

MySQL ロック メカニズムで行ロック、テーブル ロック、デッドロックを実装する方法

1. Mysql ロックとは何ですか?ロックにはどのような種類がありますか?
ロック定義:
同じリソースに同時にアクセスできるのは 1 つのスレッドのみです
データベース内 (従来のコンピューティング リソースを除く) (CPU など、I/O の競合に加えて) データは、多くのユーザーによって共有されるリソースでもあります。データへの同時アクセスの一貫性と有効性をどのように確保するかは、すべてのデータベースが解決しなければならない問題です。ロックの競合も、データベースへの同時アクセスのパフォーマンスに影響を与える重要な要素です。
最も一般的に使用されるオプティミスティック ロックは、バージョンを反映するデータのバージョン レコードであり、実際には識別子です。
例:update test set a=a-1 where id=100 and a> 0; 対応するバージョンは a フィールドであり、必ずしもversion というフィールドがあります。このフィールドがあり、この条件が満たされるとトリガーされます
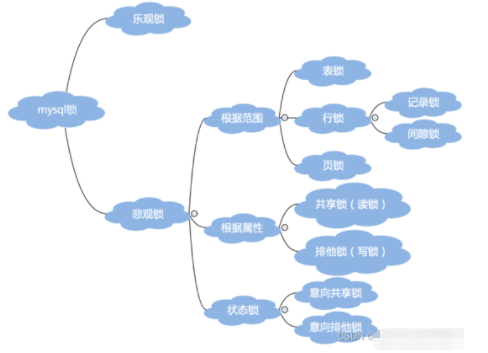
ロック分類:
データタイプによる操作の分類 (読み取りまたは書き込み)
読み取りロック (共有ロック): 同じデータに対して、複数の読み取り操作を相互に影響を与えることなく同時に実行できます。
書き込みロック (排他的ロック): 現在の書き込み操作が完了する前に、他の書き込みロックと読み取りロックがブロックされます。
データ操作の粒度から
テーブル レベルのロック: テーブル レベルのロックは、MySQL で最も粒度の高いロックです。つまり、現在の操作のテーブル全体がロックされます。ロック (MyISAM エンジンはデフォルトでテーブル レベルのロックを設定し、テーブル レベルのロックのみをサポートします)。 たとえば、100,000 テーブル内のデータを更新すると、この更新によってトランザクションがコミットされる前に他のトランザクションが除外され、粒度は非常に大きくなります。
行レベルのロック: 行レベルのロックは、Mysql で最も粒度の細かいロックです。つまり、現在操作されている行のみがロックされます (インデックスに基づいているため、特定のロックがロックされると、 locked 操作でインデックスが使用されない場合、ロックはテーブル ロックに縮退します。)
ページ レベルのロック: ページ レベルのロックは、行レベルのロックと行レベルのロックの間のロック粒度を持つ MySQL のロックです。テーブル レベルのロック。ワンタイム ロックです。隣接するレコードのグループ
#同時実行性の観点からの分散 -- 実際、楽観的ロックと悲観的ロックは単なるアイデアです悲観的ロック: 外部 (このシステムを含む) によってブロックされているデータの場合。他の現在のトランザクションや外部システムからのトランザクションの変更に対して保守的 (悲観的) な態度を取るため、データをロック状態に保ちます。データ処理プロセス全体にわたって。
オプティミスティック ロック: オプティミスティック ロックは、データが通常競合を引き起こさないことを前提としているため、データが更新のために送信されると、データの競合が正式に検出されます。競合が見つかった場合は、エラー メッセージが返されます。再試行してください。ビジネス
