

ChatGPT は誰でも理解できる 第 1 章: ChatGPT と自然言語処理


ChatGPT (Chat Generative Pre-training Transformer) は、人工知能の一分野である自然言語処理 (NLP) の分野に属する AI モデルです。いわゆる自然言語とは、人間が日常生活で接し、使用している英語、中国語、ドイツ語などを指します。自然言語処理とは、コンピューターが自然言語を理解して正しく操作し、人間が指定したタスクを完了できるようにすることを指します。 NLP の一般的なタスクには、テキストからのキーワード抽出、テキスト分類、機械翻訳などが含まれます。
NLP にはもう 1 つの非常に難しいタスクがあります。それは、一般にチャットボットとも呼ばれる対話システムです。これはまさに ChatGPT が実現するものです。
ChatGPT とチューリング テスト
1950 年代にコンピューターが登場して以来、人間が自然言語を理解して処理する際にコンピューターがどのように役立つかを研究し始めました。これは、 NLP の分野で、最も有名なのは間違いなくチューリング テストです。
1950 年、コンピューターの父であるアラン チューリングは、機械が人間のように考えることができるかどうかを確認するテストを導入しました。このテストはチューリング テストと呼ばれました。具体的なテスト方法は現行のChatGPT手法と全く同じで、人間とテスト対象のモデルが対話するコンピュータ対話システムを構築するというもので、相手が機械モデルなのか区別できない場合には、別の人、それはモデルが合格したことを意味します チューリングテストに合格した後、コンピューターはインテリジェントになります。長い間、チューリング テストは学会ではとらえどころのない頂点であると考えられてきました。このため、NLP は人工知能の至宝としても知られています。 ChatGPT が実行できる作業は、チャット ロボットの範囲をはるかに超えており、ユーザーの指示に従って記事を作成したり、技術的な質問に答えたり、数学の問題を実行したり、外国語の翻訳を実行したり、単語ゲームをしたりすることができます。つまり、ある意味では、ChatGPT が最高の宝石を手に入れたのです。
ChatGPT のモデリング フォーム
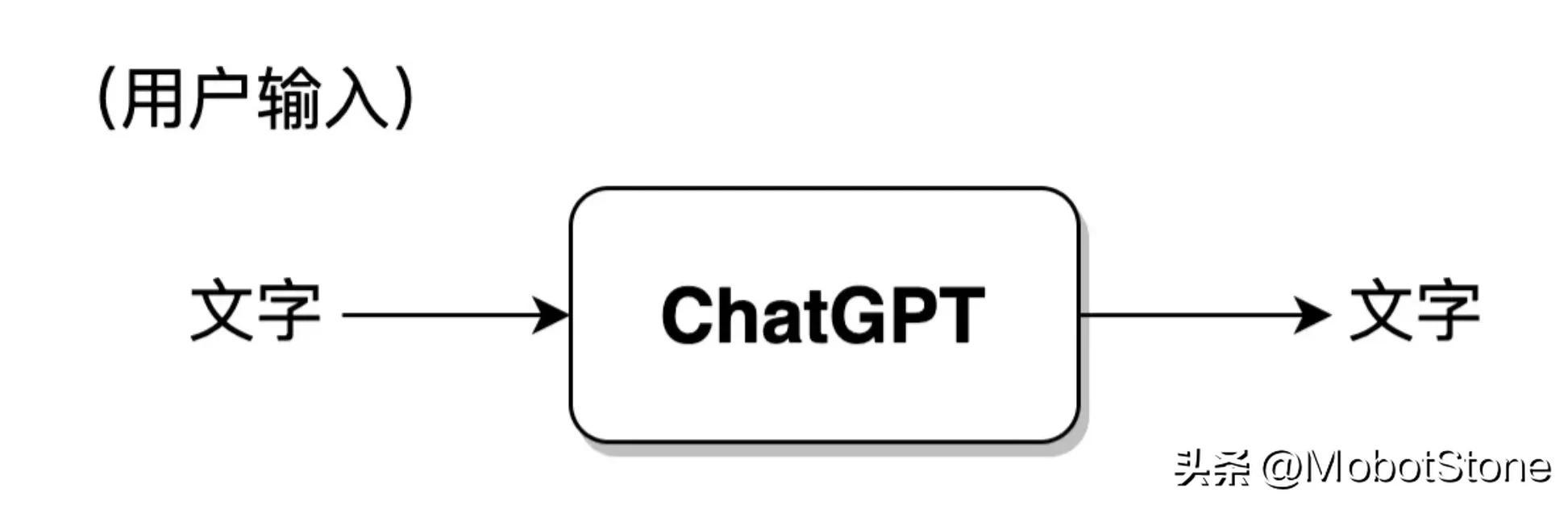
ChatGPT の動作フォームは非常にシンプルで、ユーザーが ChatGPT に質問すると、モデルがそれに答えます。
 このうち、ユーザーの入力とモデルの出力は両方とも
このうち、ユーザーの入力とモデルの出力は両方とも
の形式です。 1 つのユーザー入力とモデルからの 1 つの対応する出力は、会話と呼ばれます。 ChatGPT モデルは次のプロセスに抽象化できます。
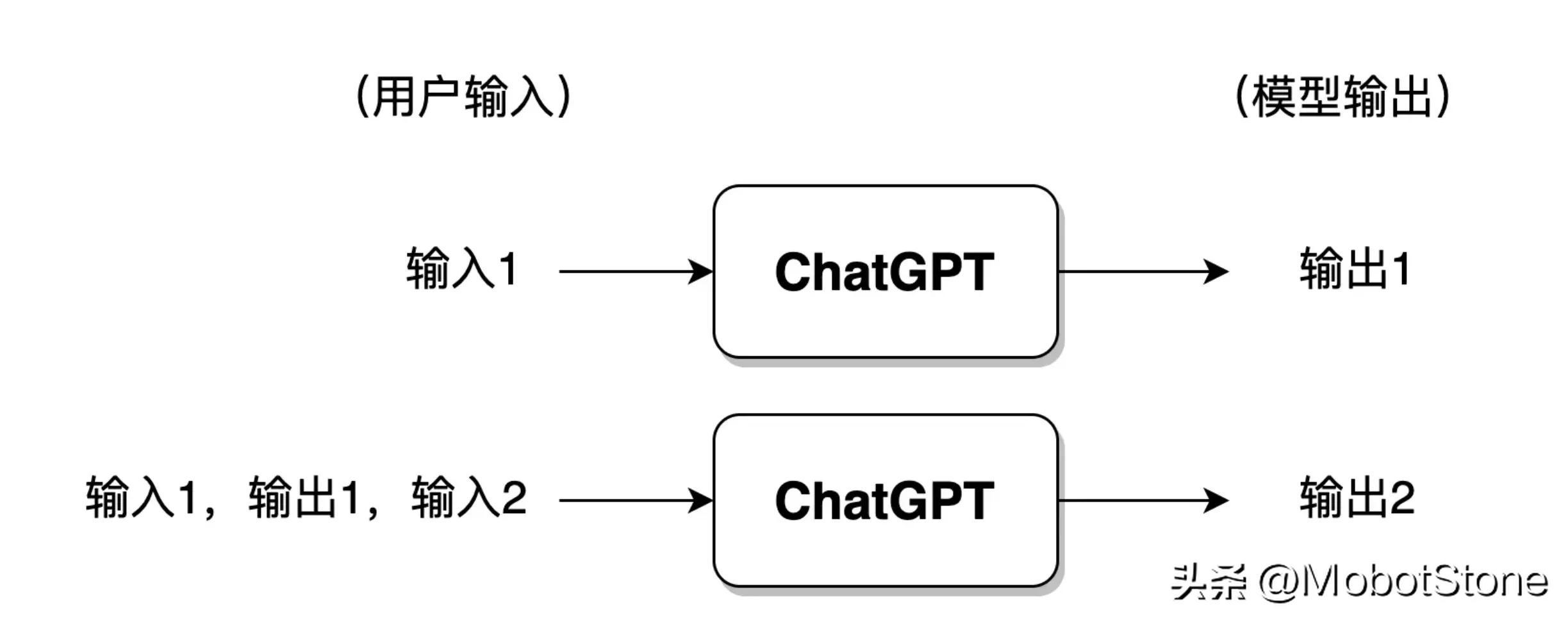
 さらに、ChatGPT はユーザーからの継続的な質問、つまり複数ラウンドの対話に答えることもできます。関連している。その具体的な形式も非常にシンプルで、ユーザーが2回目に入力すると、システムはデフォルトで1回目の入力情報と出力情報をつなぎ合わせ、ChatGPTが最後の会話の情報を参照できるようにします。
