

一般に、データベースのストレージ エンジンは B ツリーまたは B ツリーを使用してインデックスを保存します。まず、図に示すように、B ツリーを見てください。
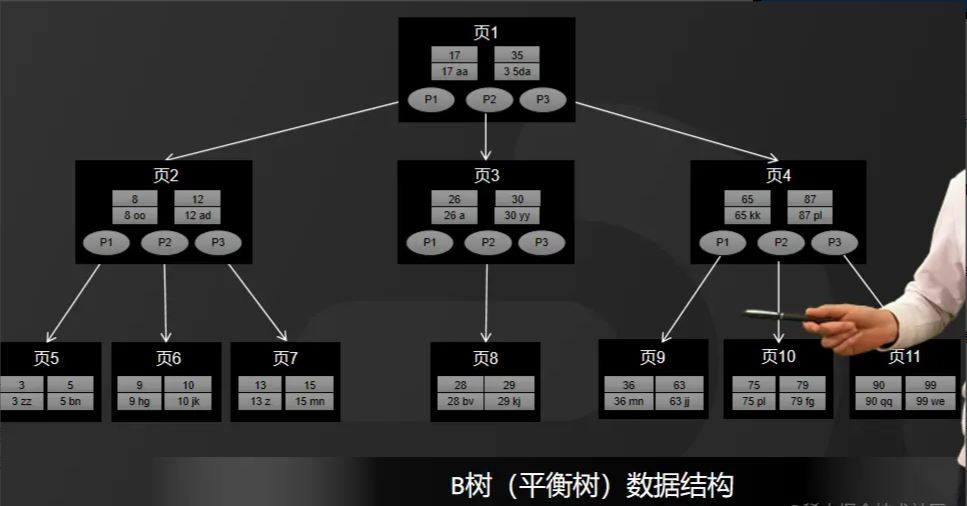
#B ツリーは多方向バランスのとれたツリーです。このストレージ構造を使用して大量のデータを保存すると、全体の高さはそれよりもはるかに低くなります。二分木の。
データベースの場合、すべてのデータはディスクに保存され、特にランダムなディスク I/O の場合、ディスク I/O の効率は比較的低くなります。
したがって、高さによってディスク I/O の数が決まります。ディスク I/O の数が少ないほど、パフォーマンスの向上は大きくなります。このため、次のように B ツリーがインデックス ストレージ構造として使用されます。図の中にあります。
MySQL の InnoDB ストレージ エンジンは、改良された B ツリー構造、つまり B ツリーをインデックスおよびデータ ストレージ構造として使用します。
B ツリー構造と比較すると、図に示すように、B ツリーは 2 つの点で最適化されています。
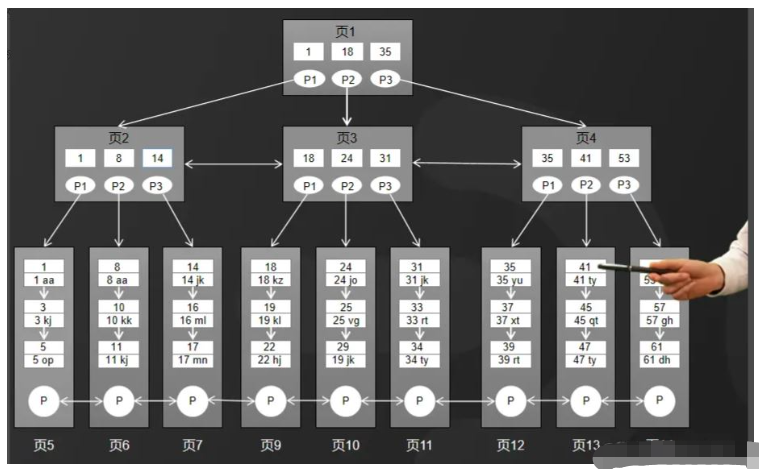
#1. B ツリー内のすべてのデータはリーフ ノードに格納され、非リーフ ノードにはインデックスのみが格納されます。
2. リーフ ノードのデータは、二重リンク リストを使用して関連付けられます。
MySQL インデックス構造が B-tree を使用しているのは、次の 4 つの理由によると考えられます。ディスク I/O 効率の観点から: B ツリーの非リーフ ノードはデータを格納しないため、ツリーの各層により多くのインデックスを格納できます。つまり、B ツリーの層の高さは B ツリーの層の高さと同じになります。ツリー: ツリーにはより多くのデータが保存され、間接的にディスク I/O の数が減少します。
2. 範囲クエリの効率性の観点から: MySQL では、範囲クエリは比較的一般的な操作であり、B ツリーのリーフ ノードに格納されているすべてのデータは二重リンク リストを使用して関連付けられているため、B-ツリー クエリを実行する場合、走査のために 2 つのノードをチェックするだけで済みますが、B ツリーはすべてのノードを取得する必要があるため、範囲クエリでは B ツリーの方が効率的です。 
以上がMySQL インデックス構造で B+ ツリーを使用する場合の問題を理解する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



