 との統合により進化を続けています。PyTorch 2.0 はより高速で Python 的ですが、これまでと同様に動的です。これにより、TorchDynamoやTorchInductorなどの新機能が有効になります。 Meta はまた、MTIA アクセラレータをサポートし、内部表現と高度な最適化に MLIR を使用するように Triton DSL を拡張しています。
MTIA パフォーマンス
Meta は MTIA のパフォーマンスを他のアクセラレータと比較しました。結果は次のとおりです:
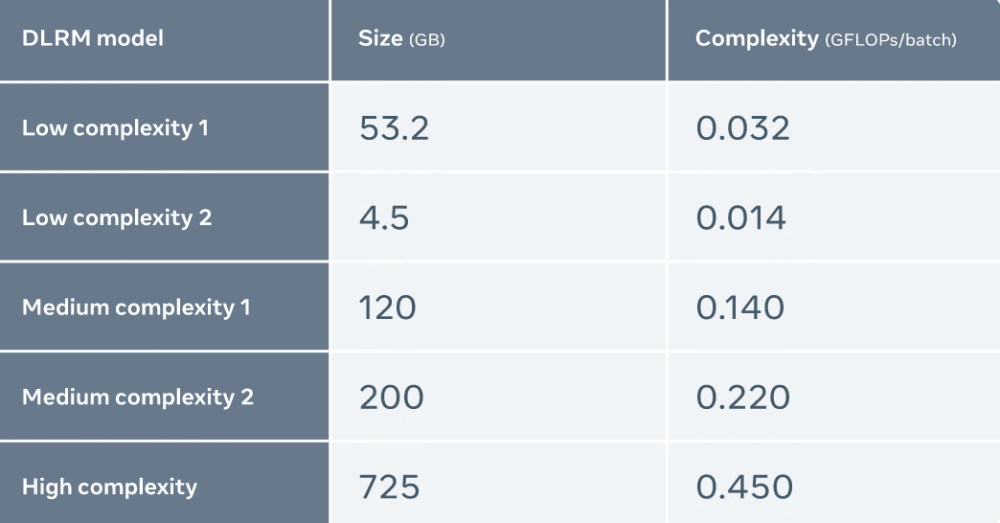
Meta は 5 つの異なる DLRM (複雑さの低いものから高いものまで) を使用して MTIA を評価します
さらに、Meta は MTIA を NNPI および GPU と比較しました。結果は次のとおりです。

評価の結果、MTIA は、低複雑度 (LC1 および LC2) および中複雑度 (MC1 および MC2) モデルの処理において、NNPI および GPU よりも効率的であることがわかりました。さらに、Meta は高複雑性 (HC) モデルの MTIA 用に最適化されていません。
参考リンク:
https://ai.facebook.com/blog/meta-training-inference-accelerator-AI-MTIA/
以上がGPU より効率的な 7nm プロセス、Meta が第 1 世代 AI 推論アクセラレータをリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7469
7469
 15
1376
52
77
11
19
29
15
1376
52
77
11
19
29

 カーソルAIでバイブコーディングを試してみましたが、驚くべきことです!
Mar 20, 2025 pm 03:34 PM
カーソルAIでバイブコーディングを試してみましたが、驚くべきことです!
Mar 20, 2025 pm 03:34 PM
バイブコーディングは、無限のコード行の代わりに自然言語を使用してアプリケーションを作成できるようにすることにより、ソフトウェア開発の世界を再構築しています。 Andrej Karpathyのような先見の明に触発されて、この革新的なアプローチは開発を許可します
 2025年2月のトップ5 Genai発売:GPT-4.5、Grok-3など!
Mar 22, 2025 am 10:58 AM
2025年2月のトップ5 Genai発売:GPT-4.5、Grok-3など!
Mar 22, 2025 am 10:58 AM
2025年2月は、生成AIにとってさらにゲームを変える月であり、最も期待されるモデルのアップグレードと画期的な新機能のいくつかをもたらしました。 Xai’s Grok 3とAnthropic's Claude 3.7 SonnetからOpenaiのGまで
 オブジェクト検出にYolo V12を使用する方法は?
Mar 22, 2025 am 11:07 AM
オブジェクト検出にYolo V12を使用する方法は?
Mar 22, 2025 am 11:07 AM
Yolo(あなたは一度だけ見ています)は、前のバージョンで各反復が改善され、主要なリアルタイムオブジェクト検出フレームワークでした。最新バージョンYolo V12は、精度を大幅に向上させる進歩を紹介します
 ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4は現在利用可能で広く使用されており、CHATGPT 3.5のような前任者と比較して、コンテキストを理解し、一貫した応答を生成することに大幅な改善を示しています。将来の開発には、よりパーソナライズされたインターが含まれる場合があります
 Google' s Gencast:Gencast Mini Demoを使用した天気予報
Mar 16, 2025 pm 01:46 PM
Google' s Gencast:Gencast Mini Demoを使用した天気予報
Mar 16, 2025 pm 01:46 PM
Google Deepmind's Gencast:天気予報のための革新的なAI 天気予報は、初歩的な観察から洗練されたAI駆動の予測に移行する劇的な変化を受けました。 Google DeepmindのGencast、グラウンドブレイク
 chatgptよりも優れたAIはどれですか?
Mar 18, 2025 pm 06:05 PM
chatgptよりも優れたAIはどれですか?
Mar 18, 2025 pm 06:05 PM
この記事では、Lamda、Llama、GrokのようなChatGptを超えるAIモデルについて説明し、正確性、理解、業界への影響における利点を強調しています(159文字)
 O1対GPT-4O:OpenAIの新しいモデルはGPT-4Oよりも優れていますか?
Mar 16, 2025 am 11:47 AM
O1対GPT-4O:OpenAIの新しいモデルはGPT-4Oよりも優れていますか?
Mar 16, 2025 am 11:47 AM
OpenaiのO1:12日間の贈り物は、これまでで最も強力なモデルから始まります 12月の到着は、世界の一部の地域で雪片が世界的に減速し、雪片がもたらされますが、Openaiは始まったばかりです。 サム・アルトマンと彼のチームは12日間のギフトを立ち上げています
 クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
この記事では、トップAIアートジェネレーターをレビューし、その機能、創造的なプロジェクトへの適合性、価値について説明します。 Midjourneyを専門家にとって最高の価値として強調し、高品質でカスタマイズ可能なアートにDall-E 2を推奨しています。