さらに、ChatGPT はユーザーからの継続的な質問、つまり複数ラウンドの対話に答えることもできます。関連している。その具体的な形式も非常にシンプルで、ユーザーが2回目に入力すると、システムはデフォルトで1回目の入力情報と出力情報をつなぎ合わせ、ChatGPTが最後の会話の情報を参照できるようにします。
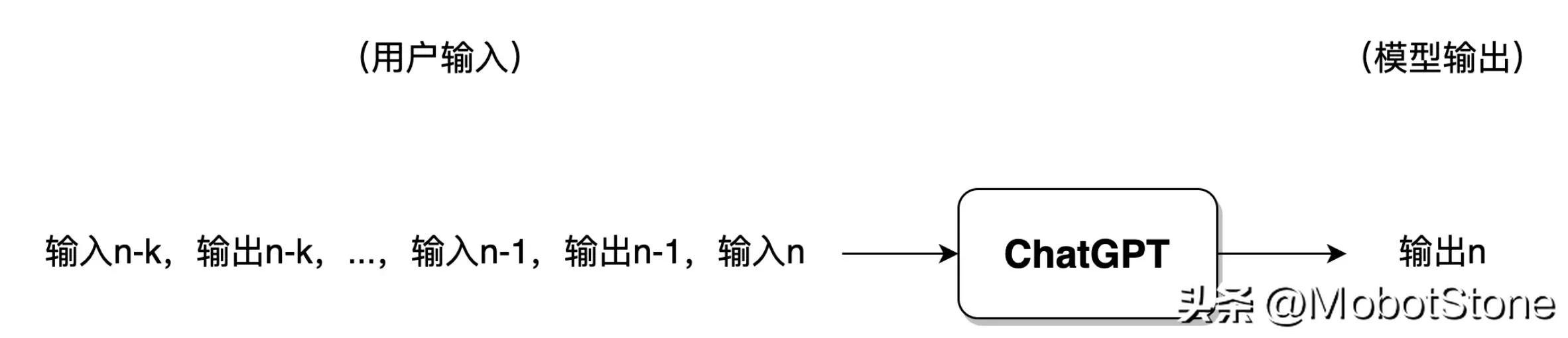
 ユーザーが ChatGPT との会話が多すぎる場合、一般的に、モデルは最新の会話の情報のみを保持し、以前の会話情報は忘れられます。 。
ユーザーが ChatGPT との会話が多すぎる場合、一般的に、モデルは最新の会話の情報のみを保持し、以前の会話情報は忘れられます。 。
 ChatGPT ユーザーの質問入力を受け取った後、出力テキストは直接一度に生成されるのではなく、単語ごとに生成されます。 ,
ChatGPT ユーザーの質問入力を受け取った後、出力テキストは直接一度に生成されるのではなく、単語ごとに生成されます。 ,
。以下に示すように。
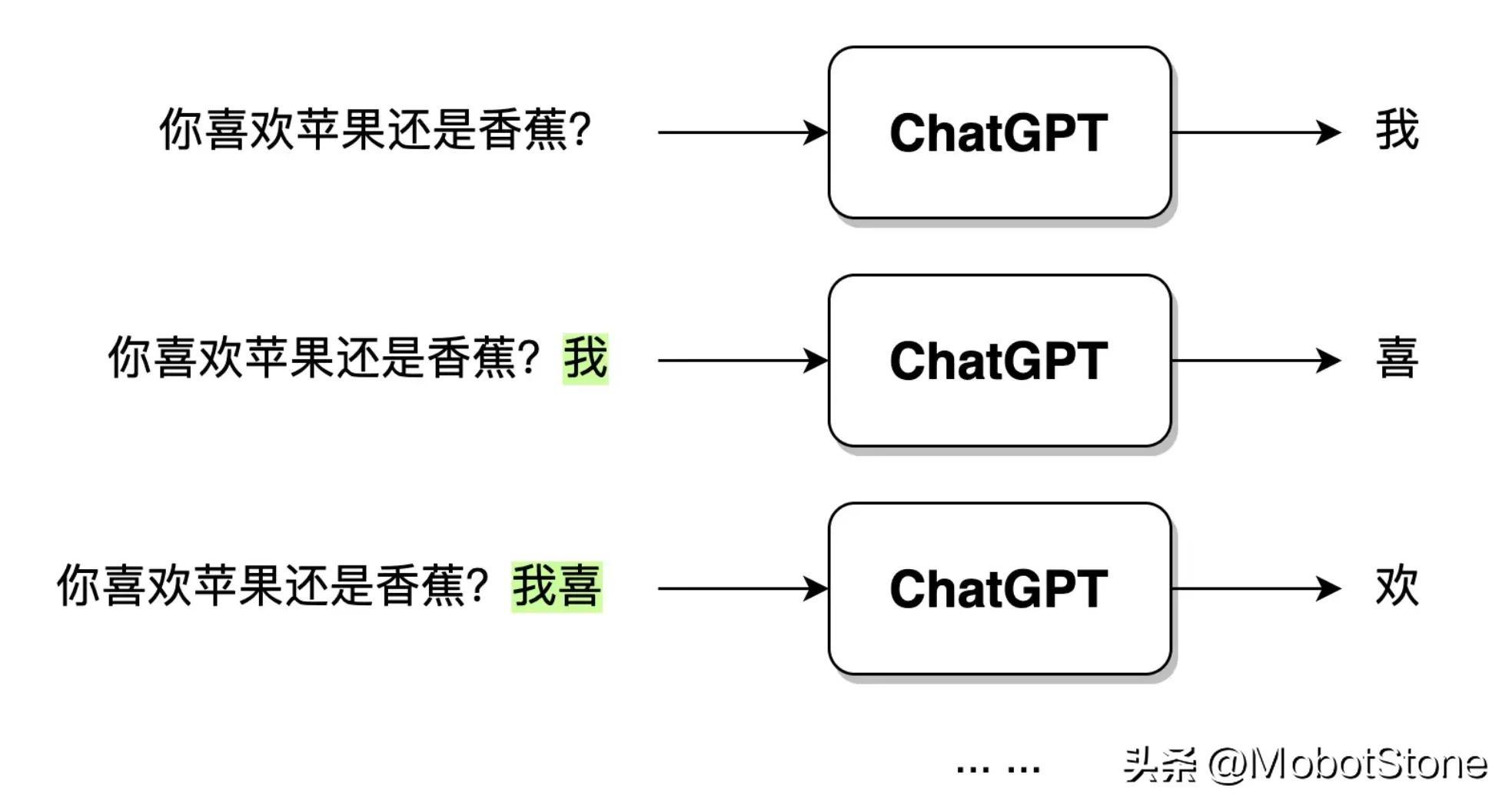 ユーザーが「リンゴとバナナは好きですか?」という質問を入力すると、ChatGPT がデータを受信した後、最初に単語「I」を生成し、次に単語「I」を生成します。モデルはユーザーの質問と生成された単語「I」を合成し、次の単語「hi」を生成し続けます。 「私はリンゴが好きです」という完全な文が生成されるまで続きます。
ユーザーが「リンゴとバナナは好きですか?」という質問を入力すると、ChatGPT がデータを受信した後、最初に単語「I」を生成し、次に単語「I」を生成します。モデルはユーザーの質問と生成された単語「I」を合成し、次の単語「hi」を生成し続けます。 「私はリンゴが好きです」という完全な文が生成されるまで続きます。
ChatGPT と NLP の開発の歴史
ChatGPT のモデリング形式については先ほど紹介しましたが、もし ChatGPT モデルの実装を求められたら、どのようなアイデアや方法があるでしょうか?実際には、rules に基づく NLP と statistics に基づく NLP という、大きく 2 つの戦略があります。 ChatGPT の開始以来、NLP 分野は 強化学習 の時代、つまり強化学習に基づく NLP の時代に入りました。
ルールベースの NLP
ルールベースの NLP は、自然言語を処理するために手動で作成されたルールの使用を指します。これらのルールは通常、文法、意味論、語用論の知識に基づいており、自然言語の解析と生成に使用できます。たとえば、次のルールに基づいて対話システムを設計できます。
ルール 1: モデルがユーザーの質問を受け取ると、質問内の単語「?」を削除し、「?」に置き換えます。 " "."
ルール 2: 「あなた」を「私」に、「私」を「あなた」に置き換えます
これから、これらのルールに従って対話を作成できますモデルでは、ダイアログ モードがオンになっています。
ユーザー: こんにちは。モデル:こんにちは。ユーザー: ChatGPT ですか? モデル: はい、ChatGPT です。ユーザー: ナゲッツ コミュニティは好きですか?モデル: 私はナゲッツのコミュニティが大好きです。ユーザー: jionlp ツールキットを使用したことがありますか? モデル: jionlp ツールキットを使用しました。