その他のロック:ギャップ ロック: id>100 などの条件付きクエリでは、InnoDB は条件を満たす既存のデータ レコードのインデックスを提供します。 項目のロック; キー値が条件範囲内にあるが存在しないレコードの場合、それを「ギャップ」と呼びます。ギャップの目的は、ファントム読み取りを防ぐことです
インテンション ロック: インテンション ロックはインテンション共有ロックに分割されます( IS) およびインテンション排他ロック (IX)、インテンション ロックの目的は、トランザクションがテーブルの行をロックしている、またはロックする予定であることを示すことです
#2. 行ロックとテーブル ロックの違い
で最も大きなロック粒度を持つロックであり、現在の操作のテーブル全体をロックすることを意味します。実装は簡単です。最も一般的に使用される MYISAM と INNODB は、テーブル レベルのロックをサポートします。 特徴: 低いオーバーヘッド、高速なロック
、デッドロックなし、ロックの粒度が大きく、ロック競合の可能性が最も高く、同時実行性が最も低い。
で最も粒度の細かいロックです。つまり、現在の操作の行のみがロックされます。行レベルのロックにより、データベース操作における競合を大幅に減らすことができます。ロックの粒度は最も小さくなりますが、ロックのオーバーヘッドも最大になります。 特徴: 高いオーバーヘッド、遅いロック、デッドロックが発生する可能性がある、ロックの粒度が最も小さく、ロック競合の確率が最も低く、同時実行性が最も高い使用法: InnoDB 行ロックはインデックスをロックすることです。これを達成するために、InnoDB は
インデックス条件を通じてデータを取得する場合にのみ行レベルのロックを使用します
それ以外の場合、InnoDB はテーブル ロックを使用します次の update ステートメントでは、 b はインデックス列ではなく一般フィールドの場合、この時点で行レベルのロックがテーブルレベルのロックに変更されます。
update from test set a=100 where b='100';
次に、innnodb が行ロックをどのように使用するかを実際の例で見てみましょう。
現在のテーブルのデータ:
 最初に 2 つのセッション ウィンドウを開き、次に mysql トランザクション レベルを非コミット レベルに設定します:
最初に 2 つのセッション ウィンドウを開き、次に mysql トランザクション レベルを非コミット レベルに設定します:
セッション 1 ウィンドウ:
 セッション 2 ウィンドウ:
セッション 2 ウィンドウ:
其中会话2的update一直都在Running中,一直到超时结束,或者会话1提交事务后才会Running结束。
可以通过show VARIABLES like "%innodb_lock_wait_timeout%" 查询当前mysql设置的锁超时时间,默认是50秒。
可以通过set innodb_lock_wait_timeout = 60; 设置锁的超时时间。
只有在第一个会话提交后,第二个会话的更新语句才能成功执行。这代表了innodb用了锁。
那怎么确定是用了行锁呢?
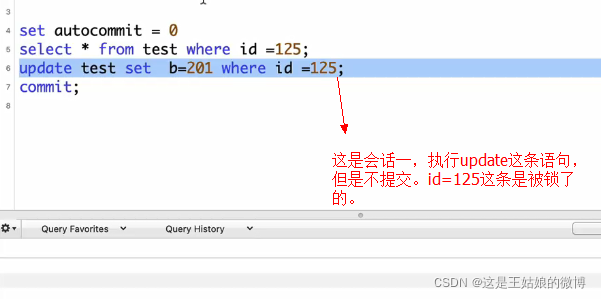