上記は、ルールベースの対話システムの非常に表面的な例です。読者はそこに存在する問題点を容易に発見できると思います。ユーザーの問題が複雑すぎる場合はどうすればよいでしょうか?質問に疑問符がない場合はどうなりますか?上記の特殊な状況をカバーするために、さまざまなルールを常に作成する必要があります。これは、ルールに基づくいくつかの明らかな欠点があることを示しています:
- 自然言語では、要件を完全にカバーできるルールはないため、複雑な自然言語タスクを扱う場合には効果的ではありません;
- ルールは無限にあり、人間の力に頼ると膨大な作業になります;
- 本質的に、自然言語処理のタスクはコンピューターに引き継がれるのではなく、依然として人間によって支配されています。 。
これは、初期段階で NLP が開発された方法です。つまり、ルールに基づいたモデル システムを構築しました。初期には、それは一般に象徴主義とも呼ばれていました。
統計ベースの NLP
統計ベースの NLP は、機械学習アルゴリズムを使用して、多数のコーパスから自然言語の規則的な特徴を学習します。初期の頃はコネクショニズムとも呼ばれていました。この方法ではルールを手動で記述する必要がなく、ルールは主に言語の統計的特性を学習することによってモデルに暗黙的に組み込まれます。言い換えれば、ルールベースの方法では、ルールは明示的で手動で記述されますが、統計ベースの方法では、ルールは目に見えず、モデルパラメータに暗黙的に含まれ、データに基づいてモデルによってトレーニングされます。
これらのモデルは近年急速に発展しており、ChatGPT もその 1 つです。また、形状や構造が異なるさまざまなモデルがありますが、基本的な原理は同じです。
トレーニングモデル=> トレーニング済みモデルを使って作業する
ChatGPTでは主に事前トレーニング(Pre-training)が行われます。 ) テクノロジーを使用して、統計ベースの NLP モデル学習を完了しました。 NLP 分野における事前トレーニングは、ELMO モデル (Embedding from Language Models) によって最初に導入され、この手法は ChatGPT などのさまざまなディープ ニューラル ネットワーク モデルで広く採用されました。
その焦点は、大規模なオリジナルのコーパスに基づいた言語モデルを学習することであり、このモデルは特定のタスクを解決する方法を直接学習するのではなく、文法、形態論、語用論から常識、知識までを学習します。などの情報が言語モデルに統合されます。直観的には、実際的な問題を解決するために知識を適用するというよりは、知識の記憶に似ています。
事前トレーニングには多くの利点があり、ほぼすべての NLP モデルのトレーニングに必要なステップとなっています。これについては後続の章で詳しく説明します。
統計ベースの手法はルールベースの手法よりもはるかに人気がありますが、その最大の欠点はブラックボックスの不確実性、つまりルールが目に見えずパラメータに暗黙的に含まれていることです。たとえば、ChatGPT も曖昧で理解できない結果を返しますが、モデルがなぜそのような答えを出したのかを結果から判断することはできません。

強化学習に基づく NLP
ChatGPT モデルは統計に基づいていますが、人間のフィードバックを使用した強化学習という新しい手法も使用しています (人間のフィードバックを使用した強化学習) 、RLHF)は優れた成果を上げ、NLPの発展を新たな段階に導きました。
数年前、Alpha GO は柯潔を破りました。これは、強化学習が適切な条件下であれば、人間を完全に打ち負かし、完璧の限界に近づくことができることをほぼ証明することができます。現在はまだ囲碁の分野に限れば弱い人工知能の時代ですが、Alpha GOは強化学習を核とした強い人工知能です。
いわゆる強化学習は、エージェント (NLP におけるエージェントは主にディープ ニューラル ネットワーク モデル、つまり ChatGPT モデルを指します) に対話を通じて意思決定を行う方法を学習させることを目的とした機械学習手法です。環境との調和、最適な意思決定。
この方法は、犬 (エージェント) に笛 (環境) を聞いて食べる (学習目標) ように訓練するようなものです。
子犬は飼い主が笛を吹くのを聞くとご褒美として食べ物を与えられますが、飼い主が笛を吹かなければ子犬は餓死するしかありません。子犬は食べることと飢えることを繰り返すことで、対応する条件反射を確立することができ、実際に強化学習が完了します。
NLP の分野では、環境はさらに複雑です。 NLP モデルの環境は、実際の人間の言語環境ではなく、人工的に構築された言語環境モデルです。したがって、ここでは人工フィードバックによる強化学習に重点を置きます。

統計ベースの手法では、モデルが最も高い自由度でトレーニング データ セットに適合することができますが、強化学習ではモデルに大きな自由度が与えられ、独自に学習し、確立されたデータセットの制限を突破します。 ChatGPT モデルは統計学習手法と強化学習手法を融合したもので、そのモデル トレーニング プロセスは次の図に示されています:
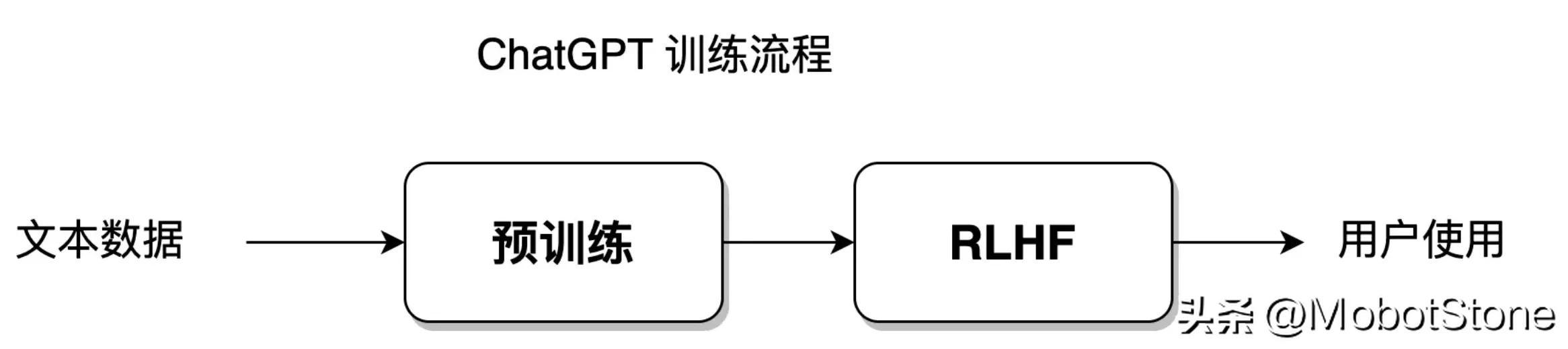
トレーニング プロセスのこの部分が開始されます。セクション 8 ~ 11 で話します。
NLP テクノロジーの開発動向
実際、ルールに基づく、統計に基づく、強化学習に基づく 3 つの手法は、自然言語を処理する単なる手段ではなく、手段です。自然言語処理の考え方。特定の問題を解決するアルゴリズム モデルは、多くの場合、これら 3 つのソリューションの融合の産物です。
コンピューターを子供に例えると、自然言語処理は人間が子供の成長を教育するようなものです。
ルールベースのアプローチは、親が子供を 100% コントロールし、毎日数時間の勉強時間を規定して子供に教えるなど、自分の指示とルールに従って行動することを要求するようなものです。すべての質問。このプロセス全体を通じて、保護者が主導権を握り、重点を置いて実践的な指導に重点が置かれます。 NLP の場合、プロセス全体の主導権と焦点は、言語ルールを作成するプログラマーと研究者にあります。
統計に基づいた方法は、親が子供たちに学習方法だけを教え、特定の問題を個別に教えるのと似ており、準指導に重点が置かれています。 NLP の場合、学習の焦点はニューラル ネットワーク モデルにありますが、主導権は依然としてアルゴリズム エンジニアによって制御されます。
集中学習という手法では、親は子どもに教育目標だけを設定するようなもので、たとえばテストで90点を取ることを要求しますが、子どもの成績などは気にしていません。子どもたちは非常に高い自由度と自発性を持っています。親は最終的な結果に対して賞罰を与えるだけで、教育プロセス全体には参加しません。 NLP の場合、プロセス全体の焦点と主導権はモデル自体にあります。