总结:会话一更新id=125的时候,给这条数据add lock了,那么在会话2中再次更新id=125的时候,这条数据是locked中的。这个lock加的是id=125这条记录。证明默认情况下id=125这条记录会加上行锁,除了这条记录之外的其它记录都可以成功地操作。
三、InnoDB死锁概念和死锁案例
发生死锁是因为多个事务相互持有和请求锁,并形成了一个循环依赖关系。多个事务同时锁定同一个资源时,也会产生死锁。在一个事务系统中,死锁是确切存在并且是不能完全避免的。
自动检测事务死锁并回滚一个事务,同时返回错误信息的功能由InnoDB自动实现。它根据某种机制来选择那个最简单(代价最小)的事务来进行回滚
死锁场景一之select for update:
产生场景:两个transaction都有两个select for update,transaction a先锁记录1,再锁记录2;而transaction b先锁记录2,再锁记录1
写锁:for update,读锁:for my share mode show engine innodb status
验证下死锁的场景:

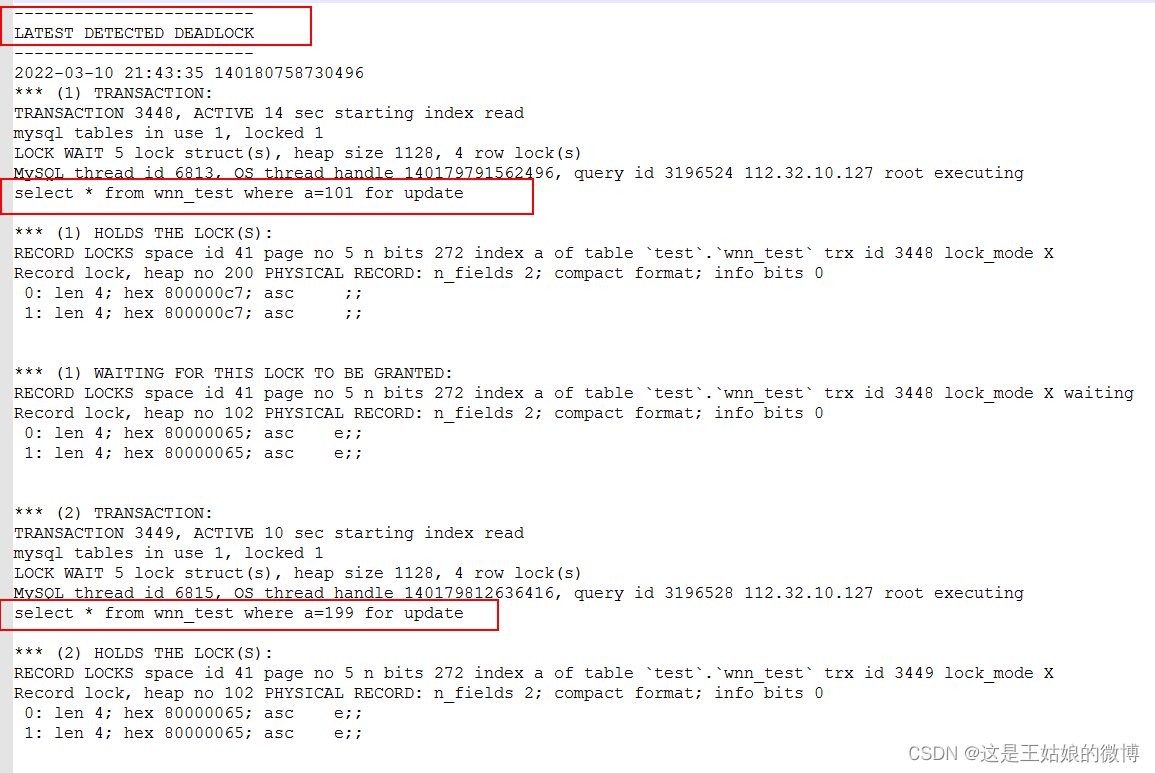
第一步更新会话一:
start TRANSACTION; select * from wnn_test where a=199 for update;
第二步更新会话二:
start TRANSACTION; select * from wnn_test where a=101 for update;
第三步更新会话一:
select * from wnn_test where a=101 for update;
第四步更新会话二;
select * from wnn_test where a=199 for update;
在更新到第三步和第四步的时候,已经发生了死锁。
来看下执行的日志:
show engine innodb status;最后一个锁的时间,锁的表,引起锁的语句。其中session1被锁 14秒(ACTIVE 14),session 2被锁了10秒(Active 10)
死锁场景二之两个update
产生场景:两个transaction都有两个update,transaction a先更新记录1,再更新记录2;而transaction b先更新记录2,再更新记录1
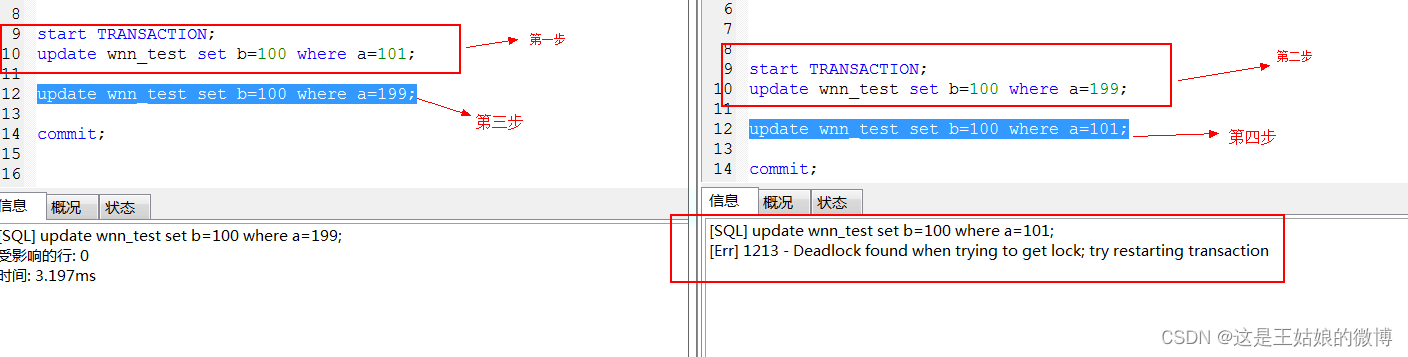
产生日志:

注意:仔细查看上面2个例子可以发现一个现象,当2条资源锁住后,再执行第三个会执行成功,但是第四个会提示死锁。在mysql5.7中,执行第三个的时候就会一直在Running状态了,本博文使用的是mysql8.0 ,其中 有这个参数 innodb_deadlock_detect 可以用于控制 InnoDB 是否执行死锁检测,当启用了死锁检测时(默认设置),InnoDB 自动执行事务的死锁检测,并且回滚一个或多个事务以解决死锁。InnoDB 尝试回滚更小的事务,事务的大小由它所插入、更新或者删除的数据行数决定。