NLP の開発は徐々に統計に基づく手法に近づき、最終的には強化学習に基づく手法が完全な勝利を収めました。勝利の兆しは ChatGPT が出てきて、ルールベースの方法は徐々に衰退し、補助的な処理方法になりました。 ChatGPT モデルの開発は、当初からモデルに自ら学習させるという方向で一貫して進められてきました。
ChatGPT のニューラル ネットワーク構造 Transformer
前回の紹介では、読者の理解を容易にするために、ChatGPT モデルの具体的な内部構造については言及しませんでした。
ChatGPT は大規模なニューラル ネットワークであり、その内部構造は複数の Transformer 層で構成されています。Transformer はニューラル ネットワークの構造です。 2018 年以降、NLP 分野で一般的な標準モデル構造となり、ほぼすべての NLP モデルに Transformer が含まれています。
ChatGPT が家だとすると、Transformer は ChatGPT を構築するレンガです。
Transformer の中核はセルフ アテンション メカニズム (Self-Attention) で、入力テキスト シーケンスを処理する際に、モデルが現在の位置文字に関連する他の位置文字に自動的に注意を払うのに役立ちます。セルフ アテンション メカニズムは、入力シーケンス内の各位置をベクトルとして表すことができ、これらのベクトルを同時に計算に参加させることができるため、効率的な並列コンピューティングが実現します。例を挙げます:
機械翻訳で、「私は良い学生です」という英語の文を中国語に翻訳する場合、従来の機械翻訳モデルはそれを「私は良い学生です」学生と翻訳する可能性があります。 、ただし、この翻訳は十分に正確ではない可能性があります。英語の冠詞「a」は中国語に翻訳する場合、文脈に応じて判断する必要があります。
Transformer モデルを翻訳に使用すると、「私は良い学生です」など、より正確な翻訳結果を得ることができます。
これは、Transformer が英語の文章内の長距離にわたる単語間の関係をより適切に捕捉し、テキスト コンテキストにおける 長い依存関係を解決できるためです。セルフアテンションの仕組みについては 5-6 節で、Transformer の詳細な構造については 6-7 節で紹介します。
概要- NLP 分野の発展は、手動でルールを記述してコンピューター プログラムを論理的に制御することから、言語環境に適応するネットワーク モデルに完全に任せることに徐々に移行してきました。
- ChatGPT は現在、チューリング テストの合格に最も近い NLP モデルであり、将来的には GPT4 と GPT5 がさらに近づくでしょう。
- ChatGPT のワークフローは生成対話システムです。
- ChatGPT のトレーニング プロセスには、言語モデルの事前トレーニングと手動フィードバックによる RLHF 強化学習が含まれます。
- ChatGPT のモデル構造は、セルフアテンション機構を核とした Transformer を採用しています。
以上がChatGPT は誰でも理解できる 第 1 章: ChatGPT と自然言語処理の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7518
7518
 15
1378
52
80
11
21
67
15
1378
52
80
11
21
67

 YOLOは不滅です! YOLOv9 がリリースされました: パフォーマンスとスピード SOTA~
Feb 26, 2024 am 11:31 AM
YOLOは不滅です! YOLOv9 がリリースされました: パフォーマンスとスピード SOTA~
Feb 26, 2024 am 11:31 AM
現在の深層学習手法は、モデルの予測結果が実際の状況に最も近くなるように、最適な目的関数を設計することに重点を置いています。同時に、予測に十分な情報を取得するには、適切なアーキテクチャを設計する必要があります。既存の方法は、入力データがレイヤーごとの特徴抽出と空間変換を受けると、大量の情報が失われるという事実を無視しています。この記事では、ディープネットワークを介してデータを送信する際の重要な問題、つまり情報のボトルネックと可逆機能について詳しく説明します。これに基づいて、深層ネットワークが複数の目的を達成するために必要なさまざまな変化に対処するために、プログラマブル勾配情報 (PGI) の概念が提案されています。 PGI は、目的関数を計算するためのターゲット タスクに完全な入力情報を提供することで、ネットワークの重みを更新するための信頼できる勾配情報を取得できます。さらに、新しい軽量ネットワーク フレームワークが設計されています。
 GNN の基礎、フロンティア、および応用
Apr 11, 2023 pm 11:40 PM
GNN の基礎、フロンティア、および応用
Apr 11, 2023 pm 11:40 PM
グラフ ニューラル ネットワーク (GNN) は、近年急速かつ驚くべき進歩を遂げています。グラフ ニューラル ネットワークは、グラフ ディープ ラーニング、グラフ表現学習 (グラフ表現学習)、または幾何学的ディープ ラーニングとも呼ばれ、機械学習、特にディープ ラーニングの分野で最も急速に成長している研究トピックです。この共有のタイトルは「GNN の基礎、フロンティア、および応用」です。主に、学者の Wu Lingfei、Cui Peng、Pei Jian、Zhao によって編纂された包括的な書籍「グラフ ニューラル ネットワークの基礎、フロンティア、およびアプリケーション」の一般的な内容を紹介します。梁さん。 1. グラフ ニューラル ネットワークの概要 1. なぜグラフを学ぶのですか?グラフは、複雑なシステムを記述およびモデル化するための汎用言語です。グラフ自体は複雑ではなく、主にエッジとノードで構成されています。ノードを使用してモデル化したい任意のオブジェクトを表現し、エッジを使用して 2 つのオブジェクトを表現できます。
 自動運転用の 3 つの主流チップ アーキテクチャの概要を 1 つの記事でまとめたもの
Apr 12, 2023 pm 12:07 PM
自動運転用の 3 つの主流チップ アーキテクチャの概要を 1 つの記事でまとめたもの
Apr 12, 2023 pm 12:07 PM