那么这个innodb_deadlock_detect参数,到底要不要启用呢?
对于高并发的系统,当大量线程等待同一个锁时,死锁检测可能会导致性能的下降。此时,如果禁用死锁检测,而改为依靠参数 innodb_lock_wait_timeout 执行发生死锁时的事务回滚可能会更加高效。
通常来说,应该启用死锁检测,并且在应用程序中尽量避免产生死锁,同时对死锁进行相应的处理,例如重新开始事务。デッドロック検出がシステムのパフォーマンスに影響し、デッドロック検出を無効にしても悪影響がないことが確認された場合にのみ、innodb_deadlock_detect オプションをオフにしてみてください。さらに、InnoDB デッドロック検出が無効になっている場合は、実際のニーズに合わせてパラメータ innodb_lock_wait_timeout の値を 調整する必要があります。
4. プログラム開発中のデッドロックを回避する方法
ロックの本質は、リソースが互いに競合し、互いに待機することです。 more) Sessions are locked. The order is inconsistent
効果的な回避方法:
プログラム内で複数のテーブルを操作する場合、次のようにしてください。同じ順序でアクセスします (待機ループの形成を避ける)
単一テーブル データをバッチで操作する場合は、最初にデータを並べ替えます (待機ループの形成を避けるため) スレッド ID: 1 、10、20の順に追加されます ロックBスレッドid:20,10,1 これは簡単にロックできます。
可能であれば、大規模なトランザクションを小規模なトランザクションに変更するか、トランザクションを開かないでください。 select for update==>insert==>update = 重複キーの更新に挿入します
テーブル ロックを回避するには、可能な限りインデックスを使用してデータにアクセスし、where 条件を使用しない操作を避けることをお勧めします。インデックスを使用すると、テーブル ロックを発生させずに行ロックを記録できるためです。
範囲クエリの代わりに等しい値クエリを使用してデータをクエリし、レコードをヒットし、同時実行性に対するギャップ ロックの影響を回避します。 1、10、20 (1,10,20) の where ID と同等範囲クエリ id>1 および id
同じテーブルを同時に読み書きする複数のスクリプトを実行することは避けてください。大量のデータをロックして操作するステートメントには特に注意してください。 ; 多くの場合、同じ時点で実行されることを避けるために、いくつかのタイミング スクリプトが使用されます。
以上がMySQL ロック メカニズムで行ロック、テーブル ロック、デッドロックを実装する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7700
7700
 15
1640
14
1393
52
1287
25
1230
29
15
1640
14
1393
52
1287
25
1230
29

 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheはデータベースに接続するには、次の手順が必要です。データベースドライバーをインストールします。 web.xmlファイルを構成して、接続プールを作成します。 JDBCデータソースを作成し、接続設定を指定します。 JDBC APIを使用して、接続の取得、ステートメントの作成、バインディングパラメーター、クエリまたは更新の実行、結果の処理など、Javaコードのデータベースにアクセスします。
 DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerでMySQLを起動するプロセスは、次の手順で構成されています。MySQLイメージをプルしてコンテナを作成および起動し、ルートユーザーパスワードを設定し、ポート検証接続をマップしてデータベースを作成し、ユーザーはすべての権限をデータベースに付与します。
 MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
WebアプリケーションにおけるMySQLの主な役割は、データを保存および管理することです。 1.MYSQLは、ユーザー情報、製品カタログ、トランザクションレコード、その他のデータを効率的に処理します。 2。SQLクエリを介して、開発者はデータベースから情報を抽出して動的なコンテンツを生成できます。 3.MYSQLは、クライアントサーバーモデルに基づいて機能し、許容可能なクエリ速度を確保します。
 MySQLをCentos7にインストールする方法
Apr 14, 2025 pm 08:30 PM
MySQLをCentos7にインストールする方法
Apr 14, 2025 pm 08:30 PM
MySQLをエレガントにインストールするための鍵は、公式のMySQLリポジトリを追加することです。特定の手順は次のとおりです。MYSQLの公式GPGキーをダウンロードして、フィッシング攻撃を防ぎます。 mysqlリポジトリファイルを追加:rpm -uvh https://dev.mysql.com/get/mysql80-community-rease-el7-3.noarch.rpm update yumリポジトリキャッシュ:yumアップデートインストールmysql:yumインストールmysql-server startup mysql sportin