現在主流の AI チップは主に GPU、FPGA、ASIC の 3 つのカテゴリに分類されます。 GPU と FPGA はどちらも比較的成熟した初期段階のチップ アーキテクチャであり、汎用チップです。 ASIC は、特定の AI シナリオ向けにカスタマイズされたチップです。業界は、CPU が AI コンピューティングには適していないことを確認していますが、CPU は AI アプリケーションにも不可欠です。 GPU ソリューション アーキテクチャ GPU と CPU の比較 CPU はフォン ノイマン アーキテクチャに従っており、そのコアはプログラム/データのストレージとシリアル シーケンシャル実行です。したがって、CPU アーキテクチャは、記憶装置 (Cache) と制御装置 (Control) を配置するために大きなスペースを必要としますが、演算装置 (ALU) が占める割合は小さいため、CPU は大規模な処理を実行します。並列コンピューティング。
 「Bilibili UP のオーナーは世界初のレッドストーン ベースのニューラル ネットワークの作成に成功しました。これはソーシャル メディアでセンセーションを巻き起こし、Yann LeCun によって賞賛されました。」
May 07, 2023 pm 10:58 PM
「Bilibili UP のオーナーは世界初のレッドストーン ベースのニューラル ネットワークの作成に成功しました。これはソーシャル メディアでセンセーションを巻き起こし、Yann LeCun によって賞賛されました。」
May 07, 2023 pm 10:58 PM
マインクラフトにおいて、レッドストーンは非常に重要なアイテムです。これはゲーム内でユニークなマテリアルであり、スイッチ、レッドストーン トーチ、レッドストーン ブロックは、ワイヤーやオブジェクトに電気のようなエネルギーを供給できます。レッドストーン回路は、他の機械を制御または起動するための構造を構築するために使用できます。回路自体は、プレイヤーによる手動の起動に応答するように設計することも、信号を繰り返し出力したり、クリーチャーの動きなどの非プレイヤーによって引き起こされる変化に応答したりすることもできます落下、植物の成長、昼と夜など。したがって、私の世界では、レッドストーンは、自動ドア、照明スイッチ、ストロボ電源などの単純な機械から、巨大なエレベーター、自動農場、小型ゲームプラットフォーム、さらにはゲーム内マシンに至るまで、非常に多くの種類の機械を制御できます。 。最近はB局UPメイン@
 強風にも耐えられるドローン?カリフォルニア工科大学は 12 分間の飛行データを使用して、ドローンに風に乗って飛行するよう教えています
Apr 09, 2023 pm 11:51 PM
強風にも耐えられるドローン?カリフォルニア工科大学は 12 分間の飛行データを使用して、ドローンに風に乗って飛行するよう教えています
Apr 09, 2023 pm 11:51 PM
傘が飛ばされるほど風が強いとき、ドローンは次のように安定しています: 風に乗って飛行することは、空中で飛行することの一部です。大きなレベルから見ると、パイロットが航空機を着陸させるとき、風速は小規模なレベルでは、強風もドローンの飛行に影響を与える可能性があります。現在、ドローンは無風の制御された条件下で飛行するか、人間がリモコンを使用して操作します。ドローンは研究者によって制御され、大空で編隊を組んで飛行しますが、これらの飛行は通常、理想的な条件と環境の下で行われます。ただし、ドローンが荷物の配達など、必要ではあるが日常的なタスクを自律的に実行するには、風の状況にリアルタイムで適応できなければなりません。風を受けて飛行する際のドローンの操作性を高めるために、カリフォルニア工科大学のエンジニアのチームが
 マルチパス、マルチドメイン、すべてを網羅! Google AI がマルチドメイン学習一般モデル MDL をリリース
May 28, 2023 pm 02:12 PM
マルチパス、マルチドメイン、すべてを網羅! Google AI がマルチドメイン学習一般モデル MDL をリリース
May 28, 2023 pm 02:12 PM
視覚タスク (画像分類など) の深層学習モデルは、通常、単一の視覚領域 (自然画像やコンピューター生成画像など) からのデータを使用してエンドツーエンドでトレーニングされます。一般に、複数のドメインのビジョン タスクを完了するアプリケーションは、個別のドメインごとに複数のモデルを構築し、それらを個別にトレーニングする必要があります。データは異なるドメイン間で共有されません。推論中、各モデルは特定のドメインの入力データを処理します。たとえそれらが異なる分野を指向しているとしても、これらのモデル間の初期層のいくつかの機能は類似しているため、これらのモデルの共同トレーニングはより効率的です。これにより、遅延と消費電力が削減され、各モデル パラメーターを保存するためのメモリ コストが削減されます。このアプローチはマルチドメイン学習 (MDL) と呼ばれます。さらに、MDL モデルは単一モデルよりも優れたパフォーマンスを発揮します。
 1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
論文のアドレス: https://arxiv.org/abs/2307.09283 コードのアドレス: https://github.com/THU-MIG/RepViTRepViT は、モバイル ViT アーキテクチャで優れたパフォーマンスを発揮し、大きな利点を示します。次に、この研究の貢献を検討します。記事では、主にモデルがグローバル表現を学習できるようにするマルチヘッド セルフ アテンション モジュール (MSHA) のおかげで、軽量 ViT は一般的に視覚タスクにおいて軽量 CNN よりも優れたパフォーマンスを発揮すると述べられています。ただし、軽量 ViT と軽量 CNN のアーキテクチャの違いは十分に研究されていません。この研究では、著者らは軽量の ViT を効果的なシステムに統合しました。
 数年後にはプログラマーが減少するということをご存知ですか?
Nov 08, 2023 am 11:17 AM
数年後にはプログラマーが減少するということをご存知ですか?
Nov 08, 2023 am 11:17 AM
「ComputerWorld」誌はかつて、IBM がエンジニアが必要な数式を書いて提出できる新しい言語 FORTRAN を開発したため、「プログラミングは 1960 年までに消滅するだろう」という記事を書きました。コンピューターを実行すればプログラミングは終了します。画像 数年後、私たちは新しいことわざを聞きました: ビジネスマンは誰でもビジネス用語を使って問題を説明し、コンピュータに何をすべきかを伝えることができます。COBOL と呼ばれるこのプログラミング言語を使用することで、企業はもはやプログラマーを必要としません。その後、IBM は従業員がフォームに記入してレポートを作成できるようにする RPG と呼ばれる新しいプログラミング言語を開発したと言われており、会社のプログラミング ニーズのほとんどはこれで完了できます。
